**
instalación Hadoop y configurar clúster pseudo-distribuido
Una instalación de JDK
https://blog.csdn.net/weixin_45873289/article/details/104945583
Nota: este enlace y también hay JDK hadoop paquete de instalación
Segunda instalar Hadoop

entrar tar -zxvf hadoop-3.1.0.tar.gzpaquete de instalación hadoop de descompresión (Debe tenerse en cuenta que el nombre del paquete de instalación es correcta) *
éxito de descompresión
tercer entorno Hadoop de configuración *
Ajuste de SSH libre entrada estrecha
en el tiempo después de la operación de la agrupación que necesitamos para conectarse con frecuencia maestro y el esclavo, por lo que una vez recibida la entrada libre de SSH secreto necesario.
Escriba el siguiente código:
ssh-keygen -t rsa -P ''
Sin contraseña para generar el par de claves, excepto la consulta directamente en la trayectoria de transporte, generar un par de claves: id_rsa y id_rsa.pub, almacenado en el directorio por defecto ~ / .ssh.
A continuación: la clave id_rsa.pub se añade a la autorización para entrar.
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
A continuación, modifique los derechos:
chmod 600 ~/.ssh/authorized_keys
Luego hay que habilitar la autenticación RSA, iniciar el público y la autenticación de clave privada pareja:
vim /etc/ssh/sshd_config Si le solicita a los permisos suficientes en comando con sudo;
1.修改ssh配置:
RSAAuthentication yes # 启用 RSA 认证
PubkeyAuthentication yes # 启用公钥私钥配对认证方式
AuthorizedKeysFile %h/.ssh/authorized_keys # 公钥文件路径
reinicio SSH
service ssh restart
Así, el trabajo preparatorio se ha hecho, tenemos que empezar a Hadoop modificar los archivos de configuración, y necesitan ser modificados un total de seis archivos. Ellos son:
-
hadoop-env.sh;
-
yarn-env.sh;
-
core-site.xml;
-
hdfs-site.xml;
-
-Site.xml mapred;
-
hilo-site.xml.
- hadoop-env.sh de configuración:

Edición hadoop-env.sh Introduce el código siguiente en el archivo:
**# The java implementation to use.**
export JAVA_HOME=/java/jdk1.8.0_171 #这里是你jdk的安装路径
- yarn-env.sh configuración
yarn-env.sh editor inserte el código siguiente:
export JAVA_HOME=/java/jdk1.8.0_171 #这里也是jdk的路径
3. Núcleo-site.xml configuración
Este es el archivo de configuración del núcleo tenemos que añadir el archivo URI y NameNode HDFS en la ubicación de la carpeta temporal, esta carpeta temporal se crea a continuación.
Agregar código siguiente al final del archivo de configuración de etiquetas:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
<description>HDFS的URI,文件系统://namenode标识:端口号</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/tmp</value>
<description>namenode上本地的hadoop临时文件夹</description>
</property>
</configuration>
4. fichero de configuración hdfs-site.xml
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/usr/hadoop/hdfs/name</value>
<description>namenode上存储hdfs名字空间元数据 </description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/hadoop/hdfs/data</value>
<description>datanode上数据块的物理存储位置</description>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
fichero de configuración 5.-site.xml mapred
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
disposición 6. hilo site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.2.10:8099</value>
<description>这个地址是mr管理界面的</description>
</property>
</configuration>
**
Crear una carpeta
**
Hemos configurado en el archivo de configuración, parte de la ruta de la carpeta, y ahora tenemos que crearlos, utilice la operación de usuario hadoop en / usr / hadoop / directorio, acumulación tmp, hdfs / nombre, hdfs / datos de directorio, ejecute el siguiente comando:
mkdir -p /usr/hadoop/tmp
mkdir /usr/hadoop/hdfs
mkdir /usr/hadoop/hdfs/data
mkdir /usr/hadoop/hdfs/name
Añadir la variable de entorno a Hadoop
Añadir la variable de entorno a Hadoop
vim /etc/profile
En el final del archivo se inserta en el código siguiente:

El último cambio entre en vigor:source /etc/profile
verificación
Ahora configurar el trabajo de base se ha hecho, sólo es necesario para completar la siguiente: 1. Formato de archivo HDFS, 2 hadoop inicio, 3 para verificar Hadoop.
formato
Antes de utilizar Hadoop alguna información básica que necesitamos para dar formato al hadoop.
Utilice el siguiente comando:
hadoop namenode -format
: Aparece la siguiente pantalla en nombre del exitoso

inicio Hadoop
start-dfs.sh
Si desea que aparezca el interfaz de comandos de entrada como se muestra a continuación:
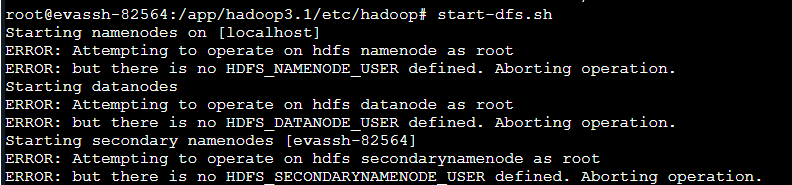 En /hadoop3.1/sbin ruta:
En /hadoop3.1/sbin ruta:
el, superior stop-dfs.sh start-dfs.sh dos archivos añaden los siguientes parámetros
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
Allí, start-yarn.sh, superior stop-yarn.sh También es necesario añadir lo siguiente:
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
Start-dfs.sh inicio de nuevo, y finalmente entrar en la verificación JPS de mando, en nombre de la interfaz siguiente comienza aparece de éxito:

Abrir el navegador Firefox y entrar en la interfaz gráfica de su máquina virtual: http: // localhost: 9870 / o de entrada de la máquina de las ventanas http: // virtual de la dirección IP de la máquina: 9870 / Hadoop también puede acceder a la página de administración.
注:hadoop2.0版本开头的端口号是50070;hadoop3.0开头的是9870
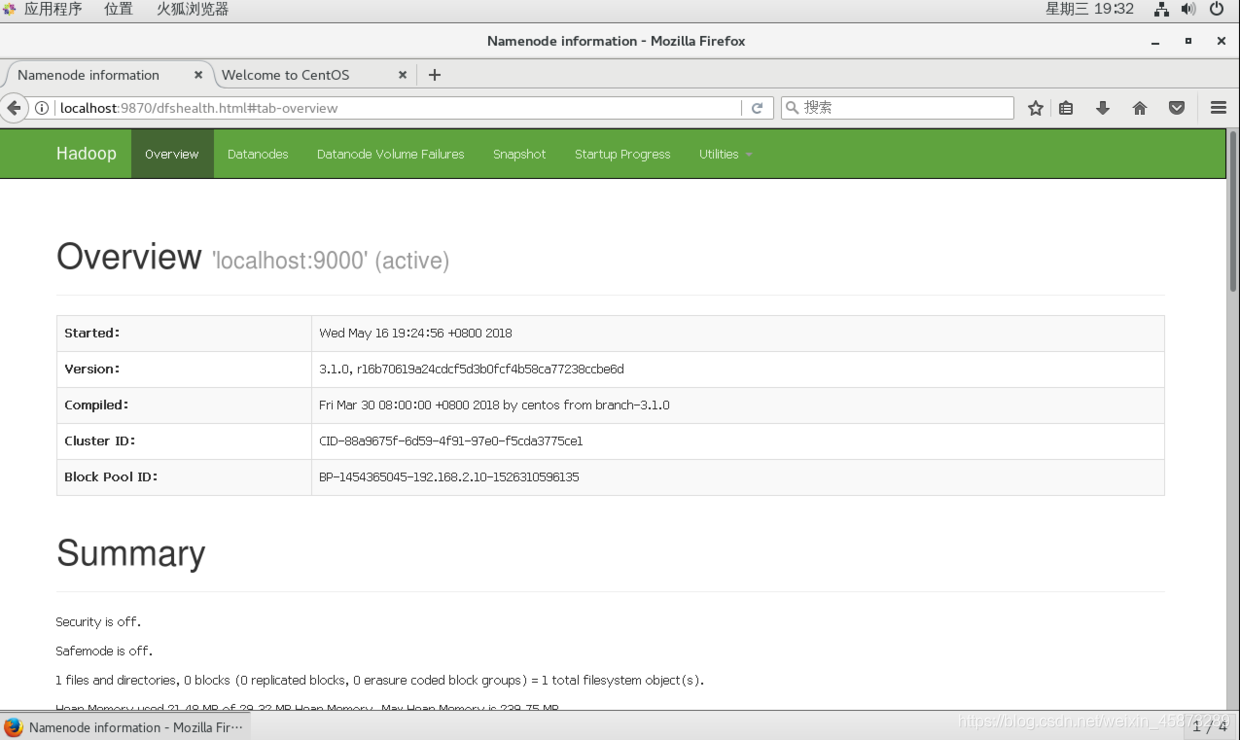
Construir el éxito
