Directorio
Antecedentes
Muchas empresas de Internet a menudo tienen una base de datos que almacena su información de usuario, y los datos en la base de datos son básicamente limpiados por el departamento de ingeniería (el uso de la tecnología de rastreadores o el análisis de datos subyacente es principalmente el trabajo del departamento de desarrollo o del departamento de ingeniería de recopilación de datos), por lo que Muchos analistas de datos comerciales pueden usar herramientas como HSQL para obtener fácilmente las cantidades masivas de datos que necesitan.
Sin embargo, hay algunas empresas B2B pequeñas y medianas en el mercado, que no son como las empresas B2C, y dependen de su propia información de usuario para la iteración del producto o el crecimiento del negocio. Se basan principalmente en el departamento de ingeniería para analizar los datos de terceros y enviar los resultados al departamento de desarrollo de productos para la construcción y visualización de plataformas de negocios. El proceso de obtención de datos de terceros requiere el uso de interfaces API de terceros, razón por la cual estas compañías requieren que los candidatos que solicitan varios puestos tengan experiencia en llamadas API, porque incluso si la compañía tiene su propia base de datos, esto es, después de todo, un departamento de ingeniería. Después de los resultados del rastreo selectivo y la clasificación, puede enfrentar el dilema de que la base de datos no tiene los datos que desea. En este momento, debe utilizar un método similar para recopilar los datos usted mismo.

Introducción a la API
El proceso de llamar a la API también es una especie de rastreador. En los rastreadores, generalmente hay dos lugares donde se mencionan las API, una es la API de la biblioteca y la otra es la API de datos.
API de biblioteca
La API de biblioteca generalmente se refiere a los desarrolladores que han desarrollado una biblioteca (como una biblioteca de Python) y proporcionan una interfaz para que los usuarios llamen a esta biblioteca. Esto es como si queremos ir al casillero de paquetes para recoger nuestro servicio de mensajería, debemos ingresar la información correcta para obtener nuestro servicio de mensajería. Esta información es una interfaz API que nos ayuda a localizar con precisión esta biblioteca y llamarla.
API de datos
En el desarrollo de productos o el desarrollo web, la API de datos es como una línea de datos que se pasa desde el back-end al front-end. El personal del back-end ha resuelto los datos que desea mostrar y solo necesita transmitir esta línea de datos al desarrollador del front-end. El front-end puede visualizarla según sea necesario. Y esta interfaz también puede ser utilizada por el mundo exterior.
A diferencia del rastreador web, el diseño de la API de datos es más simple y más eficiente. Esta interfaz ya almacena los datos que todos necesitan, y no necesitamos gastar demasiada energía para analizar la página web. Y el rastreo de datos de la página web a menudo causará presión en el servidor. Si su código no está configurado con una frecuencia de navegación de página web razonable similar a la humana, habrá un riesgo de bloqueo de IP.
Pero la API de datos también tiene algunas desventajas. Aunque hay muchos productos API en el mercado que pueden ser utilizados por el mundo exterior, muchas interfaces gratuitas tienen grandes restricciones sobre la cantidad de rastreo. Si sus necesidades de rastreo son grandes, debe pagar.
Ejemplo de rastreador de API simple
A continuación, usaré la API Graph de Facebook para rastrear datos como un ejemplo para registrar aproximadamente el proceso de llamada a la API de datos comunes.
- Información de la interfaz de llamada: proporcione la dirección de llamada de la API (generalmente en formato URL). Esta dirección es similar a ayudarnos a localizar qué fila y columna del gabinete de almacenamiento queremos obtener.
- Solicitud para obtener datos: use el protocolo HTTP para solicitar la transferencia de datos, generalmente llame a la función get en el paquete de solicitud en python.
- Establezca los parámetros de solicitud: debe proporcionar los parámetros de solicitud, es decir, debe decirle a la interfaz API qué tipo de información desea obtener. Por ejemplo, en este caso, necesito información como created_time (post time), post_id (post_id)
Documento de introducción de la API de Facebook Graph
Aunque una función get puede ayudarnos a implementar solicitudes de protocolo HTTP, muchas veces solicitar esta URL requiere autenticación de identidad. Por ejemplo, el siguiente código informará un error:
import requests
r = requests.get('https://facebook.com/user_id')
r.json()
Y volver: se requiere permiso de identidad. Por lo tanto, cuando se utiliza cualquier interfaz API, es mejor leer la documentación de uso del sitio web con anticipación para ver qué información específica requiere el protocolo de solicitud.
{'documentation_url': ''https://facebook.com/user_id/#get-the-access-token',
'message': 'Requires authentication'}
También puede ver en el manual de usuario oficial de la API de Facebook, si deseo obtener la información de una cuenta de Facebook, necesito obtener el token de esta cuenta. Si desea obtener otra información de cuenta además de usted, también necesita obtener sus tokens por adelantado. Habrá una introducción correspondiente para obtener el token-> cómo obtener el token de acceso de la cuenta de Facebook .
Después de obtener el token, pruebe el código anterior para obtener los siguientes resultados:
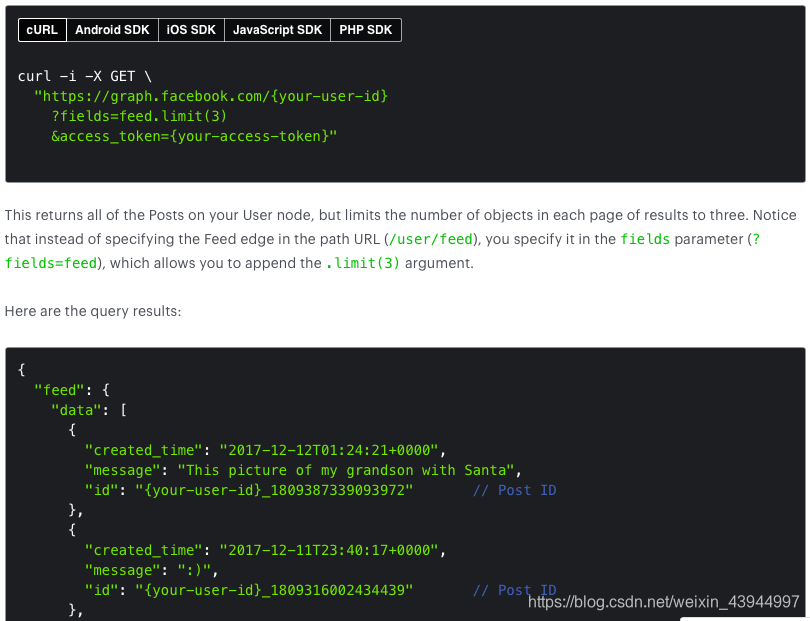
Ejemplo de código
Objetivo: obtener el número de visitas de cada videoblog desde 2020.03.01 hasta 2020.03.07, el tiempo de visualización de cada país, cada género y cada grupo de edad, y analizar el rendimiento del contenido de video de este blogger en esta semana.
1. 首先我需要拿到3.1至3.7之间每条博文的ID(post_id)
2. 筛选出仅为视频的博文ID
3. 需要获取每条视频博文的观看次数,各个国家的观看时长
4. 将json格式的数据整理成dataframe格式
5. 将观看时长可视化
1. 导入所需的包
import pandas as pd
import json, datetime, requests
from datetime import date, timedelta, datetime
import numpy as np
from pandas.core.frame import DataFrame
2.创建爬取数据的函数
def get_list_of_fb_post_ids(fb_page_id, fb_token, START, END):
'''
Function to get all the post_ids from a given facebook page during certain time range
'''
posts=[] #用来存储所有博文的post_id
graph_output = requests.get('https://graph.facebook.com/'+fb_page_id+'?fields=posts.limit(10){created_time}',params=fb_token).json()
posts+=graph_output['posts']['data']
graph_output = requests.get(graph_output['posts']['paging']['next']).json()
posts+=graph_output['data']
while True: #一直读取next_page,直到某次读取的记录的时间小于你设置的开始时间
try:
graph_output = requests.get(graph_output['paging']['next']).json()
posts+=graph_output['data']
if graph_output['data'][-1]['created_time']<=START:
break
except KeyError:
break
df_posts=pd.DataFrame(posts)
df_posts=df_posts[(df_posts.created_time>=START)&(df_posts.created_time<=(datetime.strptime(END, "%Y-%m-%d")+timedelta(days=1)).isoformat())]
df_posts.columns = ["timestamp", "post_id"]
return df_posts
3.给变量赋值,抓取post_id
fb='EAAIkwQUa1WoBAFWmq90xbMfLHecpRga****************'
fb_token = {'access_token': fb}
user_id='1404******'
output=get_list_of_fb_post_ids(user_id,fb_token,'2020-03-01','2020-03-07')
Los resultados son los siguientes:
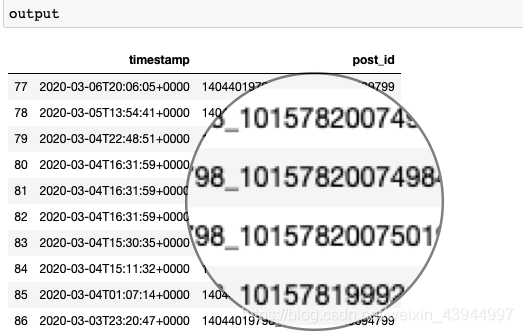
4.获取每条视频博文的相关数据
## 设定好想要获取的每条视频博文的信息
Fields = '?metric='+'post_video_views,post_video_view_time_by_region_id'
list_metrics=[ 'post_video_views','post_video_view_time_by_region_id']
def get_video_insights(output,fb_token):
final_output=pd.DataFrame()
for i in output.index.values:
post_id = output['post_id'][i]
Type = requests.get('https://graph.facebook.com/'+post_id+'?fields=type',params=fb_token).json()
if Type['type'] == 'video': #筛选出仅为视频的博文记录
try:
insights_output = requests.get('https://graph.facebook.com/'+post_id+'/insights{}&period=lifetime'.format(Fields),params=fb_token).json()
list1=list_metrics
metrics=[]
for j in range(0,len(list_metrics)):
metrics.append(insights_output['data'][j]['values'][0]['value'])
#print("metrics get")
metrics=DataFrame(metrics).T
metrics.columns=list1
col_name = metrics.columns.tolist()
col_name.insert(col_name.index('post_video_view_time_by_region_id'),'timestamp')
col_name.insert(col_name.index('timestamp'),'post_id')
metrics=metrics.reindex(columns=col_name).reset_index()
metrics['post_id']=output['post_id'][i]
metrics['timestamp']=output['timestamp'][i]
final_output=final_output.append(metrics)
except:
pass
return final_output
El resultado es:
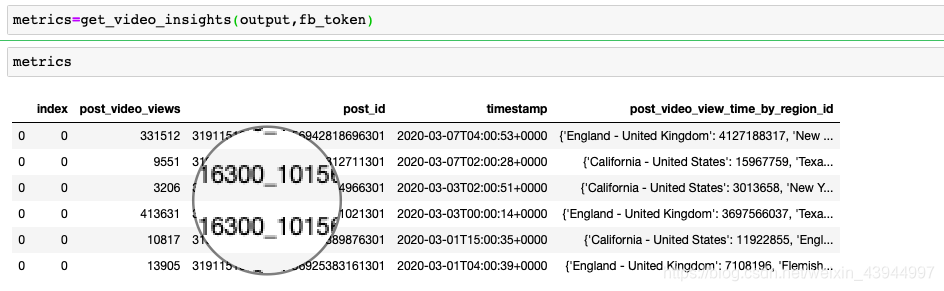
5.将json格式的数据整理成dataframe格式
De los resultados anteriores, podemos ver que dentro de esta semana, el blogger ha publicado un total de 6 publicaciones de video blog, de las cuales la más reproducida es una de las 3.3, hasta más de 400,000 veces. Sin embargo, el formato del indicador de tiempo de visualización en varias regiones es el formato json, y debemos tratarlo por separado.
Primero mire la estructura de datos de la columna de región:
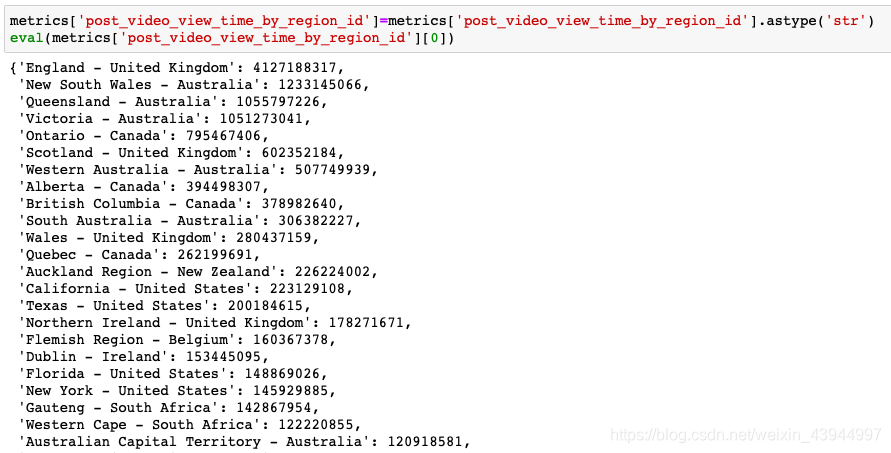
Como se puede ver en los resultados anteriores, necesitamos atravesar cada fila de la columna, generar un nuevo marco de datos, usar cada país como una columna y almacenar los valores correspondientes uno por uno.
#遍历 post_video_view_time_by_region_id 这一列的每一行
Region=pd.DataFrame()
metrics.index=range(len(metrics)) #重新定义index
metrics['post_video_view_time_by_region_id']=metrics['post_video_view_time_by_region_id'].astype('str')
for j in metrics.index.values:
e=eval(metrics['post_video_view_time_by_region_id'][j]) #返回字符串内的值,直接返回一个dict
single_graph = []
for i in e.keys():
single_graph.append(e[i])
single=pd.DataFrame(single_graph).T
single.columns=list(e.keys())
Region=Region.append(single)
Los resultados son los siguientes:
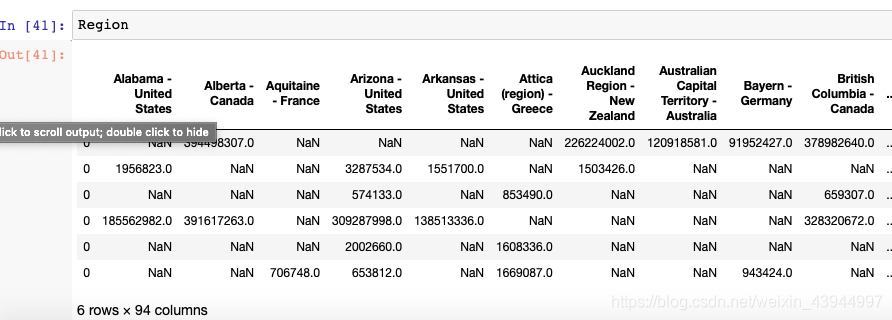
6. 将观看时长可视化
Primero, necesitamos procesar los datos en la tabla Región. Necesitamos dividir el nombre de cada columna en países y ciudades. Esto se hace para asignar más fácilmente los datos anteriores a un mapa de los Estados Unidos y determinar visualmente qué usuarios del estado prefieren el contenido de video del blogger.
o=Region.mean().to_dict() #算出每个城市的平均观看时长
dataset=pd.DataFrame(pd.Series(o),columns=['view time'])
dataset=dataset.reset_index().rename(columns={'index':'region'})
dataset['state']=dataset['region'].map(lambda x: x.split('-')[0]) #将列名分为国家和地区
dataset['country']=dataset['region'].map(lambda x: x.split('-')[1])#将列名分为国家和地区
El resultado procesado es:
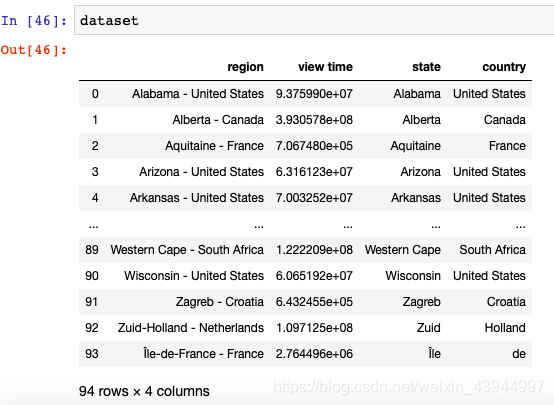
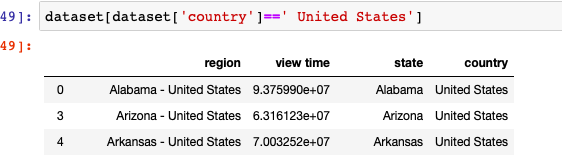
Finalmente, solo necesitamos filtrar las regiones de los Estados Unidos y convertir los datos en un mapa de los Estados Unidos, y ya está.
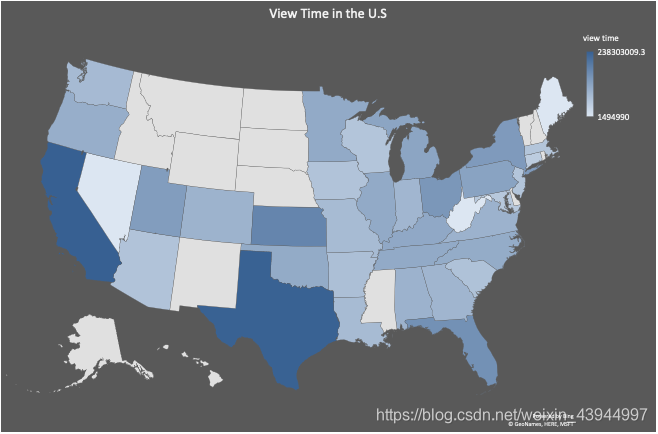
Desde el mapa, podemos analizar que el video del blogger es amado por la gente de Texas y California. Además de tratar constantemente de atender las estrategias de video de los usuarios en estos dos estados, necesitamos investigar más a fondo por qué otros estados De los videos son mucho más cortos que ellos. Con base en la información anterior, los bloggers pueden hacer que sea más geográficamente característico en la producción de video posterior, y recomendar a los bloggers que usen la función de distribución regional de Facebook para distribuir diferentes características de contenido de video a diferentes regiones para atender de manera más eficiente Los gustos y aficiones de los usuarios optimizan su propio trabajo de marketing en medios.
Los pasos anteriores son los pasos para rastrear datos usando la API de Facebook Graph. Si hay deficiencias o explicaciones incorrectas, pídales a los amigos que critiquen y corrijan. :)
