python semicolon
The default is to wrap in python to mark the end of one line statement.
a = "xxxx"
print(a) # xxxxThis code is very simple, because a = "xxxx"the back has no content of a new line, then this statement on behalf of the end. But in python we can also specify a semicolon to specify the statement ended.
a = "xxxx" ; print(a) ; b = 1; print(b)
# 输出内容
"""
xxxx
1
"""When we can see that a = "xxxx"after a specified semicolon behind, on behalf of the statement ended. Then parsing python and will not jump directly to the next line, but will continue to look back, even if there has been among the spaces, but all in a row, so the python will find print(a), and then continue to look backwards. Although doing so is possible, but we do not recommend such an approach, such an approach is purely sick, of course, we demonstrated here will not forget.
Another example is the if statement, sometimes we write in a line of cases occur when.
a = 123
if a > 100: print("a > 100"); print("这一个print和上一个print具有相同的缩进")
else: print("a < 100")
"""
a > 100
这一个print和上一个print具有相同的缩进
"""If the if statement written in a row, a block of code statements should be only one, like two print in a row we write here is problematic, and that the two print indentation level is the same, namely:
a = 123
# 这行代码
if a > 100: print("a > 100"); print("这一个print和上一个print具有相同的缩进")
# 等价于:
if a > 100:
print("a > 100")
print("这一个print和上一个print具有相同的缩进")So we write a statement only one line, do not attempt to use a semicolon multi-line statement written on one line. For if statement, for loop, and so on, if only one line of code inside it, you can write in a row, can be written if condition: statementor for i in loop: print(i)this form, but note that if the statement block more than one line, and then write this will bring confusion.
About python statements, according manifestation of our interactive interface can be divided into two types:
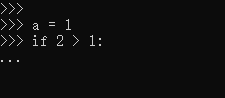
We see that when we enter the a = 1time by pressing Enter, began to appear in the next line is >>>, this means that the single statement is over. But when we enter the if 2 > 1:time by pressing Enter, the next line is emerging ..., which means that this line statement is not over, like if xx:, for xx:, while xx:, def xx():, class xx:and so with this :statement, usually require multiple lines to express, once so write press Enter, it means that there must have been below the content, but also with indented, there will be an interactive interface .... And this statement we can only appear once in a row, for example:

It was written by a different syntax check, because there were two of them :, we say that such a statement can only occur once a row. Of course, certainly no one would do it, so they know like.
python backslash
First, in python, the default is the newline character as a statement, but if a long line of code, we need to separate multiple lines to write how to do it? The answer is to use a backslash \, backslash represents an escape in python.
a = \
123456
# 当出现了\,表示表示转义,意思就是使后面的换行符失去效果,这样python就不会认为这条语句结束了
# 因为123456前面还有一些空格,因此等价于,a = 123456
a = \
123456
# 这行代码就等价于a = 123456了Another example string
a = "这是一段很" "长的字符串" "具体有多长我也不知道"
print(a) # 这是一段很长的字符串具体有多长我也不知道Python string in Comparative specifically, no explicit use of the plus sign. If a plus sign, like this code will first create three strings, and then spliced together. If you do not apply the plus sign, then it means to create a string, python when parsing will know that this is a string, just write separated.
a = "这是一段很" \
"长的字符串" \
"具体有多长我也不知道"Of course, we can also write separately, but to use \the newline escape out.
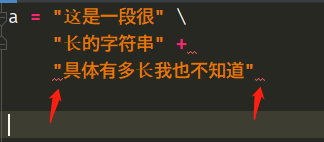
如果把\改成+号则是不行的,这个在golang里面可以,但是不同的语言的语法检测不一样,python中是以换行符作为语句结束的,当我们出现了+之后,后面啥也没有了,直接换行语句结束,那么这是无法通过语法检测的。所以+后面出现了红色波浪线,而且我们看到第三行字符串两边也出现了红色波浪线,这是因为缩进不对造成的,因为上面的语句已经结束,这是一条单独的语句,因该靠在左对齐,而这里显然没有对齐,而是出现了缩进或者空格。
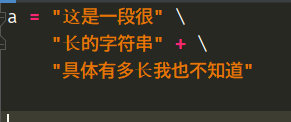
这样写是可以的,此时就等价于"这是一段很长的字符串" + "具体有多长我也不知道"。
但是还有一个特殊情况,那就是出现了括号。

我们看到这样写也是没有问题的,因为python在检测代码的时候发现了小括号的左半部分,那么即便出现了换行,python也不会认为语句结束了,只有当再找到小括号的右半部分,python才会认为语句结束了,所以此时我们是不需要\的。
再来看几个需要动点脑筋的:
a = "这是一段很"
"长的字符串"
"具体有多长我也不知道"
print(a)
# 会打印什么呢?只会打印这是一段很,因为遇到换行符语句结束了,下面两行只是创建两个字符串对象,而且还没有赋值,因此创建完之后就被销毁了。
a = "这是一段很" \
"长的字符串"; \
"具体有多长我也不知道"
print(a)
# 会打印什么呢?注意第二行出现了;会打印这是一段很长的字符串,因为我们手动指定了;,表示结束这段语句。后面出现的"具体有多长我也不知道"语句也是只创建了一个字符串对象,没有赋值,创建完毕直接销毁。
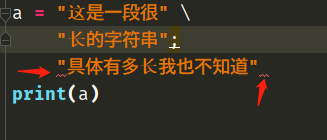
我们发现如果把第二行的\去掉了,这里又出现了红色波浪线,这个问题我们上面说过了。因为第二行出现了;,那么第三行就是单独的语句,所以应该要靠在左边。
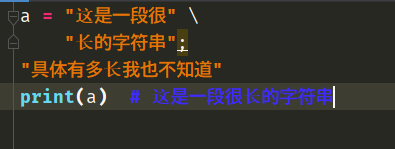
这样写是没问题的,但是第三行还是如我们之前所说,只是创建了一个字符串对象
python中的转义与r""
python中的转义,也是一个老生常谈的问题了。python中的转义我们上面说了是通过反斜杠来实现的,\有两个作用:一个是和一些特定的字符组合从而具备特殊意义(\n,\t,\r等等),另一个就是使python中的某些本来就具有特殊意义的字符失去其意义。
a = "my name is \nVan"
print(a)
"""
my name is
Van
"""
b = "my name is \"van"
print(b) # my name is "van我们看到\和字符n组合整体形成了换行。而\和"组合则并不是变成新的什么东西,而是使"失去其本来的意义,因为本来遇到"表示字符串结束了,但是前面出现了\,使得"失去了其具有的意义,遇到下一个"才表示字符串结束。而中间那个"则是正常输出了出来,但是\却不见了,因为\和"组合就等于"
当然上面都很简单,我想说的是如果字符串的开头出现了r,会是什么情况呢?
a = "my name is \nVan"
b = r"my name is \nVan"
print(a)
"""
my name is
Van
"""
print(b) # my name is \nVan如果是r""这种形式,表示的是这个字符串是原生的,这里的r表示raw。里面出现了任何东西都当成普通字符串,什么\n啊,\t啊,就是普通的字符串。但是我们说过:\具有两个作用
1:和某些特殊字符组合,从而具备一些特殊意义
2:使得某些本来就具有特殊意义的字符,失去其意义。
而r""这种形式,只会限制\的第一个作用,却不会限制其第二个作用。
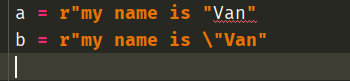
我们看到即使加上了r,第一行语句还是不合法的,因为"表示字符串的边界,因此我们即使加上了r,对于"依旧是无能为力的,这时候还是需要\
a = "my name is \"Van"
b = r"my name is \"Van"
print(a) # my name is "Van
print(b) # my name is \"Van然后我们又观察到了一个奇特的现象,当我不加r的时候,\"就表示",而加上了r,\"则表示\",因为r表示原生的,\会原原本本的输出出来。但是我们说了,r不会限制\的第二个作用,\不仅输出了出来,还使得"失去了其原本的意义。
最后引出python中一个比较让人费解的问题,估计已经有人猜到了,那就是字符串结尾出现了\
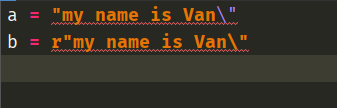
这个时候我们发现,这两行代码都是不合法的。第一行代码不合法我们能理解,因为右边的"表示字符串的结尾,现在我们使用\让其失去了其本来的意义,而后面又是空行导致相当于写了一半的语句结束了,所以不合法能够理解。但是第二行呢?不是说\表示原生的吗?为什么还是不合法的呢?显然还是如我们之前说的,r限制不了\的第二个作用,也就是第二行的\依旧会使得"失去其意义,导致同样是写了一半的语句强行结束了。因此解决办法就是再来一个\,形成\\。
a = "my name is Van\\"
b = r"my name is Van\\"
print(a) # my name is Van\
print(b) # my name is Van\\但是我们发现第二行代码的输出多了一个\,因为不加r的话,\\等价于\,因为第一个\再使得第二个\失去意义的时候,其使命也就结束了,因此只会输出一个\。但是对于有r的字符串来说,\就表示普通的字符,所以是什么就输出什么,只不过即便它是普通字符,依旧具备第二个功能。因此对于第二行有r的字符串来说,第一个\不仅让第二个\失去了意义,使得它不能再干扰结尾的",而且两个\都会原本的输出出来。
如果\出现在了其他位置呢?
a = "my nam\e is Van"
b = "my nam\\e is Van"
print(a) # my nam\e is Van
print(b) # my nam\e is Van我们发现对于两个结果输出是一样的,因为\和字符e无法形成具有特殊意义的字符,而且e也是一个普通的字符串,不具备什么特殊意义。所以对于第一个来说,就直接把\完整的输出了,但是不推荐这种写法。如果想加上一个\的话,第二行代码才是正规做法,两个\\表示一个\。如果就只想写一个\的话,可以用我们之前说的r""这种形式。
a = r"my nam\e is Van"
b = r"my nam\\e is Van"
print(a) # my nam\e is Van
print(b) # my nam\\e is Van通过r""也是可以实现的。
a = "\u6398"
b = "\\u6398"
c = r"\u6398"
print(a) # 掘
print(b) # \u6398
print(b) # \u6398而且python中\u前缀表示的是Unicode,如果不想让其显示成汉字的话,那么也是有两种做法,要么是通过多加一个\,要么通过r""这种形式声明一个字符串。
