entorno de entorno de despliegue de datos grandes capítulo --Hadoop pseudo-distribuido para construir
En primer lugar, la fase preparatoria
- 1, Hadoop-xxxtar.gz (versión pero aquí libremente recomiendan el uso de la versión 2.7.x, después de todo, esta es la versión estable, después de enfrentarse a algunas dependencias entre los otros componentes también son mejores)
Descargar el sitio web oficial https: / /hadoop.apache.org/old/releases.html
clic aquí para descargar binaria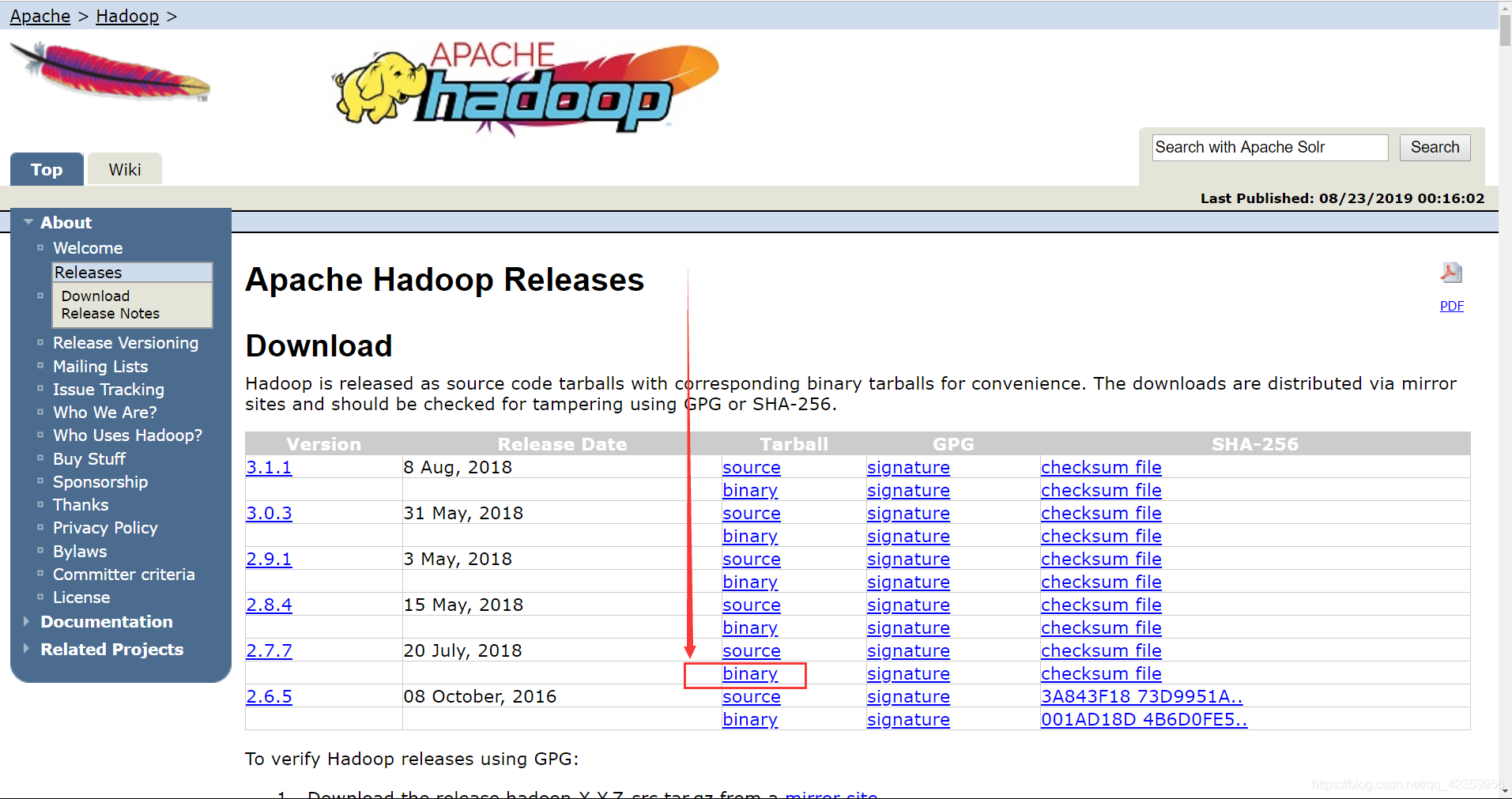

elección fuente de Tsinghua descarga, por lo que la velocidad de descarga será más rápida. - 2, JDK-xxxxx-linux- x64.tar.gz (JDK de Java archivo)
bajar la dirección del sitio web oficial: https: //www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
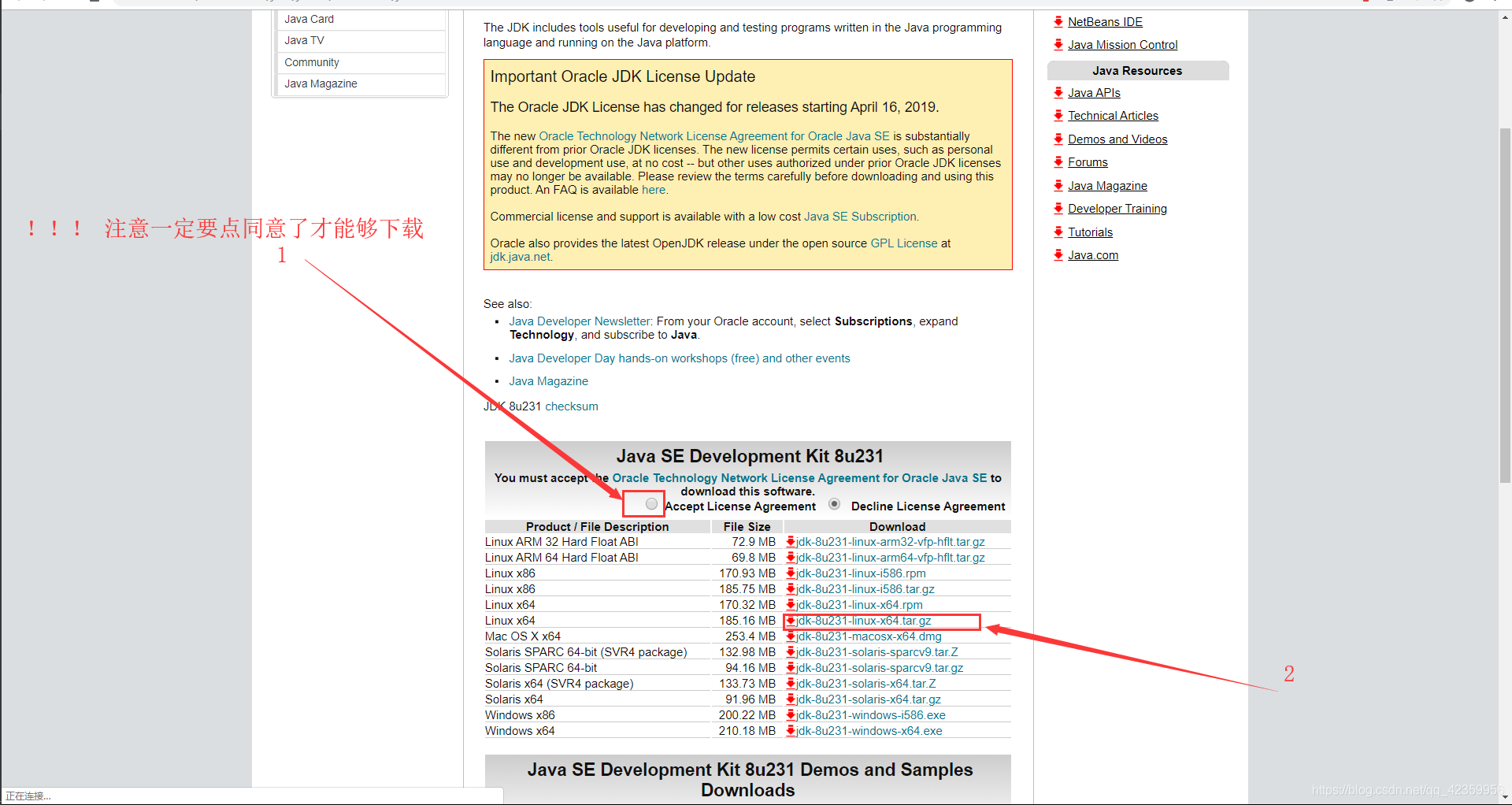
En segundo lugar, la etapa de carga de archivos
Prólogo: El lector por defecto instalado dos de las siguientes herramientas:
- 1, utilizando herramientas conectadas máquina virtual Xshell Ubuntu
(1) Vmvare en máquina virtual Ubuntu para abrir el primer paso
(2) utilizando el comando ifconfig para ver la dirección IP de la máquina virtual
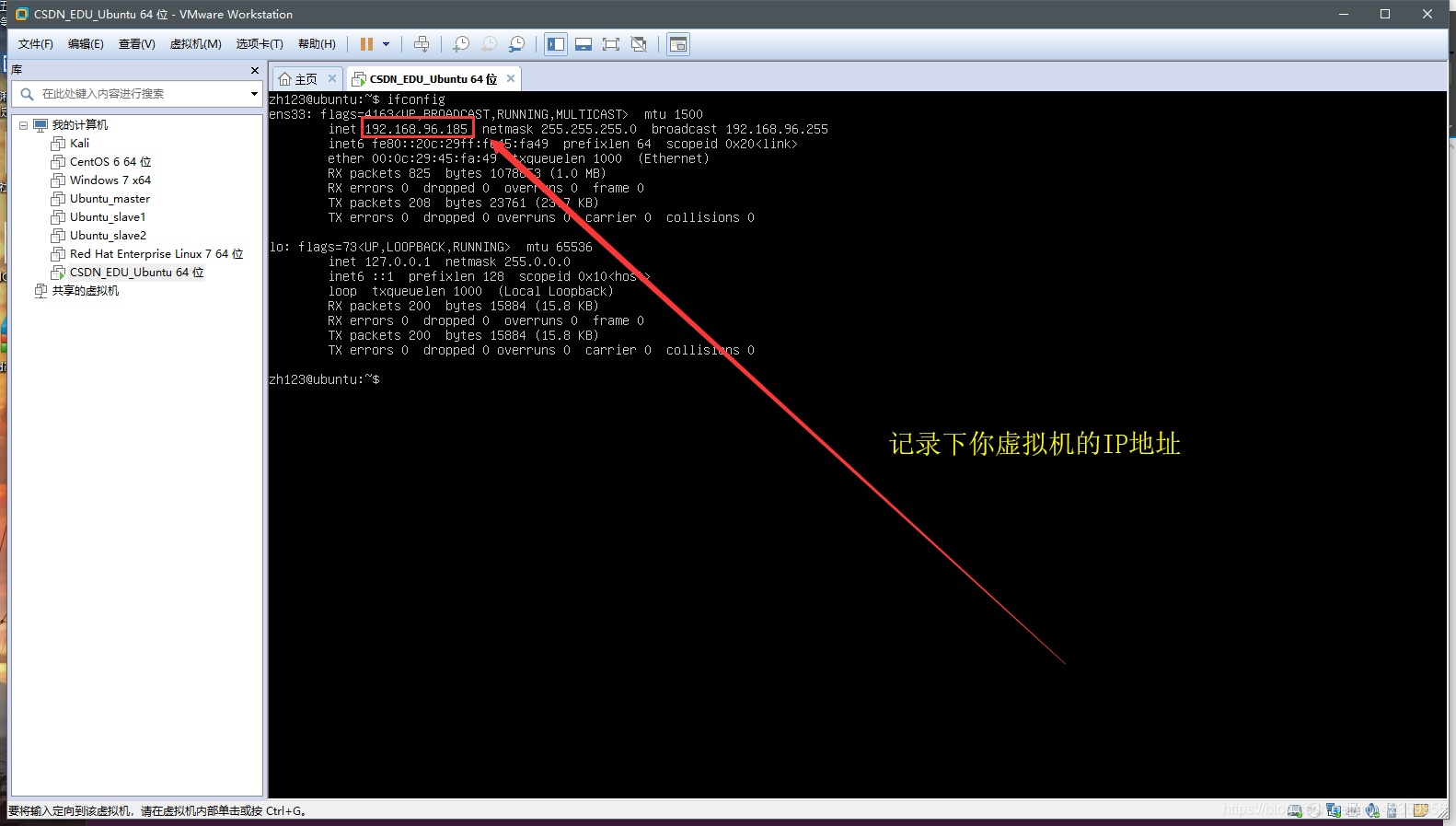
Figura I puede conocer la dirección IP de esta máquina virtual que es 192.168. el primero registrado 96.185 IP
(3) aplicación Xshell abierta, haga clic en Nueva conexión
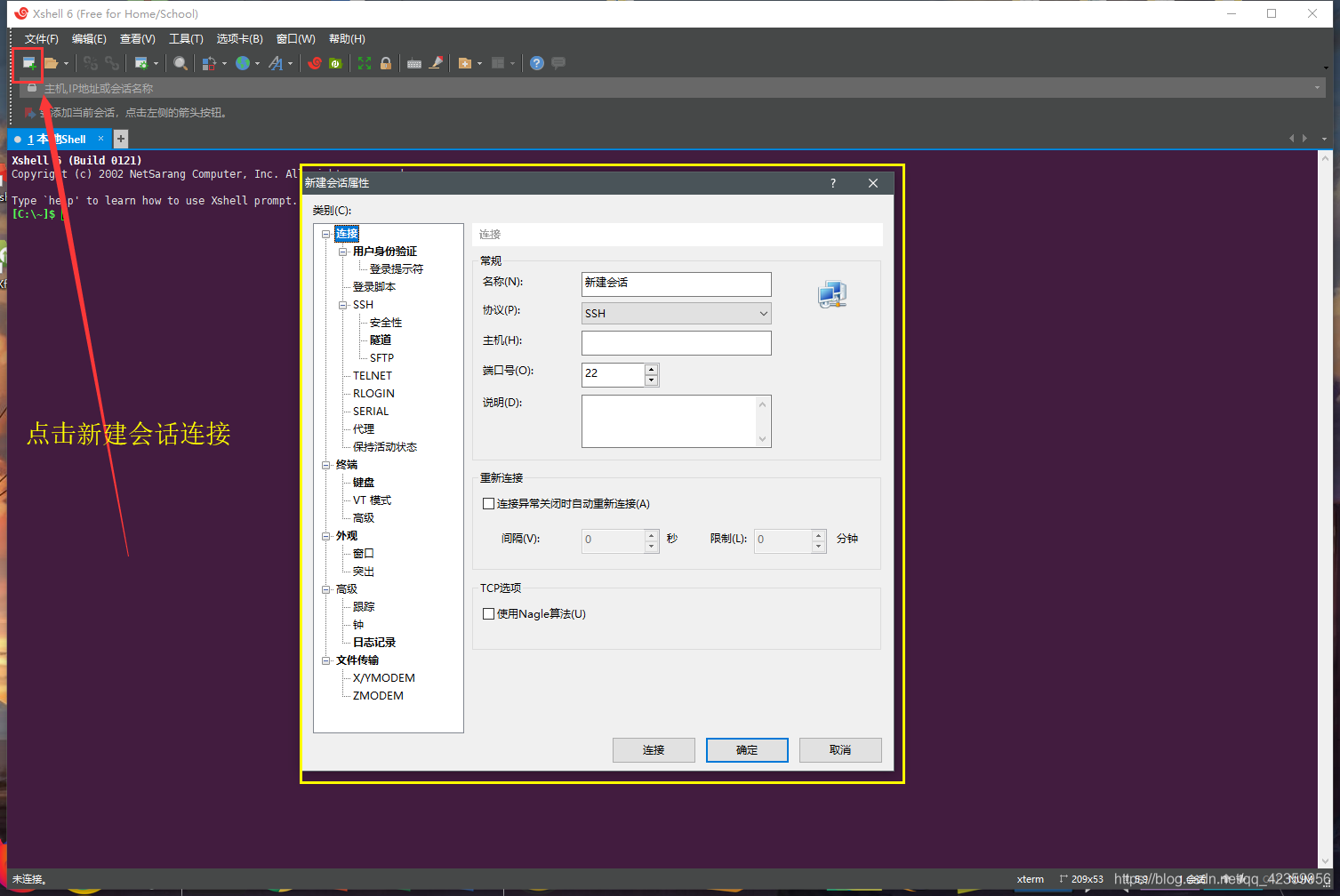
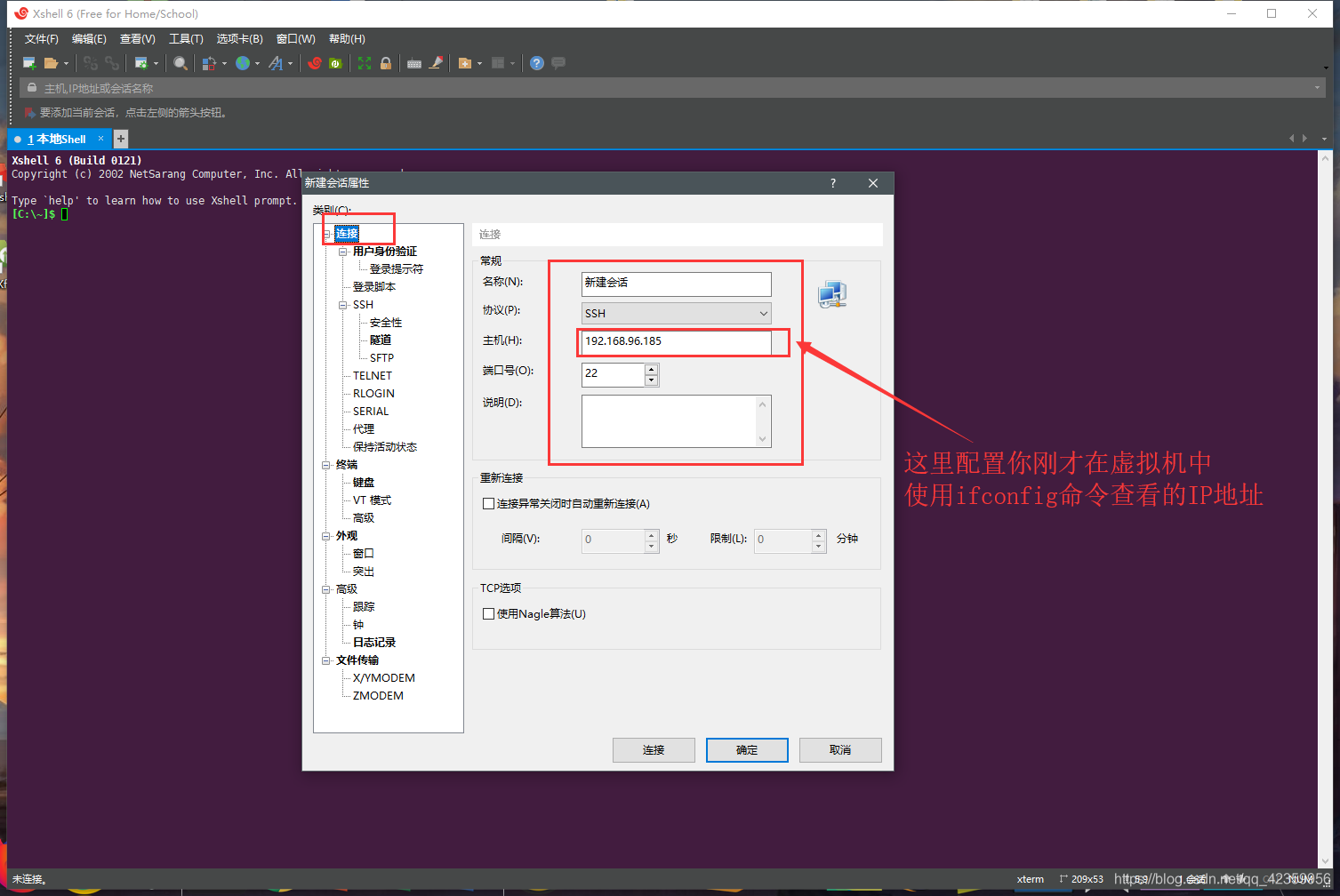
(4) de relleno en la dirección IP que acaba de grabar en el host
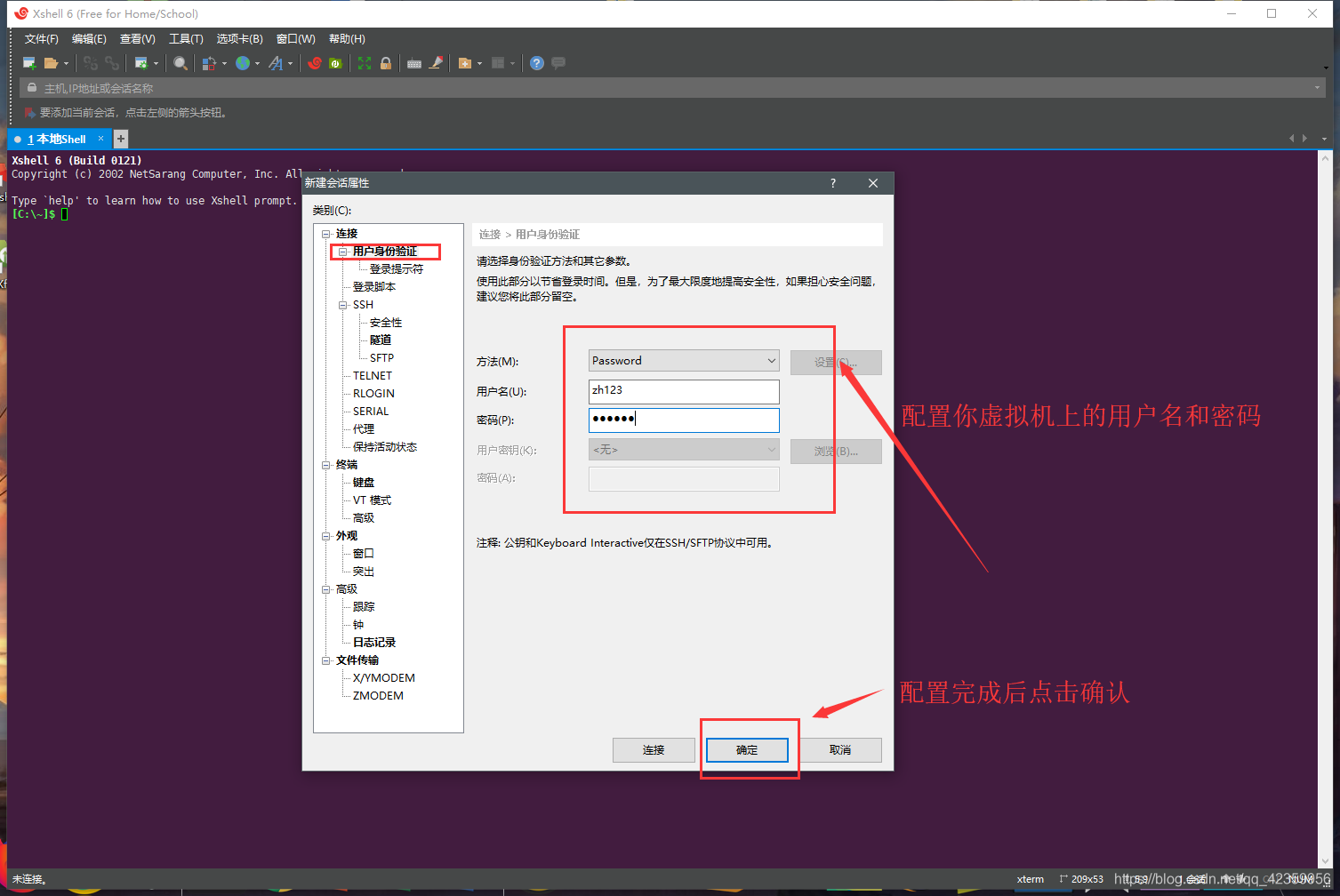
(5) haga clic en la autenticación de usuarios, configurar virtual nombre de usuario y la contraseña de la máquina virtual
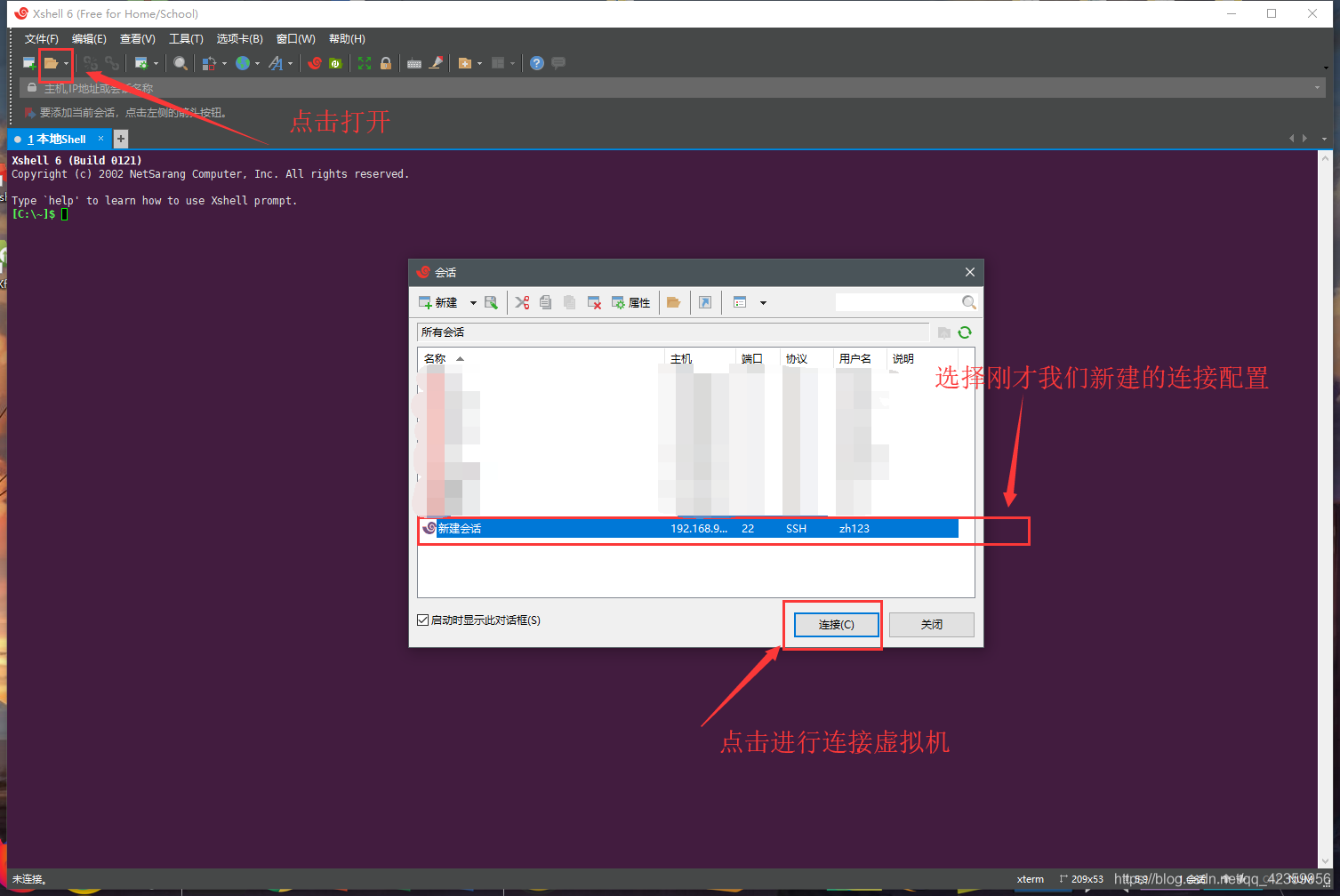
( 6) Haga clic para abrir una conexión, sólo tienes que seleccionar la nueva conexión, y luego conectar la máquina virtual
Haga clic en Guardar conexión de clave pública
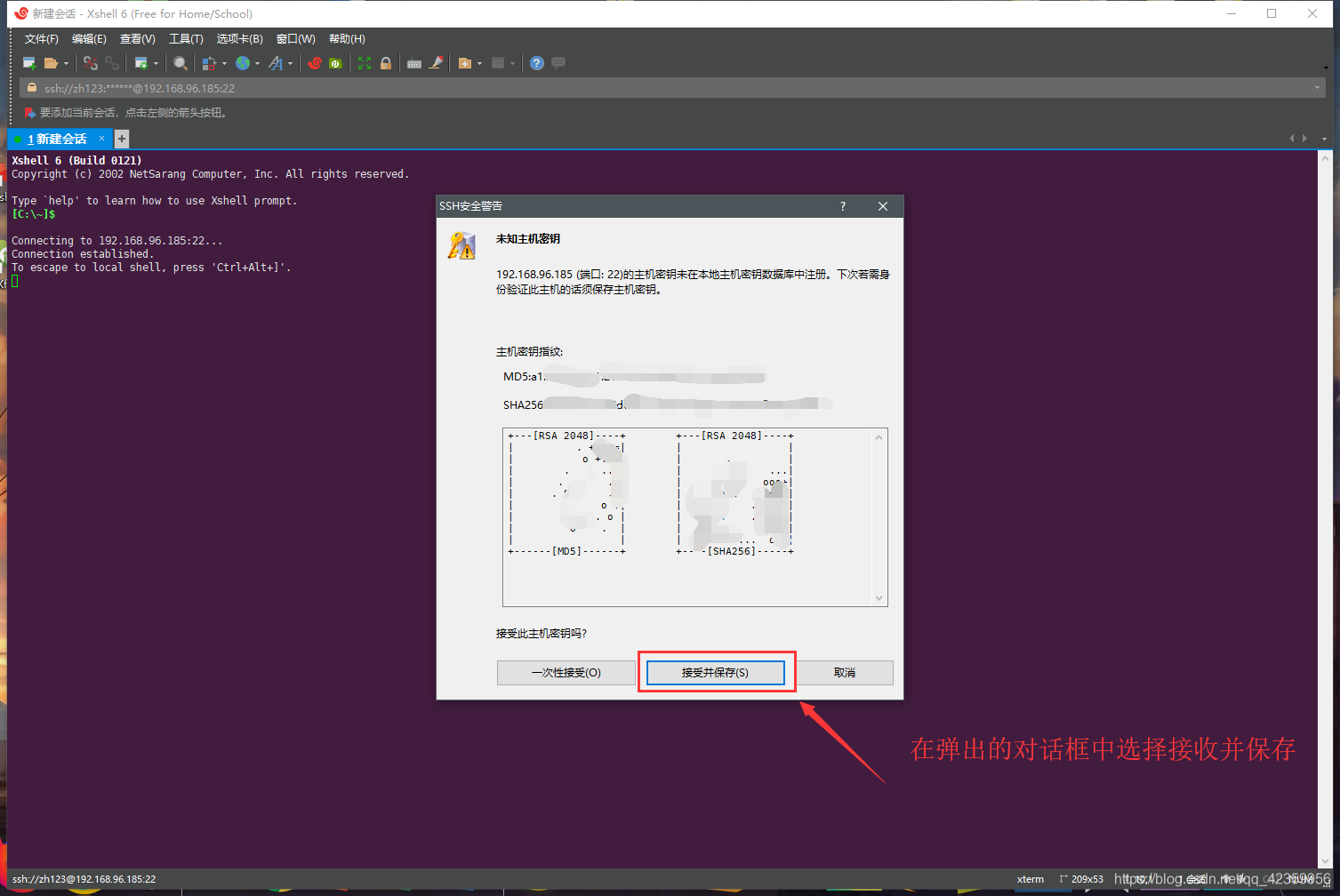
(7) aparece como se muestra en la imagen siguiente es una conexión exitosa (en este caso es posible que tengamos que preguntarse por qué el color con el autor no es lo mismo, no hay una relación, puede ajustar su propio color de fuente y fondo de la terminal)
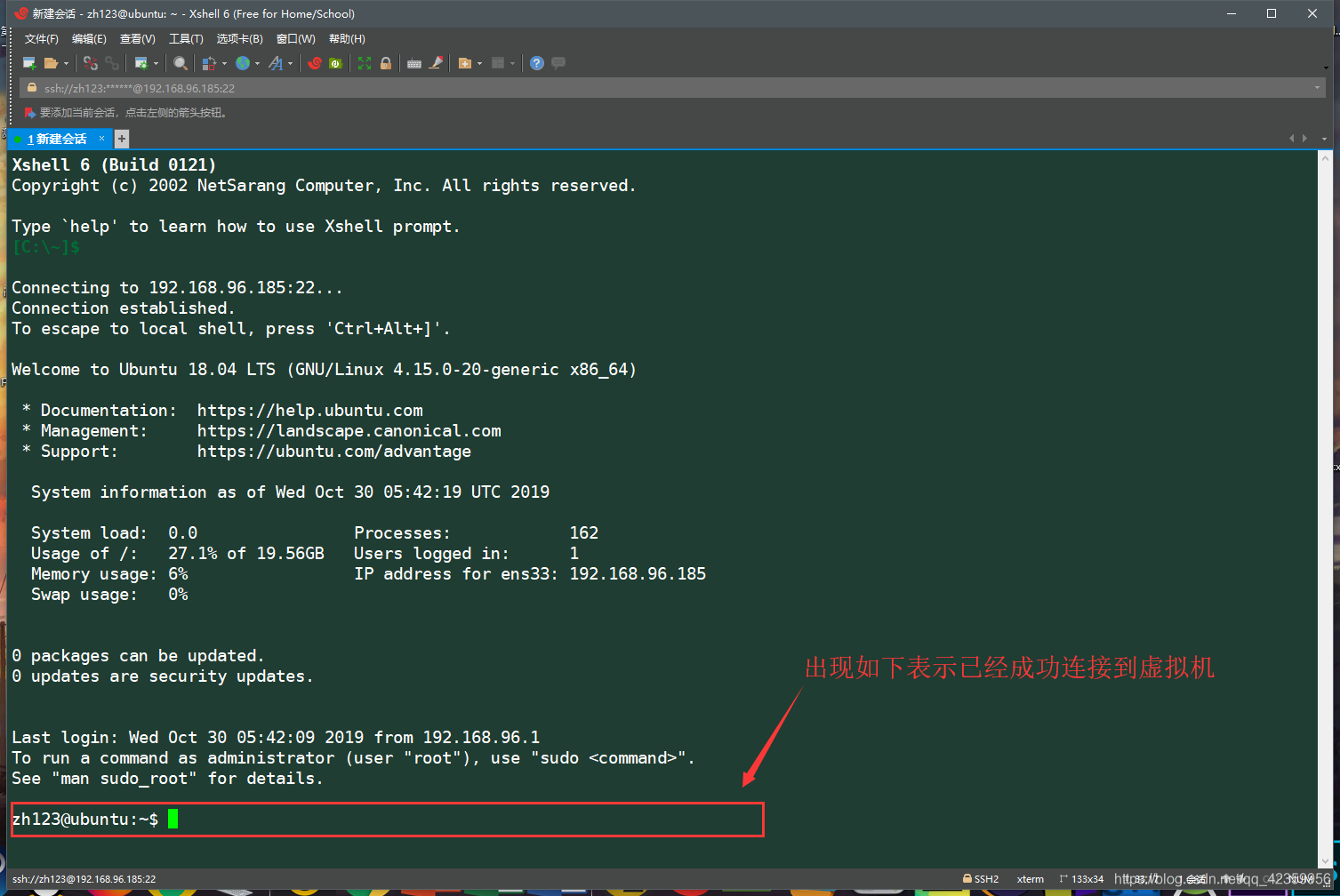
- 2, descargar Xftp en hadoop de Windows y el paquete de instalación del JDK subido a la máquina virtual de Ubuntu
(1) Haga clic en este botón verde Xftp Xshell
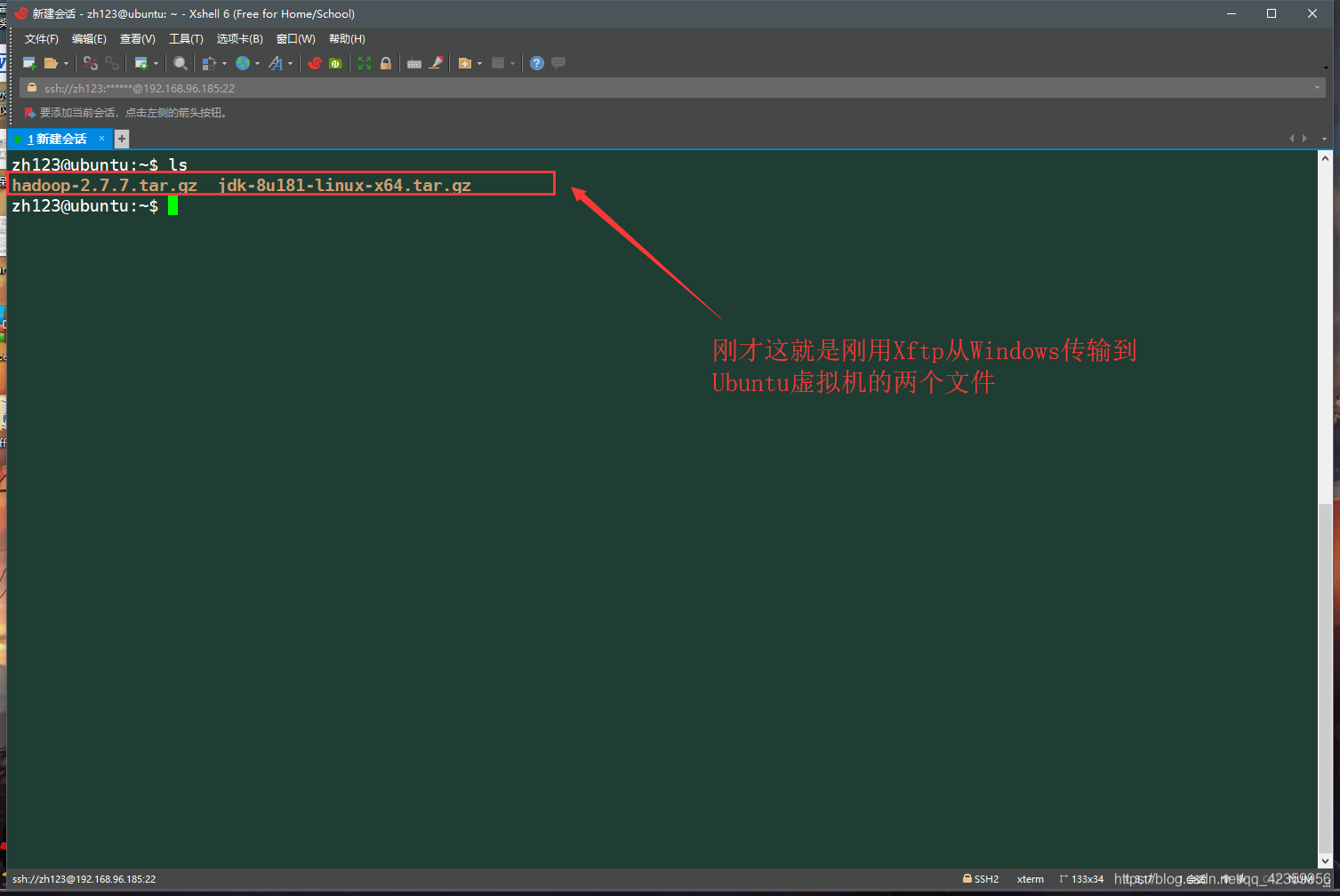
(2) para seleccionar los archivos correspondientes de arrastrar y soltar de Windows (cargar) para subir a la máquina virtual de Ubuntu en
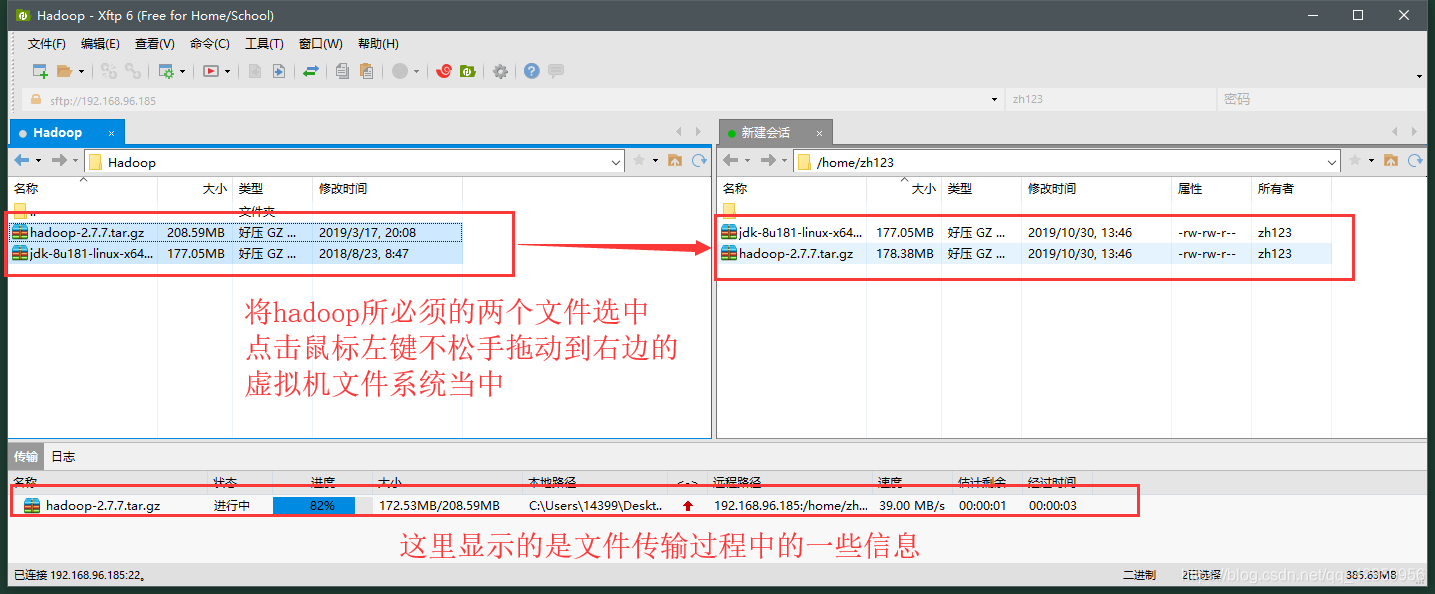
(3) subido al retorno a los dos documentos en la vista sólo subir Xshell
En tercer lugar, configure Hadoop
- 1, la instalación y la configuración del JDK (porque hadoop utilizando Java como un desarrollo, por lo que la operación depende hadoop con el entorno Java, es esencial para instalar el JDK)
(1) Nuevo directorio opt en el directorio inicial del usuario actual (nos referiremos a este directorio recién creado como el directorio de instalación de todos los componentes principales de datos)

(2) Extraiga el archivo en el JDK sólo el nuevo directorio opt

(3) usando cd ~ comando / opt para entrar sólo el nuevo directorio

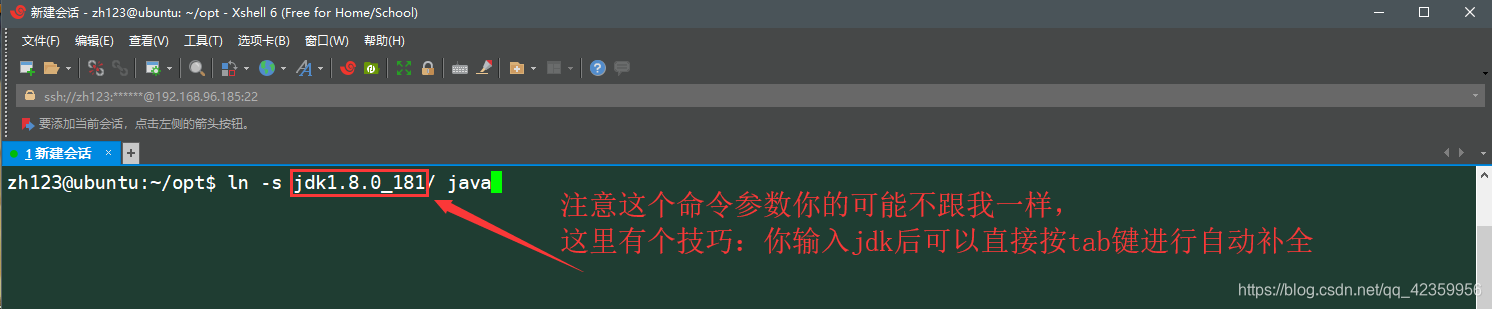
(4) el uso "ln -s" comando para crear un enlace simbólico se acaba de extraer el archivo JDK
(5) usando vim ~ / .bashrc de comandos para introducir las variables de entorno Modificar usuario (puede ser un poco difícil si el primer contacto con el lector de comando vim para operar, cuidadosamente ver una captura de pantalla de la operación)

después de entrar en i teclado realiza cambios en el modo de edición de inserción (después de pulsar la esquina inferior izquierda aparecerá -INSERT- palabras para que pueda editar este archivo)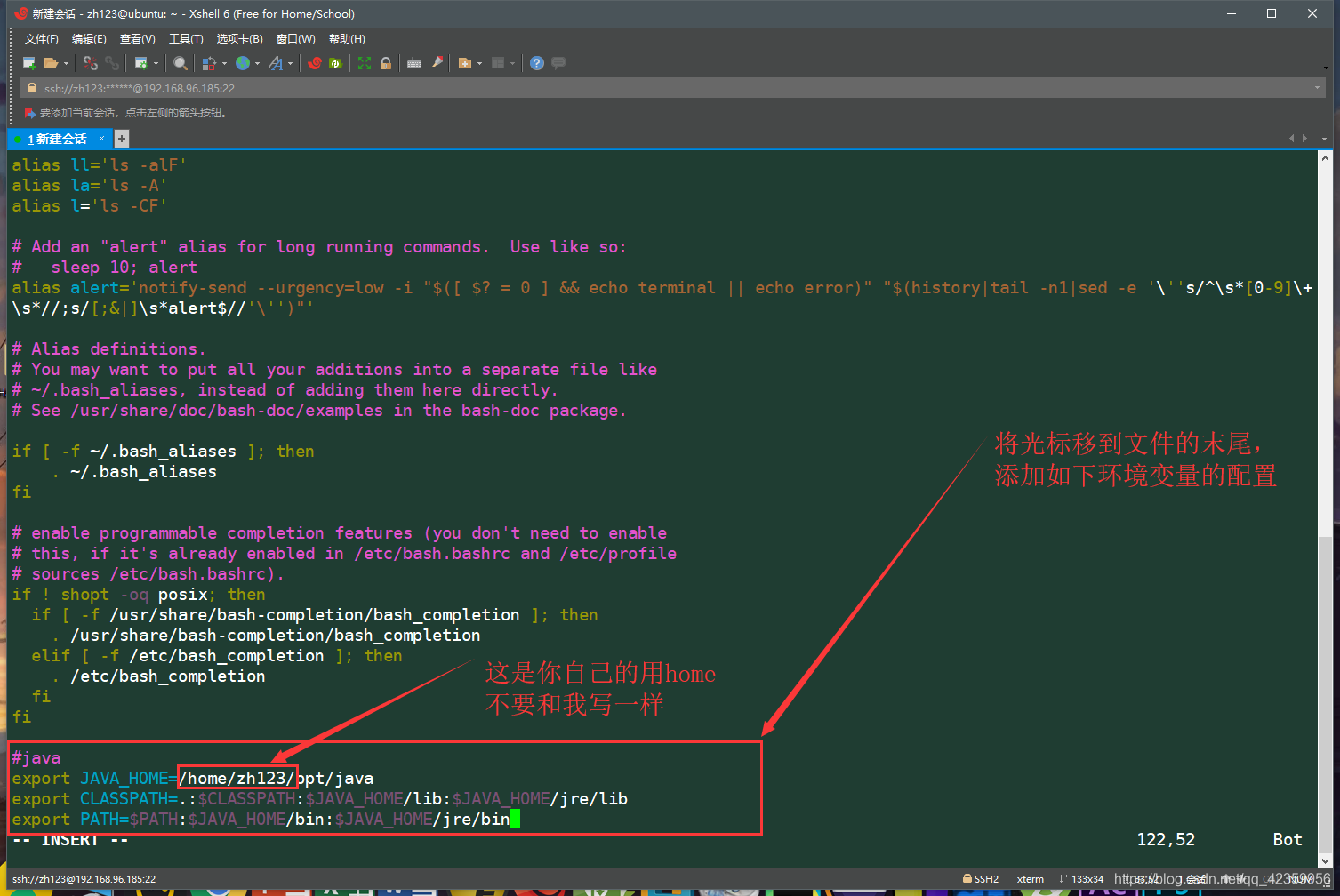



(6) Guardar y salir en la fuente de entrada de línea de comandos ~ / .bashrc fuente de configuración de actualización por lo que sólo surte efecto

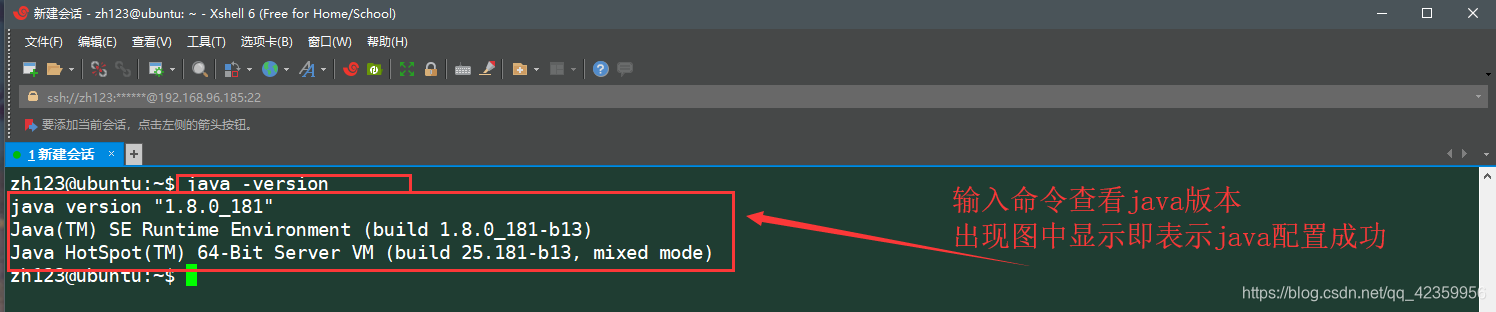
(7) entran en la prueba de comando java -version si la configuración de JDK
- 2, la instalación Hadoop y la configuración (la acumulación Hadoop tres modos [modo autónomo, el patrón pseudo-distribución, el modo de clúster] se lleva a cabo aquí para construir un patrón pseudo-distribución)
(1) usando el alquitrán -zxvf hadoop-xxxtar.gz -C ~ / opt hadoop archivo para extraer el directorio opt

directorio opt (2) cd ~ / opt y luego procede a crear la conexión metal blando hadoop ln -s archivo de comandos
(3) vim ~ / .bashrc modificar las variables de entorno de usuario y luego editar las variables de entorno de java delanteros después de la adición se muestra en el contenido de la imagen
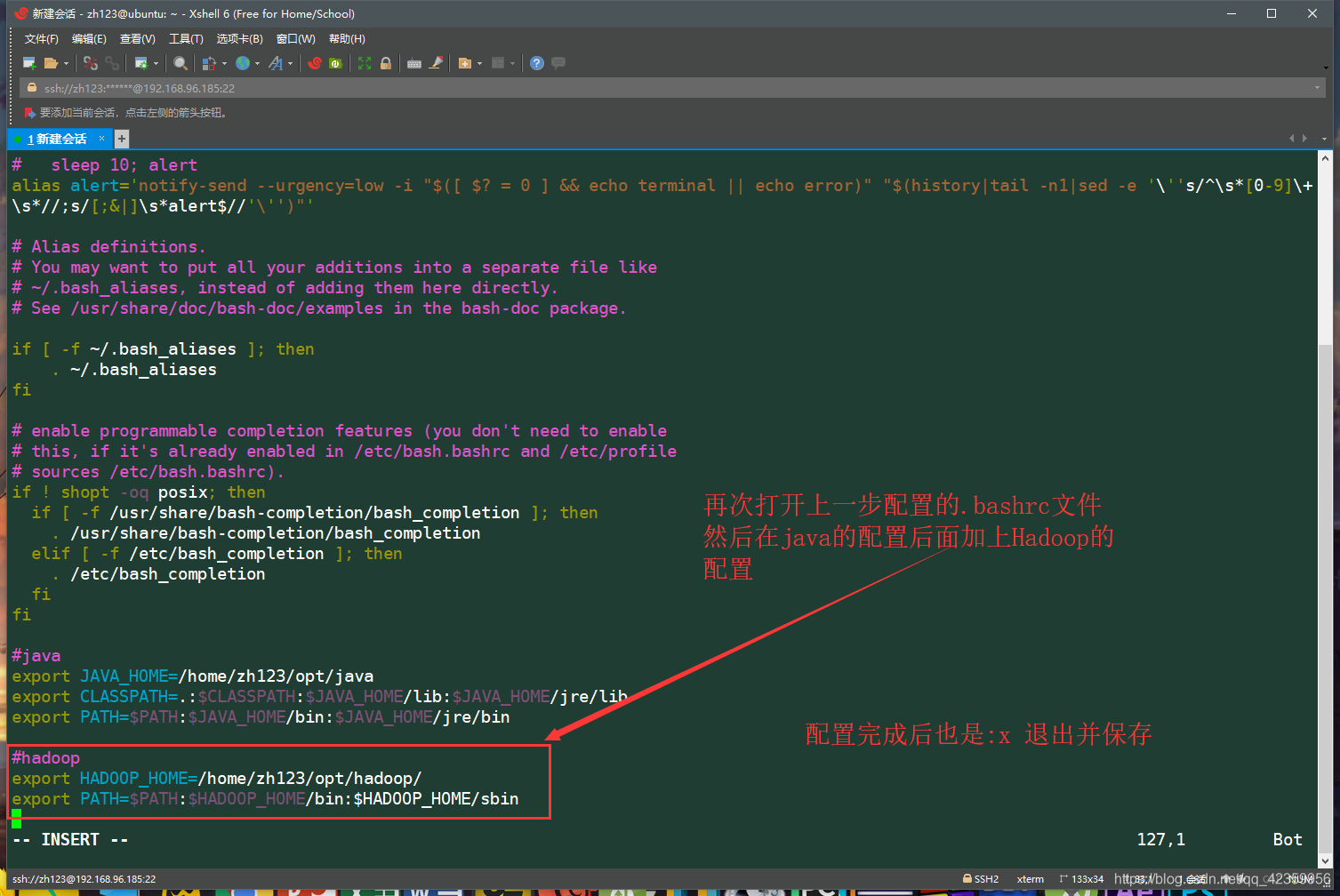
para guardar y volver salida a la interfaz de línea de comandos
de configuración de origen (4) source ~ / .bashrc por lo que sólo la actualización tiene efecto

(5) conectado a la clave pública utilizando ssh-keygen -t rsa ssh generada en
(6) cat ~ / .ssh / id_rsa.pub >> ~ / .ssh / authorized_keys la clave pública generada acaba de escribir en el archivo especificado de entre configuración de ssh
(7) en el directorio de perfil hadoop

(8) editar vim hadoop-env después de entrar en el archivo .sh figura configurado para guardar y pulse salida
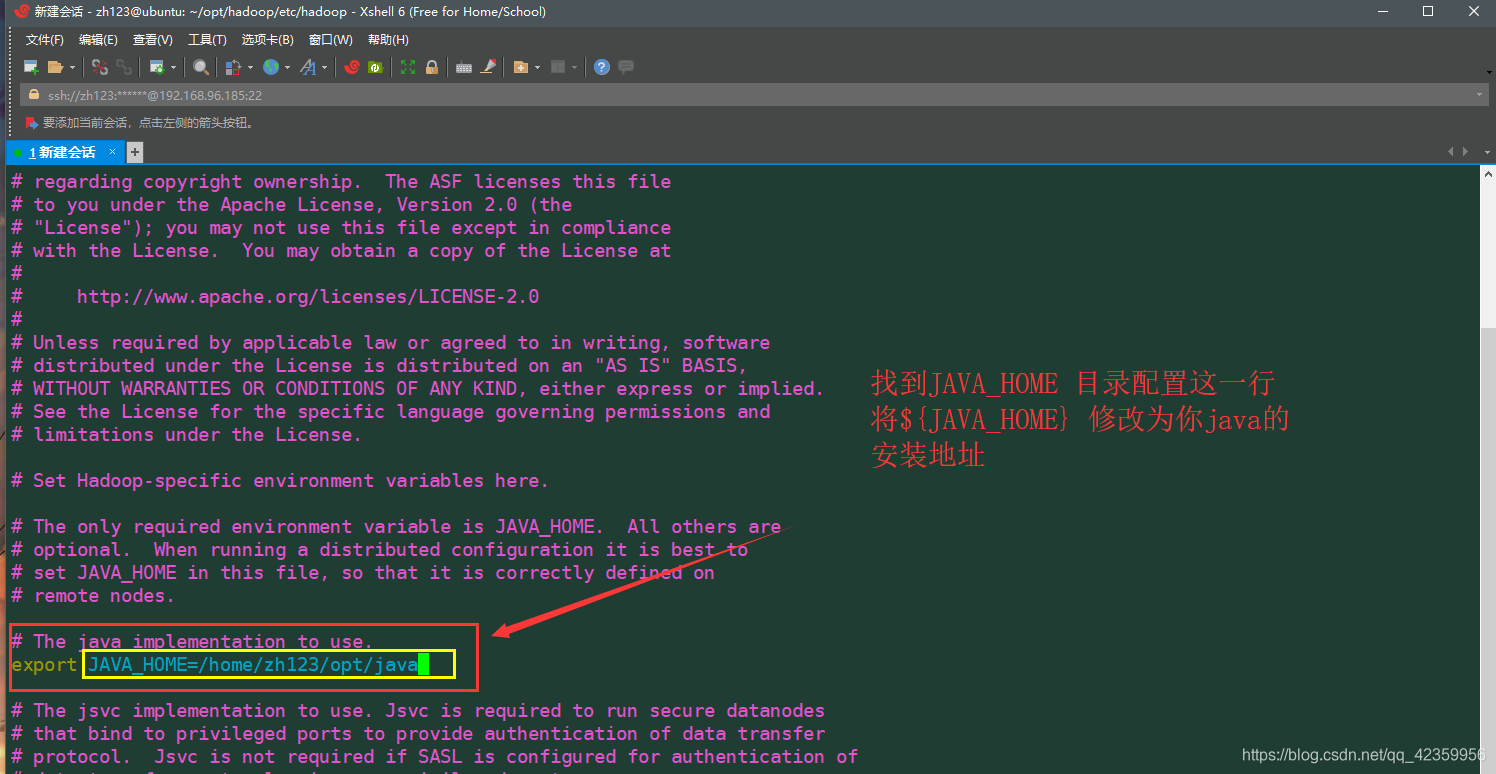
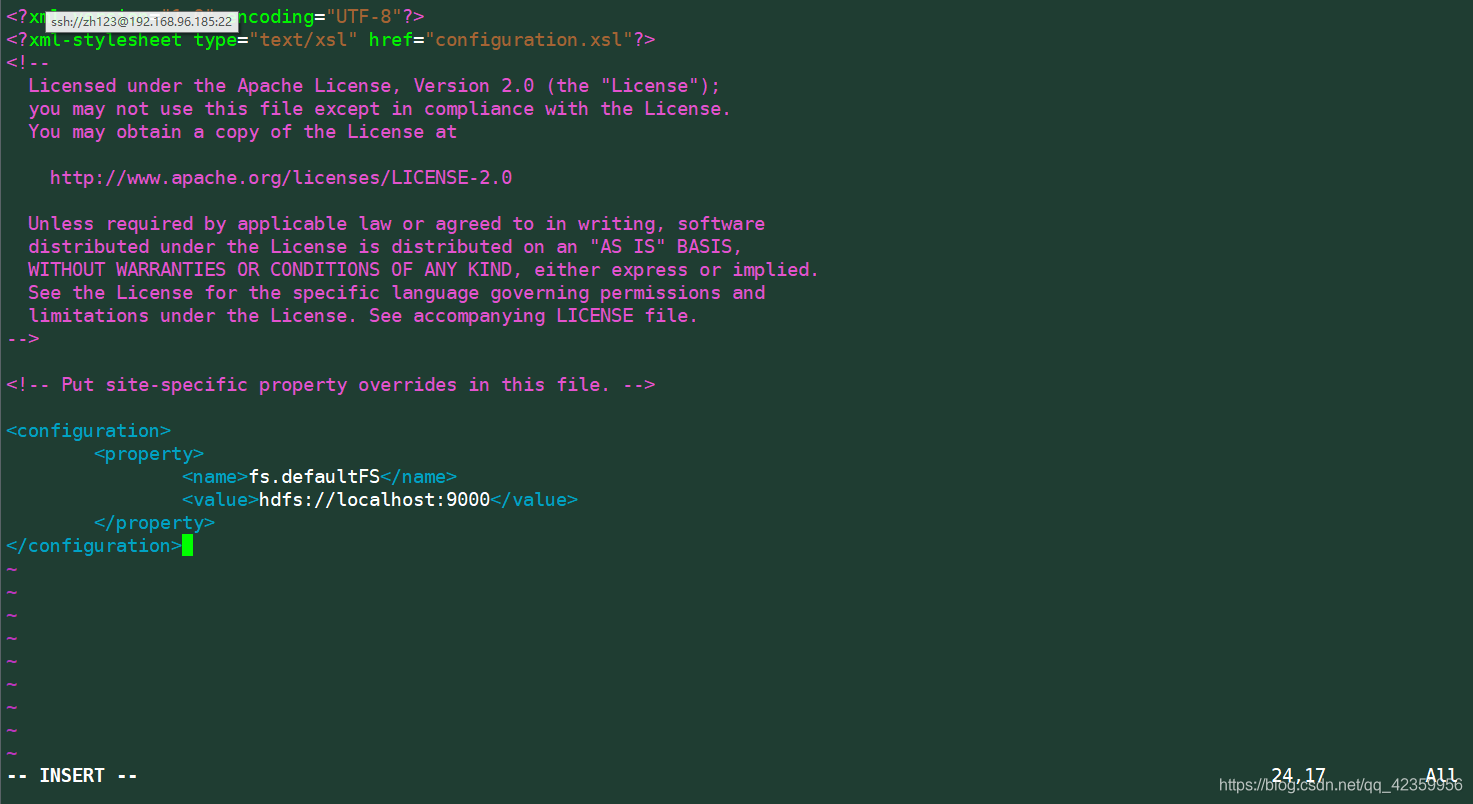
(9) para modificar el vim archivo de configuración de núcleo-site.xml estar dispuesto como sigue:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
(10) vim archivo de configuración hdfs-site.xml en la información del archivo está configurado como sigue
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/zh123/opt/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.namenode.data.dir</name>
<value>/home/zh123/opt/hadoop/dfs/data</value>
</property>
</configuration>

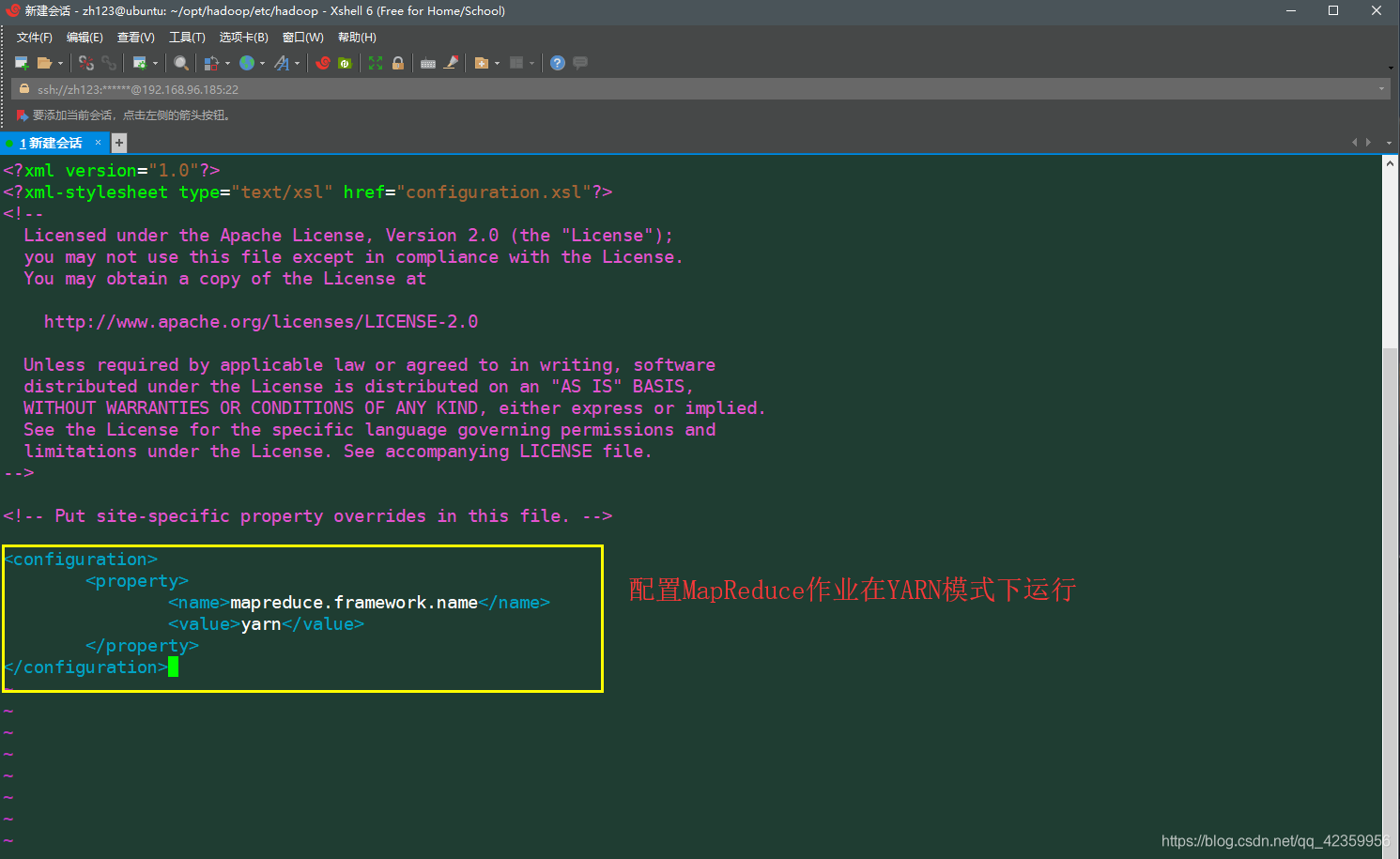
(11) archivo de configuración site.xml mapred, ya que este archivo no existe fue primero y luego salir por lo que necesitamos para conseguir una copia de este site.xml.template-mapred que contiene de su directorio original
: CP-mapred site.xml .template mapred-site.xml
continuación vim editar el archivo de información-site.xml mapred de la siguiente
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
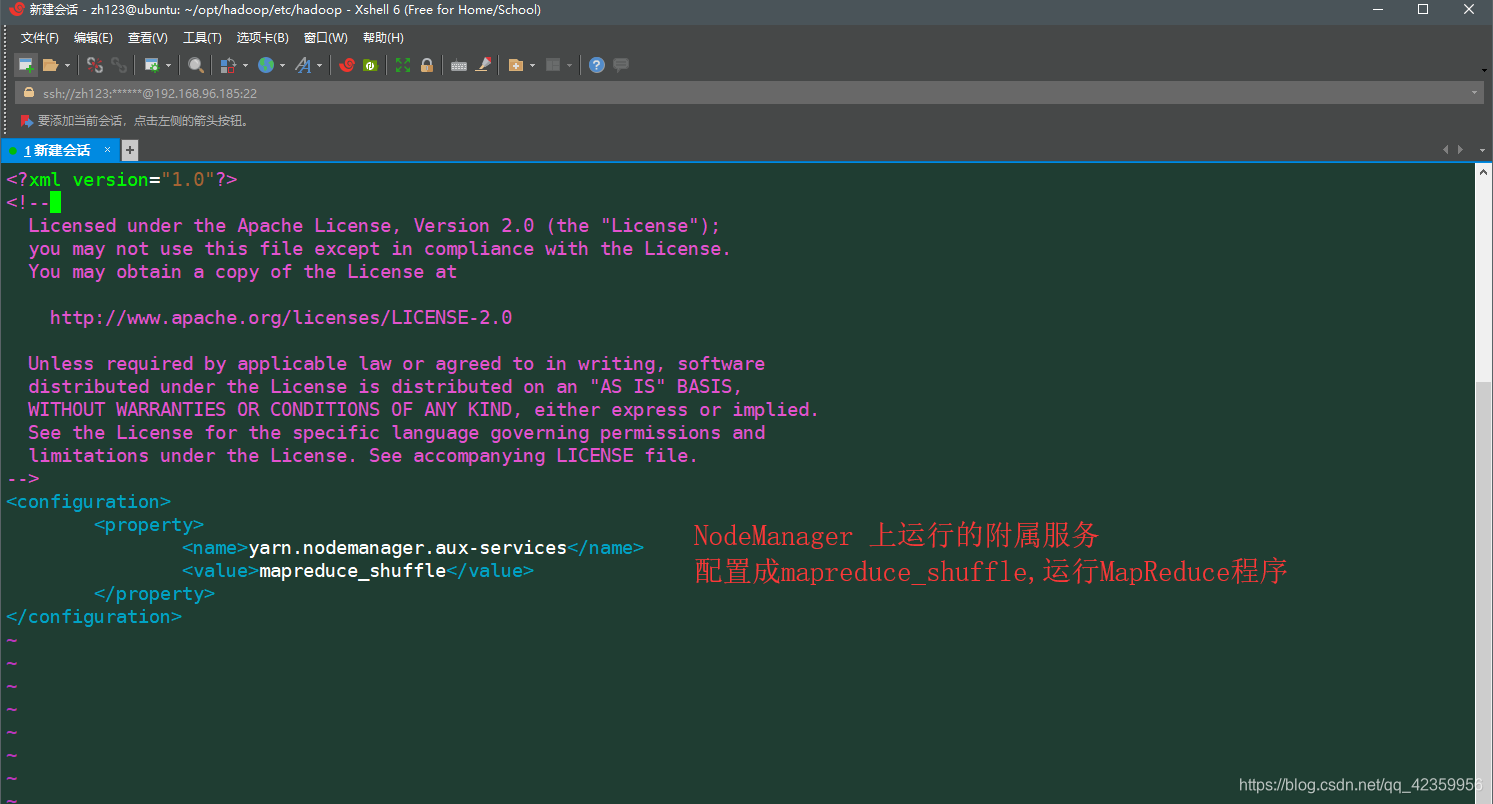
(12) vim hilo site.xml información de configuración está configurado como sigue
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
hadoop-env.sh
núcleo-site.xml
hdfs-site.xml
mapred-site.xml
hilo site.xml
Por encima es la configuración pseudo-distribuido fue hadoop tenga que modificar el nombre del perfil
En cuarto lugar, se inicia hadoop
- 1, el formato NameNode (nota que sólo la primera vez que se inicia !!! Hadoop solamente ejecutar este comando a formato NameNode)
HDFS NameNode -format

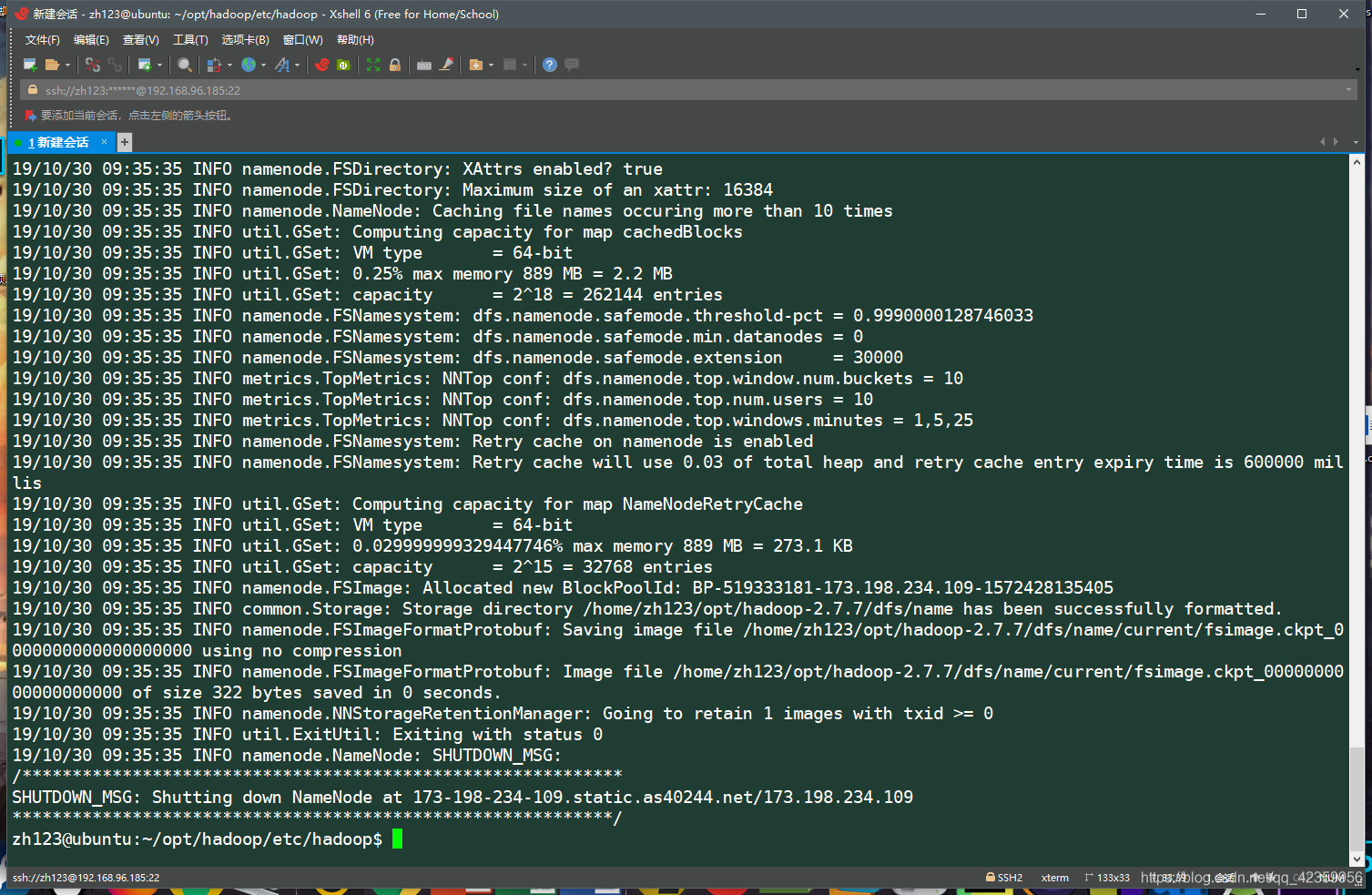
ver información como resultado del registro se disponga de medio de mensajes de error que el formato fue exitosa NameNode - 2, iniciar el servicio Hadoop
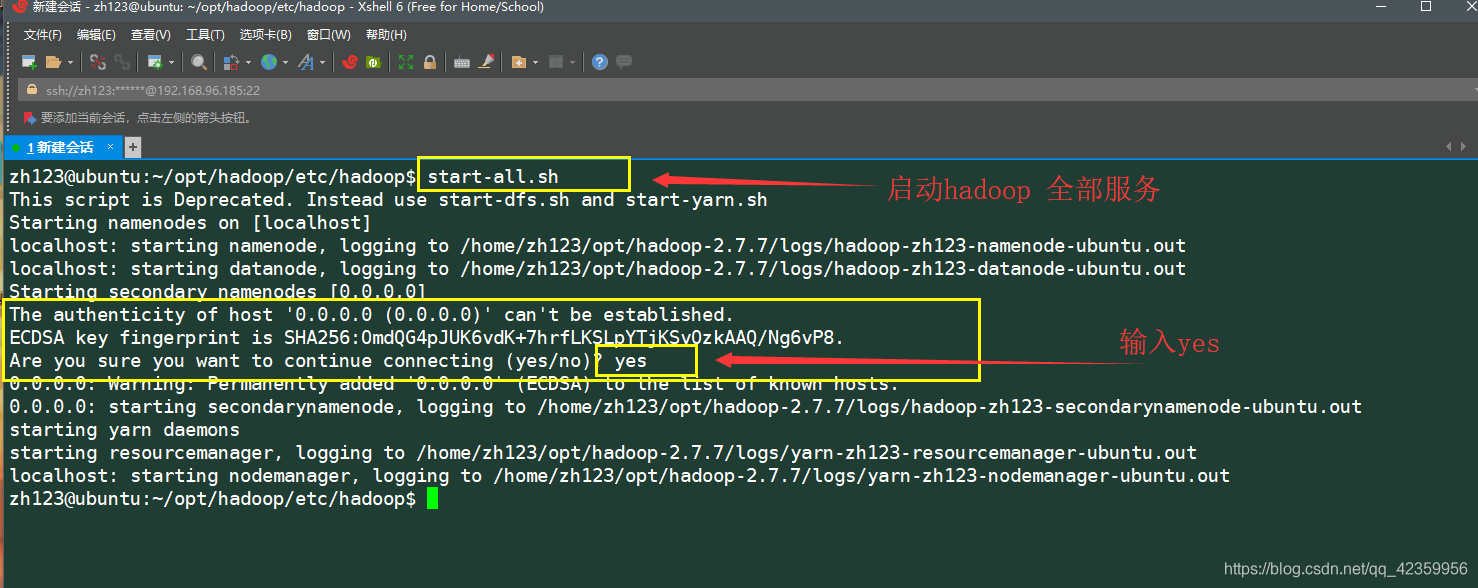
para todos los servicios con el comando start-all.sh comenzar hadoop de
otro JPS Comando línea a la vista, siendo los procesos Java activos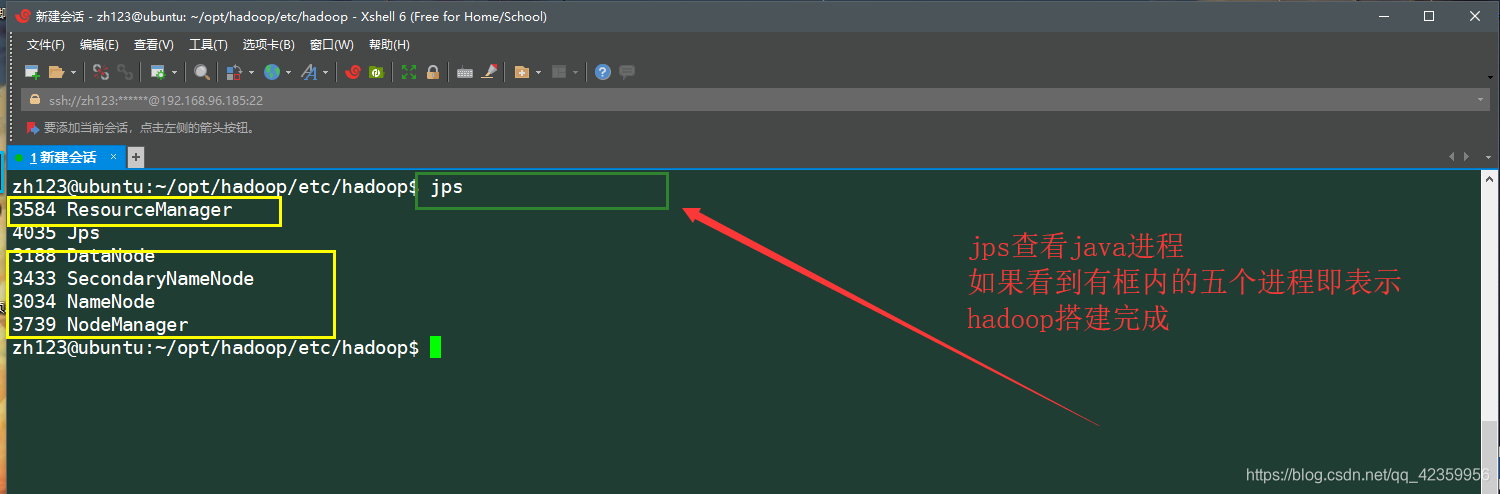
usando hdfs información detallada comando hdfs dfsadmin -report puede ver el
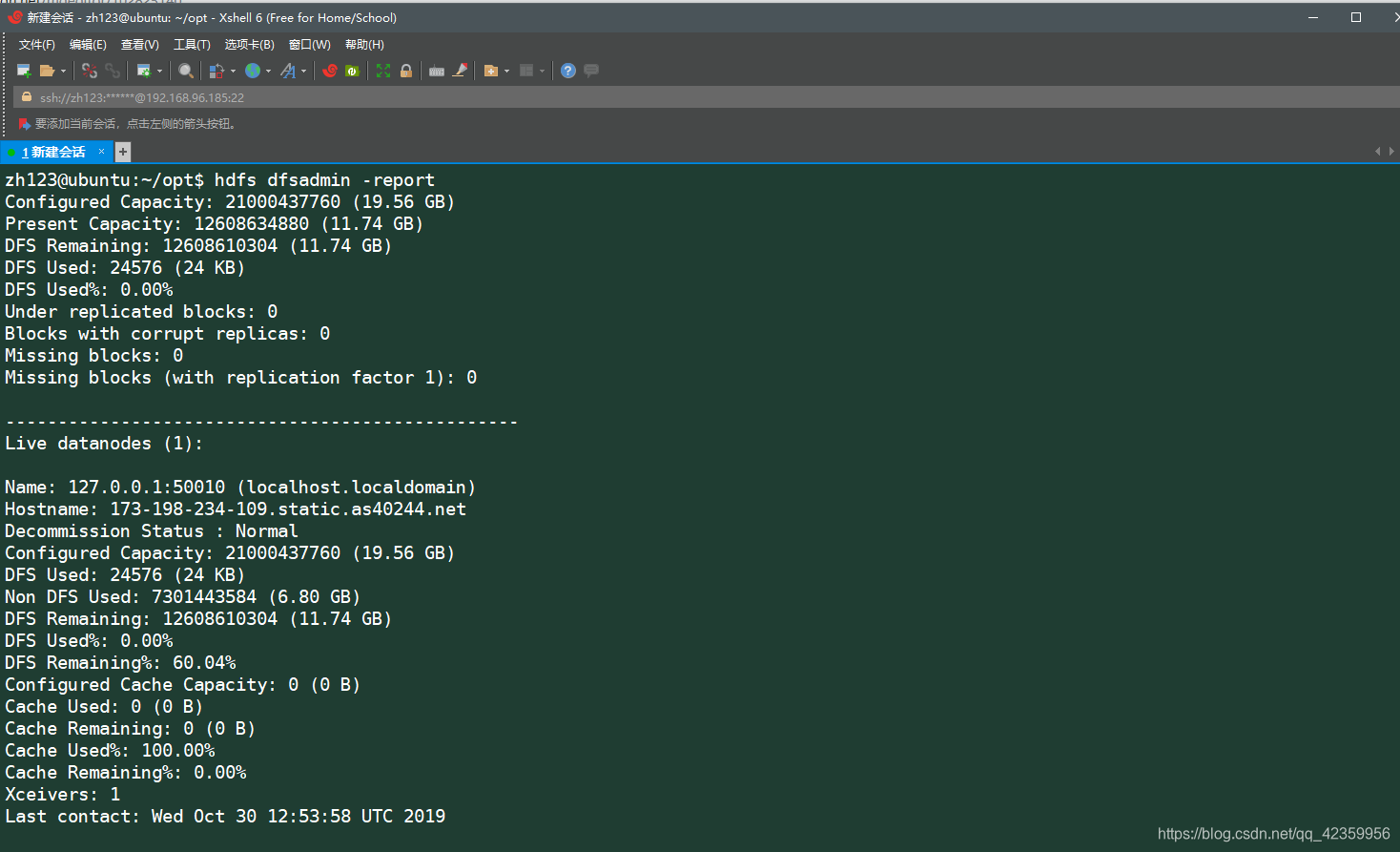
punto de entorno Hadoop pseudo-distribuido tiene de terminar la construcción, el proceso de reconfiguración socio menor si hadoop encontró pregunta, por favor comentar a continuación, explorar! ! !
