Introducción: El cerebro es la tecnología de núcleo del motor Baidu Baidu AI, incluyendo la visión, el habla, el procesamiento del lenguaje natural, mapas de conocimiento, la profundidad del aprendizaje de la tecnología de núcleo AI AI y la plataforma abierta.

Basado en Xilinx Zynq UltraScale + Edgeboard núcleo MPSoC acelerado programa es un componente clave de Baidu AI aceleró plataforma. Zynq que chip del procesador ARM integrado + GPU + FPGA (y Conexiones de vídeo la Decode ) de la arquitectura, tanto un procesamiento multi-núcleo, y de flujo de vídeo de decodificación capacidad de procesamiento de hardware, que comprende además unos programables características FPGA. Una función de sistema operativo Linux 4.14.0 profundidad ambiente de aprendizaje y pre-instalado, y Baidu plataforma de modelo del cerebro personalización (AIStudio, EasyDL, EasyEdge) de profundidad para llegar a través, para lograr el modelo de formación, despliegue, el razonamiento y la otra un servicio de ventanilla.

Baidu / Molino marcha conjuntamente tarjeta calculada estudio en profundidad FZ3 se basa en Xilinx XCZU3EG de Baidu plataforma de aceleración EdgBaord cerebro. Puede ser embebido en una variedad de formas de producto, la realización de aterrizaje de una variedad de aplicaciones de extremo AI de visión inteligente, seguridad inteligente, sistemas avanzados de asistencia al conductor (ADAS) y robots de próxima generación.
estudio en profundidad del molino / Baidu FZ3 calcula la tarjeta con la diversa y constantemente iterativo biblioteca modelo proporcionado por Baidu cerebro puede reconocer fácilmente la escena y la cara más humano, humano, animal y objetos y texto.

características:
- Con un precio tan bajo como 999RMB / 1299RMB, el alto costo placa de desarrollo Zynq / AI
- AI modelo de red FPGA arquitectura de computación escalable que puede adaptarse flexiblemente rápidamente Iteration
- recuento medido hasta 1.2TOPS fuerza, MobileNet hasta 100FPS, rendimiento potente
- Baidu cerebro y la plataforma de herramientas de compatibilidad sin fisuras, una ventanilla de la reducción del umbral de aplicaciones de la IA
- Pequeño, múltiples interfaces, buena escalabilidad, fácil de integrar una variedad de hardware inteligente
- configuración industrial, un alto nivel de excelencia en la elección de los materiales y la tecnología, la calidad de
AI potente rendimiento de computación y bajo consumo de energía
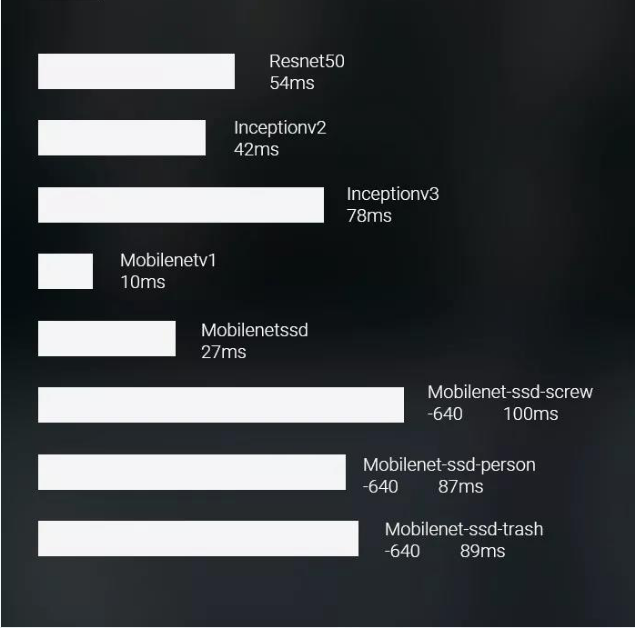
Mide el rendimiento de hasta 1.2TOPS, de cuantificar en el corte de la situación MobileNet hasta 100FPS, más de 20 veces el rendimiento de la CPU, el consumo de energía es solamente 5-10W.
modelo de casos sin recortar para cuantificar, calcular rendimiento de la tarjeta:
recursos de desarrollo ricos y herramientas de la plataforma
Baidu fisuras cerebro plataforma de herramientas de compatibilidad, una ventanilla AI reducir umbral de desarrollo

Excelente diseño del hardware
La junta basado en Xilinx Zynq UltraScale + MPSoC XCZU3EG, 4 Cortex-A53 + arquitectura de núcleo FPGA, a bordo de 2 GB / 4 GB DDR4 SDRAM (64 bits, 2400MHz) + combinación de 8 GB eMMC de almacenamiento. Pequeño y funcional, para incrustar en una variedad de formas de producto.
Interfaz Esquema:

1. Alto rendimiento, pequeño tamaño, fácil adaptación

2. Excelente calidad y década de ciclo de vida

Una amplia gama de escenarios de aplicación
Adecuado para la seguridad inteligente, inspección industrial, el diagnóstico médico, la inspección no tripulado vehículos aéreos, la investigación, los consumidores, aviones no tripulados y otros campos.

Actualmente los productos FZ3A y FZ3B han sido pre-choque, para más información, visite el sitio web oficial para averiguar sobre Cachemira Asesor: http://www.myir-tech.com/product/mys-czu3eg.htm