
The use of time series databases (TSDBs) has been common in various industries for decades, especially in financial and industrial control systems. However, the emergence of the Internet of Things (IoT) has led to a surge in the amount of time series data (time series data for short), which has placed higher requirements on database performance and storage costs, thus promoting the need for dedicated time series databases.
Faced with the problems of outdated architecture and limited scalability of legacy time series solutions, a new generation of time series databases emerged. They adopt modern architectures that enable distributed processing and horizontal expansion, as well as flexible deployment in the cloud or on-premises.
At the end of 2022, another blockbuster product joined the open source time series database track, and was tested and produced by more than 60 companies in just one year, attracting 70+ contributors from key universities and companies at home and abroad—— openGemini, Huawei's open source distributed time series database, mainly focuses on the storage and analysis of massive time series data. Through technological innovation, it simplifies the business system architecture, reduces the storage cost of massive time series data, and improves the storage and analysis efficiency of time series data.
Today, we invited Xiang Yu, the leader of the openGemini community, to talk about their open source story~
01 Originating from internal needs and gradually moving towards self-research
The research and development of openGemini originally originated from Huawei's own needs.
In 2019, with the establishment of Huawei Cloud, data centers have been built in Guangzhou, Shanghai, Beijing, Guizhou, and Hong Kong, and 260+ cloud services have been launched. On average, several TB of monitoring indicator data are collected every day. The original big data solution is gradually overwhelmed. The larger the amount of data, the lower the query efficiency, and the cost of data storage continues to rise. There is an urgent need for a high-performance, high-scalability dedicated time series database.
At that time, there were no useful time series database products that could keep up with the development of demand. InfluxDB is still a stand-alone version, and domestic Apache IoTDB and TDengine are far from meeting production requirements. Therefore, Huawei is determined to build its own database, optimize data processing, and solve very important business problems at the moment. In this context, openGemini came into being.
According to Xiang Yu, in terms of technology selection, they initially carried out cluster transformation based on the open source InfluxDB. However, with the increase in the number of indicators and the increase in collection frequency, the daily increase in data volume has reached tens of terabytes. At this time, the flaws in InfluxDB's own architecture began to become apparent, affecting the performance and stability of the system. Therefore, they chose to reconstruct the architecture and began the self-development of the openGemini kernel.
02 Unique personality, leading performance
Since its inception, openGemini has been closely linked to Huawei's own business needs, so every design is full of practical considerations. Specifically, openGemini is different from other time series databases in nine major "personalities":
Performance advantage: Among openGemini's differentiated competitiveness, high performance is the most important one. In massive data scenarios, openGemini improves simple query scenarios by more than 2 times, medium query scenarios by more than 5 times, and complex query scenarios by more than 10 times compared with open source InfluxDB. Compared with other similar open source products, openGemini also has obvious performance advantages.
The officially announced stand-alone writing performance is as follows (the test tool is TSBS, please refer to the openGemini official website documentation for relevant test details):

Officially announced single-machine query performance comparison in DevOps scenarios (average latency, ms):

Officially announced single-machine query performance comparison in IoT scenarios (average delay, ms):
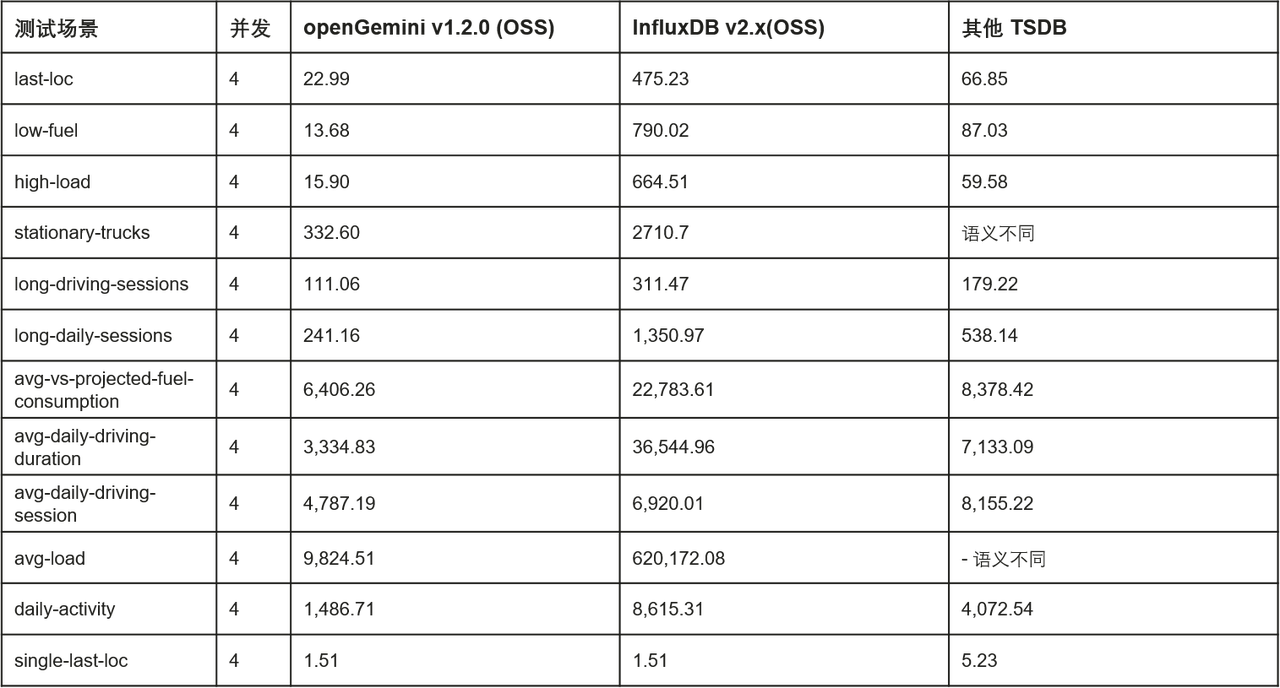
In addition, openGemini has launched a series of practical functions in data storage and data analysis to build more differentiated competitiveness:
Unique distributed architecture : openGemini provides two versions: stand-alone and distributed cluster. The distributed cluster adopts the MPP massive parallel processing layered architecture, which divides the computing engine, storage engine and metadata management into independent components. They are ts-sql, ts-store, and ts-meta respectively. Different components support independent horizontal expansion, making it possible to flexibly respond to complex application scenarios.
High cardinality engine: The high cardinality problem (also known as the disaster of dimensionality) will cause the inverted index to expand, causing excessive memory resource consumption and reduced read and write performance. It has long plagued the development of time series databases. The openGemini high-radix engine completely solves this problem by building a time-series-specific sparse index, which is very suitable for use in network monitoring, financial risk control, Internet of Things, transportation and other fields.
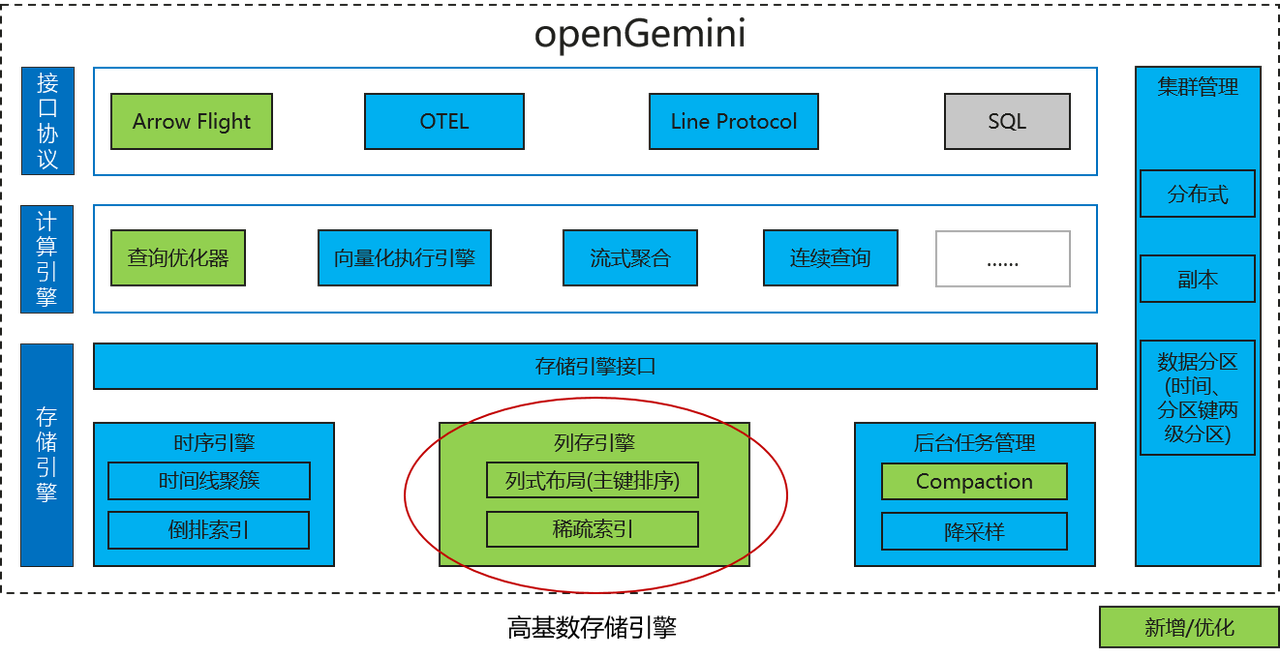
Text retrieval: Text data is a common data type. openGemini supports the creation of indexes on text data, adopts a dynamic learning word segmentation method, supports precise, phrase and fuzzy matching, and has low memory resource usage and high retrieval efficiency. advantage.
Streaming aggregation: Streaming aggregation is a pre-aggregation method that downsamples data while writing data. Its purpose is to solve the problem of traditional downsampling methods that read a large amount of historical data from disk for calculation, resulting in serious I/O amplification. The problem.
Multi-level downsampling : For existing historical data, traditional downsampling methods will retain historical data details. In some scenarios, the historical data details are not important, and only the data characteristics need to be retained. The multi-level downsampling function can extract the features of the historical data details and replace the historical data details in place, which can further reduce the cost by 50%. Storage costs.
Anomaly detection and prediction: Anomaly detection and prediction is currently one of the most mature applications of time series data analysis, and is widely used in scenarios such as quantitative transactions, network security detection, and daily maintenance of data centers, industrial equipment, and IT infrastructure. openGemini provides an anomaly detection library - openGemini-castor, which encapsulates detection algorithms for 13 common anomaly scenarios. It has the advantages of fast detection speed, high accuracy, and integration of stream and batch, helping applications improve data analysis efficiency.
Hot and cold data tiered storage: Supports the transfer of historical data to object storage, enabling a low-cost method to permanently retain historical data, and also supports offline analysis of big data. [This feature is planned to be released in H2]
Data reliability : Supports multiple computing copies to further improve data reliability. [This feature is planned to be released in H2]

03 Focus on user experience, making it easier to get started
openGemini not only has strong performance, but its unique design can also bring a lot of comfortable experience in actual applications:
In terms of getting started , openGemini is fully compatible with the InfluxDB v1. At the same time, openGemini uses the same Line Protocol as InfluxDB. The data modeling is simple and easy to understand, and it is also friendly to developers of relational databases. Finally, openGemini uses a SQL-like query language, which requires no additional learning and is easy to get started. For cluster deployment, the community also provides the one-click deployment tool Gemix, which saves a lot of configuration work.
In terms of operating systems , openGemini currently supports mainstream Linux systems (including openEuler), Windows and MacOS, making application development and debugging more convenient. The processor supports both X86 and ARM64 architectures.
In terms of cloud nativeness , openGemini provides Dockerfile and Docker images, supporting the deployment of Docker, K8s, KubeEdge and other platforms. Since the IP address changes after the container is restarted, openGemini has added a domain name function to ensure that cluster nodes can still maintain connectivity after the container is restarted. The community has also created the openGemini-operator project to facilitate users' one-click container deployment. openGemini supports Prometheus remote reading and writing, and can be used as a backend storage for Prometheus to solve its problem of insufficient storage capacity. [btw: openGemini will also directly support PromQL, which is currently under development]
In terms of observability , the community has developed the ts-monitor component, which specializes in collecting node and kernel indicators. It is divided into 19 subcategories and more than 260 items. It can be used with Grafana to achieve comprehensive monitoring of the operating status of openGemini. For example, indicators such as CPU and memory utilization, write bandwidth, write latency, write concurrency, and QPS can be viewed at a glance through the visual interface, making it easy to view operating status, database performance tuning, and precise location of problems at any time.
04 After internal actual combat testing, give back to open source
As a time series database, openGemini is currently most commonly used in the Internet of Things and operation and maintenance monitoring. In terms of processing massive data, it has advantages that ordinary databases cannot match. At the same time, openGemini, as an internal project of Huawei, has passed the test of "its own people":
Huawei Cloud SRE uses openGemini as the monitoring data storage base. A total of 25 clusters are deployed across the entire network, with a maximum cluster size of 70 nodes. It has successfully withstood the actual test of 40 million data writes per second and 50,000 concurrent queries. Compared with the original solution, when carrying the same business, the end-to-end delay of the original system is reduced by 50%, CPU resources can be saved by 68%, memory resources can be saved by 50%, and hard disk resources can be saved by more than 90%.
Huawei Cloud's industrial IoT platform has been using the stand-alone version of InfluxDB before. Since switching to openGemini, it no longer has to worry about throughput. The end-to-end and query performance has increased by 3 times, and the number of device accesses has increased to Million level.
Xiang Yu introduced that openGemini originated from open source and benefited a lot from the InfluxDB open source project. Therefore, adhering to the spirit of open source, all openGemini codes are open sourced. He hopes that more companies and developers around the world will benefit from it, and also hopes that through the open community The platform, together with developers, jointly promotes technological innovation and shares open source results.
At present, openGemini only has open source version and cloud service. It does not plan to get involved in offline commercial versions, and is willing to donate to the foundation. At present, the community still has many imperfections. Next, the community will further enrich openGemini's ecological tools (such as data migration tools, SDK, big data ecological integration, etc.), visual management interfaces, documents, etc.
"At present, the community's technical planning will generally focus on the three important application scenarios of the Internet of Things, operation and maintenance monitoring and observability, and strengthen the ecological compatibility and kernel capability building of related technologies. We are beginning to demonstrate the next generation software architecture of openGemini." Xiang Yu said.
“In the short term, openGemini will not consider industrial-related scenarios, because the business scenarios in the industrial field are very complex, the real-time requirements are extremely high, the moats of industrial software manufacturers are very deep, and the things that time series databases can do are limited. In addition, the community lacks industry background. , We don’t know enough about this scenario. After that, we will consider looking for some partners in the industrial field, such as industrial software suppliers, solution providers, etc., to cooperate and improve together,” Xiang Yu said.
openGemini official website homepage: https://www.openGemini.org/
openGemini open source address: https://github.com/openGemini
Fellow chicken "open sourced" deepin-IDE and finally achieved bootstrapping! Good guy, Tencent has really turned Switch into a "thinking learning machine" Tencent Cloud's April 8 failure review and situation explanation RustDesk remote desktop startup reconstruction Web client WeChat's open source terminal database based on SQLite WCDB ushered in a major upgrade TIOBE April list: PHP fell to an all-time low, Fabrice Bellard, the father of FFmpeg, released the audio compression tool TSAC , Google released a large code model, CodeGemma , is it going to kill you? It’s so good that it’s open source - open source picture & poster editor tool