direcciones artículo original: https://blog.csdn.net/memory_qianxiao/article/details/82388370
Dado que muchos de mis amigos necesitan estos datos, desde su lanzamiento, hay un montón de gente me pregunta por el código fuente, tengo que, hasta el 10 de marzo, más de un día, me dijeron que no hay datos después de ejecutar, tengo también a prueba que realmente no hay datos, a continuación, una simple investigación encontró que la URL solicitada se cambia debido al puente listo .... Copa azul, haga la pregunta, sin una cuidadosa investigación, después de una cuidadosa investigación encontró que la URL solicitada ha cambiado es una cosa, atención se centra en el sitio utilizando la tecnología Ajax, los datos no es el código fuente de la página en el interior, los datos de solicitud a través de Ajax es local, entonces se carga en una página web ... por lo que es necesario petición de dirección ajax para obtener el análisis de datos. . . A continuación explicaremos el proceso de reconstrucción, aunque resuelto en problemas, pero reduce la cantidad de código, al igual que 200 líneas ... en él.
Entorno de desarrollo: Pitón 3.6 + pycahrm
En tercer lugar de descarga Biblioteca: petición (solicitud de biblioteca a nivel de página), xlwt (biblioteca de manipulación de Excel), JSON (python y sistema de bibliotecas JSON conversión)
Dado que el artículo original escrito detallado proceso de rastreo, esta vez no escriba de manera detallada, y quieren aprender más que aprender, comprender, por favor refiérase al artículo original: https://blog.csdn.net/memory_qianxiao/article/details/82388370 (Aunque el código no puedo usar, pero considerado importante, después de todo, las ideas más importantes de aprendizaje, la lógica de código es una manifestación de sus propios pensamientos)
Nota: Debido a las actualizaciones del sitio de nuevo, pero esta actualización es el nuevo nombre, las solicitudes de cambio de API, lo que resulta código no se pueden usar, sólo tiene que solicitar un cambio de dirección a la petición Ajax sigue el camino original, como :( gracias, en la provincia de Jiangsu Yi Wei señaló que los estudiantes). La integridad del código final en la actualización del código una vez (abril 30 de 19 de de julio de actualización, haga clic en el siguiente :) puede GitHub.

Mientras tanto, el sitio un poco más medidas contra la subida, hay que solicitar disfrazado de un navegador, por lo que debe también aumentar cuando un encabezado de la solicitud en la solicitud, de la siguiente manera:

Actualizado: 19 Julio 2019 Origen clic en los últimos Portal GitHub disponibles: punto entré, GitHub portal ~
Las viejas reglas, Adosado figura siguiente (parte rastreada): una línea profesional de la ciencia página Excel4, artes liberales de línea, la ciencia línea de control provincial, la línea de control MEXT



A: el análisis es: Puesto que los cambios en el sitio de actualización, los datos ajax, por lo que la solicitud de URL inútil, se da el análisis de la lógica continuación:
Pulse F12 para entrar en el modo de programador, haga clic en la red, pulse y mantenga pulsado el XHR, punto justo en una universidad de, encontrar todos los puntos del año o las artes y las ciencias, habrá una API, los datos se devuelve en el interior de clave de API, el siguiente análisis es cómo api análisis se introduzca en los datos.

II: Análisis API dentro de las cabeceras de la siguiente manera:
Solicitud de URL es: https://gkcx.eol.cn/api
Método de petición: Poste! Poste! Poste! Es importante no es el método, get.
parámetros de la petición: parámetros de la petición POST se
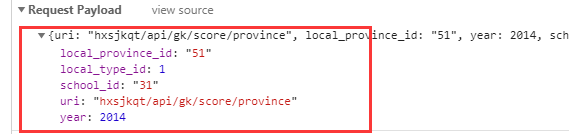
Y obtenemos los datos lo más importante aquí es los parámetros de petición:
local_province_id: es la provincia del código, las actualizaciones de la web son el posicionamiento automático, se seleccionará la corriente ip situación de posicionamiento, que lleva el nombre de código después de la posición rellena automáticamente, por lo que si necesita los datos de rastreo en otro lugar, puede cambiar los parámetros de la petición, provincias de código propio, así que tenemos que tratar.
local_type: nombre de código es artes liberales, la ciencia es 1, 2 artes liberales, pueden salir de ensayo, cada clic tendrá una nueva API para ver en la línea.
school_id: es el ID de la escuela, es necesario comprobar qué escuela para cambiar el ID de la línea
uri: "hxsjkqt / api / GK / marcador / provincia" es la línea de control provincial hxsjkqt / api / GK / marcador / línea profesional especial
año: el año es el rastreo que se lo dio el año, un año en el que los parámetros deben rastreo
Por lo tanto, el método, cuando una solicitud es request.POST (), y pase en los parámetros anteriores.
Aquí adjuntar el nombre de las 34 provincias del país, así como el código correspondiente:
北京:11
天津:12
河北:13
山西:14
内蒙古:15
辽宁:21
吉林:22
黑龙江:23
上海:31
江苏:32
浙江:33
安徽:34
福建:35
江西:36
山东:37
河南:41
湖北:42
湖南:43
广东:44
广西:45
海南:46
重庆:50
四川:51
贵州:52
云南:53
西藏:54
陕西:61
甘肃:62
青海:63
宁夏:64
新疆:65
台湾:71
香港:81
澳门:82
Tres: Porque no conoce el ID a la escuela o tomar la forma de violencia, desde 3000 hasta el comienzo del ciclo de la violencia 30 identificación de la escuela, y luego coser la solicitud de URL.
O definir tres funciones, la entrada principal () función, solicitar información get_html (), el get_info () para obtener información de la escuela, y para sobresalir en el interior almacenado. Código que tiene notas, no habrá repetición de las notas, es la misma. Sin embargo, puede haber menos errores, por lo que todavía está utilizando subida punto de interrupción, es decir, cada vez que una URL de impresión detrás de una identificación de la escuela, si el error continúa con el cambio que hora si el punto de partida para el ciclo, si no es tal un gran Dios sabe solución de errores, bienvenido orientación mensaje agradecido.

código completo es el siguiente: Excel ruta para guardar en su propio bien, la ruta del archivo.
# -*- coding: utf-8 -*-
# @Filename: 全国高校录取数据重构.py
# @Time : 2019/3/22 16:49
# @Author : LYT
"""
"""
import requests,re,xlwt,json
from bs4 import BeautifulSoup
def Get_html(url,data):
try:
headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3676.400 QQBrowser/10.4.34"
}#更新后添加的请求头,伪装成浏览器
r=requests.post(url,params=data,headers=headers)#带请求参数params,同时把headers传进去
r.encoding=r.apparent_encoding
print("请求服务成功!")
print(r.text)
return r.text
except:
print("请求失败")
def Get_info(url,id):
url_api = "https://gkcx.eol.cn/gkcx/api"#更新后请求ajax api
#请求参数信息
data = {
'local_province_id': '51', # 省份 51为四川 默认是自动定位的地方
'local_type_id': 1, # 理科为1,文科为2,
'school_id': '30', # 学校id
'uri': "hxsjkqt/api/gk/score/province", # 专业线special 省线province
'year': 2018 # 年份 网站更新后 省录取线2014 -2018 专业录取线2014-2017
}
info_like=[]#存理科省线信息列表
info_wenke=[]#存文科省线信息列表
special_like=[]#存理科专业信息列表
special_wenke=[]#存文科专信息业表
name=""
for i in range(2014,2019):#请求2014-2018的省控线信息
data['year']=i #更换参数年份
data['school_id']=id#更换学校id
data['local_type_id']=1#更换为理科
infoes=json.loads(Get_html(url_api,data))
# print(info)
# print(info['data']['item'])
#存理科省录取线
if len(infoes['data']['item'])==0:
l=[]
l.append(name) # 没有数据就填充--
l.append(str(i))
l.append('--')
l.append('--')
l.append('--')
l.append('--')
l.append('--')
info_like.append(l)
for j in range(len(infoes['data']['item'])): # 可能有多个省录取线,比如提前批,一批,二批等
l = []
info = infoes['data']['item'][j]
name = info['name']
l.append(info['name'])#存学校名字
l.append(info['year'])#存年份
l.append(info['local_type_name']) # 科类
l.append(info['max'])#最大录取分数
l.append(info['average'])#平均分
l.append(info['min']) #最低分
l.append(info['proscore']) #省控线
l.append(info['local_batch_name'])#批次
info_like.append(l)
#存文科录取线
data['local_type_id']=2#更换为文科
infoes = json.loads(Get_html(url_api,data))
if len(infoes['data']['item'])==0:
l=[]
l.append(name) # 没有数据就填充--
l.append(str(i))
l.append('--')
l.append('--')
l.append('--')
l.append('--')
l.append('--')
info_wenke.append(l)
for j in range(len(infoes['data']['item'])):#可能有多个省录取线,比如提前批,一批,二批等
l=[]
info = infoes['data']['item'][j]
name=info['name']
l.append(info['name']) # 存学校名字
l.append(info['year']) # 存年份
l.append(info['local_type_name'])#科类
l.append(info['max']) #最大录取分数
l.append(info['average']) #平均分
l.append(info['min']) #最低分
l.append(info['proscore']) #省控线
l.append(info['local_batch_name'])#批次
info_wenke.append(l)
print(info_like)
print(info_wenke)
for i in range(2014,2018):#请求2014-2017的专业录取信息
# 请求参数信息
data['year'] = i # 更换参数年份
data['school_id'] = id # 更换学校id
data['local_type_id'] = 1 # 更换为理科
data['uri']='/'.join(data['uri'].split('/')[0:-1])+"/special"#更换为请求参数为专业录取线的参数网址
infoes = json.loads(Get_html(url_api,data))
#存理科专业信息
if len(infoes['data']['item']) == 0:
l = []
l.append(name)
l.append(str(i))
l.append('--')
l.append('--')
l.append('--')
l.append('--')
l.append('--')
l.append('--')
info_like.append(l)
for j in range(len(infoes['data']['item'])):
l=[]
info=infoes['data']['item'][j]
name=info['name']
l.append(info['name'])#学校名字
l.append(info['year'])#年份
l.append(info['spname'])#专业名称
l.append(info['local_type_name'])#科类
l.append(info['average'])#专业平均分
l.append(info['max'])#最高分
l.append(info['min'])#最低分
l.append(info['local_batch_name'])#录取批次
special_like.append(l)
#存文科专业录取信息
data['local_type_id']=2#更换为文科
infoes = json.loads(Get_html(url_api, data))
if len(infoes['data']['item']) == 0:
l = []
l.append(name) #没有信息就填充--符号
l.append(str(i))
l.append('--')
l.append('--')
l.append('--')
l.append('--')
l.append('--')
l.append('--')
info_like.append(l)
for j in range(len(infoes['data']['item'])):
l=[]
info=infoes['data']['item'][j]
name=info['name']
l.append(info['name'])#学校名字
l.append(info['year'])#年份
l.append(info['spname'])#专业名称
l.append(info['local_type_name'])#科类
l.append(info['average'])#专业平均分
l.append(info['max'])#最高分
l.append(info['min'])#最低分
l.append(info['local_batch_name'])#录取批次
special_wenke.append(l)
print(special_like)
print(special_wenke)
#*******************保存数据到excel**************************
print("*************正在写入Excrl数据***************")
# 创建excel簿指定编码
file=xlwt.Workbook(encoding='utf-8')
#创建表 一个表有4个sheet
print("*************正在写入Excrl理科专业线数据***************")
table1=file.add_sheet(name+'理科专业线')
value = ['学校名称', '年份','专业名称','科类', '平均分', '最高分', '最低分', '批次']
for i in range(len(value)):
table1.write(0,i,value[i])
for i in range(len(special_like)):
for j in range(len(special_like[i])):
table1.write(i+1,j,special_like[i][j])
print("*************正在写入Excrl文科专业线数据***************")
table2 = file.add_sheet(name + '文科专业线')
value = ['学校名称', '年份', '专业名称', '科类', '平均分', '最高分', '最低分', '批次']
for i in range(len(value)):
table2.write(0, i, value[i])
for i in range(len(special_wenke)):
for j in range(len(special_wenke[i])):
table2.write(i + 1, j, special_wenke[i][j])
print("*************正在写入Excrl理科省控线数据***************")
table3 = file.add_sheet(name + '理科省控线')
value = ['学校名称', '年份', '科类', '最高分', '平均分', '最低分', '省控线', '批次']
for i in range(len(value)):
table3.write(0, i, value[i])
for i in range(len(info_like)):
for j in range(len(info_like[i])):
table3.write(i + 1, j, info_like[i][j])
print("*************正在写入Excrl文科省控线数据***************")
table4 = file.add_sheet(name + '文科省控线')
value = ['学校名称', '年份', '科类', '最高分', '平均分', '最低分', '省控线', '批次']
for i in range(len(value)):
table4.write(0, i, value[i])
for i in range(len(info_wenke)):
for j in range(len(info_wenke[i])):
table4.write(i + 1, j, info_wenke[i][j])
# ***********指定保存路径******************
file.save('D:\QQPCMgr(1)\Desktop\高校/' + name + '录取数据.xls')
print("****************"+name+"所有数据爬取成功"+"*********************")
def main():
for id in range(30,3000):
url="https://gkcx.eol.cn/school/"+str(id)
print(url)
Get_info(url,id)
if __name__ == '__main__':
main()
