-
SparkContext está programado pyspark entrada enviar trabajos, tarea de distribución, la aplicación será registrado en SparkContext en. Un ejemplo SparkContext representa una conexión y Spark, sólo se establece una conexión antes de que puedan enviar trabajos al clúster. RDD puede crear y las variables de difusión de transmisión después de SparkContext instancia.
-
adquirir Sparkcontext, comenzando
pyspark --master spark://hadoop-maste:7077después del objeto pueden ser adquiridas por SparkSession Sparkcontext la impresión desde el punto de grabación de vista, SparkContext dirección de clúster maestro Spark está conectado aspark://hadoop-maste:7077

otra forma de obtener SparkContext se introduce pyspark.SparkContext creado. Nuevo archivo parkContext.py, de la siguiente manera:from pyspark import SparkContext from pyspark import SparkConf conf = SparkConf() conf.set('master','local') sparkContext = SparkContext(conf=conf) rdd = sparkContext.parallelize(range(100)) print(rdd.collect()) sparkContext.stop()Antes de ejecutar la primera chispa en el nivel de registro de directorio de configuración log4j.properties archivo de configuración del directorio conf de la siguiente manera:

registro de impresión, tal fondo no verá demasiada impresión! cúmulo reinicio chispa
corriendospark-submit sparkContext.py
Sparkconf objetos en el código anterior está sujeta a la chispa dentro de los parámetros de configuración y, a continuación vamos a explicar en detalle a. -
acumulador es un método utilizado para crear el Sparkcontext el acumulador. La creación de acumulador puede ser acumulado en cada tarea, y sólo puede soportar la operación de adición. Este método
es compatible con valor inicial pasado en el acumulador. Acumulador al acumulador en la presente memoria hacer adición de 1 a 50 como un ejemplo para explicar.
Accumulator.py nuevo archivo, de la siguiente manera:from pyspark import SparkContext,SparkConf import numpy as np conf = SparkConf() conf.set('master','spark://hadoop-maste:7077') context = SparkContext(conf=conf) acc = context.accumulator(0) print(type(acc),acc.value) rdd = context.parallelize(np.arange(101),5) def acc_add(a): acc.add(a) return a rdd2 = rdd.map(acc_add) print(rdd2.collect()) print(acc.value) context.stop()uso
spark-submit accumulator.pyRun -
método addFile de la adición de un archivo, llegar archivo usando método SparkFiles.get
Este método toma un camino, el método cargar el archivo en la ruta de acceso local a los nodos del clúster para cada nodo durante la operación de descarga de datos, la ruta puede ser una ruta local es también pero es hdfs ruta, o una dirección http, https, o TFP la URI. Si subes una carpeta, especifique el parámetro recursize en True. Subir archivos usando SparkFiles.get manera (nombre del archivo) para obtener.Si una ruta local, los requisitos locales de todos los nodos tienen la misma ruta del archivo, el archivo para encontrar cada nodo en el directorio local respectiva.
Nuevo archivo addFile.py, de la siguiente manera:
from pyspark import SparkFiles import os import numpy as np from pyspark import SparkContext from pyspark import SparkConf tempdir = '/root/workspace/' path = os.path.join(tempdir,'num_data') with open(path,'w') as f: f.write('100') conf = SparkConf() conf.set('master','spark://hadoop-maste:7077') context = SparkContext(conf=conf) context.addFile(path) rdd = context.parallelize(np.arange(10)) def fun(iterable): with open(SparkFiles.get('num_data')) as f: value = int(f.readline()) return [x*value for x in iterable] print(rdd.mapPartitions(fun).collect()) context.stop()Ejecutar
spark-submit addFile.py
este ejemplo es un archivo local para su uso, a continuación, tratamos hdfs archivo en la ruta.
Nuevo archivo hdfs_addFile.py, de la siguiente manera:from pyspark import SparkFiles import numpy as np from pyspark import SparkContext from pyspark import SparkConf conf = SparkConf() conf.set('master','spark://hadoop-maste:7077') context = SparkContext(conf=conf) path = 'hdfs://hadoop-maste:9000/datas/num_data' context.addFile(path) rdd = context.parallelize(np.arange(10)) def fun(iterable): with open(SparkFiles.get('num_data')) as f: value = int(f.readline()) return [x*value for x in iterable] print(rdd.mapPartitions(fun).collect()) context.stop()#查看hdfs的根目录 hdfs dfs -ls / #在根目录下创建/datas文件夹 hdfs dfs -mkdir /datas # 将本地目录中的num_data文件put至hdfs目录/datas/下 hdfs dfs -put num_data /datas/num_data # 查看是否拷贝成功 hdfs dfs -ls /datas # 打印hdfs目录中/datas/num_data中的内容 hdfs dfs -cat /datas/num_data
corridaspark-submit hdfs_addFile.py

Tenga en cuenta que el valor predeterminado addFile identificar la ruta local, si la ruta de hdfs, es necesario especificar hdfs://hadoop-maste:9000el protocolo, URI y la información de puerto.
Luego, busquen en la red lee la información del archivo. 182.150.37.49 en esta máquina, he instalado el servidor httpd. httpd configuración e instalación se refieren a mis notas esto: [link]
en / var / www / html / de la máquina servidor httpd instalado, los nuevos archivos num_data en este directorio, el contenido del archivo es de 100
a continuación, escribir http_addFile.py archivo leer en el código sólo en el nuevo archivo num_data servidor httpd.
Dice lo siguiente:
from pyspark import SparkFiles
import numpy as np
from pyspark import SparkContext
from pyspark import SparkConf
conf = SparkConf()
conf.set('master','spark://hadoop-maste:7077')
context = SparkContext(conf=conf)
path = 'http://192.168.0.6:808/num_data'
context.addFile(path)
rdd = context.parallelize(np.arange(10))
def fun(iterable):
with open(SparkFiles.get('num_data')) as f:
value = int(f.readline())
return [x*value for x in iterable]
print(rdd.mapPartitions(fun).collect())
context.stop()
Correr sparksubmit http_addFile.py
de lo anterior tres ejemplos, se puede observar que el poder del método addFile. Con este método, el pyspark tarea en funcionamiento puede leer los archivos de prácticamente cualquier situación de participar metros
recuento!
5. applicationId, registrarse con el grupo de ID de aplicación
from pyspark import SparkContext ,SparkConf
import numpy as np
conf = SparkConf()
conf.set('master','spark://hadoop-maste:7077')
context = SparkContext(conf=conf)
rdd = context.parallelize(np.arange(10))
print('applicationId:',context.applicationId)
print(rdd.collect())
context.stop()
- BinaryFiles leer archivos binarios.
El método de lectura de un archivo binario como audio, vídeo, imágenes, devuelve una tupla para cada archivo, un primer elemento de la tupla para la ruta de acceso al archivo, el segundo parámetro es el dos
archivos binarios contenidos.
He subido en el directorio / HDFS Datas / fotografías bajo las dos imágenes, usando BinaryFiles leer el directorio de datos / datas / fotos binario de imágenes
de archivos Nueva binaryFiles.py, de la siguiente manera:
from pyspark import SparkContext ,SparkConf
import numpy as np
conf = SparkConf()
conf.set('master','spark://hadoop-maste:7077')
context = SparkContext(conf=conf)
rdd = context.binaryFiles('/datas/pics/')
print('applicationId:',context.applicationId)
result = rdd.collect()
for data in result:
print(data[0],data[1][:10])
context.stop()
Ejecutar spark-submit binaryFiles.py
este método es muy fácil de leer archivos de datos binarios, especialmente con imágenes, tiempo de audio y vídeo.
- radiodifusion las variables
método de difusión para la creación de emisión de variables SparkContext, variables compartidas por más de 5 millones de difusión recomienda. mecanismo de difusión puede reducir al mínimo la red IO, con el fin de mejorar el rendimiento. Posteriormente ejemplo, transmitir una cadena 'hola', cada tarea recibe las variables de difusión, El regreso de la costura. Broadcast.py nuevo archivo, de la siguiente manera.
from pyspark import SparkContext ,SparkConf
import numpy as np
conf = SparkConf()
conf.set('master','spark://hadoop-maste:7077')
context = SparkContext(conf=conf)
broad = context.broadcast(' hello ')
rdd = context.parallelize(np.arange(27),3)
print('applicationId:',context.applicationId)
print(rdd.map(lambda x:str(x)+broad.value).collect())
context.stop()
Ejecutar spark-submit broadcast.py
partir de los resultados, distribuido ejecutar cada tarea son recibidos por la emisión hola variable.

- defaultMinPartitions.py obtener el número mínimo predeterminado de las particiones
from pyspark import SparkContext ,SparkConf
import numpy as np
conf = SparkConf()
conf.set('master','spark://hadoop-maste:7077')
context = SparkContext(conf=conf)
print('defaultMinPartitions:',context.defaultMinPartitions)
context.stop()
-
emptyRDD crear un RDD vacío, el RDD ninguna partición, ni ningún dato
sc = sparkContext sc.emptyRDD() rdd.collect() rdd.getNumPartitions()
-
getconf () devuelve el método la información de configuración de la tarea objeto
sc.getConf().toDebugString()

-
getLocalProperty y setLocalProperty obtener y establecer información de atributos en la secuencia de procesamiento local. Por ajuste de setLocalProperty, la propiedad se establece en el trabajo sólo en el hilo actual someterse, no para otros trabajos. Tipo de valor de la propiedad: clave
-
setLogLevel Ajuste el nivel de registro, esta configuración anulará el nivel de registro establece ningún definida por el usuario. Valor tiene: ALL, depurar, ERROR, FATAL, INFO, OFF, TRACE, WARN de salida mediante la comparación de los diferentes niveles de ambos registros, el registro puede ser visto que de salida diferentes niveles de registro son diferentes, pueden ser seleccionados por este el nivel de depuración de registro correspondiente.
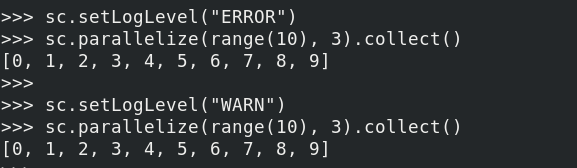

-
getOrCreate obtener o crear una objetos SparkContext, SparkContext objetos creados por este método es objeto singleton. El método puede aceptar un objeto Sparkconf.

-
hadoopFile leer 'viejo' es la interfaz de Hadoop HDFS proporciona formato de archivo.
`sc.hadoopFile ( '/ DATOS / num_data', inputFormatClass = 'org.apache.hadoop.mapred.TextInputFormat', keyClass = 'org.apache.hadoop.io .text 'valueClass =' ruta de archivo para el primer parámetro, el segundo parámetro es el formato del archivo de entrada, y el tercer parámetro es el formato de la clave, el valor de la cuarta formato de parámetro
sc.hadoopFile("/datas/num_data", inputFormatClass="org.apache.hadoop.mapred.TextInputFormat",
keyClass="org.apache.hadoop.io.Text", valueClass="org.apache.hadoop.io.LongWritable").collect()

Leerá el número de línea por defecto como la clave!
- la lectura de archivos de texto y archivo de texto saveAsTextFile ubicados en el HDFS
este método para leer el tipo de texto se encuentra en la mayoría de los hdfs simple de archivos

-
PARALLELIZE RDD usando creación conjunto pitón, gama función se puede utilizar, por supuesto, también puede ser usado para crear método dentro arange numpy

-
saveAsPickleFile y pickleFile RDD se guardarán como archivos comprimidos en formato pitón salmuera.
sc.parallelize(range(100),3).saveAsPickleFile('/datas/pickles/bbb', 5) sorted(sc.pickleFile('/datas/pickles/bbb', 3).collect())métodos ordenados utilizan argumentos clave inversa, se establece en True
-
rango (inicio, final = Ninguno, paso = 1, numSlices = None) proporcionado de acuerdo con el valor de inicio y la longitud del paso, creando RDD
numSlices para designar el número de particionesrdd = sc.range(1,100,11,3) rdd.collect() dir(rdd)
-
runJob (RDD, partitionFunc, particiones = Ninguno, allowLocal = False) que se ejecuta en una función de partición dada especificados
particiones para el número de la partición especificada, una lista. Si la partición especificada por defecto todas las particiones de ejecutar la función partitionFuncrdd = sc.range(1,1000,11,10) sc.runJob(rdd,lambda x:[a for a in x])0,1,4,6 especificado funcionan con una función de partición 2 **
rdd = sc.range(1,1000,11,10) sc.runJob(rdd,lambda x:[a**2 for a in x],partitions=[0,1,4,6])
-
directorio setCheckpointDir (dirName) puesto de control, el punto de control para la recuperación de errores cuando se produce una excepción, el directorio HDFS directorio debe.
Checkpoint directorio / Datas / puesto de control /sc.setCheckpointDir('/datas/checkpoint/') rdd = sc.range(1,1000,11,10) rdd.checkpoint() rdd.collect()Después de la carrera es completa, ver el / Datas / directorio hdfs puesto de control
encontró durante la operación de los datos que se conserva, si se produce una excepción durante el programa Spark se está ejecutando, el puesto de control se puede utilizar para recuperar anomalías en los datos.

-
sparkUser hacer el trabajo actual que se ejecuta el nombre de usuario
sc.sparkUser()

-
Volver horaInicio hora de inicio de la tarea
sc.startTime
que devuelve el tipo de valor de tiempo de milisegundos de largo, se puede convertir por medio de la herramienta de línea de tiempo en tiempo vista específica

-
Empleo de Identificación del método StatusTracker statusTracker () para la adquisición de un objeto, pueden ser adquiridos a través del objeto activo, actividad etapa de identificación. La información del trabajo, la etapa de información. Puede utilizar este objeto para supervisar el estado de las operaciones del centro de datos que se ejecutan en tiempo real.
t = sc.statusTracker() dir(t)
-
método stop () se utiliza para detener la conexión SparkContext y el clúster. Los procedimientos generales por escrito la última línea de esta frase debe añadirse para asegurar que el trabajo se ejecuta después de la finalización de la agrupación de clúster de conexión y desconexión.
sc.stop() -
uiWebUrl volver a la URL de la Web
sc.uiWebUrl
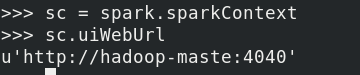
-
unión (DDR) en combinación con una pluralidad de rdd rdd
rdd1 = sc.parallelize(range(5),4) rdd2 = sc.parallelize(range(10),3) rdd3 = sc.union([rdd1,rdd2]) rdd3.collect()
Obtiene el número de particiones RDD:
rdd.getNumPartitions()

-
versión para obtener el número de versión
sc.version

