Desembalaje y agrupación
El protocolo TCP puede dividir los datos que se transmitirán en varios paquetes de datos y enviarlos al host remoto bajo la premisa de garantizar el orden de transmisión de los paquetes de datos y volver a ensamblarlos en el original.
Los ejemplos son los siguientes:
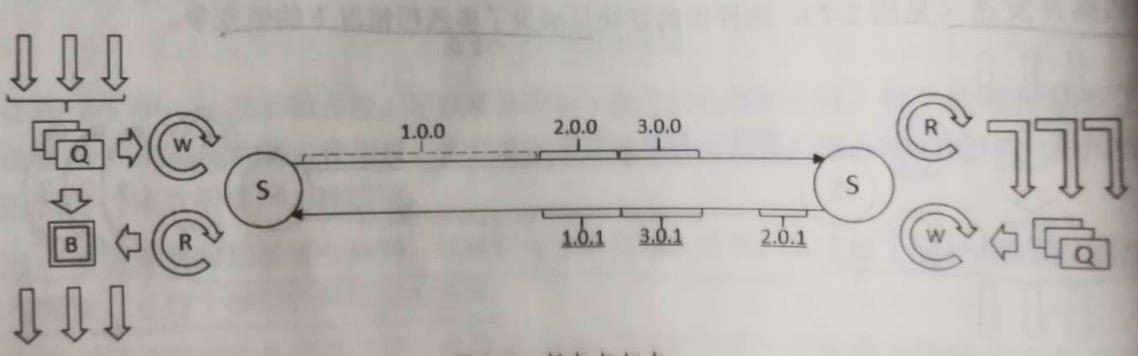
Cuando el paquete 1.0.0 es muy grande, encontrará que la transmisión del paquete de datos 2.0.0 se retrasa.Si la transmisión del paquete de datos 1.0.0 falla, se enviará toda la solicitud.
Para evitar la situación anterior, dividiremos los paquetes 1.0.0 en paquetes más pequeños y los pondremos en la cola de envío, y ensamblaremos y restauraremos estos paquetes cuando se reciban. El efecto es el siguiente.
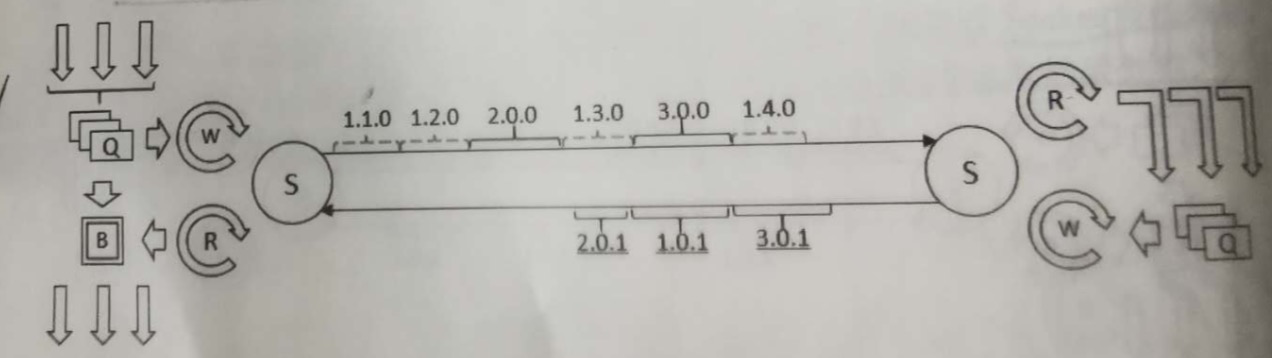
Como se muestra en la figura, dividimos el 1.0.0 original en 1.1.0 + 1.2.0 + 1.3.0 + 1.4.0, para que otros paquetes de datos tengan la oportunidad de insertarse en él para su transmisión sin esperar la totalidad La transferencia de datos solicitada está completa. Esta mejora es aplicable a escenarios donde la transmisión está restringida y la equidad debe ser considerada. Además, si una solicitud de un determinado paquete de datos falla durante la transmisión, puede continuar transmitiendo desde el paquete de datos fallido, que es adecuado para escenarios en los que se requiere reanudar la transmisión.
Romper y pegarse
El protocolo TCP dividirá o fusionará los datos a transmitir de acuerdo con el tamaño del paquete (algoritmo de Nagle). Por lo tanto, el mismo paquete de datos TCP puede contener el contenido de múltiples paquetes de datos autodefinidos, los paquetes de datos pequeños pueden enviarse al mismo tiempo y los paquetes de datos grandes se dividen y envían.
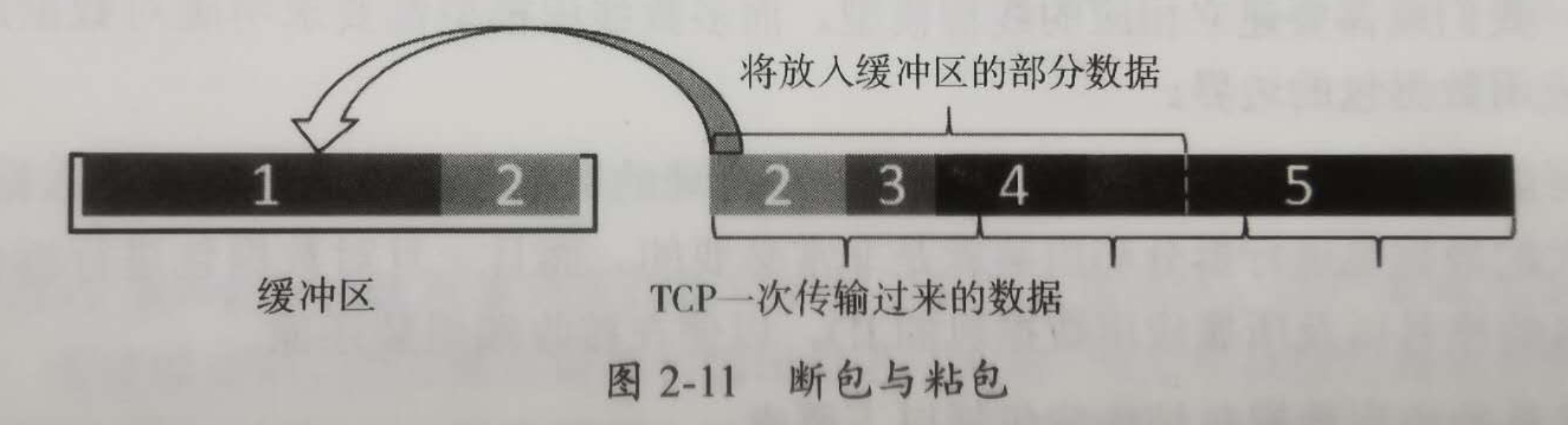
Como se muestra en la figura: el búfer es un paquete de datos completo 1 y solo la mitad del paquete de datos de la aplicación 2. La conexión TCP está transmitiendo los paquetes de datos de la aplicación 2, 3, 4 y 5, que se dividen en 3 paquetes de datos TCP, divididos en 3 Tiempos
La primera vez que la aplicación lee datos del búfer es solo el paquete 1 y la mitad del paquete 2. Independientemente de la situación de división, el paquete 2 está roto, lo que se denomina paquete roto.
Al leer desde el búfer por segunda vez, se leerá la segunda mitad del paquete de datos de la aplicación 2, parte de los paquetes de datos de la aplicación 3, 4 y parte del paquete de datos de la aplicación 5. Los paquetes de datos de la aplicación 3 y 4 están completos, pero parece que el paquete de datos 4 está atascado detrás del paquete de datos 3 y se llama paquete fijo.
Cuando una aplicación lee datos de un socket, en realidad lee los datos del búfer del sistema operativo al búfer de la aplicación. Por lo tanto, incluso si usamos el algoritmo TCP NODELAY para prohibir que TCP aplique el algoritmo Nagle para fusionar y enviar paquetes de datos, no hay garantía de que el receptor no se adhiera al paquete.
La tecnología de paquetes puede resolver el problema anterior: agregue encabezado de datos y marca de cola de datos a los datos para aclarar el comienzo y el final de cada paquete de datos.
Estructura del paquete
- ID de paquete: ID del paquete al que pertenece.
- Número de serie: el número de serie del subcontrato.
- Tamaño de paquete: la longitud de datos de este paquete.
- Segmento de datos: contenido de datos real.