- Principio del zócalo
- 1. ¿Qué es el zócalo?
- 2. Cómo se comunican los procesos en la red
- 3. Cómo comunicarse con Socket
- 4. Protocolo TCP / IP
- 4.1 Concepto
- 4.2 Problema de paquetes fijos de TCP y falta de bordes de datos:
- 4.3, estructura del datagrama TCP:
- 4.4 Establecimiento de la conexión (apretón de manos de tres vías):
- 4.5, protocolo de enlace TCP de cuatro vías para desconectar
- 4.6. Explicación sobre el estado TIME_WAIT
- 4.7 Elegante desconexión-apagado ()
- 5. Modelo OSI
- 6. Interfaz de función de uso común de socket y su principio
Principio del zócalo
Vaya a: https://www.jianshu.com/p/066d99da7cbd
1. ¿Qué es el zócalo?
En el campo de las comunicaciones informáticas, zócalo se traduce como "socket", que se encuentra entre las computadoras se comunican en una convención o una forma. A través del acuerdo de socket, una computadora puede recibir datos de otras computadoras o enviar datos a otras computadoras. El
socket se origina en Unix, y una de las filosofías básicas de Unix / Linux es "todo es un archivo", puede usar "open open- > Leer y escribir escribir / leer-> cierra el modo "cerrar" para operar.
Entiendo que Socket es una implementación de este patrón: ese socket es un archivo especial y algunas funciones de socket son operaciones en él (lectura / escritura de E / S, abrir, cerrar).
La función Socket () devuelve un descriptor de Socket entero, y las operaciones posteriores como el establecimiento de la conexión y la transmisión de datos se implementan a través del Socket.
2. Cómo se comunican los procesos en la red
Dado que Socket se usa principalmente para resolver la comunicación de red, entonces comprendamos cómo se comunican los procesos en la red.
2.1, comunicación local entre procesos
a. Paso de mensajes (canalización, cola de mensajes, FIFO)
b. ¿Sincronización (mutexes, variables de condición, bloqueos de lectura-escritura, bloqueos de registros de archivos y escrituras, semáforos)? [No está muy claro]
c. Memoria compartida (anónima y con nombre, por ejemplo: canal)
d. Llamada a procedimiento remoto (RPC)
2.2. Cómo se comunican los procesos en la red
Para comprender cómo se comunican los procesos en la red, tenemos que resolver dos problemas:
a. Cómo identificamos un host, es decir, cómo determinamos en qué host se está ejecutando el proceso que queremos comunicar.
b) ¿Cómo identificamos procesos únicos, identificación local por pid, cómo se debe identificar en la red?
Solución:
a. La familia de protocolos TCP / IP nos ha resuelto este problema. La "dirección IP" de la capa de red puede identificar de manera única al host en la red
b. El "protocolo + puerto" de la capa de transporte puede identificar de manera única la aplicación en el host. (Proceso), por lo tanto, podemos usar triples (dirección IP, protocolo, puerto) para identificar el proceso de la red, y la comunicación del proceso en la red puede usar esta bandera para interactuar con otros procesos
3. Cómo comunicarse con Socket
Ahora, sabemos cómo comunicarnos entre procesos en la red, es decir, el uso de triples [dirección IP, protocolo, puerto] puede comunicarse entre redes, entonces, ¿cómo deberíamos lograrlo? Por lo tanto, nuestro socket surgió, es usar Un triplete es una herramienta de middleware para la comunicación en red. En la actualidad, casi todas las aplicaciones usan sockets, como el socket de UNIX BSD (socket) y el TLI de UNIX System V (ha sido eliminado).
Existen dos métodos de transmisión de datos de uso común para la comunicación por socket:
a. SOCK_STREAM: indica un método de transmisión de datos orientado a la conexión. Los datos pueden llegar a otra computadora sin errores, y si se dañan o se pierden, se pueden reenviar, pero la eficiencia es relativamente lenta. El protocolo http común utiliza SOCK_STREAM para transmitir datos, ya que es necesario garantizar la exactitud de los datos, de lo contrario, la página web no se puede analizar normalmente.
b. SOCK_DGRAM: indica un método de transmisión de datos sin conexión. La computadora solo transmite los datos y no realiza la verificación de datos. Si los datos se dañan durante la transmisión o no llegan a otra computadora, no hay forma de remediarlos. En otras palabras, los datos son incorrectos y no se pueden retransmitir. Debido a que SOCK_DGRAM realiza menos trabajo de verificación, la eficiencia es mayor que SOCK_STREAM.
Por ejemplo: el chat de video QQ y el chat de voz usan SOCK_DGRAM para transmitir datos, porque antes que nada, debemos garantizar la eficiencia de la comunicación y minimizar el retraso, y la precisión de los datos es secundaria, incluso si se pierde una pequeña parte de los datos, el video y el audio pueden El análisis normal, hasta ruido o ruido, no tendrá un impacto sustancial en la calidad de la comunicación.
4. Protocolo TCP / IP
4.1 Concepto
TCP / IP [TCP (Protocolo de control de transmisión) e IP (Protocolo de Internet)] proporciona un mecanismo de enlace punto a punto que estandariza cómo se deben encapsular, direccionar, transmitir, enrutar y recibir datos en el destino. Resume el proceso de comunicación del software en cuatro capas abstractas y adopta la pila de protocolos para implementar diferentes protocolos de comunicación. Los diversos protocolos de la familia de protocolos se clasifican en estas cuatro estructuras jerárquicas según sus funciones, y a menudo se consideran como un modelo OSI simplificado de siete capas.
Entre ellos es como el papel de la línea de entrega y la estación. Por ejemplo, para sugerir una estación de entrega, debe comprender los detalles de la entrega.
TCP (Transmission Control Protocol, Transmission Control Protocol) es un protocolo de comunicación basado en la transmisión de bytes, confiable y orientado a la conexión. Los datos deben conectarse antes de la transmisión y desconectarse después de la transmisión. El cliente envía y recibe datos Antes de usar la función connect () para establecer una conexión con el servidor. El propósito de establecer una conexión es garantizar que la dirección IP, el puerto, el enlace físico, etc. sean correctos y abrir canales para la transmisión de datos.
Al establecer una conexión, TCP transmite tres paquetes de datos, comúnmente conocidos como protocolo de enlace de tres vías (Protocolo de enlace de tres vías). La imagen se puede comparar con el siguiente diálogo:
[Shake 1] 套接字A:“你好,套接字B,我这里有数据要传送给你,建立连接吧。”
[Shake 2] 套接字B:“好的,我这边已准备就绪。”
[Shake 3] 套接字A:“谢谢你受理我的请求。
4.2 Problema de paquetes fijos de TCP y falta de bordes de datos:
https://blog.csdn.net/m0_37947204/article/details/80490512
4.3, estructura del datagrama TCP:
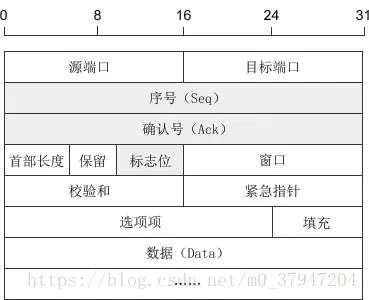
Los campos sombreados deben resaltarse:
(1) Número de secuencia: el número de secuencia Seq (número de secuencia) ocupa 32 bits y se utiliza para identificar el número de secuencia del paquete de datos enviado desde la computadora A a la computadora B. Esto se marca cuando la computadora envía datos .
(2) Número de acuse de recibo: El número de acuse de recibo Ack (número de acuse de recibo) ocupa 32 bits, tanto el cliente como el servidor pueden enviar, Ack = Seq + 1.
(3) Bit de bandera: cada bit de bandera ocupa 1Bit, hay 6 en total, a saber, URG, ACK, PSH, RST, SYN, FIN, el significado específico es el siguiente:
(1)URG:紧急指针(urgent pointer)有效。
(2)ACK:确认序号有效。
(3)PSH:接收方应该尽快将这个报文交给应用层。
(4)RST:重置连接。
(5)SYN:建立一个新连接。
(6)FIN:断开一个连接。
4.4 Establecimiento de la conexión (apretón de manos de tres vías):
Cuando utilice connect () para establecer una conexión, el cliente y el servidor se enviarán tres paquetes de datos entre sí, consulte la siguiente figura:
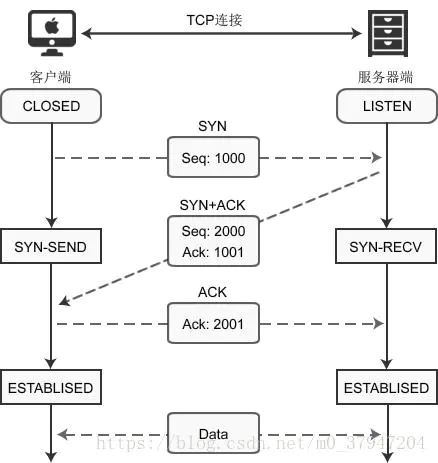
El cliente llama socket () para crear un socket después, porque no se establece una conexión, el enchufe se encuentra en estado cerrado; llamadas del lado del servidor escuchan () después de la función, la toma en el estado LISTEN, comience a escuchar las peticiones de los clientes
, donde el cliente El terminal inicia la solicitud:
1) Cuando el cliente llama a la función connect (), el protocolo TCP construirá un paquete de datos y establecerá el bit indicador SYN, lo que indica que el paquete de datos se utiliza para establecer una conexión síncrona. Al mismo tiempo, se genera un número aleatorio 1000 y se llena el campo "Seq" para indicar el número de secuencia del paquete de datos. Después de completar estas tareas, comienza a enviar paquetes de datos al servidor y el cliente ingresa al estado SYN-SEND.
2) El servidor recibe el paquete de datos, detecta que se ha establecido el indicador SYN y sabe que este es un "paquete de solicitud" enviado por el cliente para establecer una conexión. El servidor también configurará un paquete de datos y establecerá los indicadores SYN y ACK. SYN indica que el paquete de datos se utiliza para establecer una conexión. ACK se utiliza para confirmar que el paquete enviado por el cliente ha sido recibido. El
servidor genera un número aleatorio 2000 y completa el "número de serie (Seq) "campo. 2000 no tiene nada que ver con los paquetes del cliente.
El servidor agrega 1 al número de secuencia del paquete de datos del cliente (1000) para obtener 1001, y llena el campo "Ack" con este número.
El servidor envía el paquete de datos y entra en el estado SYN-RECV.
3) El cliente recibe el paquete de datos, detecta que se han establecido los indicadores SYN y ACK, y sabe que este es un "paquete de confirmación" enviado por el servidor. El cliente verificará el campo "Ack" (Ack) para ver si su valor es 1000 + 1, si es así, significa que la conexión se ha establecido con éxito.
A continuación, el cliente continuará creando paquetes de datos y establecerá el indicador ACK, que indica que el cliente ha recibido correctamente el "paquete de reconocimiento" del servidor. Al mismo tiempo, agregue 1 al número de secuencia (2000) del paquete de datos enviado por el servidor justo ahora para obtener 2001, y use este número para completar el campo "Ack".
El cliente envía el paquete de datos y entra en el estado ESTABLECIDO, lo que indica que la conexión se ha establecido correctamente.
4) El servidor recibe el paquete de datos, detecta que se ha establecido el indicador ACK y sabe que se trata de un "paquete de confirmación" enviado por el cliente. El servidor verificará el campo "número de acuse de recibo (Ack)" para ver si su valor es 2000 + 1, si es así, significa que la conexión se estableció con éxito y el servidor entra en el estado ESTABLECIDO.
En este punto, el cliente y el servidor han entrado en el estado ESTABLECIDO, la conexión se ha establecido con éxito y luego puede enviar y recibir datos.
4.5, protocolo de enlace TCP de cuatro vías para desconectar
Es muy importante establecer una conexión, es la premisa de la transmisión correcta de datos; la desconexión también es importante, le permite a la computadora liberar recursos que ya no están en uso. Si la conexión no se puede desconectar normalmente, no solo causará errores de transmisión de datos, sino que también hará que el socket no se cierre y continúe ocupando recursos. Si la cantidad de concurrencia es alta, la presión del servidor es preocupante.
La desconexión requiere cuatro apretones de manos, que pueden compararse con el siguiente diálogo:
[Shake 1] 套接字A:“任务处理完毕,我希望断开连接。”
[Shake 2] 套接字B:“哦,是吗?请稍等,我准备一下。”
等待片刻后……
[Shake 3] 套接字B:“我准备好了,可以断开连接了。”
[Shake 4] 套接字A:“好的,谢谢合作。”
La siguiente figura muestra el escenario donde el cliente se desconecta activamente:
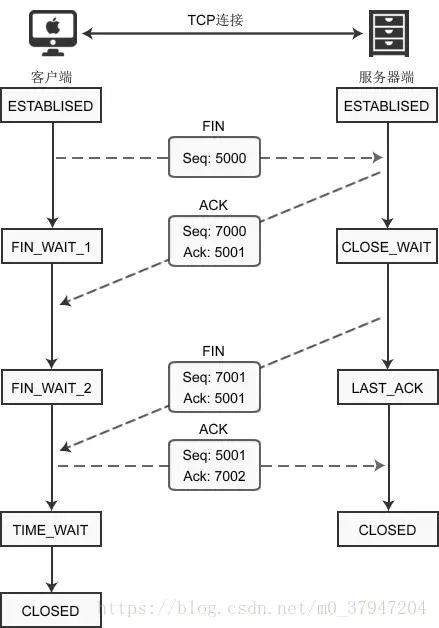
Una vez establecida la conexión, tanto el cliente como el servidor están en estado ESTABLECIDO. En este momento, el cliente inicia una solicitud de desconexión:
- Después de que el cliente llama a la función close (), envía un paquete FIN al servidor y entra en el estado FIN_WAIT_1. FIN es la abreviatura de Finish, lo que significa que se requiere desconexión para completar la tarea.
- Después de recibir el paquete de datos, el servidor detecta que el indicador FIN está configurado y sabe que se desconecta, por lo que envía un "paquete de confirmación" al cliente y entra en el estado CLOSE_WAIT.
Nota: El servidor no se desconecta inmediatamente después de recibir la solicitud, pero primero envía un "paquete de confirmación" al cliente, diciéndole que sé que debo prepararme para desconectarme. - Después de recibir el "paquete de confirmación", el cliente ingresa al estado FIN_WAIT_2 y espera a que el servidor se prepare para enviar nuevamente el paquete de datos.
- Después de esperar un momento, el servidor está listo para desconectarse, por lo que envía activamente un paquete FIN al cliente para decirle que estoy listo, desconéctelo. Luego ingrese el estado LAST_ACK.
- Después de recibir el paquete FIN del servidor, el cliente envía un paquete ACK al servidor para indicarle que se desconecte. Luego ingrese el estado TIME_WAIT.
- Después de recibir el paquete ACK del cliente, el servidor se desconecta, cierra el socket y entra en el estado CERRADO.
4.6. Explicación sobre el estado TIME_WAIT
Después de que el cliente envía el paquete ACK por última vez, ingresa el estado TIME_WAIT en lugar de ingresar directamente el estado CERRADO para cerrar la conexión.
TCP es un método de transmisión orientado a la conexión. Debe garantizarse que los datos puedan llegar a la máquina de destino correctamente sin pérdida o error. La red es inestable y puede destruir los datos en cualquier momento, por lo que cada vez que la máquina A envía un paquete de datos a la máquina B, requiere La máquina B "reconoce" y devuelve un paquete ACK, diciéndole a la máquina A que lo recibí, para que la máquina A pueda saber que la transmisión de datos fue exitosa. Si la máquina B no devuelve un paquete ACK, la máquina A reenviará hasta que la máquina B devuelva un paquete ACK.
Cuando el cliente envía el paquete ACK nuevamente al servidor por última vez, es posible que el servidor no lo reciba debido a problemas de red. El servidor enviará el paquete FIN nuevamente. Si el cliente cierra completamente la conexión en este momento, el servidor no recibirá el ACK de todos modos. Paquete, por lo que el cliente debe esperar un momento y confirmar que la otra parte recibe el paquete ACK antes de ingresar al estado CERRADO. Entonces, ¿cuánto tiempo tienes que esperar?
El paquete de datos tiene un tiempo de supervivencia en la red. Si no alcanza el host de destino después de este tiempo, se descartará y se notificará al host de origen. Esto se llama el tiempo de vida máximo del segmento (MSL). TIME_WAIT espera 2MSL antes de entrar en estado CERRADO. A MSL le toma tiempo llegar al servidor y MSL a tiempo para que el servidor retransmita el paquete FIN. 2MSL es el tiempo máximo para el viaje de ida y vuelta del paquete de datos. Si el paquete FIN retransmitido por el servidor no se ha recibido después de 2MSL, significa que el servidor ha recibido el paquete ACK.
4.7 Elegante desconexión-apagado ()
La diferencia entre close () / closesocket () y shutdown ()
Para ser precisos, close () / closesocket () se usa para cerrar el socket, borrar el descriptor (o handle) del socket de la memoria y ya no se puede usar después Este socket es similar a fclose () en lenguaje C. Después de que la aplicación cierra el socket, la conexión y el caché asociados con el socket pierden su significado, y el protocolo TCP activa automáticamente la operación para cerrar la conexión.
shutdown () se usa para cerrar la conexión, no el socket. No importa cuántas veces se llame a shutdown (), el socket aún existe hasta que se llame a close () / closesocket () para borrar el socket de la memoria.
Cuando se llama a close () / closesocket () para cerrar el socket, o se llama a shutdown () para cerrar el flujo de salida, se envía un paquete FIN a la otra parte. El paquete FIN indica que la transmisión de datos se ha completado. La computadora recibe el paquete FIN y sabe que no se transmitirán más datos.
Por defecto, close () / closesocket () enviará inmediatamente un paquete FIN a la red, independientemente de si hay datos en el búfer de salida, y shutdown () esperará a que se transmitan los datos en el búfer de salida antes de enviar el paquete FIN. Esto significa que llamar a close () / closesocket () perderá los datos en el búfer de salida, mientras que llamar a shutdown () no
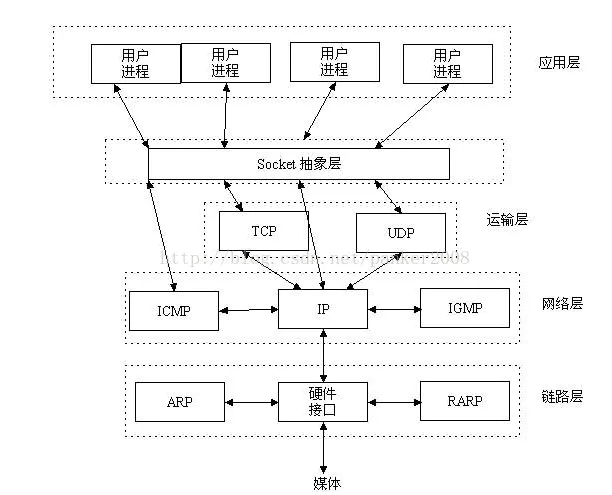
5. Modelo OSI
TCP / IP divide la capa de modelo de red de OSI de la siguiente manera:

El modelo de referencia de protocolo TCP / IP clasifica todos los protocolos de la serie TCP / IP en cuatro capas abstractas
Capa de aplicación: TFTP, HTTP, SNMP, FTP, SMTP, DNS, Telnet, etc.
Capa de transporte: TCP, UDP
Capa de red: IP , ICMP, OSPF, EIGRP,
capa de enlace de datos IGMP : SLIP, CSLIP, PPP, MTU.
Cada capa de abstracción se basa en los servicios proporcionados por la capa inferior y proporciona servicios para la capa superior.

6. Interfaz de función de uso común de socket y su principio
Función de socket gráfico:
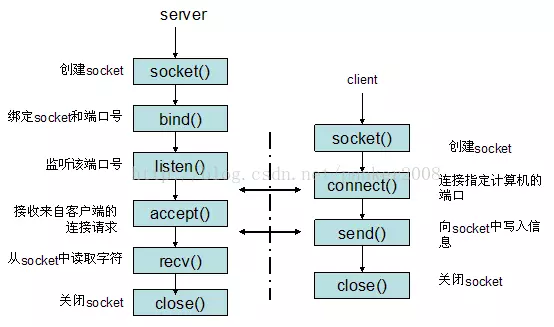
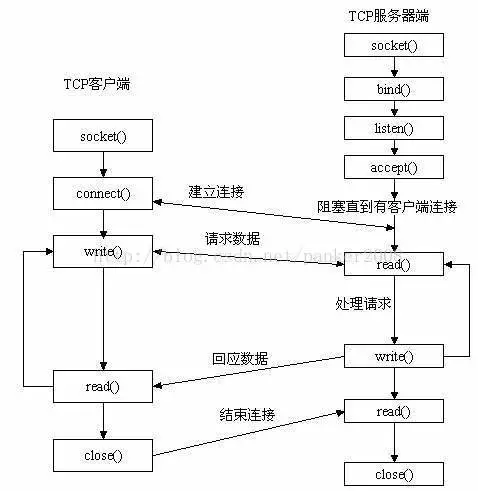
6.1. Utilice la función socket () para crear un socket
int socket(int af, int type, int protocol);
- af es la familia de direcciones (Familia de direcciones), es decir, el tipo de dirección IP que se usa comúnmente son AF_INET y AF_INET6. AF es la abreviatura de "Familia de direcciones" e INET es la abreviatura de "Inetnet". AF_INET representa una dirección IPv4, como 127.0.0.1; AF_INET6 representa una dirección IPv6, como 1030 :: C9B4: FF12: 48AA: 1A2B.
Debe recordar 127.0.0.1, es una dirección IP especial, lo que significa la dirección local, que se utilizará con frecuencia en los siguientes tutoriales. - tipo es el método de transmisión de datos, comúnmente utilizados son SOCK_STREAM y SOCK_DGRAM
- El protocolo representa el protocolo de transmisión, comúnmente utilizados son IPPROTO_TCP e IPPTOTO_UDP, respectivamente representan el protocolo de transmisión TCP y el protocolo de transmisión UDP
6.2. Usar las funciones bind () y connect ()
La función socket () se usa para crear un socket y determinar varias propiedades del socket, y luego la función bind () del lado del servidor se usa para vincular el socket a una dirección IP y puerto específicos. Los datos de la dirección IP y el puerto solo pueden transferirse al socket para su procesamiento; el cliente debe usar la función connect () para establecer una conexión
int bind(int sock, struct sockaddr *addr, socklen_t addrlen);
sock es el descriptor del archivo de socket, addr es el puntero de la variable de estructura sockaddr, addrlen es el tamaño de la variable addr, y el
siguiente código se puede calcular mediante sizeof () para vincular el socket creado a la dirección IP 127.0.0.1 y al puerto 1234 Conjunto:
//创建套接字
int serv_sock = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
//创建sockaddr_in结构体变量
struct sockaddr_in serv_addr;
memset(&serv_addr, 0, sizeof(serv_addr)); //每个字节都用0填充
serv_addr.sin_family = AF_INET; //使用IPv4地址
serv_addr.sin_addr.s_addr = inet_addr("127.0.0.1"); //具体的IP地址
serv_addr.sin_port = htons(1234); //端口
//将套接字和IP、端口绑定
bind(serv_sock, (struct sockaddr*)&serv_addr, sizeof(serv_addr));
La función connect () se utiliza para establecer una conexión y su prototipo es:
int connect(int sock, struct sockaddr *serv_addr, socklen_t addrlen);
6.3. Usar las funciones listen () y accept ()
En el programa del lado del servidor, después de usar bind () para vincular el socket, también necesita usar la función listen () para hacer que el socket entre en el estado de escucha pasiva, y luego llamar a la función accept (), puede responder a la solicitud del cliente en cualquier momento.
A través de la función ** listen () **, el socket puede ponerse en estado de escucha pasiva. Su prototipo es:
int listen(int sock, int backlog);
Sock es el socket que necesita ingresar al estado de escucha, y el backlog es la longitud máxima de la cola de solicitudes.
El llamado monitoreo pasivo significa que cuando no hay una solicitud del cliente, el socket está en el estado de "suspensión". Solo cuando se recibe la solicitud del cliente, el socket se "despertará" para responder a la solicitud.
Cola de solicitudes
Cuando el socket procesa la solicitud del cliente, si entra una nueva solicitud, el socket no se puede procesar y solo se puede colocar en el búfer. Después de procesar la solicitud actual, se eliminará del búfer Léelo para procesar. Si siguen llegando nuevas solicitudes, se pondrán en cola en el búfer en orden, hasta que el búfer esté lleno. Este búfer se llama Solicitar cola.
La longitud del búfer (cuántas solicitudes de clientes pueden almacenarse) puede especificarse mediante el parámetro de la tarea de escuchar (), pero no existe un estándar para cuánto, puede determinarse de acuerdo con sus necesidades, y la concurrencia puede ser 10 o 20 .
Si el valor de la acumulación se establece en SOMAXCONN, el sistema determina la longitud de la cola de solicitudes. Este valor generalmente es grande, que puede ser de varios cientos o más.
Cuando la cola de solicitudes está llena, ya no recibe nuevas
Cuando la cola de solicitudes está llena, no se recibirán nuevas solicitudes. Para Linux, el cliente recibirá un error ECONNREFUSED
Nota: listen () solo pone el socket en el estado de escucha y no recibe la solicitud. Se requiere la función accept () para recibir la solicitud.
Cuando el socket está en estado de escucha, la solicitud del cliente se puede recibir a través de la función accept () . Su prototipo es:
int accept(int sock, struct sockaddr *addr, socklen_t *addrlen);
Sus parámetros son los mismos que listen () y connect (): sock es el zócalo del lado del servidor, addr es la variable de estructura sockaddr_in y addrlen es la longitud del parámetro addr, que se puede obtener mediante sizeof ().
accept () devuelve un nuevo socket para comunicarse con el cliente, addr guarda la dirección IP y el número de puerto del cliente, y sock es el socket del lado del servidor, todos deben prestar atención para distinguir. Cuando se comunique con el cliente más tarde, use este socket recién generado en lugar del socket original del lado del servidor.
Finalmente, debe tenerse en cuenta que listen () solo pone el socket en el estado de escucha y en realidad no recibe solicitudes de clientes. El código detrás de listen () continuará ejecutándose hasta que encuentre accept (). accept () bloqueará la ejecución del programa (el código subyacente no se puede ejecutar) hasta que llegue una nueva solicitud.
6.4. Recepción y transmisión de datos de socket
La recepción y el envío de datos en
Linux Linux no distingue entre archivos de socket y archivos normales. Utilice write () para escribir datos en el socket y read () para leer datos del socket.
Como dijimos anteriormente, la comunicación entre dos computadoras es equivalente a la comunicación entre dos sockets. Write () se usa para escribir datos en el socket en el lado del servidor, y el cliente puede recibirlos, y luego usar read () Leer desde el socket y completar una comunicación.
El prototipo de write () es:
ssize_t write(int fd, const void *buf, size_t nbytes);
fd es el descriptor del archivo que se va a escribir, buf es la dirección del búfer de los datos que se van a escribir y nbytes es el número de bytes de los datos que se van a escribir.
La función write () escribe nbytes bytes en el buffer buf en el archivo fd. Si tiene éxito, devuelve el número de bytes escritos, y si falla, devuelve -1.
El prototipo de read () es:
ssize_t read(int fd, void *buf, size_t nbytes);
fd es el descriptor del archivo que se va a leer, buf es la dirección del búfer de los datos que se van a recibir y nbytes es el número de bytes de los datos que se van a leer.
La función read () lee nbytes bytes del archivo fd y los guarda en la memoria intermedia del búfer. Si tiene éxito, devuelve el número de bytes leídos (pero devuelve 0 al final del archivo) y -1 si falla.
6.5, buffer de socket y modo de bloqueo
Búfer de socket Después de
crear cada socket, asignará dos buffers, buffer de entrada y buffer de salida.
write () / send () no transmite inmediatamente los datos a la red, pero primero los escribe en el búfer y luego el protocolo TCP envía los datos del búfer a la máquina de destino. Una vez que los datos se escriben en el búfer, la función puede regresar con éxito, independientemente de si llegan a la máquina de destino, y de cuándo se envían a la red, esto es de lo que es responsable el protocolo TCP.
El protocolo TCP es independiente de la función write () / send (). Los datos pueden enviarse a la red tan pronto como se escriben en el búfer, o pueden continuar acumulándose en el búfer. Los datos escritos varias veces se envían a la red a la vez. Depende de muchos factores, como las condiciones de la red en ese momento, si el subproceso actual está inactivo, etc., y no está controlado por el programador.
Lo mismo es cierto para la función read () / recv (), que también lee datos desde el búfer de entrada en lugar de directamente desde la red
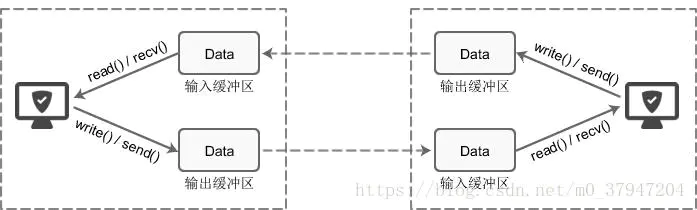
Las características de estos búferes de E / S se pueden organizar de la siguiente manera:
(1)I/O缓冲区在每个TCP套接字中单独存在;
(2)I/O缓冲区在创建套接字时自动生成;
(3)即使关闭套接字也会继续传送输出缓冲区中遗留的数据;
(4)关闭套接字将丢失输入缓冲区中的数据
El tamaño predeterminado del búfer de entrada y salida es generalmente de 8K, que se puede obtener a través de la función getsockopt ():
unsigned optVal;
int optLen = sizeof(int);
getsockopt(servSock, SOL_SOCKET, SO_SNDBUF, (char*)&optVal, &optLen);
printf("Buffer length: %d\n", optVal);
Modo de bloqueo
Para sockets TCP (por defecto), cuando se utiliza write () / send () para enviar datos:
1) 首先会检查缓冲区,如果缓冲区的可用空间长度小于要发送的数据,那么 write()/send() 会被阻塞(暂停执行),直到缓冲区中的数据被发送到目标机器,腾出足够的空间,才唤醒 write()/send() 函数继续写入数据。
2) 如果TCP协议正在向网络发送数据,那么输出缓冲区会被锁定,不允许写入,write()/send() 也会被阻塞,直到数据发送完毕缓冲区解锁,write()/send() 才会被唤醒。
3) 如果要写入的数据大于缓冲区的最大长度,那么将分批写入。
4) 直到所有数据被写入缓冲区 write()/send() 才能返回。
Cuando use read () / recv () para leer datos:
1) 首先会检查缓冲区,如果缓冲区中有数据,那么就读取,否则函数会被阻塞,直到网络上有数据到来。
2) 如果要读取的数据长度小于缓冲区中的数据长度,那么就不能一次性将缓冲区中的所有数据读出,剩余数据将不断积压,直到有 read()/recv() 函数再次读取。
3) 直到读取到数据后 read()/recv() 函数才会返回,否则就一直被阻塞。
这就是TCP套接字的阻塞模式。所谓阻塞,就是上一步动作没有完成,下一步动作将暂停,直到上一步动作完成后才能继续,以保持同步性。
Los zócalos TCP están en modo de bloqueo por defecto