[table of Contents]
- Chapter 1 Overview
- Chapter II: The overall data tiering
- Chapter 3: overall implementation framework
- Chapter 4: Metadata
- Chapter V: ETL
- Chapter 6: data validation
- Chapter 7: Data standardization
- Chapter 8: de-duplication
- Chapter 9: incremental / full amount
- Chapter X: zipper processing
- Chapter 11: Distributed Processing increment
- Chapter XII: columnar storage
- Chapter XIII: logical data model (model number of bins)
- Chapter XIV: Data Model Reference
- Chapter XV: dimensional model
- Chapter XVI: slowly changing dimensions
- Chapter XVII: Data Rollback
- Chapter XVIII: About Report
- Chapter XIX: Data Mining
Data Warehousing practice-talk (five) ETL
ETL is the core data warehousing, and it is the largest part of the workload. The so-called ETL, noted earlier: abbreviation Extract-Transform-Load of. Extraction - Conversion - loading. It is extracted from the source system through a series of processing (modification), and finally loaded into the data warehouse. As long as the data processing done will know, that the Transform (converting) process is actually composed of many sequential process steps, conditions thereof.
ETL platform should include the following basic functions:
- Can extract data from different data sources, supports multiple databases, various storage media to read files from the file system or the like.
- Numerous number of management conversion program, you can clearly know what each program is doing.
- Support calls from extension handler definition.
- Support combinations of organic conversion process, with the same workflow, the order may be, branching, synchronization.
- Support the load data into different data storage systems.
The above are just the most basic functions, in fact, for the processing of large amounts of data, often need to consider the cluster, to achieve a distributed data processing. such as:
- Scale work node management, exception recovery, error metastasis.
- It provides a graphical interface for the design processes.
- Built-in many data processing functions.
This is a very complex system of. We generally say that a system is basically only 20% of the code is to achieve normal, basic function, and the remaining 80% of the code is to handle exceptions and to enhance the experience.
Early popular ETL tool DataStage and Informatic basically dominated. expensive. Of course, they are very powerful, graphical interface to do very well, drag drag drag to complete the basic ETL development, a powerful metadata management capabilities. There are many other functions, such as data mapping, blood tracking, support a variety of conventional processing mode and so on. Then do a data warehouse students basically have a dream, do yourself a good ETL tool. Thanks to the development of the open source community, now have a choice of non-commercial software, and basically do not need to own.
More mature, well-known open source ETL tool Kettle and probably should be the Airflow the bar. Very good tool to support big data, support for distributed, graphical interface. I think the biggest difference is Kettle of Java, Airflow is Python. Python is very popular now, do data processing is very gradual, but for those who like the old Java programmers, Java by calling Python handler, a little trouble.
Incidentally, Kettle Pentaho company is out, Mondrian is out of this company. Will be mentioned later, this is the year a very powerful tool for open-source ROLAP.
Below is an example of a kettle: the
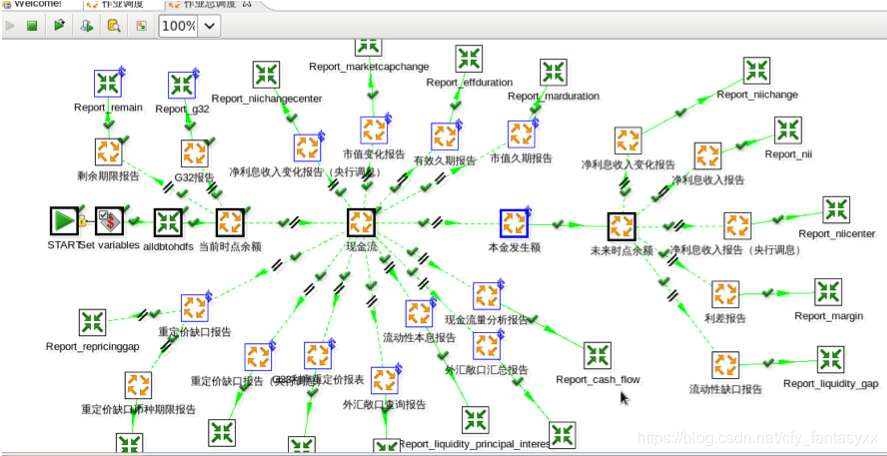
current relatively complete open source ETL is a company out of the open source, open source community is not supported. If applicable, actually see their ideas. Of course, some people put some data loading tools (such as Sqoop), data pipeline tools (such as Kafka), also considered ETL tool. And I think it's just part of ETL, ETL in the implementation process can go by, but not all of the ETL. Of course, in certain scenarios, such as high real-time data requirements, treatment is not complicated (direct load), also suggested that future Kafka is the data processing.
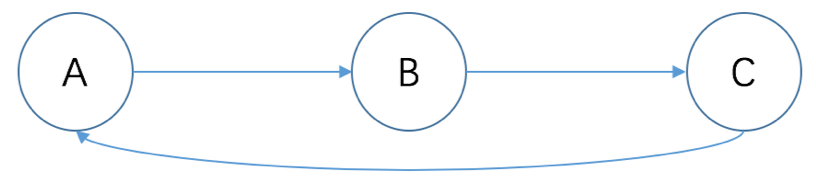
In any case, the core is a defined sequence of ETL processing tasks. In fact, just the same workflow. But generally for OA (office automation) workflows for each step are basically the people involved, and the flow of data processing are generally silent execution. This resulted in a now popular word - directed acyclic graph (DAG). It not advanced mathematical theory, the so-called directional, that is, between the two nodes is the direction from A to B to A. B is not possible to No ring, no circuit is required, such as A to B, B to C, C back to A, a loop is. There loop will result in an endless loop, after all graphical process definition is very difficult to decide to move forward or back depending on various circumstances of program execution. Moreover, re-execute the previous steps, it may be a disaster for the existing data.
ETL tools generally provide a large number of built-in processing, such as map data (the Mapping), which is a field from a table corresponds to a field in another table. There are similar projections, selected, combined Union, join the connection and other operations. But rarely used in the actual processing. The vast majority of the data conversion is processed by a program of its own (based metadata-driven) with. At least our practical experience is, one to one mapping of complete machinery, a simple program to get, you do not need to drag for a long time; complex mappings have to pull a line associated with a custom program.
So we can say that the majority of successful data processing platform is composed of a plurality of data processing program fragments. Corresponding to the program executed by the scheduling means scheduling ETL. However, such a handler may be many, such as the bank's data warehouse platform there are more than thousands of handlers. Manage these programs is very important.
Therefore, we can manage to focus on the numerous processing program fragment. A good data handler segment should have the following characteristics:
- Pure function: even considered an indicator of an indicator, handling a table on a table, do not put too many things to do on a program which can do what we can clearly by a simple description;
- Metadata drive: as far as a parameter using the metadata development, avoid hard-coding table or field names, and even common indicators should also be parametric equation processing;
- Clear input and output: input what data, what data output, can be formally clearly defined;
- Comes rollback feature: how to handle the error occurred after he rolled back, or call the Public rollback procedures, but there must be a corresponding rollback procedures or mechanisms;
Do not worry too much run a program in trouble, ETL scheduling tool is used to do this thing. Should be concerned about is how to effectively manage so many procedures, so that the team understand, and follow-up took people understand what each program is doing. Practice tells us, expect first written set of procedures for documentation and redevelopment program, or vice versa, are invalid, the end result is not finished project, documents and programs you do not correspond, the effort to come up with a fee a pile of garbage.
Fortunately, modern technology has given us a good software tools. Swagger using similar tools, in the development of the code written in accordance with certain specifications comment, and then generates the interface document, the document is converted into the final metadata content. This will ensure maximum consistency of documentation and procedures, programmers just need to keep good programming practice - to write an annotated program - without additional documentation workload.
To be continued.
