
Welcome to the Kangaroo Cloud 09 product feature update report. In this report, we adhere to the concept of equal emphasis on innovation and optimization, and carry out in-depth polishing and comprehensive upgrade of the product. The improvement of every detail is our unremitting pursuit of excellent quality. We hope that these new functions can help your business operations and development, making the road to digital transformation smoother.
The following is the content of Kangaroo Cloud Product Function Update Report Issue 09. For more exploration, please continue reading.
Offline development platform
New feature updates
1.Task template
Background: Customers hope to maintain daily common code templates offline and directly reference them during data development.
The difference between templates and components:
1. Editing is supported after the template code is referenced, but editing is not supported after the component is referenced.
2. Template changes will not affect the referenced tasks, but component changes will affect the referenced tasks.
New feature description: Supports project code templates and tenant code templates for each task type, and supports referencing code templates when creating tasks .
2.shell on agent/python on agent adds new project dimension control
background:
Shell on agent is a special task type for offline platforms.
The Shell task is not run directly on the cluster-deployed machine, but the Shell is run on an independently deployed server node. Because one offline task requires two cores, if there are many Shell tasks in the customer scenario, it is easy to fill up the cluster resources . Therefore, running tasks such as Shell and Python on independently deployed nodes can effectively reduce the pressure on the cluster.
There is currently a problem. As long as the customer configures the node and server user on EM and the console, all projects under the cluster can use the configured node and server user. This poses a security issue. For example, for users with high permissions such as root, customers pay more attention to security issues and do not want all projects to be able to use this account. Therefore, it is necessary to design a solution that can control the configuration of server nodes and server users to solve this problem.
Description of new features:
1. The console controls node and server user permissions through project authorization.
2. Tasks in offline projects support selecting authorized server nodes and users.
Function optimization
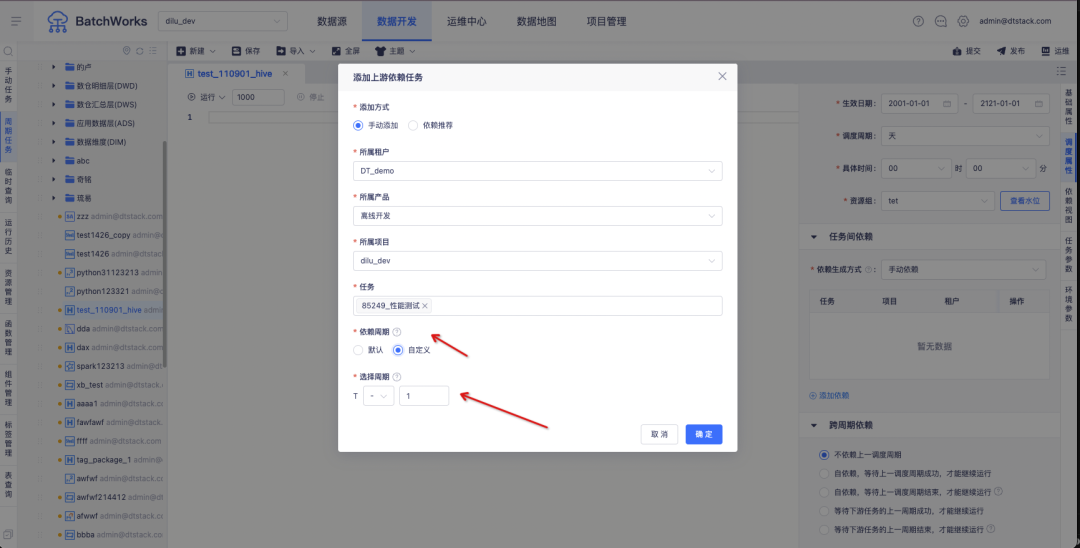
1. Scheduling configuration optimization, which can control any periodic instance that relies on upstream tasks
background:
Currently, scheduling Zhongtian tasks can only rely on the upstream instance of the current cycle by default. Customers may have the following scenarios:
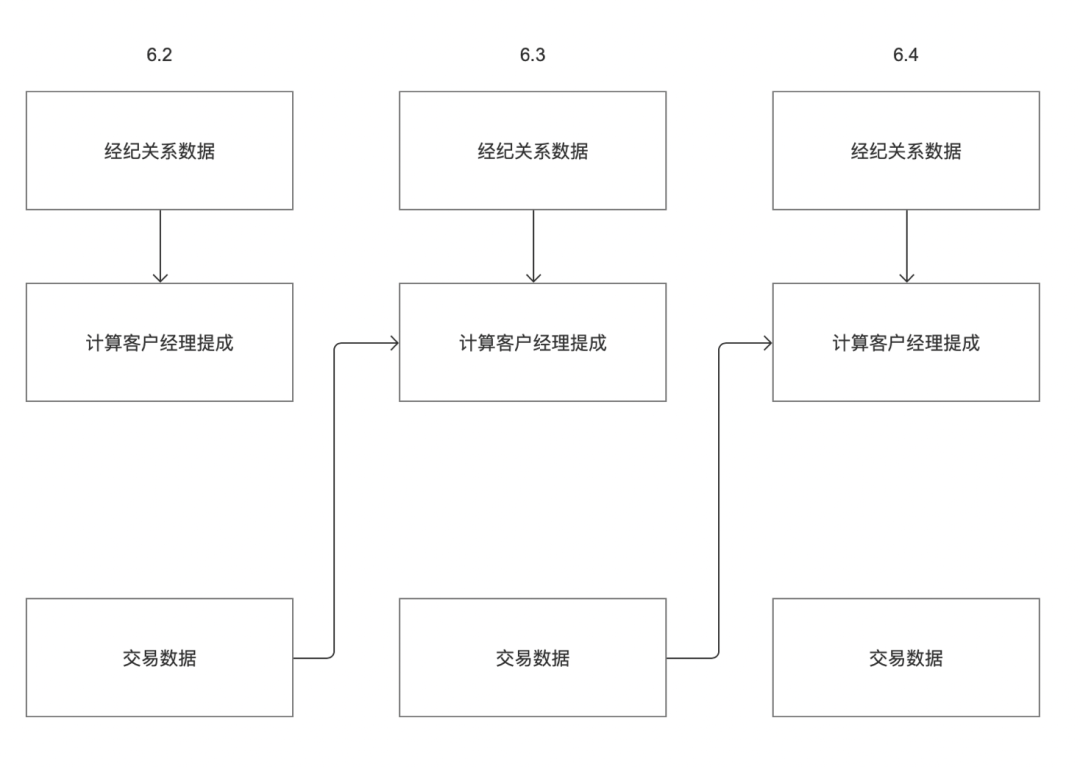
For example, a customer has two business systems "brokerage relationship data" and "transaction data". The customer's commission on June 3 needs to be calculated based on the "brokerage relationship data" and "transaction data" respectively. As shown in the figure above, the "brokerage relationship data" business system data output time on June 2 is June 3; the "transaction data" business system data output time on June 2 is the evening of June 2.
According to the current offline upstream and downstream dependency logic, the "Calculate Account Manager Commission" task can only obtain tasks on June 3, but cannot obtain tasks on June 2. Therefore, it needs to be modified to support task instance dependency settings, which can be customized. cycle.
Experience optimization instructions:
Supports customizing the scheduling cycle of dependent upstream tasks .
T represents the planned time of the current task (downstream task), "+ -" represents the offset direction, "+" represents the time offset to the future, "-" represents the time offset to the past, and "-" is selected by default.
The offset is a numeric input box with a maximum value of 10 and a minimum value of 1, which represents the number of upstream task cycles of the offset.
Real-time development platform
New feature updates
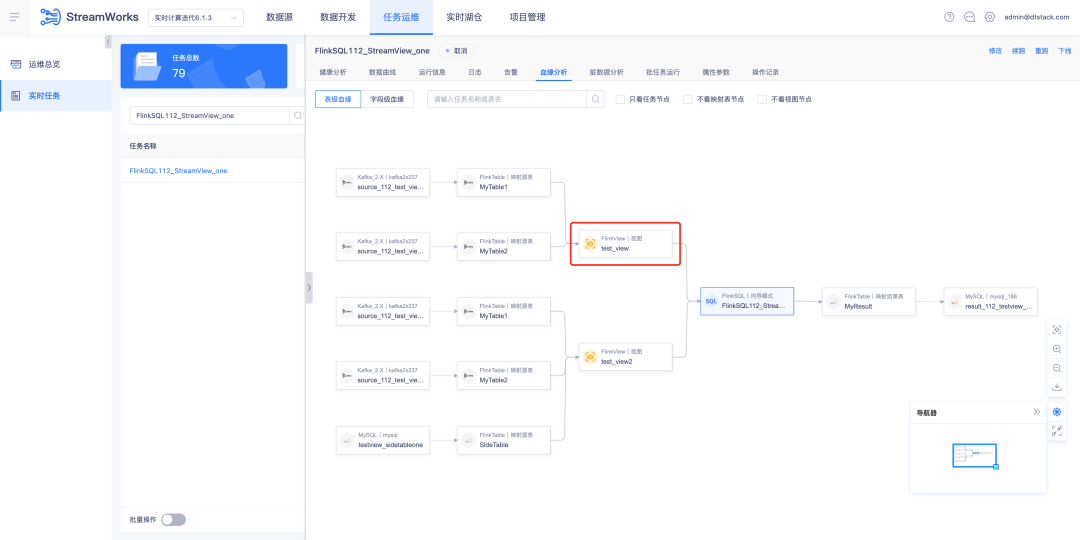
1. View bloodline analysis
Background: Currently, SQLParser does not support FlinkSQL's view lineage analysis. However, in general development scenarios, if the task involves more than three tables, many meetings choose to build views in the IDE to facilitate reading of SQL logic.
Function:
1. SQLParser supports FlinkSQL view table to display blood relationship analysis
2. Task operation and maintenance - real-time tasks - FlinkSQL task details - bloodline analysis display function
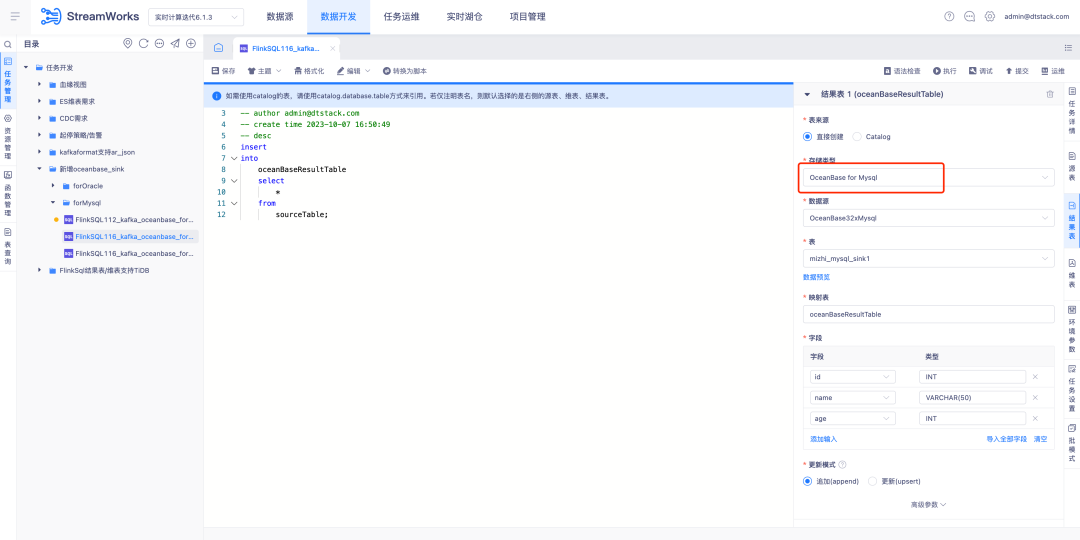
2.FlinkSQL supports Oceanbase Sink
FlinkSQL version 1.16 supports OceanBase result tables and is compatible with the MySQL and Oracle modes of OceanBase version 4.2.0, providing users with more flexible and efficient data processing capabilities.
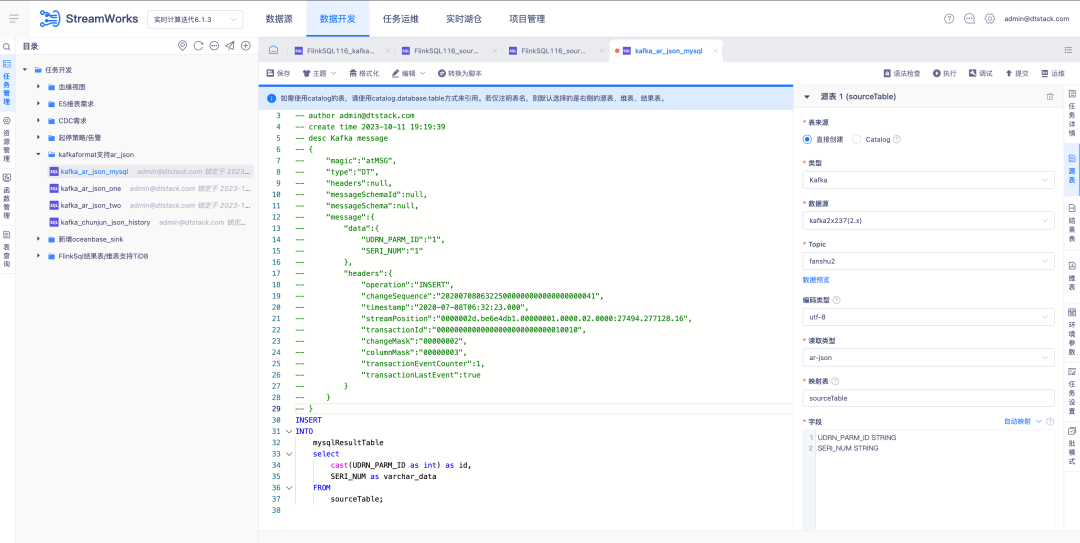
3. Source table Kafka read type supports AR Json
Background: OGG and Attunity Replicate are two widely used commercial products abroad. In order to better meet customer needs, we need to ensure that Kafka's JSON format is compatible with the AR Json reading type.
New feature description: FlinkSQL1.16 version source table Kafka read type supports AR Json type and supports automatic mapping related functions to parse Json.
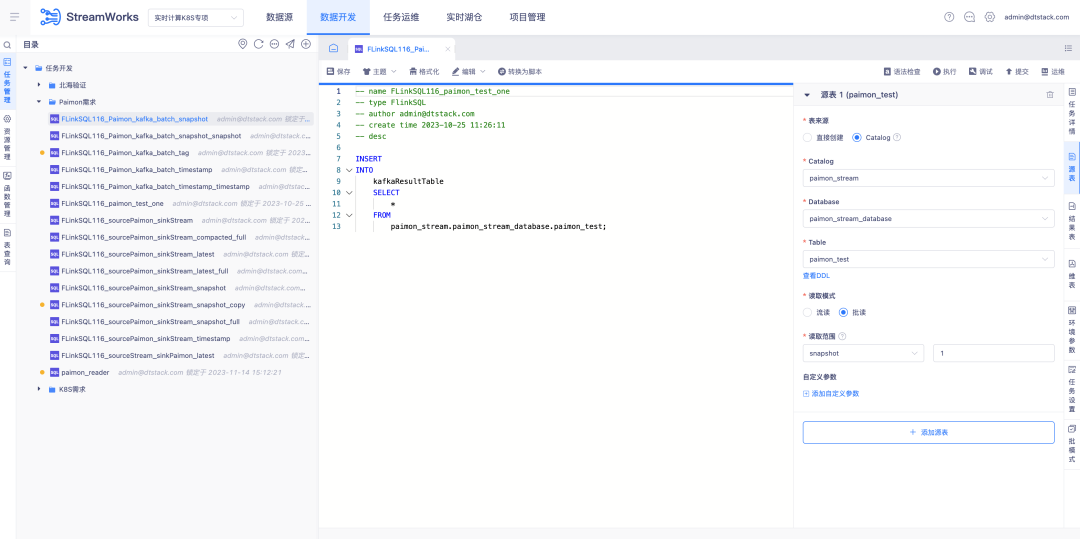
4. Real-time lake warehouse Paimon support
Background: With the development of Paimon, a new FlinkSQL development model needs to be iterated this time. Using this model, the lake warehouse management module can be strung together across the entire chain.
Description of new features:
1. Lake warehouse management adds the ability to add, delete, modify and query Paimon tables
2. Add the visual configuration function of Paimon table to the data development platform.
3. The data development platform uses the IDE to complete the reading and writing functions of the Paimon table.
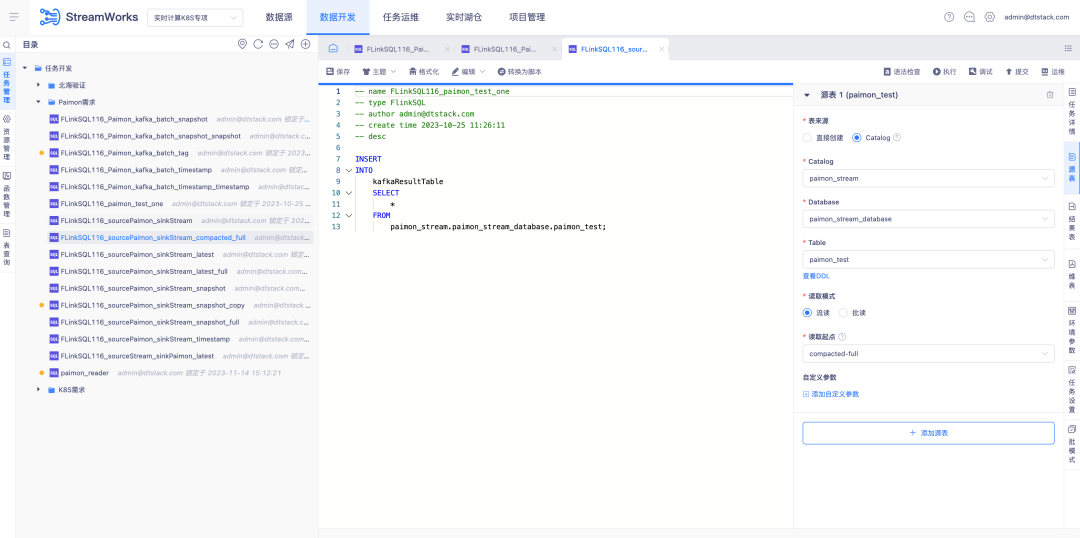
5.FlinkSQL built-in FlinkCDC
Background: FlinkCDC is an open source real-time collection component with very fast iteration speed. The underlying Flink framework it relies on is also the same as the ChunJun framework we use. Therefore, we consider making it a default component for real-time platform deployment and packaging it into our system.
Description of new features:
1. Real-time default deployment package, bring FlinkCDC real-time collection set up
2. Platform script mode, you need to verify FlinkCDC’s built-in collection capabilities and supported Connectors
3. Platform wizard mode will configure the Connector collection supported by FlinkCDC according to the project situation.
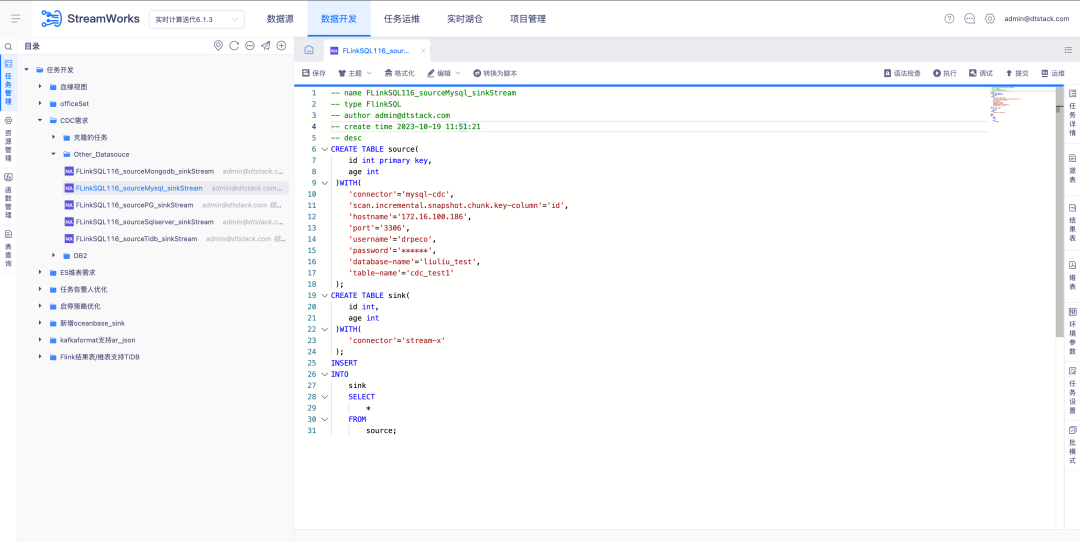
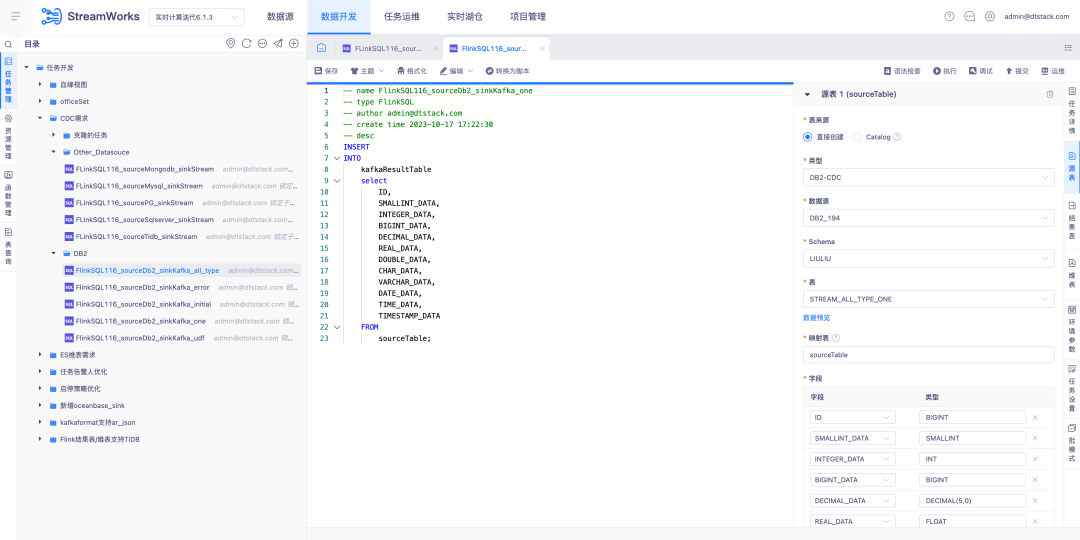
6.FlinkSQL supports FlinkCDC DB2 data source
Background: Customers need to support real-time collection of DB2. Considering that CDC Connector development is difficult, FinkCDC just supports it, so the bottom layer borrows the capabilities of FlinkCDC.
New function description: The real-time platform supports wizard mode to configure the source table as the DB2-CDC data source .
Function optimization
1.Optimization of continuation logic
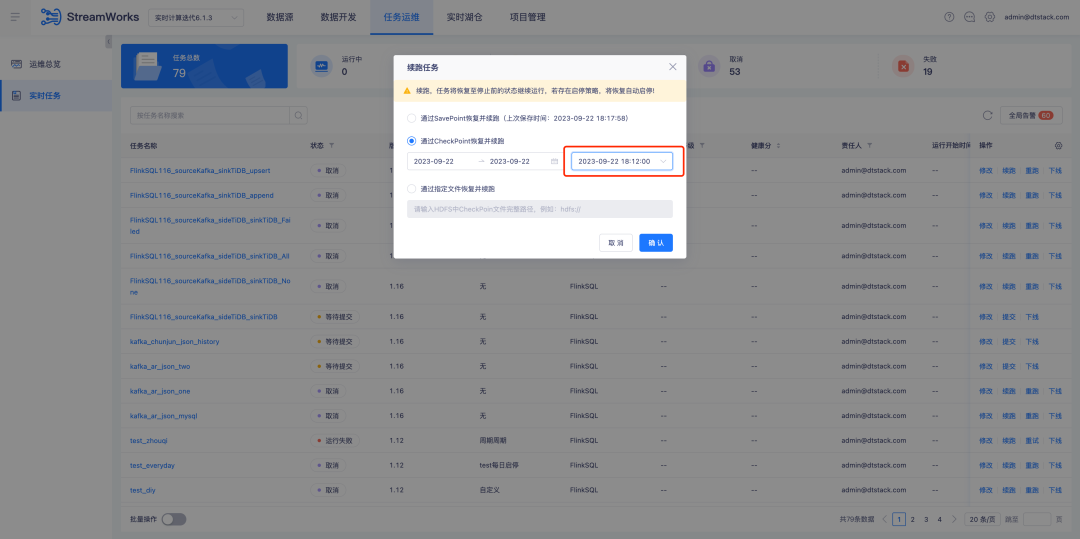
Background: When a real-time task is resumed through CheckPoint and continues running, a time point needs to be manually selected. However, in fact, most continuation scenarios select the latest CheckPoint.
Experience optimization description: When optimizing to restore and continue running through CheckPoint , the nearest CheckPoint within the date will be automatically selected.
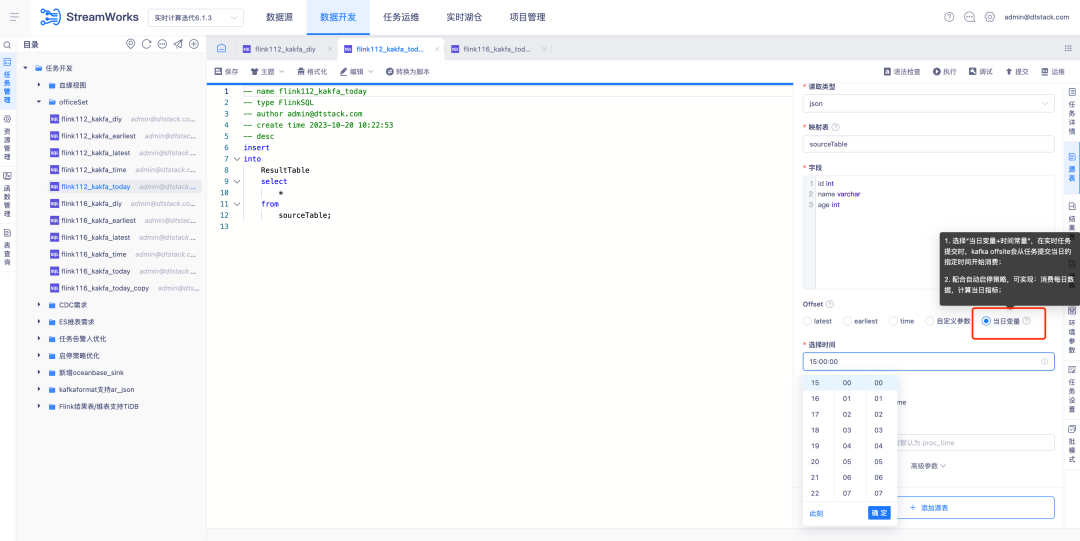
2. Start-stop strategy/Offsite optimization
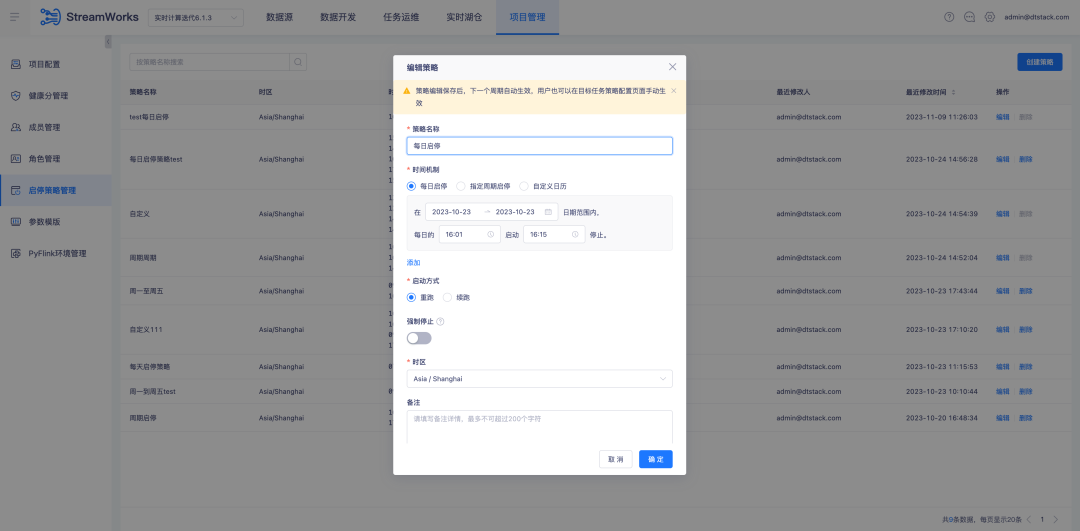
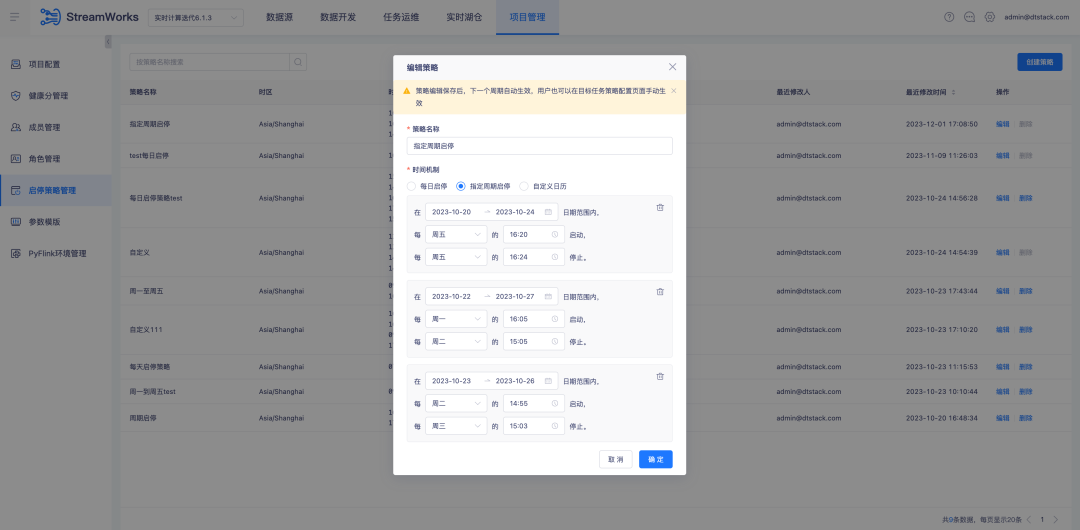
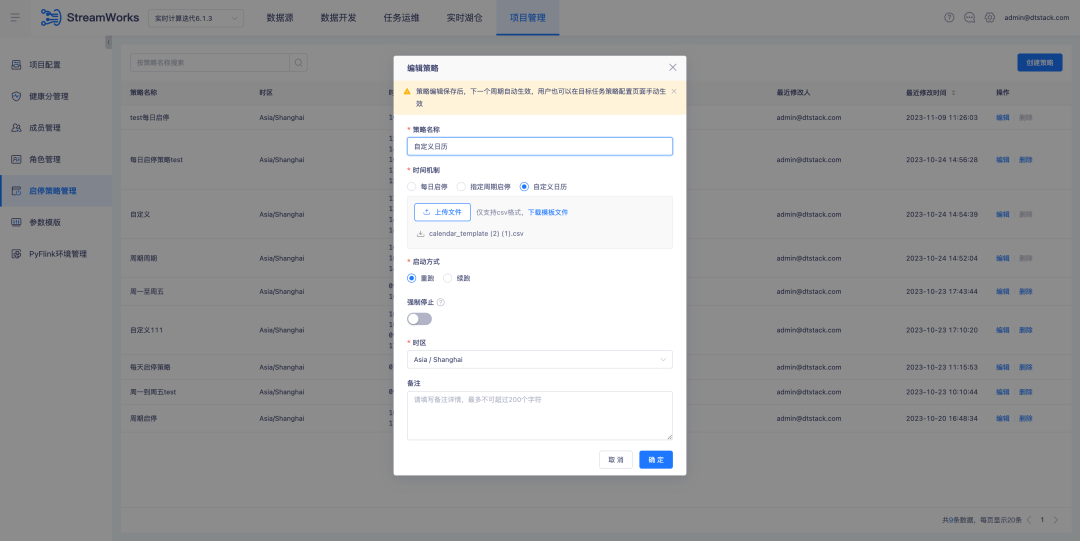
Background: During the in-depth use by customers, we found that aspects such as start-stop strategy, submission and re-run can be optimized to achieve a more efficient workflow and better user experience.
Currently, the Offsite timestamp configuration in our data development source tables is fixed. However, in real-time task computing scenarios, some customers only focus on the data calculation of the day, so they configure a start-stop policy to rerun the task every day. They want to be able to rerun the task starting at midnight every day, rather than using a fixed timestamp. Although Latest can theoretically meet this requirement, the consumption of real-time task startup time may cause the actual running time to deviate from zero, resulting in data errors.
Experience optimization instructions:
1. Optimize the start-stop policy configuration , now support cross-day start-stop policy, and improve the current start-stop policy page interaction to provide a more efficient and convenient operating experience
2. Data development - source table, supports parameterized configuration of Offsite locations
3.FlinkSQL1.16 version ES7.x plug-in optimization
Background: The ES plug-in of FlinkSQL version 1.10 supports configuring dimension table timeout time and timeout data limit. This function is temporarily unavailable in the current FlinkSQL version 1.16 and is being actively optimized.
Experience optimization instructions:
FlinkSQL1.16 version ES7.x plug-in dimension table configures table.exec.async-lookup.timeout or uses hints syntax to set the timeout. When the task is running in the LRU mode of the dimension table, the asynchronous query timeout takes effect.
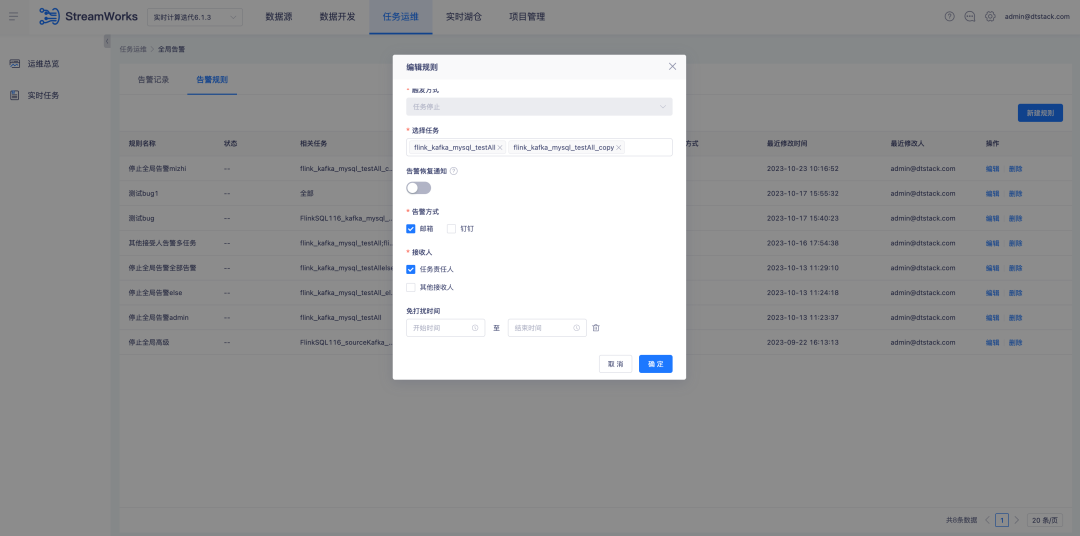
4.Alarm configuration optimization
Background: In the task alarm rules, the alarm receiving configuration needs to be manually selected. It is not possible to automatically match and send alarm information according to the task responsible person. At the same time, in the global alarm configuration, it is also impossible to automatically send the corresponding alarm information according to the task responsible person.
Experience optimization instructions:
1. Single task alarm rule configuration recipient adjustment. The task responsible person is selected by default. Other recipients can be selected through the selection box. Multiple selection is supported.
2. Global alarm rule configuration will actually be sent to the person responsible for each task when the task responsible person is checked. When other recipients are selected, the selected task will be sent to the selected recipient when the selected task is abnormal.
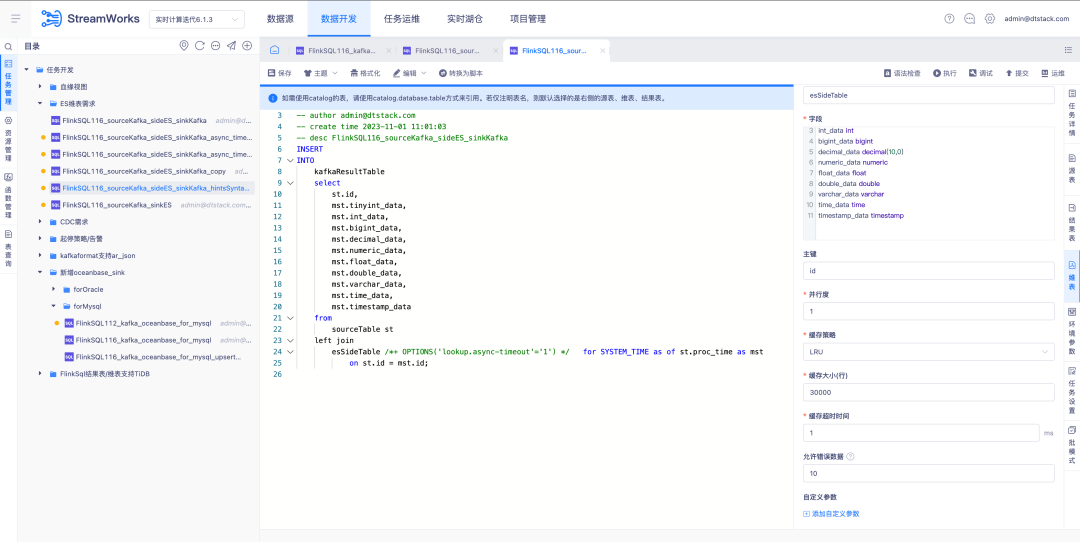
5.FlinkSQL1.12&1.16 version Tidb plug-in platform is compatible
Background: FlinkSQL versions 1.12 and 1.16 have completed adaptation to Tidb. However, the platform layer has only been adapted in version 1.10, so versions 1.12 and 1.16 are not supported.
Experience optimization instructions:
The real-time platform is compatible with Tidb plug-in version 1.12&1.16, and needs to support both dimension tables and result tables.
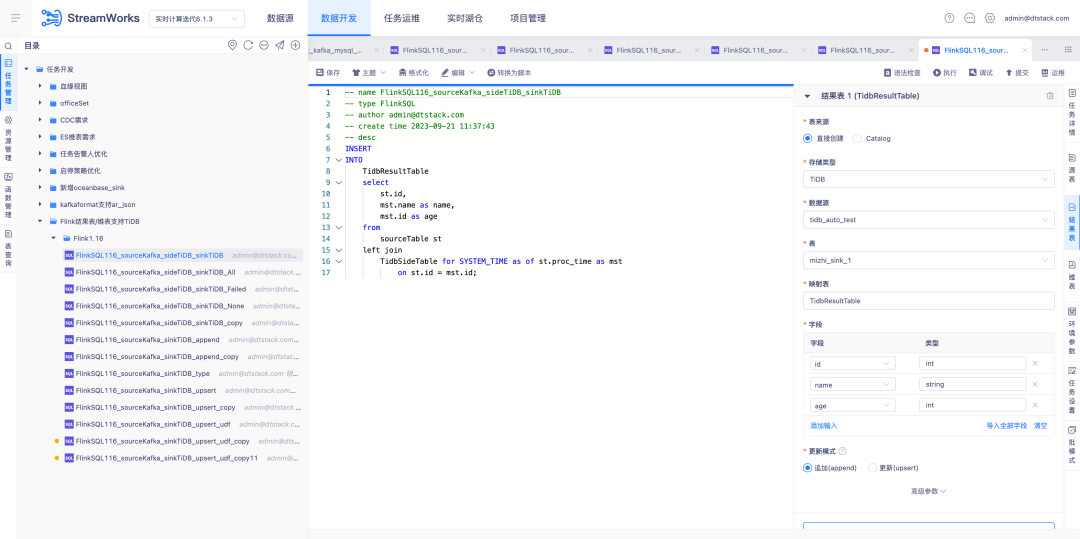
6.FlinkSQL1.12&1.16 version Hive huaweiCloud adaptation
Background: Real-time backup of Kafka data is entered into MRS Hive. When there is a problem with the real-time calculation data, the backup messages in Hive can be analyzed.
Experience optimization instructions:
FlinkSQL version 1.12&1.16 is adapted to Hive huaweiCloud. The data source center, engine, and platform are simultaneously developed to support the Hive huaweiCloud result table. You need to pay attention to the scenario of enabling Kerberos.
Data service platform
New feature updates
1. Support HBase TBDS version creation API
Added HBase TBDS version creation API, including: wizard mode generation API , import and export, and publishing to target projects.

Function optimization
1.Oracle data source supports DML
Improve the data sources supported by DML .
2. Custom SQL mode comment parsing no longer overwrites the description
Background: For historical logic, after the custom SQL schema is re-parsed for the database, the comments that come with the database will overwrite the modified instructions.
Experience optimization instructions: Modify the historical logic. For the modified instructions, the comments in the database will no longer be overwritten after re-parsing.
3. After row-level permissions are enabled, it is not required to be filled in by default.
Background: For historical row-level permissions, row-level permissions will be enabled from the fields in the table. After being enabled, the fields will be required by default and user cancellation is not supported.
Experience optimization description: This iteration adjusts the historical logic. Row-level permissions will be enabled from the API level. After being enabled, when the API uses the table, it will be restricted by row-level permissions.
4. Framework version and component upgrade
The Spring Cloud (Boot) framework version is upgraded, and the Nacos component is upgraded to reduce the probability of vulnerabilities and enhance the stability of the API itself.
Customer Data Insight Platform
New feature updates
1.Support custom UDF functions
Background: The mobile phone number, ID number and other data involved in the data processed by the customer are encrypted data. From an audit perspective, this kind of data cannot be displayed in plain text, but there will be scenarios where plain text content is displayed in the upper-level business. For example: SMS marketing based on mobile phone numbers.
Customers need to put the decryption process as late as possible, put it on the label platform to complete, and add custom labels through UDF function customization to complete processing.
Description of new functions: A new function management module has been added to the tag center , under which UDF functions can be created, viewed, and deleted (only Trino385 and above versions support creating functions)
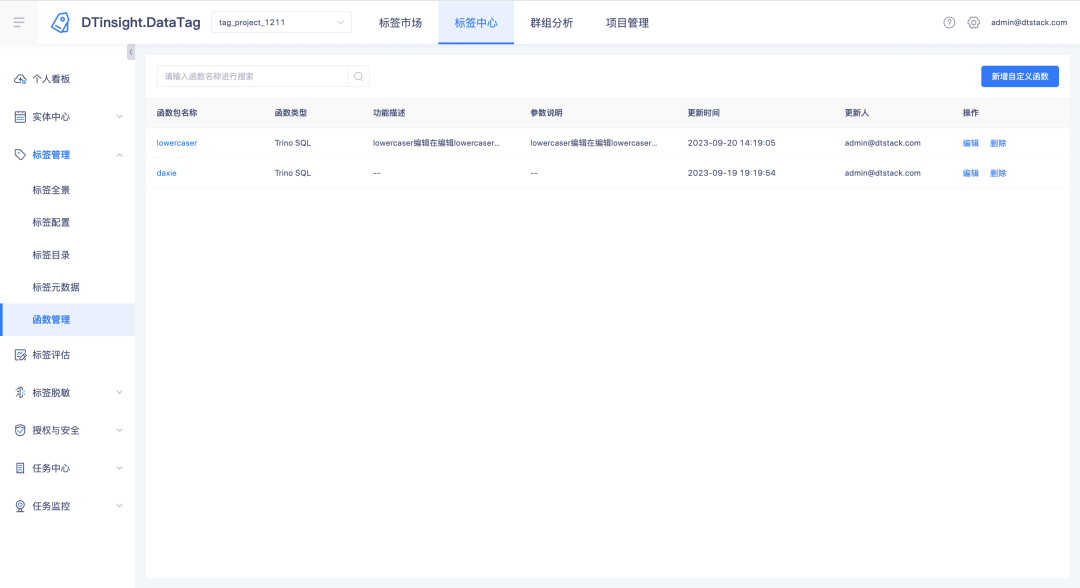
For uploaded functions, you can click on the function name to view function details.
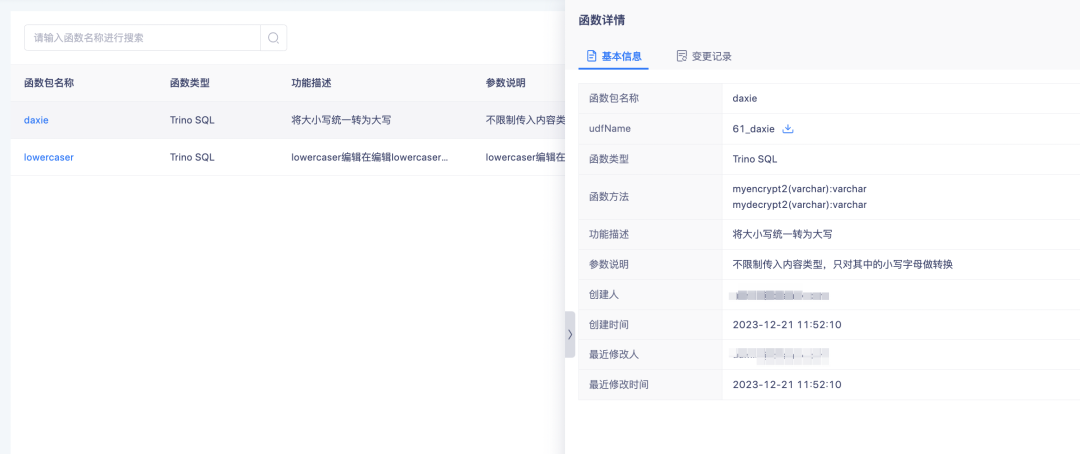
The uploaded function is mainly used for processing derived SQL tags.
2. Support processing multi-value tags
Background: The current processing rules for derived tags and combined tags are that when an instance first hits a certain rule condition, the corresponding tag value will be marked on the instance, and other tag values will no longer be matched. In the end, the single-value tag results will be stored in the database.
However, in practical applications, the conditions are not necessarily mutually exclusive. For example, the user is given a product preference label based on the number of times the user has purchased a specific type of product. A user can like both furniture and clothing. In this case, multiple values need to be supported. Label settings.
Description of new features:
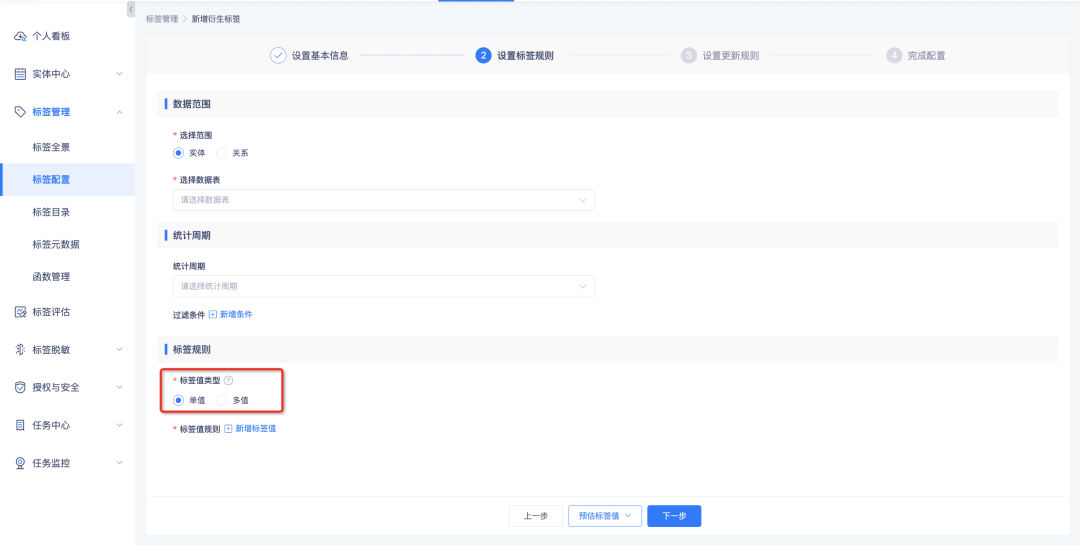
Derived rule tags, derived SQL tags, combination tags, and custom tag processing support configuration as multi-value tags , and the system calculates them based on the set tag value type.
• Single-value tags: Match in order according to the rule configuration. Stop matching when a certain tag value is hit. There is at most one tag value in the data result.
• Multi-value tags: Match in sequence according to the rule configuration order. Each rule will be matched once. There will be at most n configured tag values in the data result.
Based on the calculation results, the label details will count the number of instances for each individual label, that is, the sum of the number of instances covered by each label value of a single-value label is the number of instances covered by the label, and the number of instances covered by each label value of a multi-valued label. The sum of the numbers is greater than or equal to the number of label coverage instances.
3. Customized role docking business center
Background: Previously, roles were built-in roles in the system, and roles could not be added/modified/delete. Role permissions could not be customized. The functions were too fixed and could not be flexibly adjusted according to the actual business scenarios of customers. In version 6.0, the business center has added customization Role function, the tag product is connected to this function of the business center to achieve the following effects:
1. Support new roles
2. Support custom role permissions
New function description: Configure roles and their indicator permissions in the business center, and the labeling platform will automatically introduce the permission configuration results for query.
1. Add new roles and configure role permission points in the business center:
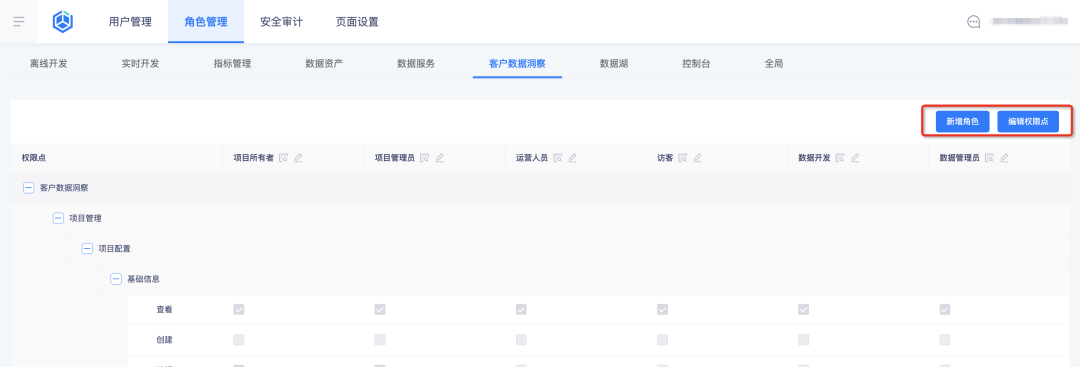
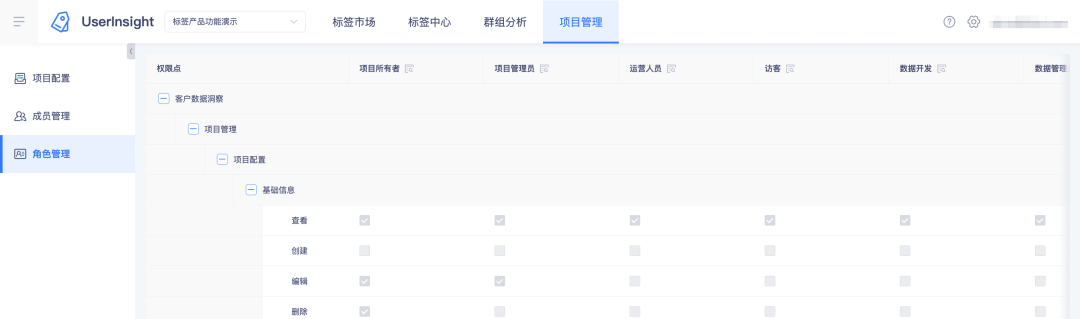
2. View roles and their permission points on the tag platform:
4. Data display format supports customization
Background: For numeric tags, setting the display precision is currently not supported, resulting in irregular page display. Some display integers such as 1, and some display decimals such as 1.234. The overall reading experience is not high. In order to improve the user experience, it is necessary to Add data display rule settings.
Description of new features:
1. When creating/editing entities, editing atomic tags, and creating/editing derived SQL tags, it is supported to set display rules for numeric tags.
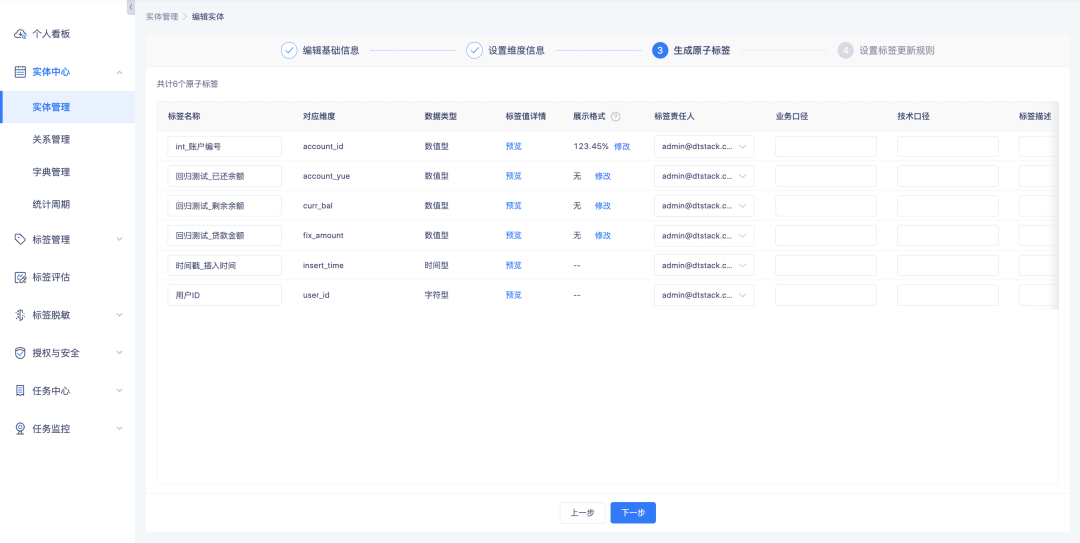
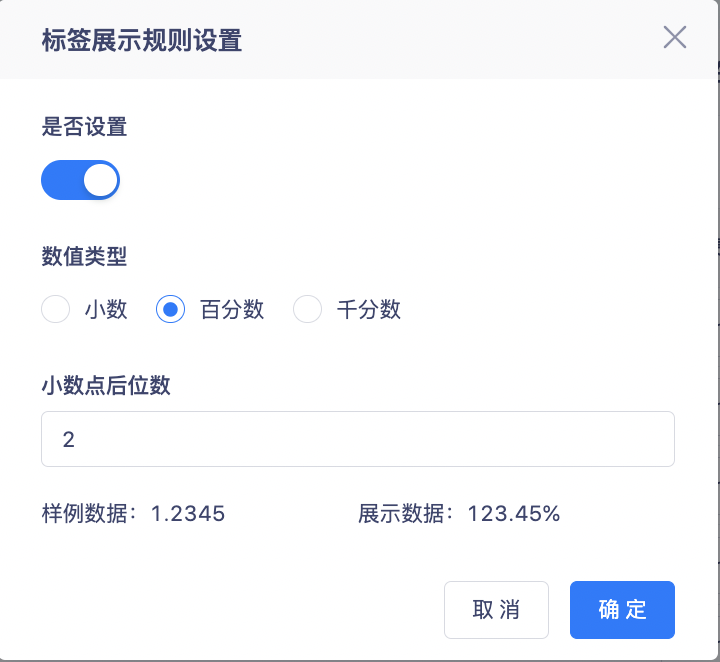
2. Supports display as decimals, percentages, and thousandths, and supports setting the number of digits after the decimal point.
3. The tag data displayed on group-related pages is displayed according to the set display rules.
5. Tag/group file upload supports viewing the upload progress
Background: The file import function currently uploads without progress prompts. When the file is too large, the waiting time is long, which will cause users to misunderstand that the page is stuck. Progress prompts need to be added to make the current progress clear to users.
Description of new features:
1. Added progress prompts during label, group file upload, and offline query tasks.
2. Group file upload has been adjusted to support uploading files up to 500M in size.
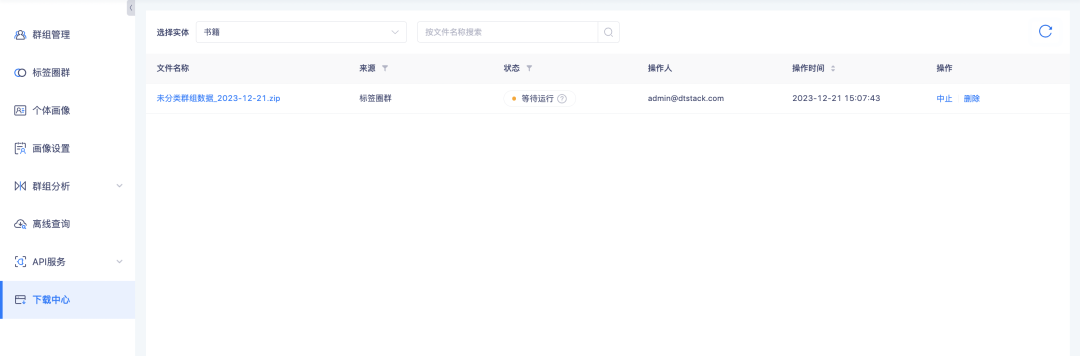
6. The download center supports querying the download progress.
Background: During the data download process, due to the large amount of data, it takes a long time to prepare the data before it can be downloaded. Users do not expect it when using it, and need to refresh frequently to determine whether the download can be performed. Download progress prompts need to be added to guide users to determine how long to wait.
New function description: Download center task status adds waiting to run and aborted status. Among them, the download of tag circle group-group list, group details-group list, upload local group-instance list, offline query-group details-instance list, group intersection and difference-instance list depends on the group list data. If the download volume is large, it will be executed in serial download mode. Tasks related to the group list will be queued for execution in sequence. Those that are not queued are waiting to be run. Other downloads with small data volumes will be executed directly. While tasks are running, you can abort tasks that are no longer needed.
Function optimization
1. Data export is adjusted to download files through the download center
Background: File downloads on some pages are downloaded directly, causing the button to always be in a running state and the user cannot perceive the download progress.
Experience optimization description: After clicking the button related to data export, the file will be downloaded asynchronously. After the download is completed, you can enter the "Download Center" module to download the data details. The page buttons involved are as follows: Tag Circle Group -Data Export, Group Details-Group List-data export, upload local group-instance list-data export, offline query-upload local group/group intersection and difference details-data export, group intersection and difference-data export.
If the amount of data is too large, the system will export it in separate files based on the upper limit of the number of records set by the user.
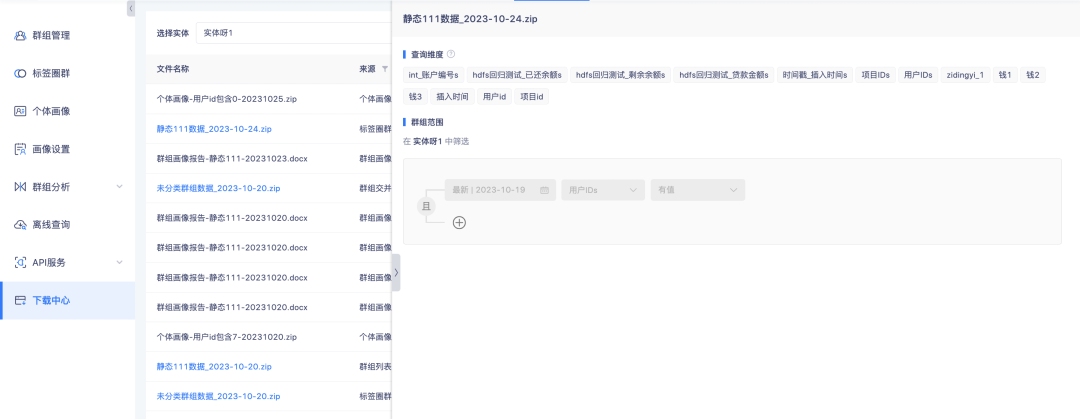
2. List data from tag circle groups and group details in the download center supports viewing configuration details.
Background: Currently, there are many file sources in the download center, and it is inconvenient to distinguish the content based only on file names. It is necessary to increase file data sources to improve data availability.
Experience optimization description: List data from tag circle groups and group details support clicks. Click the sidebar to open the configuration details.
3. Optimization of new tag functions in the tag market
Background: Currently, the platform does not explain the definition of new tags and needs to be added.
Experience optimization description: New tags on the platform are defined as the last 24 hours, but in actual use, people generally do not pay attention to them on weekends. When they pay attention again on Monday, there will be situations where the updated tags from Friday to Sunday morning cannot be notified in place. Adjust the definition to the last 7 days.
4. Cross-sub-product switching permission adaptation optimization
When a tagged product is switched across sub-products, the tab content on the page will be missing. This is caused by permission issues. This optimization ensures that the function is available when switching pages across products.
5. Support column width adjustment and customization
Group list, group details-group list, tag circle group-user list, group intersection and difference-instance list , and tag list column width support customization.
After customizing the column width, it will take effect for subsequent uses based on the current browser and the currently logged-in user. When the user logs in using a new browser or clears the cache of the current browser, or logs in again, the default settings will be displayed.
Indicator management platform
New feature updates
1. Customized role docking business center
Background: Previously, roles were built-in roles in the system, and roles could not be added/modified/delete. Role permissions could not be customized. The functions were too fixed and could not be flexibly adjusted according to the customer's actual business scenario.
Description of new features:
Configure the role and its indicator permissions in the business center , and the indicator platform will automatically introduce the permission configuration results for query:
1. Add new roles and configure role permission points in the business center
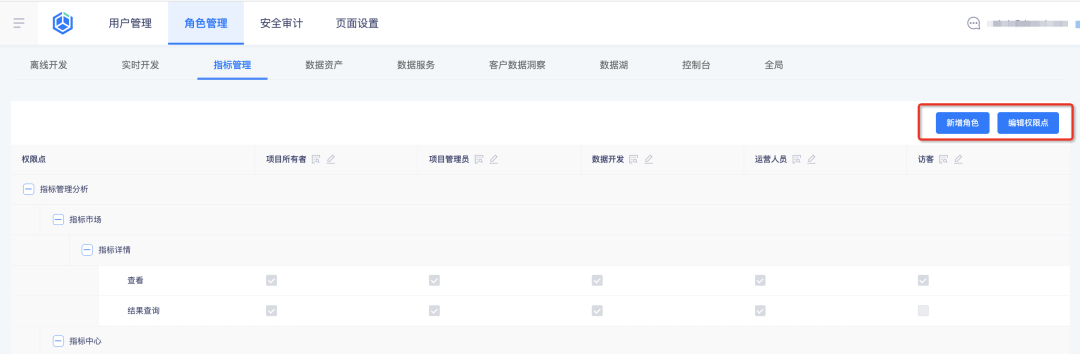
2. View roles and their permission points on the indicator platform
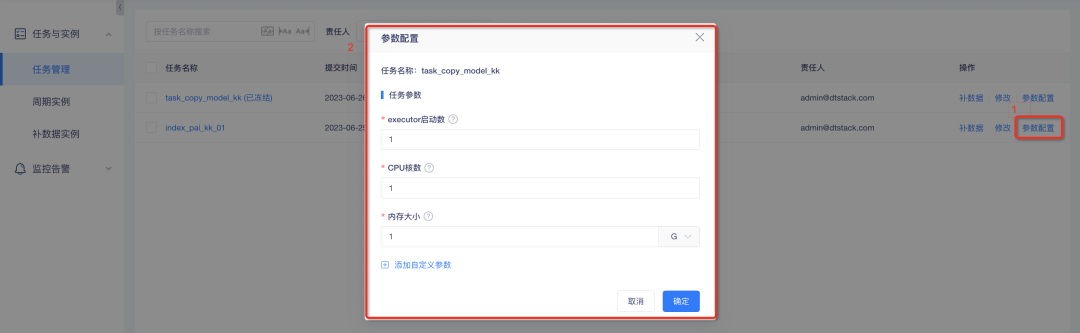
2.Spark and data synchronization tasks support custom parameter configuration
Background: For Spark tasks and data synchronization tasks, parameter adjustments can currently only be made through the console. The adjustment results will take effect globally. However, the data magnitude differences between indicator tasks are large, and configuring the same parameters will cause a waste of resources. Therefore, task-level parameters can be set for Spark and data synchronization tasks to facilitate flexible control of tasks.
Description of new features:
1. Spark task custom parameter configuration : among them, the number of executor starts, the number of CPU cores, and the memory size are required; custom parameters can be set
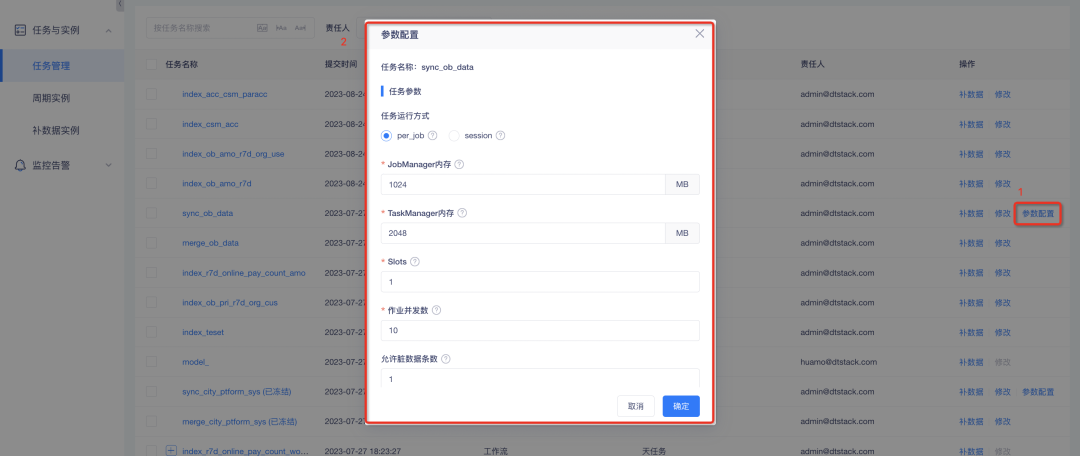
2. Custom parameter configuration for data synchronization tasks : in per-job mode, jobmanager memory, taskmanager memory, and slots are required; the number of concurrent jobs and HBase’s WriteBufferSize are required; custom parameters can be set
Function optimization
1. The browser supports opening multiple projects at the same time
Background: In the history function, the cookie does not store project parameters. As a result, when the data stack opens a new project window, the content in the history window will be refreshed and the user will return to the project list page for project selection, which affects customer use.
Experience optimization description: This optimization supports the browser to open multiple projects at the same time for query, operation, etc. to improve product usage efficiency.
2.edge browser compatible
Compatible with the egde browser, the functions will be adapted accordingly to improve the usability of the product on mainstream browsers.
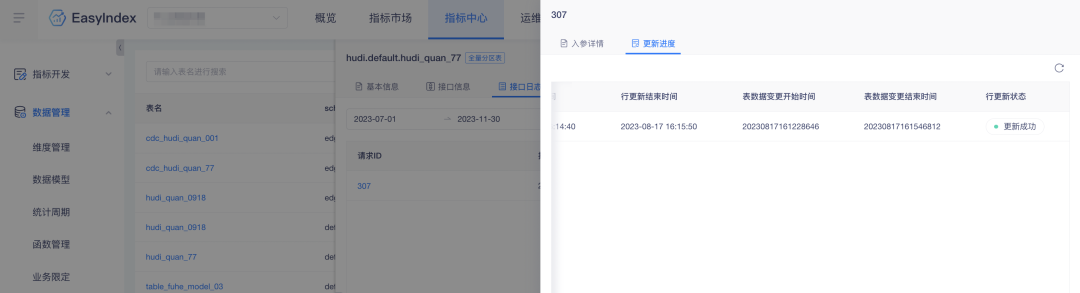
3. Row update supplementary table update time
Background: The row update data record lacks the table data change time period, which makes data retrieval inconvenient. In order to improve the efficiency of data retrieval, relevant data is added to the platform.
Experience optimization description: Indicator row update adds table data change start time and end time.
4. Add manual refresh function to row update status
During the row update process, in order to facilitate timely follow-up of the update progress, a refresh button is added to the page to improve refresh efficiency.
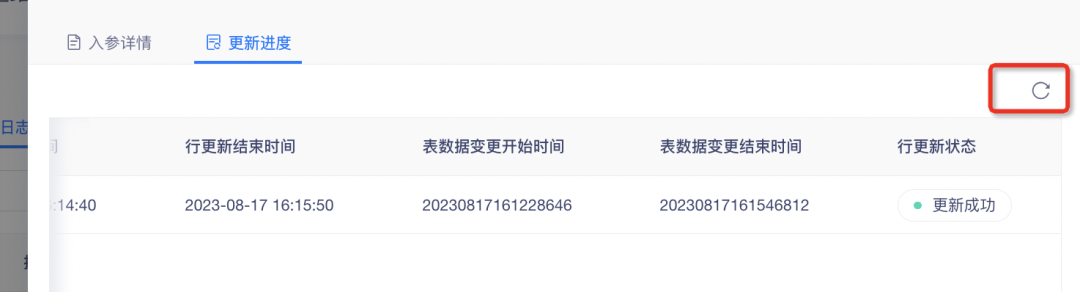
5. Optimization of model-populated dimensional objects and dimensional attribute functions
When editing the model, in the step of setting dimension information, the system will backfill the dimension information bound to the main dimension table fields by default. If the user has modified the associated dimensions in the historical version, and if you do not pay attention to the adjustment during the editing process, incorrect data will be saved. To avoid Data error rate, adjusted to echo the information saved in the previous version.
6. API gateway supports custom prefixes
The prefix information of the indicator is currently written into the configuration item of the API. At the same time, the API currently has a custom prefix function to improve API configuration flexibility. At this time, when the API configuration items of the indicator are inconsistent with the API custom prefix, the data cannot be called normally. It needs to be adjusted to the configuration settings of the docking API to ensure that the global configuration is unique.
"Dutstack Product White Paper" download address: https://www.dtstack.com/resources/1004?src=szsm
"Data Governance Industry Practice White Paper" download address: https://www.dtstack.com/resources/1001?src=szsm
For those who want to know or consult more about big data products, industry solutions, and customer cases, visit the Kangaroo Cloud official website: https://www.dtstack.com/?src=szkyzg
Linus took it upon himself to prevent kernel developers from replacing tabs with spaces. His father is one of the few leaders who can write code, his second son is the director of the open source technology department, and his youngest son is an open source core contributor. Robin Li: Natural language will become a new universal programming language. The open source model will fall further and further behind Huawei: It will take 1 year to fully migrate 5,000 commonly used mobile applications to Hongmeng. Java is the language most prone to third-party vulnerabilities. Rich text editor Quill 2.0 has been released with features, reliability and developers. The experience has been greatly improved. Ma Huateng and Zhou Hongyi shook hands to "eliminate grudges." Meta Llama 3 is officially released. Although the open source of Laoxiangji is not the code, the reasons behind it are very heart-warming. Google announced a large-scale restructuring