Resolviendo la mediana
Tenemos el siguiente conjunto de datos de edad:
La edad de 2 empleados es 17 La edad de
4 empleados es 28 La edad de
1 empleados es 18
2 La edad de 2 empleados es 31 La edad de
3 empleados es 21 La edad de
1 empleados es 33
La edad de 1 empleados es 26
2 La edad de los empleados es 34 La edad de
1 empleados es 26 La edad de
3 empleados es 37 La edad de
1 empleados es 39 La edad de
3 empleados es 43 La edad de
2 empleados es 40
- Cree una matriz de edad, establezca el número de personas sin edad en 0
>> f_abs = [2 1 0 0 3 0 0 1 0 1 0 4 0 2 0 1 2 0 0 3 0 1 2 0 0 3];
- Crea una matriz para almacenar la edad
>> bins = [17:43];
- Crea una matriz, repitiendo cada elemento por frecuencia
raw = [];
Procedimiento completo:
f_abs = [2 1 0 0 3 0 0 1 0 1 0 4 0 2 0 1 2 0 0 3 0 1 2 0 0 3];
bins = [17:43];
raw = [];
for i = 1:length(f_abs)
if f_abs(i) > 0
new = bins(i) * ones(1,f_abs(i));
else
new = [];
end
raw = [raw,new];
end
ave = mean(raw)%计算平均值
md = median(raw)%计算中位数
sigma = std(raw)%计算标准偏差
Trazado de histograma de frecuencia
- Paso 1: calcular el área
area = sum(f_abs);%计算面积
- Calcular la relación de frecuencia
scaled = f_abs/area;%计算比例
Completa:
f_abs = [2 1 0 0 3 0 0 1 0 1 0 4 0 0 2 0 1 2 0 0 3 0 1 2 0 0 3];
bins = [17:43];
raw = [];
for i = 1:length(f_abs)
if f_abs(i) > 0
new = bins(i) * ones(1,f_abs(i));
else
new = [];
end
raw = [raw,new];
end
area = sum(f_abs);%计算面积
scaled = f_abs/area;%计算比例
bar(bins,scaled),xlabel('年龄'),ylabel('频数比例');
Imagen:

La distribución en este ejemplo está más dispersa, veamos otro ejemplo:
f_abs = [2 1 0 0 5 4 6 7 8 6 4 3 2 2 1 0 0 1];
bins = [17:34];
raw = [];
for i = 1:length(bins)
if f_abs(i) > 0
new = ones(1,f_abs(i))*bins(i);
else
new = [];
end
raw = [raw,new];
end
avr = mean(raw)
media = median(raw)
sigma1 = std(raw)
Esta vez, la distribución de edad es 17~34intermedia, y la desviación estándar es mucho menor, trazamos el histograma de distribución de frecuencia:

f_abs = [2 1 0 0 5 4 6 7 8 6 4 3 2 2 1 0 0 1];
bins = [17:34];
raw = [];
for i = 1:length(bins)
if f_abs(i) > 0
new = ones(1,f_abs(i))*bins(i);
else
new = [];
end
raw = [raw,new];
end
avr = mean(raw);
media = median(raw);
sigma1 = std(raw);
area = f_abs/sum(f_abs);
bar(bins,area),xlabel('年龄'),ylabel('频数比例')
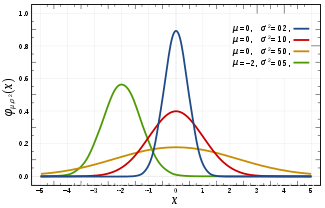
Esto es algo similar a la curva de distribución gaussiana, por lo tanto, cuando los datos se ajustan a la distribución gaussiana, la desviación estándar se puede usar para describir los datos y determinar la probabilidad de caer en ciertos datos.
La desviación estándar está representada por este símbolo: la

media está representada por este símbolo:

entonces la probabilidad de que la curva caiga en el siguiente rango son:

la desviación estándar y la media en el ejemplo anterior son:
avr =
24.6538
sigma1 =
3.3307
La 68%edad aproximada cae dentro de una desviación estándar de la media, es decir, aver-sigma~aver+sigmaentre y más amplia, 96%la edad caerá dentro de dos desviaciones estándar de la media ...
