@Este artículo proviene del número público: csdn2299, como si pudieras prestar atención a la academia de programadores de números públicos
Este artículo presenta principalmente la implementación de predicciones y análisis de series temporales en Python utilizando el modelo LSTM. El código de muestra en este artículo es muy detallado y tiene cierto valor de aprendizaje de referencia para el aprendizaje o el trabajo de todos. Aprendamos juntos
Modelo de serie temporal
El análisis de pronóstico de series de tiempo consiste en utilizar las características de un tiempo de evento en el período pasado para predecir las características del evento en el período futuro. Este es un tipo relativamente complejo de problema de modelado predictivo. A diferencia del modelo de análisis de regresión, el modelo de serie temporal depende de la secuencia de eventos. La salida del modelo de entrada después de que el mismo valor de tamaño cambia el orden es diferente.
Tomemos un ejemplo: basándose en los datos de precios de acciones diarios de una acción de los últimos dos años, prediga el cambio en el precio de las acciones de la semana siguiente; prediga la cantidad de personas que consumirán en la tienda la próxima semana en función de la cantidad de personas que desean pasar cada semana en una tienda en los últimos 2 años
Modelos RNN y LSTM
La herramienta más utilizada y potente para los modelos de series temporales es la red neuronal recurrente (RNN). En comparación con las características independientes de los resultados de cálculo de la red neuronal ordinaria, los resultados de cálculo de cada capa oculta del RNN están relacionados con la entrada actual y los resultados de la capa oculta anterior. Mediante este método, los resultados del cálculo RNN tienen las características de memorizar los resultados anteriores.
Una estructura de red RNN típica es la siguiente: la estructura 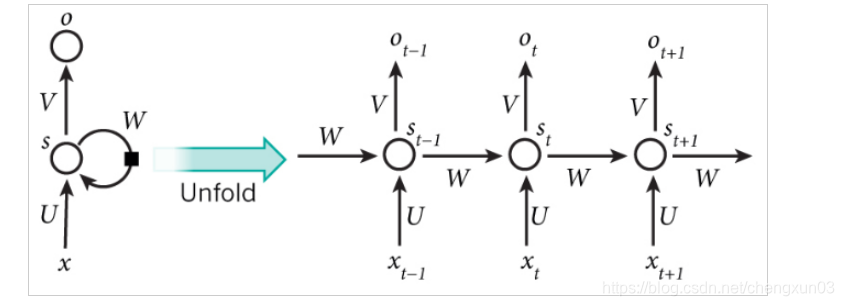
de la derecha se crea para comprender fácilmente la memoria durante el cálculo. En pocas palabras, x es la capa de entrada, o es la capa de salida, s es la capa oculta yt se refiere al número de cálculos; V, W, U son los pesos, donde St = f (U Xt + W St-1), para lograr el propósito de vincular el resultado de entrada actual con el cálculo anterior La
limitación
de RNN : Debido a que el modelo RNN necesita lograr memoria a largo plazo, el cálculo del estado oculto actual debe calcularse con los n cálculos anteriores. Hook, es decir St = f (U Xt + W1 St-1 + W2 St-2 +… + Wn St-n), entonces la cantidad de cálculo aumentará exponencialmente, resultando en un aumento significativo en el tiempo de entrenamiento del modelo, por lo que el modelo RNN es generalmente Utilizado directamente para cálculos de memoria a largo plazo.
Modelo LSTM El modelo
LSTM (memoria de corto plazo) es una variante de RNN, propuesta por primera vez por Juergen Schmidhuber. La estructura de un modelo LSTM clásico es la siguiente: 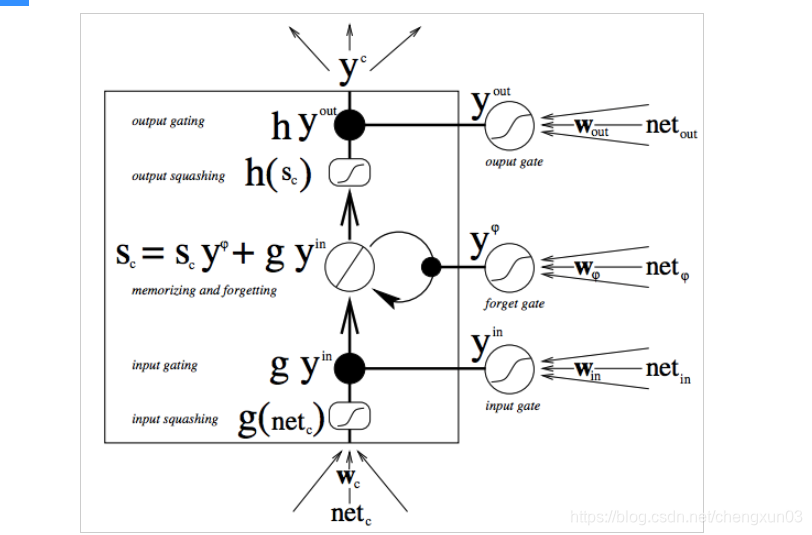
la característica de LSTM es la adición de nodos de válvula de varias capas además de la estructura RNN. Hay 3 tipos de válvulas: puerta de olvido, puerta de entrada y puerta de salida. Estas válvulas se pueden abrir o cerrar, y se usan para juzgar si la salida de memoria de la red modelo (el estado de la red anterior) en esta capa alcanza el umbral para agregarse al cálculo actual de esta capa. Como se muestra en la figura, el nodo de la válvula utiliza la función sigmoidea para calcular el estado de memoria de la red como entrada; si el resultado de la salida alcanza el umbral, la salida de la válvula se multiplica por el resultado del cálculo de la capa actual como la entrada de la siguiente capa (PS: aquí Multiplicación significa multiplicación elemento por elemento en la matriz); si no se alcanza el umbral, se olvida la salida. El peso de cada capa, incluido el nodo de la válvula, se actualiza durante el proceso de entrenamiento de propagación inversa de cada modelo. A continuación se muestra el proceso de cálculo de juicio LSTM más específico: 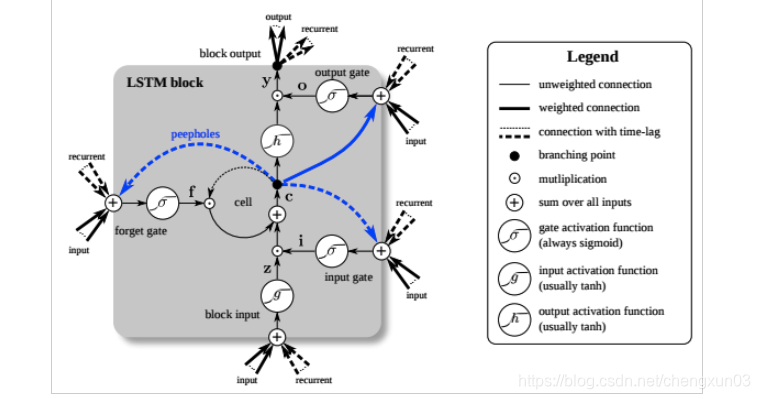
estos nodos de válvula realizan la función de memoria del modelo LSTM. Cuando se abre la válvula, los resultados del entrenamiento del modelo anterior estarán relacionados con el cálculo del modelo actual, y cuando la válvula está cerrada, los resultados del cálculo anterior ya no afectarán el cálculo actual. Por lo tanto, al ajustar la apertura y el cierre de la válvula, podemos lograr el efecto de la secuencia temprana en el resultado final. Y cuando no desee que los resultados anteriores afecten el futuro, como el comienzo de un nuevo párrafo o capítulo en el procesamiento del lenguaje natural, cierre la válvula para
ilustrar cómo funciona la válvula en detalle: el control de la válvula controla la secuencia La primera variable de entrada afecta los resultados del cálculo variable de la cuarta y sexta secuencia.
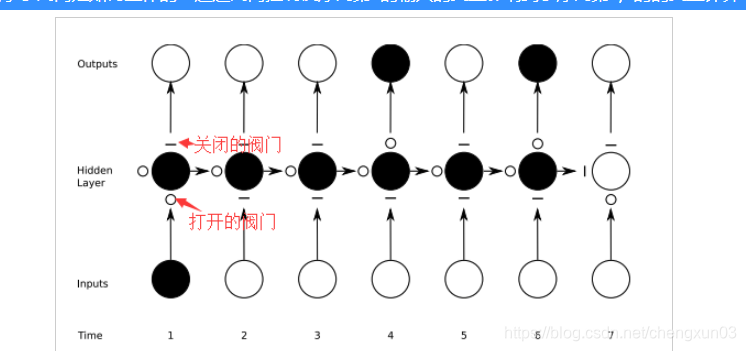
El círculo sólido negro representa que el resultado del cálculo del nodo se envía a la siguiente capa o al siguiente cálculo; el círculo abierto representa que el resultado del cálculo del nodo no se ingresa a la red o no ha recibido una señal de la hora anterior.
Implementación de la construcción del modelo LSTM en Python
Hay muchos paquetes en Python a los que se puede llamar directamente para construir modelos LSTM, como pybrain, kears, tensorflow, cikit-neuralnetwork, etc.
Aquí usamos keras. (PD: ¡Si el sistema operativo usa Linux o Mac, presione Tensorflow!)
Debido a que la capacitación del modelo de red neuronal LSTM se puede optimizar ajustando muchos parámetros, como la función de activación, el número de capas LSTM, las dimensiones variables de entrada y salida, etc., el proceso de ajuste es bastante complicado. Aquí hay un simple ejemplo de aplicación para describir el proceso de construcción de LSTM.
Ejemplos de aplicación
Según el tiempo de consumo histórico de un cliente de una tienda determinada, se estima el tiempo de la visita previa del cliente a la tienda. Los datos específicos son los siguientes:
消费时间
2015-05-15 14:03:51
2015-05-15 15:32:46
2015-06-28 18:00:17
2015-07-16 21:27:18
2015-07-16 22:04:51
2015-09-08 14:59:56
..
..
Operación específica:
- La conversión de los datos originales
primero debe digitalizar los datos del punto de tiempo. La conversión de un tiempo específico en un período de tiempo se utiliza para indicar el intervalo de tiempo entre los dos consumos adyacentes del usuario, y luego importar el modelo para capacitación es un método más común. Los datos convertidos son los siguientes:
消费间隔
0
44
18
0
54
..
..
2. Genere un conjunto de datos de entrenamiento modelo (determine la longitud de la ventana del conjunto de entrenamiento)
. La ventana aquí se refiere a cuántos intervalos de consumo son necesarios para predecir el próximo intervalo de consumo. Aquí usamos primero una longitud de ventana de 3, es decir, usamos t-2, t-1, t intervalos de consumo para el entrenamiento del modelo, y luego usamos intervalos t + 1 para verificar los resultados. El formato del conjunto de datos es el siguiente: X es información de entrenamiento e Y es información de verificación.
PD: También es inapropiado decir que se determina aquí, porque la longitud de la ventana debe ajustarse de acuerdo con los resultados de la verificación del modelo.
X1 X2 X3 Y
0 44 18 0
44 18 0 54
..
..
Nota: La precisión general de la predicción será peor directamente. Puede agrupar el valor pronosticado Y de acuerdo con el valor en varias categorías, y luego usar la etiqueta única para convertirlo en entrenamiento. Por ejemplo, si divide Y en cinco categorías (1: 0-20, 2: 20-40, 3: 40-60, 4: 60-80, 5: 80-100) de acuerdo con el rango de valores, la fórmula anterior se puede transformar en:
X1 X2 X3 Y
0 44 18 0
44 18 0 4
...
Después de que Y se convierte en uno caliente, es
1 0 0 0 0
0 0 0 0 1
...
- Determinación y ajuste de la estructura del modelo de red
Aquí utilizamos la biblioteca de keras de Python. (Los estudiantes que usan Java pueden consultar la biblioteca deeplearning4j). El proceso de capacitación de la red está diseñado para ajustar muchos parámetros: por ejemplo
La función de activación (función de activación) del módulo LSTM debe determinarse (el valor predeterminado es tanh en keras);
Determine la función de activación de la red neuronal artificial totalmente conectada que recibe la salida LSTM (el valor predeterminado es lineal en keras);
Determine la tasa de rechazo de cada capa de nodos de red (para evitar el sobreajuste), aquí establecemos el valor predeterminado en 0.2;
Para determinar el método de cálculo del error, aquí usamos el error cuadrático medio (error cuadrático medio);
Método de actualización iterativa para determinar los parámetros de peso, aquí usamos el algoritmo RMSprop, que generalmente se usa en redes RNN. Determine la época y el tamaño del lote del modelo de capacitación
En términos generales, mientras más capas del módulo LSTM (generalmente no más de 3 capas, es más difícil converger cuando se entrena más), mayor será la capacidad de aprendizaje para el tiempo de alto nivel; Finalmente, se agregará una capa de red neuronal común para reducir la dimensionalidad de los resultados de salida. La estructura típica es la siguiente: 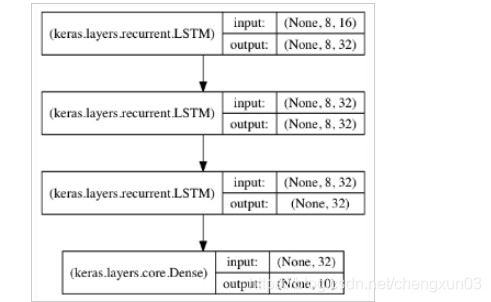
si es necesario entrenar varias secuencias en el mismo modelo, las secuencias se pueden ingresar a módulos LSTM independientes y los resultados de salida se combinan y se ingresan en la capa común. La estructura es la siguiente: 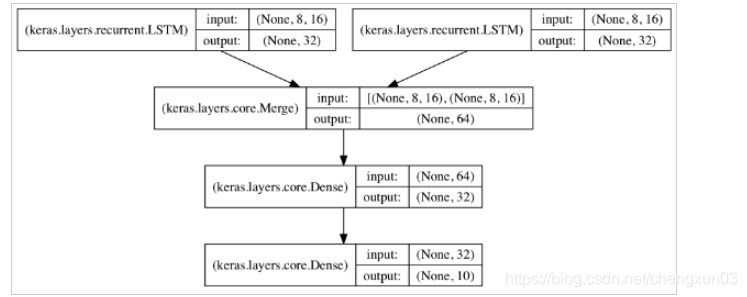
4. Modelo de entrenamiento y predicción de resultados
El conjunto de datos anterior se divide aleatoriamente en un conjunto de entrenamiento y un conjunto de verificación en una proporción de 4: 1, para evitar el sobreajuste. Entrenar a la modelo. Luego importe la columna X de los datos como un parámetro al modelo para obtener el valor predicho, y compare el valor Y real con el modelo.
Código de implementación
La secuencia del intervalo de tiempo se formatea en el formato del conjunto de entrenamiento requerido
import pandas as pd
import numpy as np
def create_interval_dataset(dataset, look_back):
"""
:param dataset: input array of time intervals
:param look_back: each training set feature length
:return: convert an array of values into a dataset matrix.
"""
dataX, dataY = [], []
for i in range(len(dataset) - look_back):
dataX.append(dataset[i:i+look_back])
dataY.append(dataset[i+look_back])
return np.asarray(dataX), np.asarray(dataY)
df = pd.read_csv("path-to-your-time-interval-file")
dataset_init = np.asarray(df) # if only 1 column
dataX, dataY = create_interval_dataset(dataset, lookback=3) # look back if the training set sequence length
La fuente de datos de entrada aquí es un archivo csv, si los datos de entrada provienen de la base de datos, puede consultar aquí
Estructura de red LSTM
import pandas as pd
import numpy as np
import random
from keras.models import Sequential, model_from_json
from keras.layers import Dense, LSTM, Dropout
class NeuralNetwork():
def __init__(self, **kwargs):
"""
:param **kwargs: output_dim=4: output dimension of LSTM layer; activation_lstm='tanh': activation function for LSTM layers; activation_dense='relu': activation function for Dense layer; activation_last='sigmoid': activation function for last layer; drop_out=0.2: fraction of input units to drop; np_epoch=10, the number of epoches to train the model. epoch is one forward pass and one backward pass of all the training examples; batch_size=32: number of samples per gradient update. The higher the batch size, the more memory space you'll need; loss='mean_square_error': loss function; optimizer='rmsprop'
"""
self.output_dim = kwargs.get('output_dim', 8)
self.activation_lstm = kwargs.get('activation_lstm', 'relu')
self.activation_dense = kwargs.get('activation_dense', 'relu')
self.activation_last = kwargs.get('activation_last', 'softmax') # softmax for multiple output
self.dense_layer = kwargs.get('dense_layer', 2) # at least 2 layers
self.lstm_layer = kwargs.get('lstm_layer', 2)
self.drop_out = kwargs.get('drop_out', 0.2)
self.nb_epoch = kwargs.get('nb_epoch', 10)
self.batch_size = kwargs.get('batch_size', 100)
self.loss = kwargs.get('loss', 'categorical_crossentropy')
self.optimizer = kwargs.get('optimizer', 'rmsprop')
def NN_model(self, trainX, trainY, testX, testY):
"""
:param trainX: training data set
:param trainY: expect value of training data
:param testX: test data set
:param testY: epect value of test data
:return: model after training
"""
print "Training model is LSTM network!"
input_dim = trainX[1].shape[1]
output_dim = trainY.shape[1] # one-hot label
# print predefined parameters of current model:
model = Sequential()
# applying a LSTM layer with x dim output and y dim input. Use dropout parameter to avoid overfitting
model.add(LSTM(output_dim=self.output_dim,
input_dim=input_dim,
activation=self.activation_lstm,
dropout_U=self.drop_out,
return_sequences=True))
for i in range(self.lstm_layer-2):
model.add(LSTM(output_dim=self.output_dim,
input_dim=self.output_dim,
activation=self.activation_lstm,
dropout_U=self.drop_out,
return_sequences=True))
# argument return_sequences should be false in last lstm layer to avoid input dimension incompatibility with dense layer
model.add(LSTM(output_dim=self.output_dim,
input_dim=self.output_dim,
activation=self.activation_lstm,
dropout_U=self.drop_out))
for i in range(self.dense_layer-1):
model.add(Dense(output_dim=self.output_dim,
activation=self.activation_last))
model.add(Dense(output_dim=output_dim,
input_dim=self.output_dim,
activation=self.activation_last))
# configure the learning process
model.compile(loss=self.loss, optimizer=self.optimizer, metrics=['accuracy'])
# train the model with fixed number of epoches
model.fit(x=trainX, y=trainY, nb_epoch=self.nb_epoch, batch_size=self.batch_size, validation_data=(testX, testY))
# store model to json file
model_json = model.to_json()
with open(model_path, "w") as json_file:
json_file.write(model_json)
# store model weights to hdf5 file
if model_weight_path:
if os.path.exists(model_weight_path):
os.remove(model_weight_path)
model.save_weights(model_weight_path) # eg: model_weight.h5
return model
Aquí solo escribo sobre la estructura de la red LSTM. En cuanto a cómo normalizar el procesamiento de datos en la estructura requerida por la red y visualizar la comparación estadística de los resultados de la predicción del modelo con los valores reales, debe ajustarlo de acuerdo con la situación real.
Muchas gracias por leer
. Cuando decidí estudiar Python en la universidad, descubrí que me comía una mala base informática. No tenía una calificación académica. Esto
no es nada que hacer. Solo puedo compensarlo, así que comencé mi propio contraataque fuera de la codificación. El camino, continúe aprendiendo los conocimientos básicos de Python, el estudio en profundidad de los conceptos básicos de la computadora, resuelto, si no está dispuesto a ser mediocre, ¡únase a mí en la codificación y continúe creciendo!
De hecho, no solo hay tecnología aquí, sino también cosas más allá de esas tecnologías. Por ejemplo, cómo ser un programador exquisito, en lugar de "seda de gallo", el programador en sí es una existencia noble, ¿no? [Haz clic para unirte] ¡ Quieres ser tú mismo, quieres ser una persona noble, vamos!
