Directorio artículo
- En primer lugar, la implementación manual
- En segundo lugar, la automatización del despliegue hadoop pseudo-distribuido
- En tercer lugar, el error de determinación
Medio Ambiente: una sola máquina virtual VMware, IP es 172.16.193.200.
En primer lugar, la implementación manual
1, apague el servidor de seguridad, SELinux
systemctl stop firewalld
sed -i '/SELINUX/s/enforcing/disabled/g' /etc/selinux/config
2, establecer el nombre de host
hostnamectl set-hostname huatec01
3, instale jdk1.8
https://blog.csdn.net/weixin_44571270/article/details/102939666
4, descargar hadoop
wget http://mirrors.hust.edu.cn/apache/hadoop/core/hadoop-2.8.5/hadoop-2.8.5.tar.gz
mv hadoop-2.8.5.tar.gz /usr/local
cd /usr/local
tar xvf hadoop-2.8.5.tar.gz
mv hadoop-2.8.5 hadoop
5, modificar el archivo de configuración hadoop
cd /usr/local/hadoop/etc/hadoop/
- hadoop.env.sh
- core-site.xml
- hdfs-site.xml
- mapred-site.xml
- hilo-site.xml
(1) hadoop.env.sh
Este archivo es el archivo de configuración del entorno operativo Hadoop, necesidad de depender de JDK Hadoop consecutivo, el valor del cual modificamos la exportación ruta JAVA_HOME JDK instalamos de la siguiente manera:
export JAVA_HOME=/usr/local/jdk1.8.0_141
(2) de núcleo-site.xml
El archivo de perfil de Hadoop núcleo, el contenido del archivo de configuración de la siguiente forma:
<configuration>
<property>
<name>fs.defaultFS </name>
<value>hdfs://huatec01:9000</value>
</property>
<property>
<name>Hadoop.tmp.dir</name>
<value>/huatec/hadoop-2.8.5/tmp</value>
</property>
</configuration>
En el código anterior, hemos configurado principalmente con dos atributos, un primer atributo para especificar una dirección de comunicación NameNode HDFS, aquí lo asignamos a huatec01; generar un segundo atributo para la operación de almacenamiento de archivos al especificar Hadoop catálogo, no necesitamos para crear este directorio, ya que el formato se crea automáticamente cuando el Hadoop.
(3) hdfs-site.xml
El archivo de configuración es archivos HDFS centrales, archivos de configuración de la siguiente manera:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
El número predeterminado de copias clúster Hadoop es tres, pero ahora sólo pseudo-distribuido instalación en un solo nodo, sin tener que guardar tres copias, que modifica el valor de la propiedad a 1 puede ser. Tres nodos están totalmente distribuidos.
(4) mapred-site.xml
no existe este archivo, pero no es un archivo de plantilla mapred-site.xml.template, vamos a cambiar el nombre del archivo de plantilla mapred-site.xml, y luego editarlo. El perfil de los archivos MapReduce al núcleo, el contenido del archivo de configuración como sigue:
mv mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
La razón por la configuración de las propiedades anteriores, porque después de Hadoop2.0, mapreduce se está ejecutando en la arquitectura del hilado, tenemos que hacer declaración especial.
(5) los hilados-site.xml
Hilado es el archivo de perfil de marco, que especifica el nombre de nodo y las principales propiedades de nuestra NodeManager ResourceManager, el contenido del archivo de configuración de la siguiente manera:
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>huatec01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
En el código anterior, hemos configurado las dos propiedades. El primer atributo se utiliza para especificar la dirección de la ResourceManager, porque somos implementación de un solo nodo, podemos especificar huatec01; un segundo atributo para especificar el modo de reductor de adquisición de datos.
6, el sistema de archivos con formato
Primera puesta en marcha es necesario realizar hdfs NameNode -format sistema de archivo de formato, y luego empezar a hdfs e hilo, posterior puesta hdfs arranque directo e hilo pueden ser.
/usr/local/hadoop/bin/hdfs namenode -format
7, iniciar hdfs e hilo
cd /usr/local/hadoop/sbin/
sh start-dfs.sh
sh start-yarn.sh
#关闭hadoop
sh stop-dfs.sh
sh stop-yarn.sh
8, ver proceso hadoop
jps
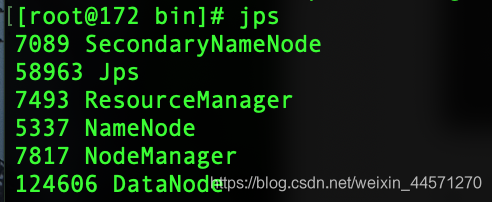 El acceso lo 172.16.193.200:50070
El acceso lo 172.16.193.200:50070
 acceso 172.16.193.200:8088, entrar en la interfaz de gestión de MapReduce:
acceso 172.16.193.200:8088, entrar en la interfaz de gestión de MapReduce:
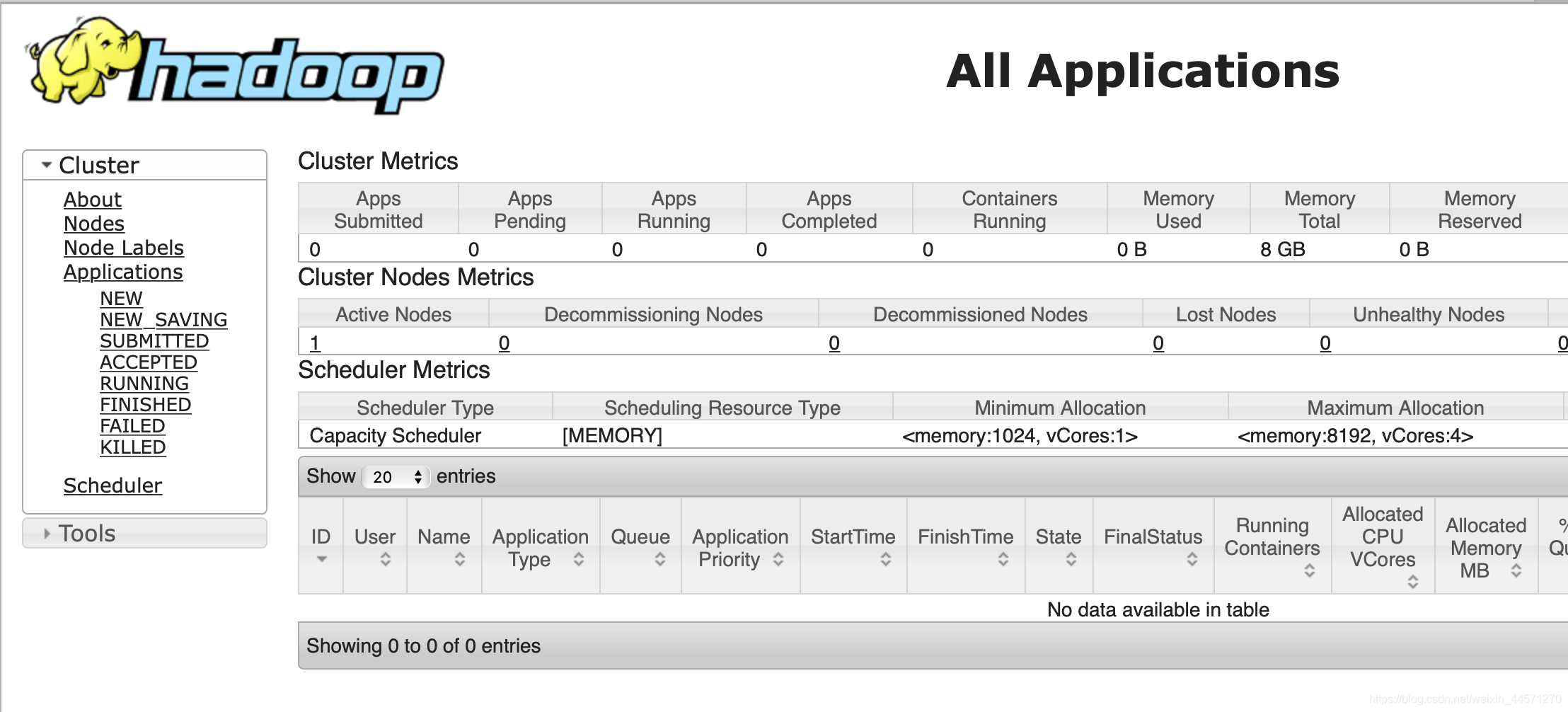 una implementación exitosa!
una implementación exitosa!
En segundo lugar, la automatización del despliegue hadoop pseudo-distribuido
#!/bin/bash
#authored by WuJinCheng
#This shell script is written in 2020.3.17
JDK=jdk1.8.tar.gz
HADOOP_HOME=/usr/local/hadoop
#------初始化安装环境----
installWget(){
echo -e '\033[31m ---------------初始化安装环境...------------ \033[0m'
sed -i '/SELINUX/s/enforcing/disabled/g' /etc/selinux/config
systemctl stop firewalld
wget -V
if [ $? -ne 0 ];then
echo -e '\033[31m 开始下载wget工具... \033[0m'
yum install wget -y
fi
}
#------JDK install----
installJDK(){
ls /usr/local/|grep 'jdk*'
if [ $? -ne 0 ];then
echo -e '\033[31m ---------------开始下载JDK安装包...------------ \033[0m'
wget http://www.wujincheng.xyz/$JDK
if [ $? -ne 0 ]
then
exit 1
fi
mv $JDK /usr/local/
cd /usr/local/
tar xvf $JDK
mv jdk1.8.0_141/ jdk1.8
ls /usr/local/|grep 'jdk1.8'
if [ $? -ne 0 ];then
echo -e '\033[31m jdk安装失败! \033[0m'
fi
echo -e '\033[31m jdk安装成功! \033[0m'
fi
}
JDKPATH(){
echo -e '\033[31m ---------------开始配置环境变量...------------ \033[0m'
grep -q "export JAVA_HOME=" /etc/profile
if [ $? -ne 0 ];then
echo 'export JAVA_HOME=/usr/local/jdk1.8'>>/etc/profile
echo 'export CLASSPATH=$CLASSPATH:$JAVAHOME/lib:$JAVAHOME/jre/lib'>>/etc/profile
echo 'export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin'>>/etc/profile
source /etc/profile
fi
}
#------hadoop install----
installHadoop(){
hostnamectl set-hostname huatec01
ls /usr/local/|grep "hadoop*"
if [ $? -ne 0 ];then
echo -e '\033[31m ---------------开始下载hadoop安装包...------------ \033[0m'
wget http://mirrors.hust.edu.cn/apache/hadoop/core/hadoop-2.8.5/hadoop-2.8.5.tar.gz
if [ $? -ne 0 ]
then
exit 2
fi
mv hadoop-2.8.5.tar.gz /usr/local
cd /usr/local
tar xvf hadoop-2.8.5.tar.gz
mv hadoop-2.8.5 hadoop
fi
}
#------hadoop conf----
hadoopenv(){
sed -i '/export JAVA_HOME=/s#${JAVA_HOME}#/usr/local/jdk1.8#g' /usr/local/hadoop/etc/hadoop/hadoop-env.sh
}
coresite(){
echo '<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS </name>
<value>hdfs://huatec01:9000</value>
</property>
<property>
<name>Hadoop.tmp.dir</name>
<value>/huatec/hadoop-2.8.5/tmp</value>
</property>
</configuration>'>$HADOOP_HOME/etc/hadoop/core-site.xml
}
hdfssite(){
echo '<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>'>$HADOOP_HOME/etc/hadoop/hdfs-site.xml
}
mapredsite(){
mv $HADOOP_HOME/etc/hadoop/mapred-site.xml.template $HADOOP_HOME/etc/hadoop/mapred-site.xml
echo '<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>'>$HADOOP_HOME/etc/hadoop/mapred-site.xml
}
yarnsite(){
echo '<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>huatec01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- Site specific YARN configuration properties -->
</configuration>'>$HADOOP_HOME/etc/hadoop/yarn-site.xml
}
#------hdfs 格式化----
hdfsFormat(){
echo -e '\033[31m -----------------开始hdfs格式化...------------ \033[0m'
$HADOOP_HOME/bin/hdfs namenode -format
if [ $? -ne 0 ];then
echo -e '\033[31m Hadoop-hdfs格式化失败! \033[0m'
exit 1
fi
echo -e '\033[31m Hadoop-hdfs格式化成功! \033[0m'
}
install(){
installWget
installJDK
JDKPATH
installHadoop
hadoopenv
coresite
hdfssite
mapredsite
yarnsite
hdfsFormat
}
case $1 in
install)
install
echo -e '\033[31m Hadoop自动化部署完成! \033[0m'
;;
JDK)
installWget
installJDK
JDKPATH
;;
Hadoop)
installWget
installHadoop
echo -e '\033[31m Hadoop安装完成! \033[0m'
;;
confHadoop)
hadoopenv
coresite
hdfssite
mapredsite
yarnsite
echo -e '\033[31m Hadoop配置完成! \033[0m'
;;
format)
hdfsFormat
;;
*)
echo "Usage:$0 {install|JDK|Hadoop|confHadoop|format}";;
esac
En tercer lugar, el error de determinación
1, puede ser incapaz de iniciar la sesión en la séptima hadoop inicio paso! Denegar inicio de sesión
 aparece esta frase.
aparece esta frase.
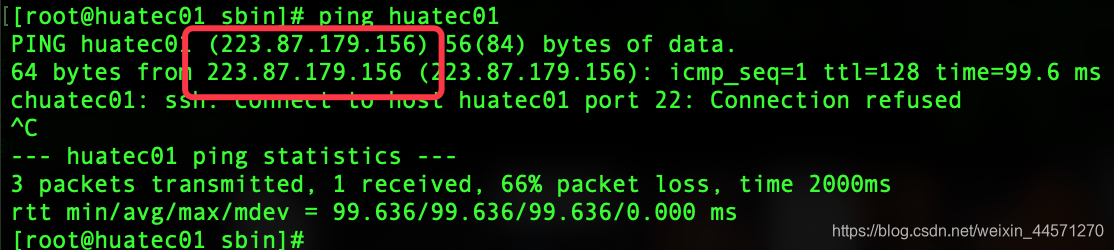 de ping acerca de nuestro anfitrión! Se encontró que el huatec01 cuando una resolución de nombres de dominio. tan
de ping acerca de nuestro anfitrión! Se encontró que el huatec01 cuando una resolución de nombres de dominio. tan
vim /etc/resolv.conf
 Eso es todo!
Eso es todo!
2, DataNode comenzado, pero sin interfaz hadoop DataNode
sexto paso de formatear inconsistencias en repetidas ocasiones ClusterID causado si se tiene en cuenta!
cd /tmp/hadoop-root/dfs/
VERSIÓN bajo el nombre de ClusterID bajo actual
y
VERSIÓN ClusterID bajo las inconsistencias en los datos actuales
a ser modificado en una, un servicio consistente reinicio hadoop!
