- resumen :
- Por la extracción de entidades en cuestión , se pueden obtener en el centro del nodo entidad mediante la consulta de las entidades subgrafo base de conocimiento en una base de conocimientos, cada borde nodo o subgrafo se puede usar como una respuesta candidato. , Llevada a cabo mediante la observación de ciertas reglas o plantillas basadas en el problema de la extracción de información, obtener la caracterización de preguntas fuertes y vectores de características respuestas candidatos, el establecimiento de la clasificación, la selección de candidatos respuestas a través de la función de vector de entrada para obtener la respuesta final.
- métodos:
- En la base de conocimientos como una colección de 'tema' interconectados. A preguntas en lenguaje natural pueden incluir uno o varios tema, entonces podemos encontrar el tema relevante en la base de conocimientos, y luego extraer la respuesta desde el nodo asociado con un nodo de tema pocos saltos . Este punto de vista se llama la gráfica autor tema, suponiendo que la respuesta se puede encontrar en la figura. del autor objetivo es extraer proceso a través de una combinación de una gran cantidad de problemas y elementos de identificación del tema de los mapas para automatizar las mayores posibles respuestas medida.
-
- Un reto consulta KB lenguaje natural se compara con la sintaxis KB, relativamente carácter informal de la consulta. Por ejemplo, la pregunta: ¿Quién engañó celebridad A? La respuesta puede ser recuperada a través de la relación celebrity.infidelity.participant Knowledge Base, pero la frase conexión trampa en el conocimiento y la relación formal no está claro . Para resolver este problema, el mejor intento es un mapeo de los parámetros de reverberación predicado triples en triples relación Freebase.
- antecedentes:
- base de conocimientos Q y A se enfrenta a dos retos principales: el modelo y los datos.
- modelo de desafío se encontró que mejor representa la importancia del problema, convertirlo a ejecutar la consulta y en la base de conocimientos. La mayoría del trabajo para resolver el problema representado por los diversos puente intermedio que comprende una combinación de la sintaxis de clasificación, de contexto de sincronización gramática, el árbol de dependencias, la cadena principal, el árbol de sensor. Estos funcionan de manera muy eficaz en el control de calidad, a pesar de la lógica subyacente requiere anotación mano.
- Q y A base de conocimientos para resolver el problema desde la perspectiva de la IE: Aprendemos directamente al modo de control de calidad, representada por Freebase resolución de la estructura de dependencia y preguntas de respuesta de los candidatos, sin el uso del sentido común en el medio de la representación.
- datos reto pueden ser considerados como texto o coincidencia de patrones (texto): dos cuerpos estructura de acoplamiento / o base de datos de mapa (en la extensión) y la relación entre el texto NL KB.
- base de conocimientos Q y A se enfrenta a dos retos principales: el modelo y los datos.
- características fig:
- resolución de dependencias
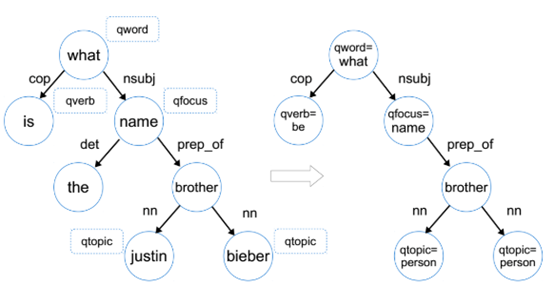
La primera es la palabra de interrogación (palabra interrogativa, QWord), tales como qué, quién, cómo, etc. Ejemplos de palabras de uso común 9 preguntas, entonces el foco de la cuestión (foucs de interrogación, qfocus), esperada tipo de respuesta, como el nombre, el dinero , tiempo, etc., el autor aquí no entrena el clasificador, sino que simplemente se extrae depende término QWord como qfocus; a continuación, emitir un verbo (verbo pregunta, qverb), tal como es, jugar, tomar, el verbo principal del problema extracto, también puede implicar problemas verbales tipos de respuestas, tales como el juego verbo, detrás puede tomar instrumento, película, equipo y así sucesivamente. La última cuestión es el tema de (tema cuestión, qtopic), cuestiones temáticas nos ayudará a encontrar la página Freebase, sólo tiene que poner en práctica una entidad denominada reconocimiento encuentra cuestiones temáticas. Tenga en cuenta que el problema puede ser más de un tema.
-
- Figura problema
- Si un nodo está marcado con el problema en el que, el nodo se sustituye entonces con las características problemáticas, tales como lo que → QWord = lo
- Si un nodo etiquetado entidad nombrada qtopic, a continuación, se reemplaza con el nombre de nodo de la entidad en la forma de, por ejemplo Bieber → qtopic = persona
- Deseche todos los calificadores de nodos hoja, preposición o puntuacion
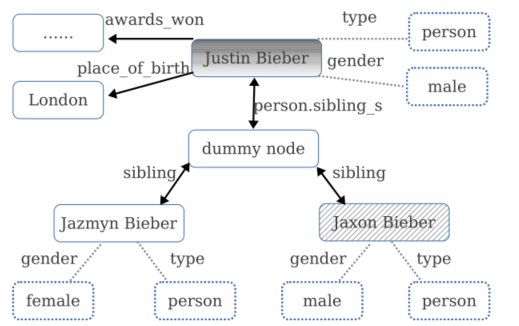
- Las relaciones y atributos de una diferencia importante es que los parámetros son relaciones de nodos y atributos de los parámetros es un nodo, una cadena, tales como place_of_birth es la relación de Justin Bieber Justin Bieber y la propiedad de Londres género masculino.
- Figura problema
- Mapeo relacional
- Queremos construir una tabla describe las relaciones de correspondencia entre la base de conocimientos de base libre y las palabras del lenguaje natural, el objetivo es encontrar las mejores posibles problemas de relación. Dado un problema Q vector de la palabra w, tenemos que encontrar la relación entre R, de manera que la probabilidad P (R | Q) como máximo. Debido al ruido y la integridad de la fuente de datos, se utiliza en lugar de la verdadera probabilidad P ~ P. Para mayor comodidad de cálculo, en el supuesto de independencia condicional entre las palabras, Naive Bayes obtenidos:
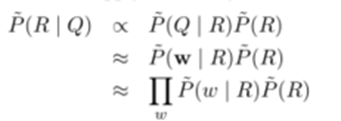
Una relación puede estar compuesto por una serie de relaciones de niños, tales como people.person.parents relación niño de personas, la persona, los padres . hijo entre los supuestos de independencia condicional:

-
- Extracción de Características
- Problemas en la que: cada borde e (s, t) en cuestión dispone en los dibujos, la extracción de s, t, s | t, s | e | t como una característica. Por ejemplo, prep_of borde (qfocus = nombre, hermano) , extraer las siguientes características: qfocus = nombre, hermano, qfocus = nombre | hermano, qfocus = nombre | prep_of | hermano.
- función de respuesta candidato: un nodo relaciones y atributos que distinguen La respuesta es muy importante. Para un tema mapa problema correspondiente, extraemos todas las relaciones y los atributos de cada nodo como una característica.
- Extracción de Características
Vamos a emitir una característica y un candidato función respuestas juntos, para que pueda capturar la relación entre el nodo de modo de pregunta y respuesta.
Por ejemplo, la pregunta - respuesta combinación de características: qfocus = dinero | node_type = moneda.
-
- modelo de formación
Seremos tratados como tarea de clasificación binaria en Freebase Q, para cada nodo de mapas conceptuales, extraemos características y respuestas para determinar si el nodo . Cada pregunta por kit Stanford CoreNLP y el proceso de shell-modelo. Luego cuenta y la función de nodos para cada nodo, una combinación de problema (combinar). Para 3000 tema del conjunto de entrenamiento, hay 3 millones de nodos (cada uno un tema mapa 1000 nodos), 7 millones de tipo de entidad. En la formación en diferentes modelos y encontró que L1 regularizado logística mejor rendimiento de regresión.
-
- experimento
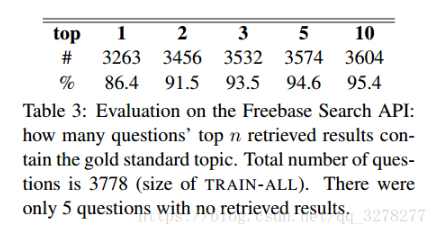
En primer lugar, para un problema dado, tenemos que localizar el nodo de tema apropiado problema. Todas las entidades nombradas calificadas por Freebase API de búsqueda. WEBQUESTIONS no sólo marcan la respuesta, y conocen la respuesta a un tema de qué nodo. Por lo tanto, podemos evaluar recuperar el rango de Freebase API de búsqueda usando el conjunto de entrenamiento.
Una vez palabras clave, mediante la consulta de la API de Freebase tema puede ser recuperada con el tema. A continuación, es el proceso de extracción de características y modelo de tren.
-
- resumen
Hemos propuesto un método de datos de configuración de la fuente (a Freebase) preguntas de forma automática. Los problemas asociados con las características descritas en modo de respuesta Freebase, e implementos los resultados más avanzados en corpus QA equilibrada y realista. Todo el proceso es el primer problema a resolver los problemas se resuelven dependen mapa, tema de reconocimiento de entidades que entonces se llamaba extractos, tema en los mapas de consulta FreeBase la base de conocimientos, el problema de extracción - el candidato responde a una combinación de características, el entrenamiento del clasificador. Por lo tanto, si el sujeto en la base de conocimientos no existe, entonces el problema no se puede resolver. Mientras tanto, algunos de los razonamientos del problema es imposible de resolver, como Xiao Ming mucho mayor que el rojo.