Microservices are immortal—detailed explanation of the implementation of shared variables in the policy engine project
Others
2024-04-17 00:41:37
views: null
background
1. Proposition of shared variables
Some time ago, a case study from the Amazon Prime Video team caused an uproar in the developer community. Basically, as a streaming platform, Prime Video provides thousands of live streams to customers every day. To ensure customers received content seamlessly, Prime Video needed to build a monitoring tool to identify quality issues in every stream customers viewed, which imposed extremely high scalability requirements.
In this regard, the Prime Video team prioritized the microservice architecture. Because microservices can decompose a single application into multiple modules, this not only solves the problem of independent development and deployment of tools, but also provides higher availability, reliability, and technical diversity for applications. Ultimately, Prime Video's service consists of three parts. The media converter sends the audio and video streams to the detector's audio and video buffer; the defect detector executes the algorithm and sends real-time notifications when defects are found; and the third component provides Control the orchestration of service processes.
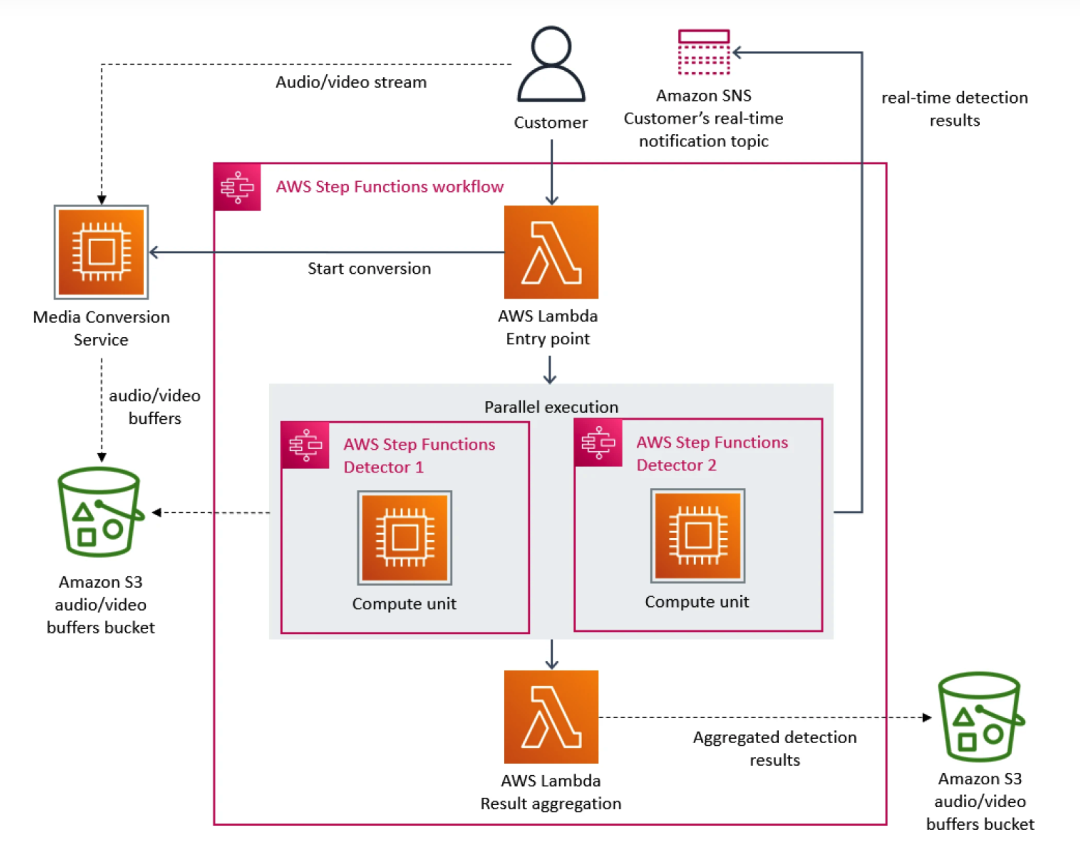 As more flows are added to the service, the problem of excessive cost begins to appear. Since AWS Step charges users based on function state transitions, when a large number of streams need to be processed, the overhead of running the infrastructure at scale becomes very expensive. The total cost of all building blocks is too high, which prevents the Prime Video team from accepting the initial large-scale s solution. In the end, the Prime Video team restructured the infrastructure and migrated from microservices to a monolithic architecture. According to their data, infrastructure costs were reduced by 90%.
This incident also made us more aware that distributed architecture also has shortcomings compared to single service architecture. For example, the Prime Video team encountered a problem: the distributed architecture cannot share variables like the monolithic architecture, which causes the underlying service to handle more of the same requests, resulting in soaring costs. This dilemma also exists in iQiyi’s overseas architecture, especially in the calling relationship of the strategy engine.
As more flows are added to the service, the problem of excessive cost begins to appear. Since AWS Step charges users based on function state transitions, when a large number of streams need to be processed, the overhead of running the infrastructure at scale becomes very expensive. The total cost of all building blocks is too high, which prevents the Prime Video team from accepting the initial large-scale s solution. In the end, the Prime Video team restructured the infrastructure and migrated from microservices to a monolithic architecture. According to their data, infrastructure costs were reduced by 90%.
This incident also made us more aware that distributed architecture also has shortcomings compared to single service architecture. For example, the Prime Video team encountered a problem: the distributed architecture cannot share variables like the monolithic architecture, which causes the underlying service to handle more of the same requests, resulting in soaring costs. This dilemma also exists in iQiyi’s overseas architecture, especially in the calling relationship of the strategy engine.
2. iQiyi overseas strategy engine calling relationship
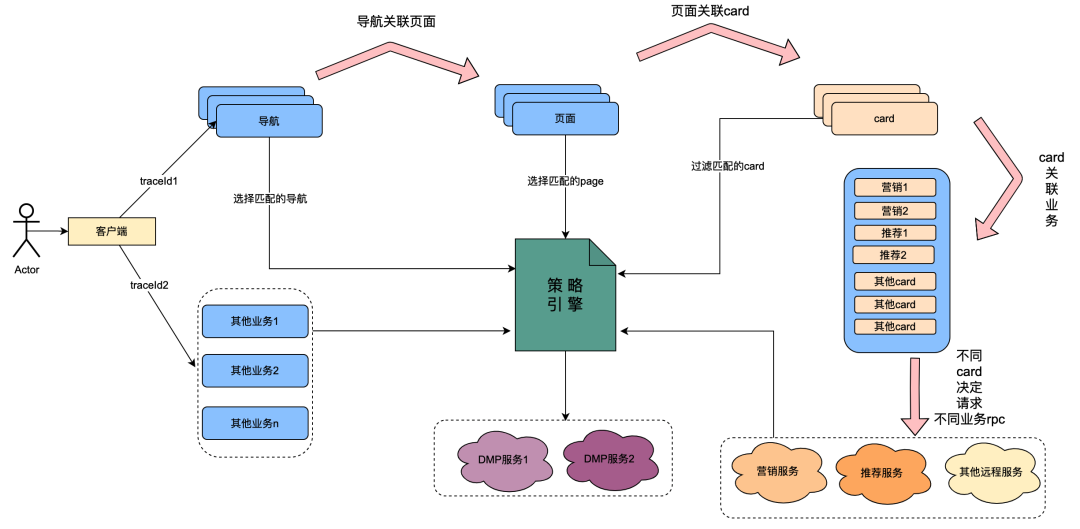
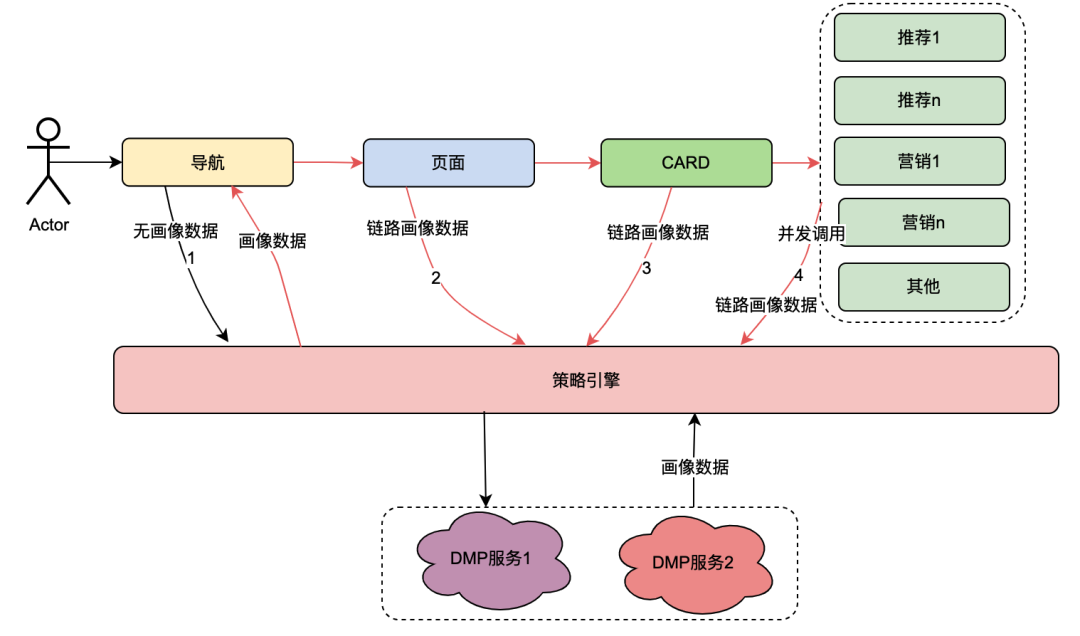
2.1 Introduction to policy engine calling relationship
Among them, card is the subdivision module of each column in the page. Usually columns such as TV series and movies are one card. The data sources in each card are different, such as marketing data obtained from marketing, content obtained from recommendations, program content obtained from Chip, etc. There is an association relationship. For example, the page is associated under the navigation, the card is associated under the page, and the specific business data in the card is associated under the card.
The policy engine is a matching service for identifying groups of people. For example, a group policy is currently configured, which contains Japanese gold members, men, membership expiration days of less than 7 days, and preference for Japanese anime. The policy engine service can identify whether a user belongs to the above group policies.
After the technological transformation of " anything goes ", the ability to customize the user profile dimensions of navigation, pages, cards, and data within cards has been achieved. The general implementation is as follows: when the client initiates a request, it first requests the navigation API. In the navigation data configuration background, operations students configured different navigation data, and each piece of navigation data was associated with a policy. The navigation API internally obtains all the navigation data, and then uses the navigation-associated policy and the user uid and device id as input parameters to request the policy engine. The policy engine will match and return the matching policy. The navigation API will associate the navigation with the policy that meets the requirements. Data is returned, thus realizing the ability for different user portraits to see different navigation data. Pages, cards, and data within cards are implemented in roughly the same way.
From the above content, it can be summarized that the calling link of the policy engine has the following characteristics:
(1) One operation of a user opening a page will call multiple policy engine services in series.
(2) Policy engine interface performance directly affects user experience: it associates requests for many page business services.
(3) Strategy engine data requires strong real-time nature: after a user purchases a membership, it should be immediately associated with member-related strategies.
2.2 Dilemmas encountered
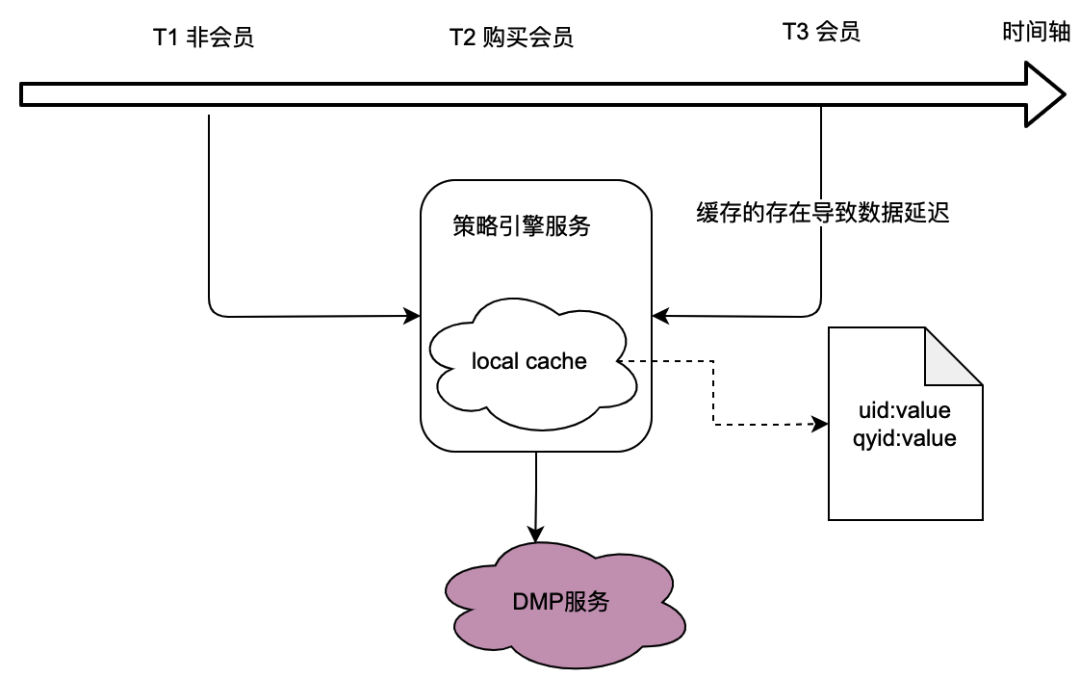
As can be seen from the calling relationship in the previous section, the policy engine, as the underlying service, undertakes the traffic of many business parties, and the policy engine needs to obtain user portrait data to determine whether the crowd policy matches, which in turn relies heavily on the DMP (Data Management Platforms) service. In order to reduce the traffic to the DMP service, we considered a local caching solution.
However, the problem with this is obvious, that is, it cannot meet the real-time data requirements . When a user purchases a membership and the portrait data returned by the DMP service changes, the user cannot see the latest policy-related data due to the delay in local caching, which is obviously intolerable.
We also considered distributed caching solutions. If the user ID is used as the key, the pain point is the same as that of local cache, which cannot meet the real-time requirements.
Therefore, how to optimize the traffic to DMP services while meeting the real-time requirements of data is a challenge for the optimization of the entire policy engine project.
The dawn of shared variables
1 Overview
The crux of the dilemma is that distributed services cannot share variables. A user's page opening behavior is accompanied by multiple backend requests, and the user profile data associated with these multiple backend requests is actually one, that is, the profile data obtained from the DMP service must be the same. Next, we conduct an abstract analysis of the call link of the policy engine to see what features it has.
2. Policy engine call link analysis
The calling relationship of the policy engine has been introduced in the chapter 1.2.1 Introduction to the policy engine calling relationship. This time we mainly abstractly classify its calling links.
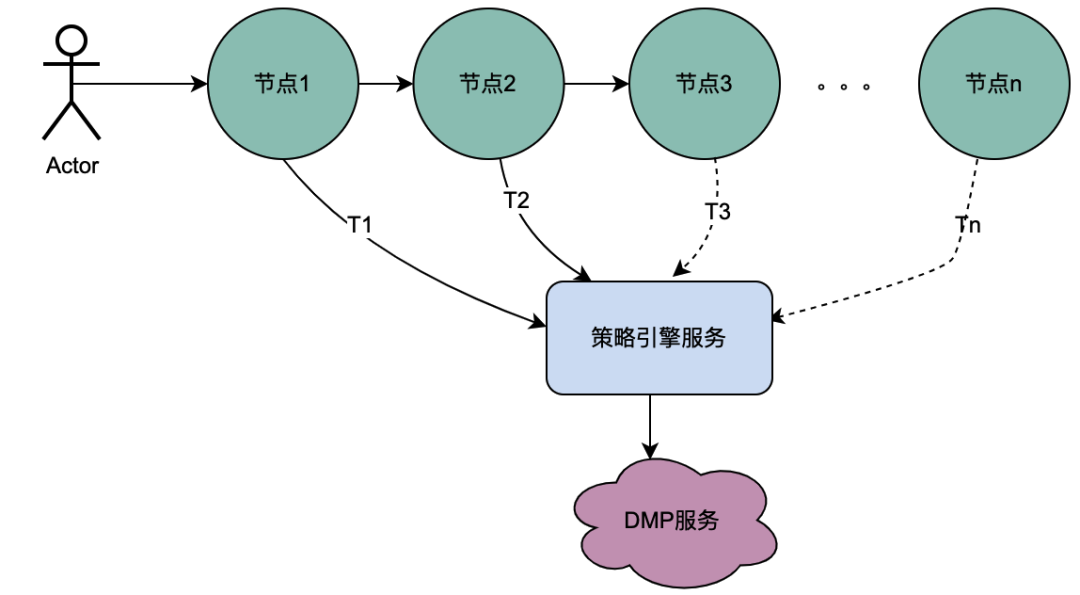
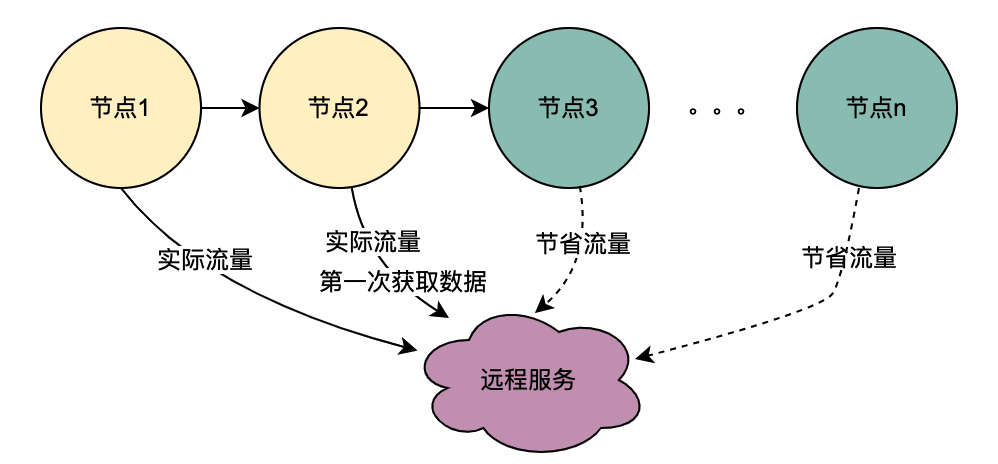
2.1 Serial calling scenario
As you can see from the figure above, a user initiates a request and passes through multiple node services. The node services are in a serial relationship, and each node relies on the policy engine service. The policy engine service needs to obtain the user's portrait data. , and obviously, the requests from T1 to Tn are all from the same user, and the data obtained by the DMP service must be the same. Then, if the idea of shared variables is used, the requests to the DMP service from T1 to Tn can be optimized to 1 ask. We name the portrait data obtained from the DMP service here distributed shared variables .
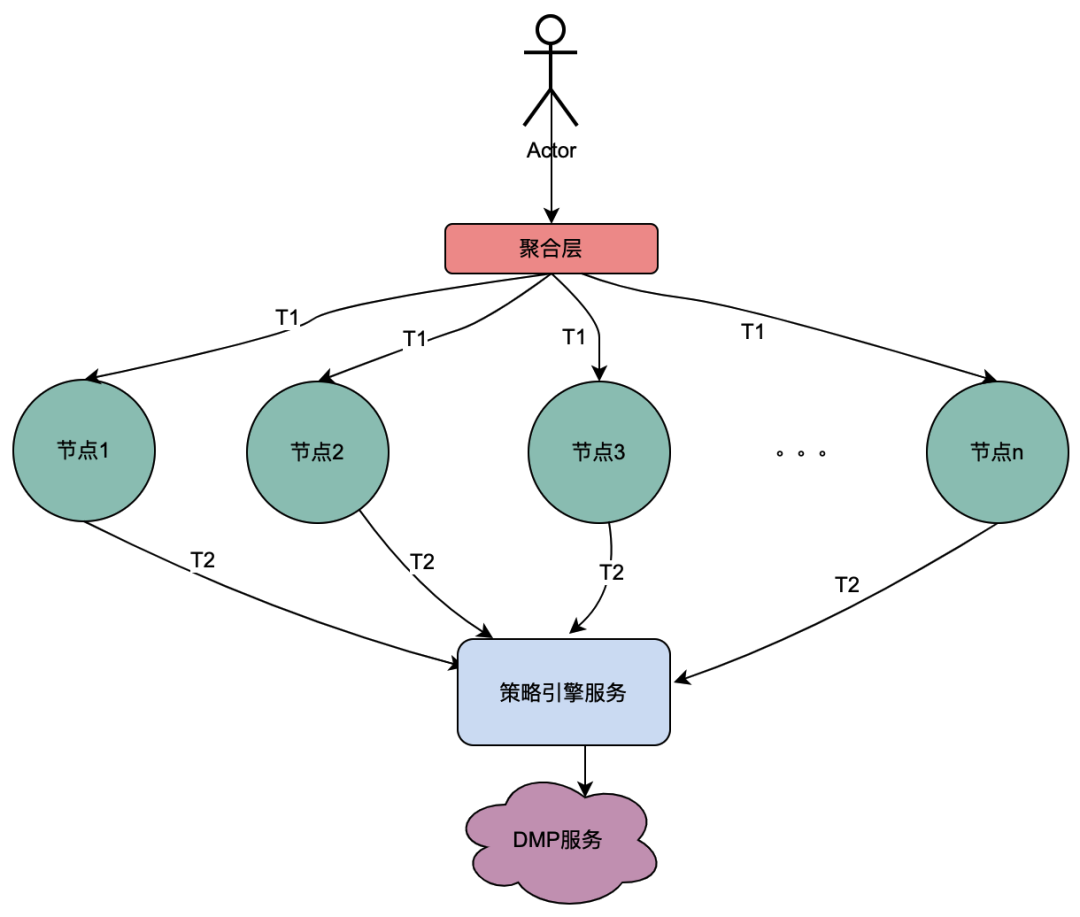
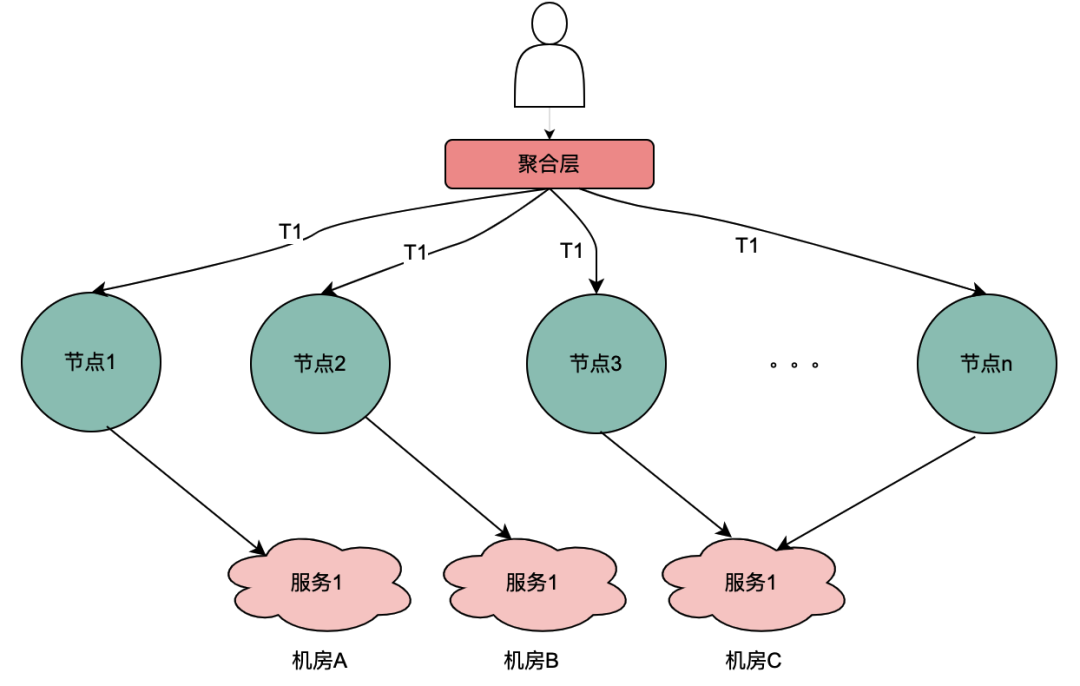
2.2 Parallel calling scenario
Different from the above serial call chain, the serial calls T1 to Tn are in time sequence, and the T1 call must be before the T2 call. There is no time sequence for parallel calls, that is, the same user may initiate a request, and the aggregation layer business may initiate a request to the dependent service at the same time, and the dependent service depends on the policy engine. Therefore, a request initiated by the same user will be executed at the same time. Make multiple requests to the policy engine. Then if multiple requests are placed in a queue, the first request actually requests the DMP service, and the remaining requests wait in the queue for the data of the first request, n requests can be optimized into 1 request. We call the portrait data obtained from the DMP service here local shared variables .
Introduction to distributed shared variables
1. Principle overview
When the user opens the page, the client will request navigation, and then obtain the feature page, specific card and feature card data in sequence. Every link involves the policy engine service. Under normal circumstances, a client request will trigger multiple calls to the policy engine, thereby causing multiple calls to the DMP service. But obviously, this is a request from the same user, and the user portrait data obtained by these requests to the DMP service must be the same.
Based on the above analysis, a simple description of the principle of distributed shared variables is that when [Navigation] obtains the portrait data for the first time, it puts its content in the request link and passes it down similar to the TraceId of the full link. In this way, when the downstream such as [Page] requests the policy engine again, it can directly obtain the link data in the link context TraceContext without requesting the DMP service. For CARD, the same is true for the page business.
It is worth mentioning that TraceContext can only be passed down through request. In this way, when link data is stored, the portrait data can only be placed in the link context TraceContext after [Navigation] obtains the policy engine data.
如果导航没有关联策略数据,无需请求策略引擎,但是后面的页面、CARD等又关联了策略引擎,那该怎么处理呢?我们参考了TraceId的处理方式,在每个调用策略引擎服务的节点(不同业务如页面、CARD等)进行判断是否有链路数据,如果没有,则获取策略引擎数据后放置进去,如果有则忽略。这样就保证最前置的节点拿到画像数据后,进行向后传递,减少后续节点对于DMP服务的流量。很明显,这些逻辑有一些业务侵入性,所以我们将调用策略引擎的方式优化为SDK调用,在SDK内部做了一些统一的逻辑处理,让业务调用方无感知。
2、全链路追踪 — 基于SkyWalking
skywalking 是分布式系统的应用程序性能监视工具,专为微服务、云原生架构和基于容器化技术(docker、K8s、Mesos)架构而设计,它是一款优秀的 APM(Application Performance Management)工具。skywalking 是观察性分析平台和应用性能管理系统。提供分布式追踪、服务网格遥测分析、度量聚合和可视化一体化解决方案。对于为什么选择skywalking,除去skywalking本身的优势以外,业务上的理由是爱奇艺海外项目目前已经接入SkyWalking,开发成本最低,维护更加便利。所以,使用skywalking传递分布式共享变量只需要引入一个Maven依赖,调用其特有的方法,就可以将数据进行链路传递。
分布式共享变量的方案会增加网络传递数据的大小,增加网络开销;当链路数据足够大的时候甚至会影响服务响应性能。因此控制链路数据大小、链路数据的控制和评估链路数据对网络性能造成影响是尤为重要的。下面将详细介绍。
3、链路传输优化 — 压缩解压缩
3.1 压缩基本原理
目前用处最为广泛的压缩算法包括Gzip等大多是基于DEFLATE,而DEFLATE 是同时使用了 LZ77 算法与哈夫曼编码(Huffman Coding)的一种无损数据压缩算法。其中 LZ77 算法是先通过前向缓冲区预读取数据,然后再向滑动窗口移入(滑动窗口有一定的长度), 不断寻找能与字典中短语匹配的最长短语,然后通过标记符标记,依次来缩短字符串的长度。哈夫曼编码主要是用较短的编码代替较常用的字母,用较长的编码代替较少用的字母,从而减少了文本的总长度,其较少的编码通常使用构造二叉树来实现。
3.2 压缩选型
由于BI获取的用户画像TAG固定且个数较少,因此这里选择DMP数据作为实验对比数据。以下是不同场景下压缩大小对比数据

方案3得到的数据最小,因此选择方案3作为分布式共享变量的压缩方案。
4、数据大小导致的网络消耗分析和极端情况控制
4.1 背景概述
这种方案也存在一些弊端,即需要把用户画像数据通过网络传递,显然这增加了网络开销。理论上,网络数据量与传输速度成正比,但是在工程实践中,带宽肯定是有上限的,因此,对于DMP画像数据存入大小进行压测试验,以确定分布式共享变量对于网络性能的影响。
4.2 压测方案
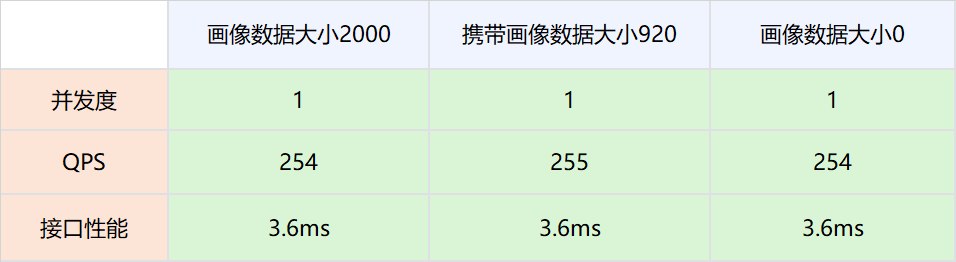
1.测试网络,画像数据不被策略引擎使用,策略引擎依然请求DMP服务。
实验组是请求策略引擎服务的时候带入压缩后的画像数据,对照组是请求策略引擎服务的时候不带入压缩后的画像数据。调整并发值,比较在不同QPS场景下两者的接口性能。
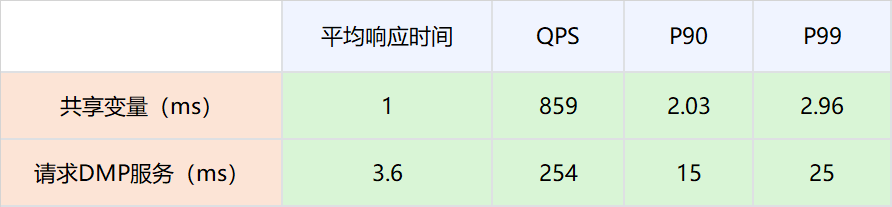
2.分布式共享变量的画像数据被策略引擎使用,策略引擎在有分布式共享变量画像数据的时候,不再请求DMP服务。
4.3结论
-
网络链路上存放数据大小在2000以下,对网络性能的影响可以忽略不计。
-
因为分布式共享变量的存在而减少对DMP服务的请求,接口性能可以有比较大的提升。具体数值为P99从25ms提升到2.96ms。
4.4 极端情况控制
因为DMP数据与用户行为相关,比如一个用户在海外站点所有站点都有购买会员的行为,那么其DMP画像数据就会很大。为了防止这种极端情况所以在判断压缩后的用户画像数据足够大的时候,将自动舍弃,而不是放入网络当中,防止大数据对整个网路数据的性能损耗。
5、线上运行情况
5.1 性能优化
|
|
|
|
|
|
|
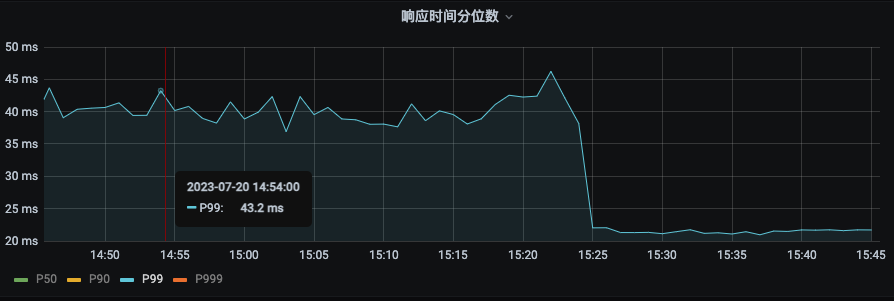
P99 由之前的43ms下降到22ms。下降幅度 48.8%
|
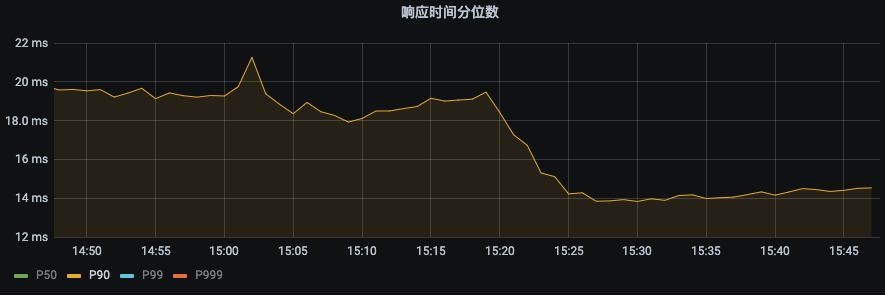
P90由之前19ms下降到14ms,下降幅度26.3%
|
5.2 对DMP服务的流量优化
|
|
|
|
|
分布式共享变量使用率即为对不同DMP服务优化流量。
A业务节约大约25%的流量,B业务节约约10% 的流量,
|
|
|
|
|
6、结论
分布式共享变量在满足数据实时性要求的前提下,减少了对DMP服务的流量,同时提高了策略引擎服务的接口性能,具体优化指标见上节。
本地共享变量介绍
1、原理概述
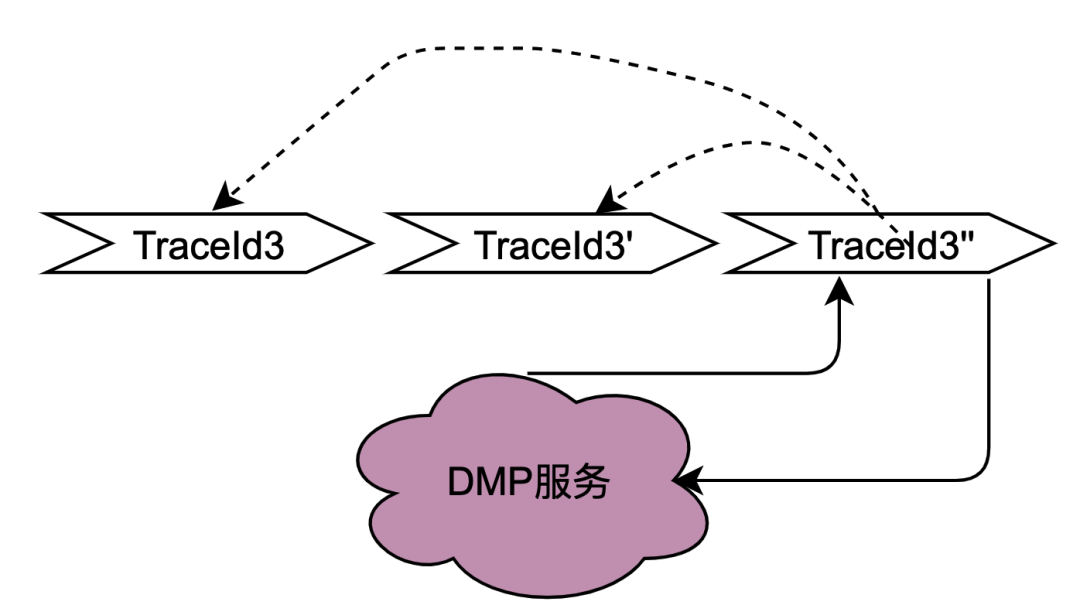
在2.2.2 并行调用场景章节对本地共享变量解决的调用场景进行了阐述,主要解决的是同一个用户并发请求策略引擎带来的多次请求DMP服务问题。如何区分是同一个用户的同一次请求呢?答案是TraceId。在一个请求下,TraceId一定是相同的,如果TraceId相同,那么策略引擎则可以认为是同一个用户的一次请求。
如上图,如果同时多个TraceId3的请求到达策略引擎,将这些请求放入队列,只要其中一个去获取用户画像数据(此处为TraceId3''),其余的请求TraceId3和TraceId3'在队列中等待TraceId3''的结果拿来用即可。
这种思路可以很好的优化并发请求的数据,符合策略引擎调用特性。实现起来有点类似AQS,开发落地有一些难点,比如Trace3''什么时候去请求DMP服务,当拿到数据后,后面仍然有其他trace3进来该如何处理,等待多少时间?这么一思考,这个组件的实现将会耗费我们很多的开发时长,那么有没有现成的中间件可以用呢?答案是本地缓存框架。
无论是本地缓存Caffeine 还是Guava Cache,有相同key的多个请求,只有一个key会请求下游服务,而其他请求会等待拿现成的结果。另外存放的时间可以通过配置缓存的失效时间来确定,至于失效时间的计算方法,将在下面章节会介绍。
2、网关层Hash路由方式的支持
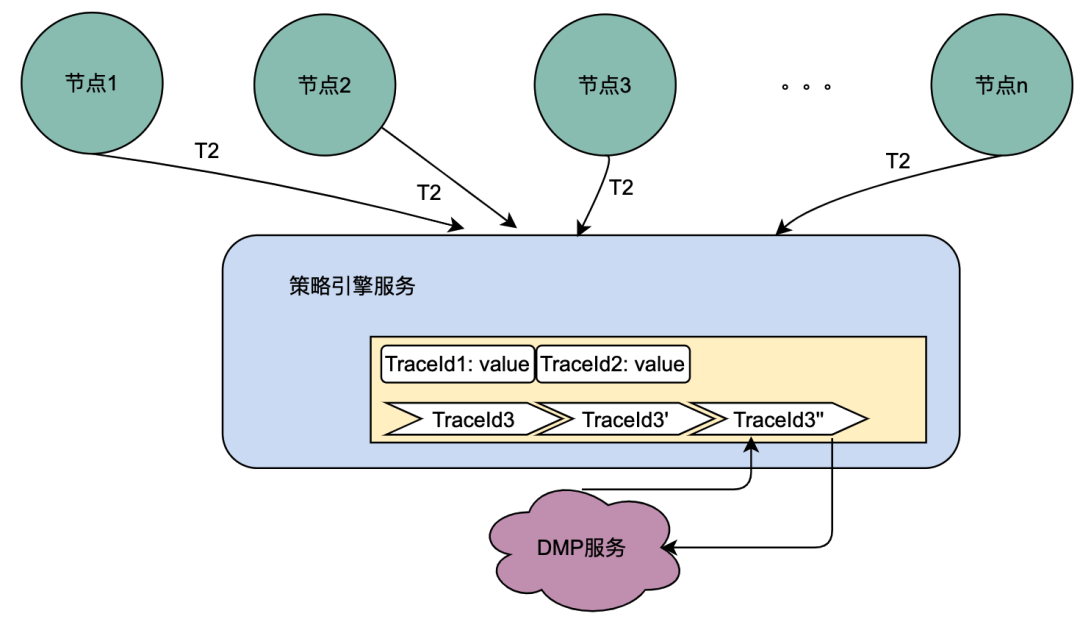
目前,主流的服务一般都是多机房多机器部署,这样有水平扩展能力可以应对业务增长带来的流量增加的问题。但同一个用户的同一个请求,很可能到不同的服务实例,这样上一次获取到的本地缓存数据在下一次请求当中就无法获取。
如上图,同一个用户的同一次请求,被聚合层并发请求到不同业务节点1到节点n。由于策略引擎服务是多实例部署,那么不同节点的请求可能到不同实例,那么本地共享变量的命中率就会大大降低,对DMP服务的流量节约数据就会小很多。因此,需要一个方案使得用户的多次请求能到同一个机房的同一个实例。
最终落地的方案是网关支持按照业务自定义字段Hash路由。策略引擎使用qyid进行hash路由,即同一个设备的所有请求到策略引擎服务,那么路由到的机器实例一定是同一个。这样可以很好的提升本地共享变量的命中率。这里提一下,相比轮询请求,字段Hash方式存在如流量偏移的问题,需要配合服务实例流量的监控和报警,避免某些实例流量过多而导致不可用。由于和本次主题无关,实例流量的监控和报警在这里就不做介绍。
3、本地共享变量个数和有效时间设计
和本地缓存不同,本地共享变量的最大个数和过期时间与命中率不成正比,这和具体业务指标相关。
假设策略引擎服务QPS10000,服务实例有50台,那么每台实例的QPS是200,即一台服务实例每秒的请求是200个。只需要保证,同一个TraceId的一批请求,在个数区间内不被淘汰,在时间区间内不被过期即可。我们通过网关日志查找历史上同一个traceId的请求时间戳,几乎都在100ms内。
那么过期时间设置为1s,最大个数设置为200个就可以保证绝大多数同一个TraceId的批次请求,只有一个请求下游服务,其余从缓存获取数据。我们为此也进行了实验,设置不同的过期时间和缓存最大个数,结论和以上分析完全一致。
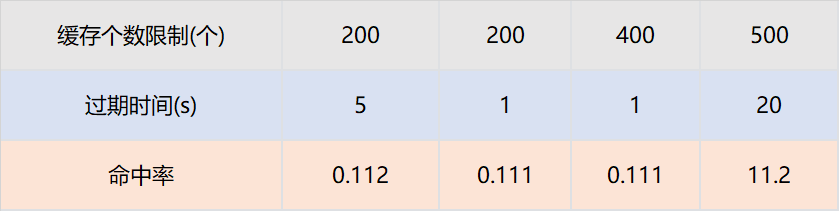
本地共享变量命中率与接口QPS和相同TraceId并发时间相关。
4、结论
-
对于DMP服务1,优化流量15.8%。对于DMP服务2,优化流量 16.7%。对于DMP服务3,优化流量16.2%。
-
与分布式共享变量一样,本地共享变量同样可以满足数据实时性要求,即不会存在1.2.2 遇到的困境 所遇到的缓存导致的数据实时性不够的问题。
总结和展望
本次优化是比较典型的技术创新项目。是先从社区看到一篇技术博客,然后想到爱奇艺海外遇到相同痛点问题的的项目,从而提出优化因为微服务导致的策略引擎对于DMP服务流量压力的目标。
在落地过程中,遇到使用本地缓存进行优化而无法克服数据实效性问题的挑战。最终沉下心分析策略引擎的调用链路,将调用链路一分为二:串行调用和并行调用,最终提出了共享变量的解决方案。因为串行调用和并行调用的特点迥异,依次针对两者进行分期优化,其中第一期通过分布式共享变量优化了串行调用DMP服务的流量,在第二期通过本地共享变量优化了并行调用DMP服务的流量。
参考文章:

也许你还想看
低代码、中台化:爱奇艺号微服务工作流实践
揭秘内存暴涨:解决大模型分布式训练OOM纪实
分布式系统日志打印优化方案的探索与实践
本文分享自微信公众号 - 爱奇艺技术产品团队(iQIYI-TP)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
Origin my.oschina.net/u/4484233/blog/10924140