By default, the Spark program has finished running after the window is closed, you can not see the log of the Web UI (4040), but by HistoryServer can provide a service by reading the log file so that we can run at the end of the program, still be able to view during operation. This blog, bloggers will bring you a detailed process configuration JobHistoryServer on the Spark for everyone.

1. Go to the conf file in the installation directory folder spark
cd /export/servers/spark/conf
2. Modify the profile name
vim spark-defaults.conf
spark.eventLog.enabled true
spark.eventLog.dir hdfs://node01:8020/sparklog
Note: The directory on HDFS need to be present in advance
hadoop fs -mkdir -p /sparklog
3. Modify spark-env.sh file
vim spark-env.sh
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000
-Dspark.history.retainedApplications=3
-Dspark.history.fs.logDirectory=hdfs://node01:8020/sparklog"
Parameter Description:
spark.eventLog.dir : the Application during operation all information is recorded in the property path specified;
= 4000 spark.history.ui.port the WEBUI access port number 4000
spark.history.fs.logDirectory = hdfs: // node01: 8020 / sparklog After you configure the property when start-history-server.sh do not need to explicitly specify the path, Spark History Server page to show only the specified path information under
spark.history.retainedApplications = 30 specifies the Application save the history of the number, if more than this value, the old application information will be deleted, this is the number of applications in memory, rather than the number of applications displayed on the page.
4. synchronization profile
Here you can use scp command, xsync custom command can also be used, how to use xsync refer to <and xsync (synchronous file directory) with your writing linux super useful script --xcall (synchronous command execution)>
xsync spark-defaults.conf
xsync spark-env.sh
5. Restart Cluster
/export/servers/spark/sbin/stop-all.sh /export/servers/spark/sbin/start-all.sh
6. Start the log server on the master
/export/servers/spark/sbin/start-history-server.sh
7. Run a PI calculation procedure of Example
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--executor-memory 1G \
--total-executor-cores 2 \
/export/servers/spark/examples/jars/spark-examples_2.11-2.2.0.jar \
100
Until after the run is completed, the input from the browserhttp://node01:4000/
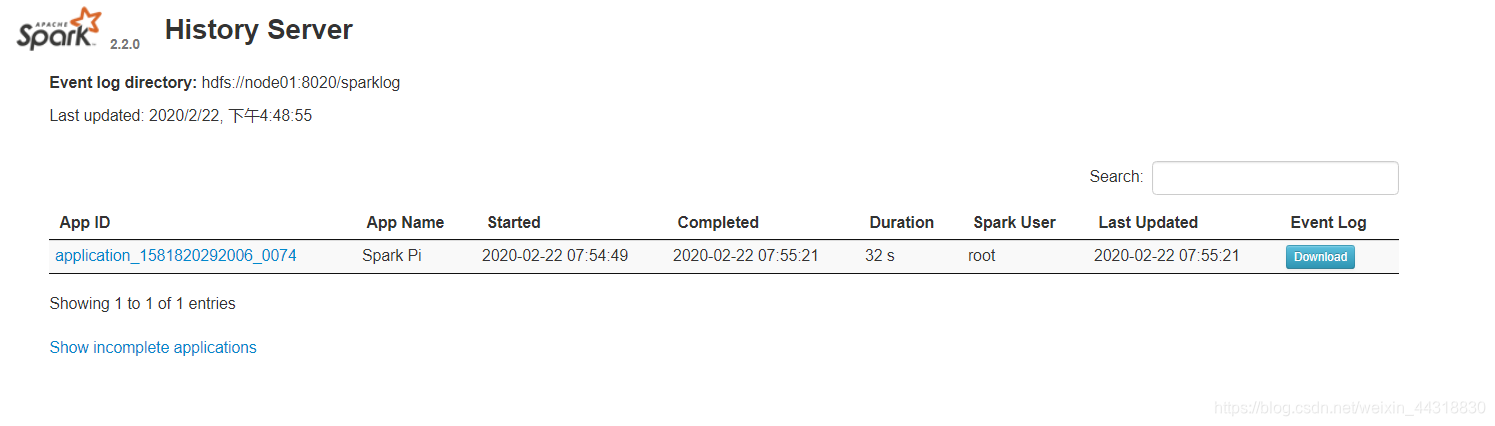
- If you experience problems Hadoop HDFS's write permissions:
org.apache.hadoop.security.AccessControlException
solution:
Adding follows hdfs-site.xml, the closure authority verification
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
The share on here, benefiting small partners or friends are interested in big data technology thumbs remember little attention bacteria yo ~

