Artículo de navegación
La intención original de la serie de código fuente de Redis es ayudarnos a comprender mejor a Redis y comprender mejor a Redis, pero no es suficiente entenderlo. Se recomienda seguir este artículo para construir el entorno y seguir el código fuente usted mismo Lee conmigo. Como utilicé C hace varios años, algunos errores son inevitables, espero que el lector pueda señalar.
Tema de esta conferencia
En primer lugar, agregaré un poco de conocimiento sobre los punteros en lenguaje C. A continuación, comenzaré a seguir el artículo de ayer sobre el proceso de inicio de redis, de mayor a menor, para evitar caer rápidamente en los detalles.
Comprensión de los punteros
Un puntero en realidad apunta a una dirección de memoria. Este puntero puede ser interpretado arbitrariamente por usted si sabe lo que está almacenado antes y después de esta dirección. Déjame darte un ejemplo:
typedef struct Test_Struct{
int a;
int b;
}Test_Struct;
int main() {
// 1
void *pVoid = malloc(4);
// 2
memset(pVoid,0x01,4);
// 3
int *pInt = pVoid;
// 4
char *pChar = pVoid;
// 5
short *pShort = pVoid;
// 6
Test_Struct *pTestStruct = pVoid;
// 7
printf("address:%p, point to %d\n", pChar, *pChar);
printf("address:%p, point to %d\n", pShort, *pShort);
printf("address:%p, point to %d\n", pInt, *pInt);
printf("address:%p, point to %d\n", pTestStruct, pTestStruct->a);
}
-
Un lugar, asigne un trozo de memoria, 4 bytes, 32 bits; devuelva un puntero a esta área de memoria, para ser precisos, apunte al primer byte, porque la memoria asignada es continua, puede entenderla como una matriz.
La función malloc () asigna bytes de tamaño y devuelve un puntero a la memoria asignada.
-
En dos lugares, llame a memset para establecer los 4 bytes de la memoria apuntados por pVoid a 0x01; de hecho, configure cada byte a 00000001.
Las notas de memset son las siguientes:
NAME memset - fill memory with a constant byte SYNOPSIS #include <string.h> void *memset(void *s, int c, size_t n); DESCRIPTION The memset() function fills the first n bytes of the memory area pointed to by s with the constant byte c.Materiales de referencia: https://www.cnblogs.com/yhlboke-1992/p/9292877.html
Aquí establecemos cada byte en 0x01, y el binario final es en realidad el siguiente:

-
3 lugares, definir un puntero de tipo int, asignarle pVoid, int toma 4 bytes
-
4 lugares, defina el puntero de tipo char, asígnele pVoid, char toma 1 byte
-
5 lugares, defina un puntero de tipo short, asígnele pVoid, short toma 2 bytes
-
En seis lugares, se define un puntero de tipo Test_Struct. Esta es una estructura, similar a una clase de lenguaje de alto nivel. La estructura de esta estructura es la siguiente:
typedef struct Test_Struct{ int a; int b; }Test_Struct;Del mismo modo, le asignamos pVoid.
-
En 7 ubicaciones, las direcciones de varios tipos de punteros y sus valores desreferenciados se imprimen por separado.
El resultado es el siguiente:

El binario de 257 es: 0000 0001 0000 0001
El binario de 16843009 es: 0000 0001 0000 0001 0000 0001 0000 0001
La estructura también es fácil de entender porque esta estructura, el primer atributo a, es de tipo int y ocupa 4 bytes.
Además, todos deben tener en cuenta que las direcciones de puntero que se muestran arriba son exactamente las mismas.
Si puedes entender esta demostración, mira este enlace, creo que entenderá más el puntero:
Operación aritmética del puntero C
Proceso de inicio aproximado del servidor Redis
int main(int argc, char **argv) {
struct timeval tv;
/**
* 1 设置时区等等
*/
setlocale(LC_COLLATE,"");
...
// 2 检查服务器是否以 Sentinel 模式启动
server.sentinel_mode = checkForSentinelMode(argc,argv);
// 3 初始化服务器配置
initServerConfig();
// 4
if (server.sentinel_mode) {
initSentinelConfig();
initSentinel();
}
// 5 检查用户是否指定了配置文件,或者配置选项
if (argc >= 2) {
...
// 载入配置文件, options 是前面分析出的给定选项
loadServerConfig(configfile,options);
sdsfree(options);
}
// 6 将服务器设置为守护进程
if (server.daemonize) daemonize();
// 7 创建并初始化服务器数据结构
initServer();
// 8 如果服务器是守护进程,那么创建 PID 文件
if (server.daemonize) createPidFile();
// 9 为服务器进程设置名字
redisSetProcTitle(argv[0]);
// 10 打印 ASCII LOGO
redisAsciiArt();
// 11 如果服务器不是运行在 SENTINEL 模式,那么执行以下代码
if (!server.sentinel_mode) {
// 从 AOF 文件或者 RDB 文件中载入数据
loadDataFromDisk();
// 启动集群
if (server.cluster_enabled) {
if (verifyClusterConfigWithData() == REDIS_ERR) {
redisLog(REDIS_WARNING,
"You can't have keys in a DB different than DB 0 when in "
"Cluster mode. Exiting.");
exit(1);
}
}
// 打印 TCP 端口
if (server.ipfd_count > 0)
redisLog(REDIS_NOTICE,"The server is now ready to accept connections on port %d", server.port);
} else {
sentinelIsRunning();
}
// 12 运行事件处理器,一直到服务器关闭为止
aeSetBeforeSleepProc(server.el,beforeSleep);
aeMain(server.el);
// 13 服务器关闭,停止事件循环
aeDeleteEventLoop(server.el);
return 0;
}
-
1, 2, 3, como ya se mencionó en el artículo anterior, inicializa principalmente varios parámetros de configuración, como los relacionados con el socket; redis.conf involucrado, aof, rdb, replication, sentinel, etc.; el servidor interno del servidor redis Estructura de datos, como runid, dirección del archivo de configuración, información relacionada con el servidor (32 bits o 64 bits, porque redis se ejecuta directamente en el sistema operativo, en lugar de lenguajes de alto nivel como máquinas virtuales, 32 bits y 64 bits, diferentes La longitud es diferente), nivel de registro, número máximo de clientes, tiempo inactivo máximo de clientes, etc.
-
4 lugares, porque el servidor centinela y el servidor redis común en realidad comparten el mismo código, por lo tanto, al comenzar aquí, depende de si se inicia el servidor centinela o el servidor redis ordinario. Si se envía centinela, configure la configuración relacionada con el centinela
-
5 lugares, verifique si el archivo de configuración se especifica en los parámetros de la línea de comando al inicio, si se especifica, prevalecerá la configuración del archivo de configuración
-
6 lugares, establecidos como demonio
-
7 lugares, de acuerdo con la configuración anterior, inicializan el servidor redis
-
8 lugares, cree un archivo pid, la ruta predeterminada general: /var/run/redis.pid, esto se puede configurar en redis.conf, como:
pidfile "/var/run/redis_6379.pid" -
9 lugares, establezca el nombre para el proceso del servidor
-
10 lugares, logo impreso
-
11. Si no se envía en modo centinela, cargue un archivo aof o rdb
-
A los 12, salta a un bucle sin fin, comienza a esperar para recibir conexiones y procesa las solicitudes de los clientes; mientras tanto, ejecuta periódicamente tareas en segundo plano, como eliminar claves caducadas, etc.
-
A las 13, el servidor se apaga. En términos generales, si no va aquí, generalmente queda atrapado en un bucle infinito a las 12; solo en ciertos escenarios, después de cambiar una parada de variable global a verdadera, el programa saltará de 12. Bucle sin fin, y luego vino aquí.
El proceso de inicialización del servidor redis
Esta sección es principalmente para refinar la operación anterior del paso 7, que es inicializar el servidor redis. Esta función, ubicada en redis.c, se llama initServer y hace muchas cosas, que se explicarán secuencialmente.
Establecer la función de procesamiento de señal global
// 设置信号处理函数
signal(SIGHUP, SIG_IGN);
signal(SIGPIPE, SIG_IGN);
setupSignalHandlers();
Lo más importante es la última línea:
void setupSignalHandlers(void) {
// 1
struct sigaction act;
/* When the SA_SIGINFO flag is set in sa_flags then sa_sigaction is used.
* Otherwise, sa_handler is used. */
sigemptyset(&act.sa_mask);
act.sa_flags = 0;
// 2
act.sa_handler = sigtermHandler;
// 3
sigaction(SIGTERM, &act, NULL);
return;
}
Tres lugares, establecidos: cuando se recibe la señal SIGTERM, se usa actpara procesar la señal, el acto se define en 1, es una variable local, tiene un campo, se asigna en 2 lugares, este es un puntero de función. El puntero de función es similar a la referencia de un método estático en java, por qué es estático, porque la implementación de tales métodos no requiere un nuevo objeto; en el lenguaje C, todos los métodos son de nivel superior, cuando se llama, no se necesita un nuevo objeto ; Entonces, desde este punto de vista, el puntero de función del lenguaje C es similar a la referencia del método estático en java.
Podemos mirar 2 lugares,
act.sa_handler = sigtermHandler;
Este sigtermHandler debe ser una función global, vea cómo se define:
// SIGTERM 信号的处理器
static void sigtermHandler(int sig) {
REDIS_NOTUSED(sig);
redisLogFromHandler(REDIS_WARNING,"Received SIGTERM, scheduling shutdown...");
// 打开关闭标识
server.shutdown_asap = 1;
}
Esta función es abrir la variable global shutdown_asap del servidor. Este campo se usa en los siguientes lugares:
serverCron in redis.c
/* We received a SIGTERM, shutting down here in a safe way, as it is
* not ok doing so inside the signal handler. */
// 服务器进程收到 SIGTERM 信号,关闭服务器
if (server.shutdown_asap) {
// 尝试关闭服务器
if (prepareForShutdown(0) == REDIS_OK) exit(0);
// 如果关闭失败,那么打印 LOG ,并移除关闭标识
redisLog(REDIS_WARNING,"SIGTERM received but errors trying to shut down the server, check the logs for more information");
server.shutdown_asap = 0;
}
La primera línea del código anterior, que identifica la ubicación de este código, es la función serverCron en redis.c. Esta función es la función de ejecución periódica del servidor redis, similar al ScheduledThreadPoolExecutor en java. Después de detectar que server.shutdown_asap está activado, cerrará el servidor.
Luego, después de recibir la señal anterior, la acción a realizar está terminada, luego, cuál es la señal, la señal es en realidad un medio de comunicación entre procesos bajo Linux, como kill -9, enviará un comando SIGKILL al pid correspondiente ; Cuando se está ejecutando el primer plano de redis, presiona ctrl + c, de hecho, también envía una señal, la señal es SIGINT, el valor es 2. Puedes ver la imagen a continuación:
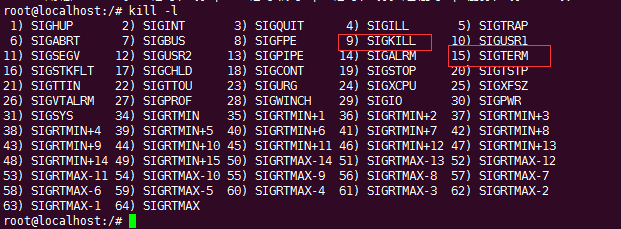
Entonces, cuál es la señal que registramos anteriormente, es: SIGTERM, 15. Es decir, cuando presionamos kill -15, esta señal se activará.
Sobre la diferencia entre kill 9 y kill 15, puedes leer este blog:
La diferencia entre Linux kill -9 y kill -15
Abrir syslog
// 设置 syslog
if (server.syslog_enabled) {
openlog(server.syslog_ident, LOG_PID | LOG_NDELAY | LOG_NOWAIT,
server.syslog_facility);
}
Este es el registro del sistema que envía el registro al sistema Linux. Puede ver la descripción de la función de registro abierto:
enviar mensajes al registrador del sistema
Esta sensación no se usa mucho, puedes verificar:
El registro de Syslog de Redis no se imprime fuera del proceso de exploración.
Inicializar algunas propiedades del redisServer actual
// 初始化并创建数据结构
server.current_client = NULL;
// 1
server.clients = listCreate();
server.clients_to_close = listCreate();
server.slaves = listCreate();
server.monitors = listCreate();
server.slaveseldb = -1; /* Force to emit the first SELECT command. */
server.unblocked_clients = listCreate();
server.ready_keys = listCreate();
server.clients_waiting_acks = listCreate();
server.get_ack_from_slaves = 0;
server.clients_paused = 0;
De hecho, no hay nada que decir. Como puede ver, por ejemplo, este server.clients, el servidor es una variable global que mantiene los diversos estados del servidor redis actual. Los clientes se utilizan para guardar el cliente actual conectado al servidor redis , El tipo es una lista vinculada:
// 一个链表,保存了所有客户端状态结构
list *clients; /* List of active clients */
Entonces, aquí está realmente llamando listCreate(), creando una lista enlazada vacía y luego asignando valores a los clientes.
Otros atributos son similares.
Crear un grupo de cadenas constante para reutilizar
Como todos sabemos, cuando redis devuelve una respuesta, generalmente es una oración: "+ OK" y similares. Esta cadena, si va a una nueva cada vez que responde, es un desperdicio demasiado, así que, simplemente, redis almacena en caché estas cadenas de uso común.
void createSharedObjects(void) {
int j;
// 常用回复
shared.crlf = createObject(REDIS_STRING,sdsnew("\r\n"));
shared.ok = createObject(REDIS_STRING,sdsnew("+OK\r\n"));
shared.err = createObject(REDIS_STRING,sdsnew("-ERR\r\n"));
...
// 常用错误回复
shared.wrongtypeerr = createObject(REDIS_STRING,sdsnew(
"-WRONGTYPE Operation against a key holding the wrong kind of value\r\n"));
...
}
Esto es lo mismo que Java, que almacena en caché los literales de cadena, todo para mejorar el rendimiento; en Java, ¿también no almacena en caché enteros de hasta 128, ¿verdad?
Ajuste la cantidad máxima de archivos que el proceso puede abrir
El servidor generalmente está en un entorno en línea real. Si necesita lidiar con una alta concurrencia, puede haber decenas de millones de clientes y un proceso en el servidor para establecer una conexión TCP. En este momento, generalmente necesita ajustar el proceso. El número máximo de archivos abiertos (los sockets también son archivos).
Antes de leer el código fuente de redis, sé que la forma de modificar la cantidad máxima de archivos que puede abrir un proceso es a través de ulimit. Específicamente, puede ver los siguientes dos enlaces:
Resumen de número de identificador de archivo máximo de Linux
Sin embargo, en este código fuente, se encontró otra forma:
- API para obtener el valor límite actual del recurso especificado
#define RLIMIT_NOFILE 5 /* max number of open files */
struct rlimit {
rlim_t rlim_cur;
rlim_t rlim_max;
};
struct rlimit limit;
getrlimit(RLIMIT_NOFILE,&limit)
El código anterior obtiene el tamaño límite de recursos del valor de NOFILE (el número máximo de archivos en el proceso) en el sistema actual.
A través de man getrlimit (necesita instalar primero, método de instalación :) yum install man-pages.noarch, puede ver:

-
setrlimit puede establecer el límite relevante de recursos
limit.rlim_cur = f; limit.rlim_max = f; setrlimit(RLIMIT_NOFILE,&limit)
Crear estructuras de datos relacionadas con el bucle de eventos
La estructura del circulador de eventos es la siguiente:
/*
* State of an event based program
*
* 事件处理器的状态
*/
typedef struct aeEventLoop {
// 目前已注册的最大描述符
int maxfd; /* highest file descriptor currently registered */
// 目前已追踪的最大描述符
int setsize; /* max number of file descriptors tracked */
// 用于生成时间事件 id
long long timeEventNextId;
// 最后一次执行时间事件的时间
time_t lastTime; /* Used to detect system clock skew */
// 已注册的文件事件
aeFileEvent *events; /* Registered events */
// 已就绪的文件事件
aeFiredEvent *fired; /* Fired events */
// 时间事件
aeTimeEvent *timeEventHead;
// 事件处理器的开关
int stop;
// 多路复用库的私有数据
void *apidata; /* This is used for polling API specific data */
// 在处理事件前要执行的函数
aeBeforeSleepProc *beforesleep;
} aeEventLoop;
El código para inicializar la estructura de datos anterior está en: aeCreateEventLoop en redis.c
En la estructura anterior, los principales son:
-
En apidata, se usa principalmente para almacenar los datos relevantes de la biblioteca multiplex. Cada vez que se llama a la biblioteca multiplex para seleccionar, si encuentra que ocurre un evento listo io, se almacenará en el atributo activado.
Por ejemplo, select es una implementación de multiplexación en la versión anterior del kernel de Linux en Linux. En redis, el código es el siguiente:
static int aeApiPoll(aeEventLoop *eventLoop, struct timeval *tvp) { ... // 1 retval = select(eventLoop->maxfd+1, &state->_rfds,&state->_wfds,NULL,tvp); if (retval > 0) { for (j = 0; j <= eventLoop->maxfd; j++) { ... // 2 eventLoop->fired[numevents].fd = j; eventLoop->fired[numevents].mask = mask; numevents++; } } return numevents; }Parte omitida del código. Entre ellos, 1 lugar selecciona, este paso es similar a la operación de selección de nio en java; 2 lugares llenan los descriptores de archivo devueltos por select al atributo activado.
-
Además, mencionamos que redis tiene algunas tareas en segundo plano, como limpiar claves caducadas, esto no se hace de la noche a la mañana; cada vez que la tarea en segundo plano se ejecuta periódicamente, limpiará una parte, y la tarea en segundo plano aquí está realmente en la estructura de datos anterior Evento de tiempo.
// 时间事件 aeTimeEvent *timeEventHead;
Asignar espacio de memoria para 16 bases de datos
server.db = zmalloc(sizeof(redisDb) * server.dbnum);
Abra el puerto de escucha y escuche las solicitudes.
/* Open the TCP listening socket for the user commands. */
// 打开 TCP 监听端口,用于等待客户端的命令请求
listenToPort(server.port, server.ipfd, &server.ipfd_count)
Aquí es donde se abre el puerto habitual 6379.
Inicializar la estructura de datos correspondiente a 16 bases de datos.
/* Create the Redis databases, and initialize other internal state. */
// 创建并初始化数据库结构
for (j = 0; j < server.dbnum; j++) {
server.db[j].dict = dictCreate(&dbDictType, NULL);
server.db[j].expires = dictCreate(&keyptrDictType, NULL);
server.db[j].blocking_keys = dictCreate(&keylistDictType, NULL);
server.db[j].ready_keys = dictCreate(&setDictType, NULL);
server.db[j].watched_keys = dictCreate(&keylistDictType, NULL);
server.db[j].eviction_pool = evictionPoolAlloc();
server.db[j].id = j;
server.db[j].avg_ttl = 0;
}
La estructura de datos de db es la siguiente:
typedef struct redisDb {
// 数据库键空间,保存着数据库中的所有键值对
dict *dict; /* The keyspace for this DB */
// 键的过期时间,字典的键为键,字典的值为过期事件 UNIX 时间戳
dict *expires; /* Timeout of keys with a timeout set */
// 正处于阻塞状态的键
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP) */
// 可以解除阻塞的键
dict *ready_keys; /* Blocked keys that received a PUSH */
// 正在被 WATCH 命令监视的键
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
struct evictionPoolEntry *eviction_pool; /* Eviction pool of keys */
// 数据库号码
int id; /* Database ID */
// 数据库的键的平均 TTL ,统计信息
long long avg_ttl; /* Average TTL, just for stats */
} redisDb;
Aquí puede ver que la clave con el tiempo de caducidad establecido, además de estar almacenada en el atributo dict, también agregará un registro al diccionario de caducidad.
caduca clave del diccionario: puntero a la clave de ejecución; valor: tiempo de caducidad.
Crear e inicializar estructuras de datos relacionadas con pub / sub
// 创建 PUBSUB 相关结构
server.pubsub_channels = dictCreate(&keylistDictType, NULL);
server.pubsub_patterns = listCreate();
Inicializar algunas propiedades estadísticas.
// serverCron() 函数的运行次数计数器
server.cronloops = 0;
// 负责执行 BGSAVE 的子进程的 ID
server.rdb_child_pid = -1;
// 负责进行 AOF 重写的子进程 ID
server.aof_child_pid = -1;
aofRewriteBufferReset();
// AOF 缓冲区
server.aof_buf = sdsempty();
// 最后一次完成 SAVE 的时间
server.lastsave = time(NULL); /* At startup we consider the DB saved. */
// 最后一次尝试执行 BGSAVE 的时间
server.lastbgsave_try = 0; /* At startup we never tried to BGSAVE. */
server.rdb_save_time_last = -1;
server.rdb_save_time_start = -1;
server.dirty = 0;
resetServerStats();
/* A few stats we don't want to reset: server startup time, and peak mem. */
// 服务器启动时间
server.stat_starttime = time(NULL);
// 已使用内存峰值
server.stat_peak_memory = 0;
server.resident_set_size = 0;
// 最后一次执行 SAVE 的状态
server.lastbgsave_status = REDIS_OK;
server.aof_last_write_status = REDIS_OK;
server.aof_last_write_errno = 0;
server.repl_good_slaves_count = 0;
updateCachedTime();
Establecer el puntero de función correspondiente al evento de tiempo
/* Create the serverCron() time event, that's our main way to process
* background operations. */
// 为 serverCron() 创建时间事件
if (aeCreateTimeEvent(server.el, 1, serverCron, NULL, NULL) == AE_ERR) {
redisPanic("Can't create the serverCron time event.");
exit(1);
}
Aquí, serverCron es una función, y serverCron se ejecutará cada vez que se active un evento de tiempo en el ciclo posterior.
Puede ver el comentario en inglés aquí, el autor también mencionó que esta es la forma principal de manejar las tareas en segundo plano.
Esto también se analizará en el futuro.
Establecer el controlador de conexión correspondiente al evento de conexión
aeCreateFileEvent(server.el, server.ipfd[j], AE_READABLE, acceptTcpHandler, NULL)
El acceptTcpHandler aquí es la función para manejar la nueva conexión:
void acceptTcpHandler(aeEventLoop *el, int fd, void *privdata, int mask) {
int cport, cfd, max = MAX_ACCEPTS_PER_CALL;
char cip[REDIS_IP_STR_LEN];
REDIS_NOTUSED(el);
REDIS_NOTUSED(mask);
REDIS_NOTUSED(privdata);
while (max--) {
// accept 客户端连接
cfd = anetTcpAccept(server.neterr, fd, cip, sizeof(cip), &cport);
if (cfd == ANET_ERR) {
if (errno != EWOULDBLOCK)
redisLog(REDIS_WARNING,
"Accepting client connection: %s", server.neterr);
return;
}
// 为客户端创建客户端状态(redisClient)
acceptCommonHandler(cfd, 0);
}
}
Crear un archivo
Si aof está abierto, debe crear un archivo aof.
if (server.aof_state == REDIS_AOF_ON) {
server.aof_fd = open(server.aof_filename,
O_WRONLY | O_APPEND | O_CREAT, 0644);
}
Las pocas tareas restantes que no están involucradas por el momento
// 如果服务器以 cluster 模式打开,那么初始化 cluster
if (server.cluster_enabled) clusterInit();
// 初始化复制功能有关的脚本缓存
replicationScriptCacheInit();
// 初始化脚本系统
scriptingInit();
// 初始化慢查询功能
slowlogInit();
// 初始化 BIO 系统
bioInit();
No podemos explicar los anteriores por el momento, solo mírelos primero.
En este punto, la inicialización del servidor redis básicamente ha terminado.
Resumen
Hay muchos contenidos en esta conferencia, principalmente en el proceso de inicio de redis, hay muchas cosas que hacer. Espero haberlo dejado claro. Entre ellos, los que están conectados al procesador solo se explican de manera aproximada, y continuaré más adelante. Gracias a todos.