《AI工匠BOOK》持续更新AI算法与最新应用,如果您感兴趣,欢迎关注AI工匠(AI算法与最新应用前沿研究)。 Padre en Keras estudio en profundidad del libro, diseñar un camino para tareas de reconocimiento de imagen para mejorar el rendimiento de unos pocos puntos porcentuales de la capa de red, la capa de red no sólo puede reemplazar Conv2D, y puede hacer el modelo más ligero, con un peso de menos entrenables parámetro, más rápido, la capa de red es la profundidad de convolución separable (profundidad para dar lugar separable convolución) capa (SeparableConv2D). ``
Padre en Keras estudio en profundidad del libro, diseñar un camino para tareas de reconocimiento de imagen para mejorar el rendimiento de unos pocos puntos porcentuales de la capa de red, la capa de red no sólo puede reemplazar Conv2D, y puede hacer el modelo más ligero, con un peso de menos entrenables parámetro, más rápido, la capa de red es la profundidad de convolución separable (profundidad para dar lugar separable convolución) capa (SeparableConv2D). ``
******深度可分离卷积原理介绍:******
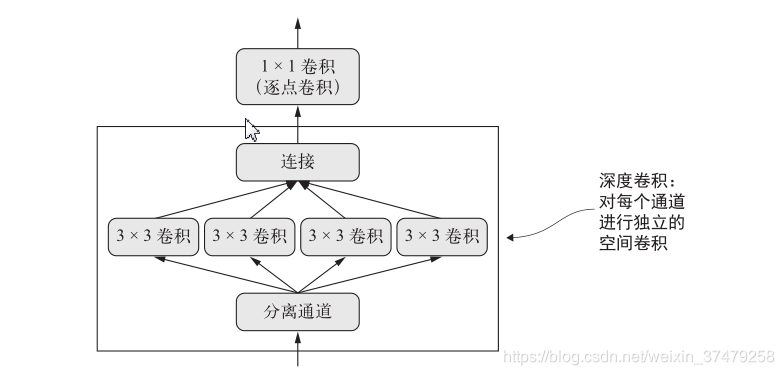 Esta capa SeparableConv2D por separado para cada canal de entrada realiza la convolución espacial, convolución y punto por punto (1 × 1 convolución) mezclar el canal de salida, que es equivalente al aprendizaje y el aprendizaje separado espacialmente en el que las características del canal, parámetros necesarios para mucho menos, la cantidad de cálculos es también más pequeño, para que pueda obtener un modelo más pequeño, más rápido. Debido a que es un método más eficiente de realizar la convolución, a menudo es posible utilizar menos datos para obtener una mejor representación del modelo para obtener un mejor rendimiento.
Esta capa SeparableConv2D por separado para cada canal de entrada realiza la convolución espacial, convolución y punto por punto (1 × 1 convolución) mezclar el canal de salida, que es equivalente al aprendizaje y el aprendizaje separado espacialmente en el que las características del canal, parámetros necesarios para mucho menos, la cantidad de cálculos es también más pequeño, para que pueda obtener un modelo más pequeño, más rápido. Debido a que es un método más eficiente de realizar la convolución, a menudo es posible utilizar menos datos para obtener una mejor representación del modelo para obtener un mejor rendimiento.
Separables escenario de aplicación profundidad convolución
asumió posición espacial de la imagen de entrada están altamente correlacionados, diferentes canales independientes.
******深度可分离卷积构建模型代码实战:******
Aquí se utiliza una profundidad de convolución separable para construir un completo modelo de reconocimiento de imágenes de la CNN,