maestro rastreador web pitón de base cero
- medio ambiente
- Escribir los primeros reptiles: Descargar imágenes del gato
- La primera vez que utilice marco
- Scrapy 1.8.0 Instalación y configuración
- La primera vez que utilice el marco: las páginas que desee para descargar datos
- Establecer proyecto scrapy
- Número uno: Crear un archivo de Python en las arañas del módulo (carpeta arañas) en la preparación de la oruga *
- Número dos: la función principal (py simplemente crear un archivo, cmd declaración en nombre del Ejecutivo, reptil corriendo)
- Serie de tres: Módulo artículo, estableciendo contenedor de datos, los datos del cribado
- Número cuatro: la función de devolución de llamada de análisis del elemento añadido
- Número cinco: ejecutar comunicado cmd en la función principal de los datos almacenados extremo directamente proyectado
Actualmente, soy un novato problema rastreador web, recordar algunos de los reptiles encontrados y las soluciones. Para algunas configuraciones de tan solo el ambiente recuerdos, sólo a título informativo.
Basado en cero: la necesidad de algunas ideas básicas de programación tales como la capacidad de configurar el entorno ifelse y ejecutar el programa
Si hay algún error, como por ejemplo la necesidad de instalar un error en ciertos módulos o accesorios, por favor recuerdan a los bloggers, los bloggers instalados para que no se olvide de llevar el error.
medio ambiente
python3.8 (locale) y descargar la configuración
pitón amd64.exe-3.8.1-enlace de descarga
si usted puede ser dueño de la insuficiencia Baidu búsqueda descarga (enlace a las ventanas de los sistemas de 64 bits, otros sistemas pueden descargar sus propias Baidu)
Notas de instalación:
1, comprobar el complemento de Python 3.7 a PATH
para agregar la ruta de instalación de Python a las variables de entorno del sistema variable Path, o necesidad de configurar sus propias variables de entorno
2. Seleccione Instalar ahora (instalación de la placa C por defecto) / instalación Personalizar (ruta de instalación personalizada)
3. instalación personalizada puede necesitar revisar, si usted no sabe el valor por defecto en él.
Compruebe la instalación se ha realizado correctamente;
introduzca el comando cmd pitón en la línea de comandos,
si se ha introducido con éxito el interactiva de línea de comandos Python, la instalación se ha realizado correctamente. Instalación es correcta, entonces se puede ver la información de la versión y entrar en el modo de programación
Comience la búsqueda IDLE (en python3.8)
plazo
Si se introduce de entrada en chino que, a continuación, se interpretará en una variedad de combinaciones de teclas, muy molestos.
Para ello, vamos a descargar más conveniente prcharm editor.
pycharm2019 3.3 (escritor) de descarga y ejecución
enlace de descarga PyCharm-comunidad-2019.3.3.exe
anteriormente para la versión de 64 bits de fallo de enlace comunitario ventanas o necesidad de descargar otra versión Buscar
Notas de instalación:
1, en las opciones de instalación de verificación sólo:
64 bits Launcher (crear un acceso directo del escritorio) y .py (py después de archivo predeterminado abierto por PyCharm)
2, el otro todo el camino en Aceptar y, a continuación, realice los ajustes no de importación, a continuación, seleccione Aceptar, todo el camino en Aceptar para completar la instalación.
Crear un nuevo proyecto y luego nombre correcto-proyecto para añadir el archivo de programa en Python Python de ejecución
实例说明python编程语言特点
def add(a,b):
return a+b # 1.递进:按照递进 来控制范围 如下的a与b的定义必须对齐
a = "123"
b = '456' #2.单引号与双引号等价
print(add(a,b)) # 3.无分号 还是按照递进来辨别
if a == "666":
print(a)
else:
print("666") # 4.仅通过递进程序才得知 if与下面的else 是同一个判断语句
La salida es:
123456
666
En este punto, con conocimientos básicos de programación pueden aprender mientras se escribe reptiles pitón.
Y así sucesivamente, el siguiente error ¿Qué demonios?
Unindent no coincide con ningún nivel de sangría externa es lo que el mal infierno?

La razón es que la sangría de los estrictos requisitos de pitón metamorfosis
puede ser visto delante del primer símbolo es una letra más pequeña >: la sangría utilizando una tecla de tabulación
y el segundo que precede símbolo de impresión es ....: pura alineados con cuatro espacios de sangría
¿qué demonios? Y por defecto no es PyCharm al espacio de visualización y símbolos notación de la lengüeta, es decir, usted tiene que mirar a las dos en blanco diferente.
Entonces, ¿cómo mostrar caracteres de espacio y notación de la lengüeta?
File-Ajustes-Editor-Aspecto-show espacios en blanco (tres opciones pequeño defecto Seleccionar todo)
Escribir los primeros reptiles: Descargar imágenes del gato
Después de instalar el entorno anterior, tratamos de gatos imágenes para descargar a su ordenador lindo gato en el medio
preámbulos, copiar y pegar corremos a punto de intentar
import urllib.request
response = urllib.request.urlopen('http://placekitten.com/g/500/600')
# 获取网页内容
cat_img = response.read()
# 读取网页内容 也就是一个图片
fp = open('cat_500_600.jpg','wb')
fp.write(cat_img)
# fp是一个文件对象,open方法第一个属性是文件名称,第二个属性是write-bytes也就是写文件模式 本地不存在则创建
# 写文件 属性为刚读取的图片cat_mig
Si el entorno no es ningún problema, ningún error de Python se puede ir al directorio para encontrar las imágenes.
Otro código adicional para acceder al directorio
import os
print (os.getcwd())#获得当前目录
Lo anterior se explica a continuación módulo de rastreador y se utiliza para explicar la frase anterior por los rastreadores de oraciones
urllib paquetes (solicitud y utilizar principalmente el módulo de análisis sintáctico)
Se utiliza para acceder a la web y el acceso al contenido, el rastreador es el diseño básico de casi
import urllib.request #引入该包的request 也就是请求(和响应)模块
módulo de análisis sintáctico
urlencode (): convertido al formato de diccionario url
módulo de solicitud: páginas Abrir URL y devuelve una respuesta (es decir, contenido web)
Los métodos principales: urlopen (URL, datos)
para abrir la dirección URL y devuelve el objeto respuesta (http.client.HTTPResponse Objeto)
parámetro url puede ser un String url, es decir, la dirección de la página.
urlopen el segundo parámetro es la adquisición de datos o parámetros de control de la página se somete
la adquisición de datos con get tiempo para Ninguno, cuando los datos presentados para la asignación posterior. Así que no entiendo es la asignación por defecto, en cuanto al momento de presentar una entrada y la diferencia entre los dos, a un lado.
Métodos Esta solicitud es una solicitud para obtener el contenido de la página Web, el parámetro es la dirección web, tan fácil
response = urllib.request.urlopen('http://placekitten.com/g/500/600')
# 调用request模块来获取网页内容
# response为网页的响应对象,其中包含网页的所有内容。
objeto de respuesta de respuesta que comprende un número de maneras, la más importante es el método de lectura ()
utilizando los Leer) devuelve la función (el contenido web no decodificado (por ejemplo, el flujo de bytes o imagen)
leer () con la función de decodificación () usando el método de decodificación correspondiente al contenido obtenido, devuelve el objeto correspondiente (por ejemplo, devuelve una cadena UTF-8)
cat_img = response.read()
# 读取未解码的网页内容 此处就是一个图片
Solicitud: una mejor información de peticiones de objetos, incluyendo las cabeceras (header petición)
Sólo uso urlopen(网页), parecía demasiado restrictiva, ya que con los avances de la tecnología de los reptiles, la tecnología anti-rastreador también está desarrollando.
Muchas páginas web cuando se determina que la solicitud rechazará su petición de acceso de pitón. Si la página no me deja cómo hacerlo datos?
Disfrazado como un usuario que no es un verdadero pitón pero accesible con un navegador.
Aquí principalmente a la solicitud de la pitón añade una serie de atributos, tales como solicitud de la página puede ser un terminal de usuario (rastreador trans utiliza para determinar si la pitón atributo solicitado) User-Agent
Agente de adquirir el usuario:
1) Sólo tiene que abrir la página (este último se selecciona de acuerdo con la página que desea visitar), como Baidu
botón derecho del ratón - cheque - Red - Los datos de la siguiente varias clic al azar en un bar - tirón hacia abajo para solicitar Headers - hasta User-Agent
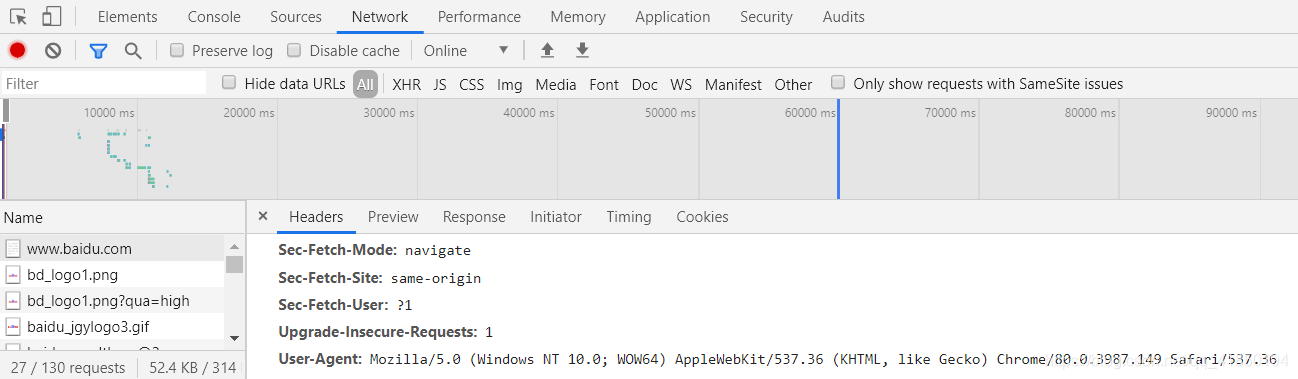
Aquí recomendamos utilizar el navegador Chrome.
Por lo tanto, solicitar el módulo y la introducción del módulo de solicitud, es decir, las páginas de solicitud de información mejores objetos de solicitud, incluyendo las cabeceras (encabezado de la solicitud) y otra información
que podemos configurar algo más de información a la solicitud objeto, a continuación,
urllib.request.urlopen(Reqeust对象)
# 属性是信息更完善的请求对象,当然其中要包括网页地址。
# 而不再只是一个网页地址
intentar
import urllib.request
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE'
}
url = 'http://placekitten.com/g/500/600'
R1 = urllib.request.Request(url=url,headers=headers)
# R1 是Request的一个对象 其中赋值了地址和信息头
# 对于该网页来说,对python没有阻拦,所以只是示范,信息头可以不加
response = urllib.request.urlopen(R1)
cat_img = response.read()
# 读取未解码的网页内容 此处就是一个图片
fp = open('cat_500_600.jpg','wb')
fp.write(cat_img)
# fp是一个文件对象,open方法第一个属性是文件名称,第二个属性是write-bytes也就是写文件模式 本地不存在则创建
# 写文件 属性为刚读取的图片cat_mig
atributo solicitud objeto configurado de la siguiente manera
Request (url = url, data = datos, cabeceras = cabeceras, method = 'post')
parámetros de datos: datos de acceso web llevan a un lado.
Requisitos bytes tipo (flujo de bytes), si un diccionario es, en primer lugar urllib.parse.urlencode () de codificación.
data = urllib.parse.urlencode(字典).encode('utf-8')
de datos está vacío, por defecto método para obtener, que se adquiere.
datos no está vacío, método por defecto pos, que se presenta.
La primera vez que utilice marco
Scrapy 1.8.0 Instalación y configuración
No, se recomienda en línea tutorial de búsqueda.
La primera vez que utilice el marco: las páginas que desee para descargar datos
Establecer proyecto scrapy
CD que desea crear un directorio del proyecto, aquí está el escritorio
C:\Users\15650>cd desktop
C:\Users\15650\Desktop>scrapy startproject hello
elemento Abrir usando PyCharm hola (File-abierta) y la operación, como se muestra en la figura,
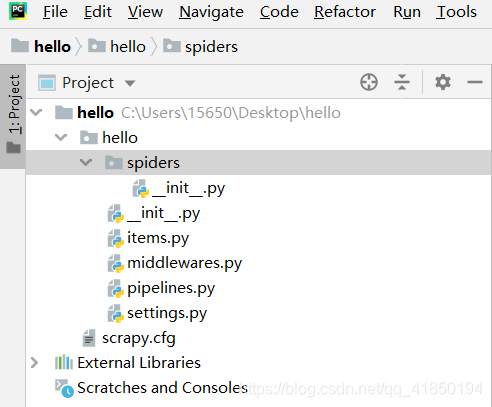
Número uno: Crear un archivo de Python en las arañas del módulo (carpeta arañas) en la preparación de la oruga *
import scrapy
class Number1Spider(scrapy.Spider):
name = "number1" # 必须唯一 ,可以理解为给爬虫起名字,以后直接叫名字 它就工作
allowed_domains = ['dmoztools.net'] # 设定域名 允许爬取的域名列表,不设置表示允许爬取所有
# 填写起始爬取地址 爬虫一开始工作就自动访问并返回信息
start_urls = [
"http://dmoztools.net/Computers/Programming/Languages/Python/Books/"
]
# 以上为爬虫启动后的第一步,自动访问网页然后返回response响应对象(网页信息)
# 此处为自动执行的回调函数parse,也就是处理response信息的函数,为处理数据部分
def parse(self, response):
with open("Book", 'wb') as f:
f.write(response.body) # response.body 是网页前端的所有信息
Número dos: la función principal (py simplemente crear un archivo, cmd declaración en nombre del Ejecutivo, reptil corriendo)
from scrapy import cmdline
cmdline.execute('scrapy crawl number1'.split())
# 引号内 本来是cmd下执行的语句,此处引入cmd模块来代执行
# 意思为 执行scrapy 的爬虫 爬虫名为number1
archivo de libro se genera en la vista del proyecto, el contenido del archivo a las portadas de toda la información, se recomienda abrir la memoria de la computadora usando el Bloc de notas
Serie de tres: Módulo artículo, estableciendo contenedor de datos, los datos del cribado
Si queremos mantener la página acaba de obtener el título, enlace y la descripción.
Artículo definir un contenedor en items.py, donde varios atributos se declararon quieren, donde queremos tres propiedades.
import scrapy
class HelloItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
Número cuatro: la función de devolución de llamada de análisis del elemento añadido
# 此处为自动执行的回调函数parse,也就是处理response信息的函数,为处理数据部分
def parse(self, response):
# response是 htmlresponse对象
sel = scrapy.selector.Selector(response)
#sel 选择器,是一个可以被xpath查找到选择器
sites = sel.xpath('//div[@class="title-and-desc"]')
items = []
for site in sites:
item = HelloItem() # 创建一个该Scrapy项目 item容器的一个对象
item['title'] = site.xpath('a/div/text()').extract()
item['link'] = site.xpath('a/@href').extract()
item['desc'] = site.xpath('div/text()').extract()
items.append(item) #将该item对象添加到items列表
return items
lxml y XPath: medios para determinar la posición de una parte del documento
lxml biblioteca de análisis sintáctico es una biblioteca de Python que soporta HTML y análisis de XML, el apoyo XPath
Instalación, cmd sigue:pip install lxml
etree introducido:from lxml import etree
cuerdas convertir HTML como el blanco, y el nodo de finalización automática:html = etree.HTML(text)
Leer el archivo en el html:html = etree.parse('./test.html',etree.HTMLParser())
El archivo HTML en una cadena de decodificación y la salida:
result = etree.tostring(html)
print(result.decode('UTF-8'))
XPath es el Lenguaje de Rutas XML, que es un método para determinar el documento XML / HTML en una posición de parte del lenguaje.
el análisis de HTML objeto XPath es el objeto que devuelve una lista
extraer():
item['name'] = each.xpath("./a/text()").extract()[0]
each html文档
each.xpath("./a/text()") xpath解析返回的是一个选择器列表
extract() 转换为Unicode字符串
[0] 列表第一个位置
Número cinco: ejecutar comunicado cmd en la función principal de los datos almacenados extremo directamente proyectado
from scrapy import cmdline
cmdline.execute('scrapy crawl number1 -o item.json'.split())
Ya sea para generar archivo de libro para ver el proyecto, el contenido del archivo para la proyección de la información completa, consejos lee directamente en el PyCharm
