Since its release on November 30, 2022, ChatGPT has been occupying the headlines in the technology industry. As Apple’s innovation capabilities decline, ChatGPT has continued to shock everyone. On November 7, 2023, the first OpenAI The developer conference was held in Los Angeles. The industry generally believes that the OpenAI developer conference may replace the Apple conference and become the most eye-catching "Technology Spring Festival Gala" in the AI era.
But how does ChatGPT work behind the scenes, and how is its super power formed? What's so special about it? Can its competitors surpass it? This series of issues is what this article will discuss.
What is ChatGPT?
ChatGPT stands for Chat Generative Pre-trained Transformer, a large language model based on deep learning. Its model structure uses the Transformer network. This network can learn the rules and patterns of language from input text and use these rules and patterns to predict the next word or character.

During the training process of chatGPT, chatGPT received massive text data, which includes various sources, such as Wikipedia, news articles, novels, web pages, etc. These huge data sets are used to form a deep learning neural network that mimics the human brain. During the learning process, chatGPT attempts to learn the language rules and patterns in these data and predict the next word or character in the text sequence to improve itself. accuracy.
When you communicate with chatGPT, your input is converted into a vector and then fed into chatGPT’s neural network. The network performs a series of calculations and transformations on the input to generate the corresponding output vector. Ultimately, the output vectors are translated into text to answer your questions or provide relevant information.
The training and inference process of chatGPT requires a large amount of computing resources and data storage, so chatGPT is usually run in the cloud or on a large server. It is designed to be scalable and efficient, can handle massive amounts of text data, and is capable of supporting multilingual and diverse natural language processing tasks.
The reason why everyone is shocked by ChatGPT is because what ChatGPT does is truly close to the human ability to understand and use language - directly receiving natural language, then directly replying to natural language, and Ensure the fluency and logic of the language. This is how people communicate with each other.
ChatGPT works by trying to understand your question and then outputting the string it predicts that best answers your question based on the training data. While this sounds relatively simple, the complexity of what goes on behind the scenes is unimaginable.
Transformer architecture
The core of ChatGPT's entire work is the "Transformer", a neural network used to process natural language data. Neural networks process information through layers of interconnected nodes to simulate the way the human brain works. Think of a neural network like a hockey team: each player has a role, but they pass the puck back and forth between players with specific roles, all working together to score points.
The algorithm structure of AI has undergone a long period of exploration and accumulation before the qualitative change of Transformer today.
The first stage: pattern matching. Enter a series of logic and rules into the AI, and the AI will make judgments and reasoning based on the rules. Representative ones include symbolic logic, connectionism, etc., which are mainly used in games including chess and chess.
The second stage: machine learning, which allows computers to have the ability to learn without explicit programs to handle more complex tasks. Representative algorithms include backpropagation, decision trees, neural networks, rule engines, etc. It is mainly used in fields such as speech recognition, image recognition and machine translation.
The third stage: artificial neural network, with the increase in data volume and improvement in computing power, a machine learning algorithm based on the neural network structure. Classic algorithms during this period include support vector machines, naive Bayes, convolutional neural networks, and recurrent neural networks.

Phase Four: Deep Learning Neural Networks, a complex, multi-layered, weighted algorithm that mimics the human brain, is able to learn patterns and relationships in text data and exploit the ability to create human-like capabilities. Respond by predicting what text should come next in any given sentence. Representative algorithms include Transformer.

The Transformer architecture processes word sequences by using "self-attention" to weigh the importance of different words in the sequence when making predictions. Self-attention is similar to the way a reader looks back to a previous sentence or paragraph to understand the context needed to understand a new word in a book. The converter looks at all the words in the sequence to understand the context and the relationships between the words.
The converter consists of multiple layers, each layer containing multiple sub-layers. The two main sub-layers are the self-attention layer and the feed-forward layer. The self-attention layer computes the importance of each word in the sequence, while the feed-forward layer applies a non-linear transformation to the input data. These layers help the transformer learn and understand the relationships between words in the sequence. While it sounds complicated and is complicated to explain, the Transformer model fundamentally simplifies how artificial intelligence algorithms are designed. It allows parallel computation (or completion at the same time), which means a significant reduction in training time. Not only does it make AI models better, it makes them faster and cheaper to produce.
Transformer does not use words, but "markers", which are blocks of text encoded as vectors (numbers with position and orientation). The closer two marker vectors are in space, the more correlated they are. Similarly, attention is encoded as a vector, which enables Transformer-based neural networks to remember important information from earlier in a paragraph.
GPT-3 was trained on approximately 500 billion tokens, which allows its language model to more easily assign meaning and predict possible subsequent text by mapping them into vector space. Many words map to a single token, but longer or more complex words are often broken up into multiple tokens. On average, tokens are approximately four characters long.

Pretraining and Reinforcement Learning with Human Feedback (RLHF)
Pre-trained means "pre-trained", which is a very important part of GPT being able to do what it can do. Artificial intelligence uses two main methods for pre-training: supervised and unsupervised.
Prior to GPT, the best-performing AI models used "supervised learning" to develop their underlying algorithms. They were trained on manually labeled data, such as a database containing photos of different animals along with human-written textual descriptions of each animal. These types of training data, while effective in some cases, are very expensive to produce and are limited in how they can be scaled. Human trainers must spend a lot of manpower, time and effort to predict all inputs and outputs.
It’s impossible to predict all the questions that will be asked, so ChatGPT uses unsupervised pre-training—and that’s a game changer.
GPT uses generative pre-training, given a few basic rules, and then fed a massive amount of unlabeled data—pretty much the entire open internet. It then processes all this data "unsupervised" and develops its own understanding of the rules and relationships that govern the text.
Of course, when you use unsupervised learning, you don't really know what you're going to get, so GPT has also been "fine-tuned" to make its behavior more predictable and appropriate. Make the model’s output reasonable through supervised instruction fine-tuning + reinforcement learning with human feedback.



training data set
Some earlier studies have proven that as the amount of parameters and training data increases, the ability of the language model will increase linearly with the exponential increase in the amount of parameters. This phenomenon is called Scaling Law. But after 2022, with in-depth research on large models, people found that when the number of parameters of the model is greater than a certain level, the model's capabilities will suddenly skyrocket, and the model will suddenly have some mutation capabilities, such as reasoning capabilities and zero-shot learning. Ability etc.

ChatGPT is a unique model and besides Persona-Chat, there are many other conversation datasets used to fine-tune ChatGPT. Here are some examples:
- Cornell Film Dialogue Corpus: A dataset containing dialogue between characters in movie scripts. It contains more than 200,000 conversations between more than 10,000 pairs of movie characters, covering a variety of topics and genres.
- Ubuntu Conversation Corpus: A collection of conversations between users seeking technical support and the Ubuntu community support team. It contains over 1 million conversations, making it one of the largest publicly available datasets for conversational systems research.
- DailyDialog: A collection of person-to-person conversations on various topics, from daily life conversations to discussions about social issues. Each conversation in the dataset consists of several turns and is labeled with a set of sentiment, mood, and topic information.
In addition to these datasets, ChatGPT was trained on large amounts of unstructured data from the Internet, including websites, books, and other text sources. This allows ChatGPT to understand the structure and patterns of language in a more general sense, which can then be fine-tuned for specific applications such as conversation management or sentiment analysis.

Natural Language Processing (NLP)
After solving the problem of accuracy, we also need to solve the problem of "natural smoothness" of communication. This is natural language processing technology, or NLP for short, a technology that enables computers to understand, interpret and generate human language.
One of the key challenges of NLP is dealing withthe complexity and ambiguity of human language. It starts by taking your question, breaking it down into tokens, and then using its Transformer-based neural network to try to understand what the most salient parts of it are and what you're really asking it to do. From there, the neural network fires up again and generates an appropriate sequence of token outputs based on what it learned from the training data and fine-tuning.
NLP algorithms need to be trained on large amounts of data to recognize and learn the nuances of language. And it needs to be continuously refined and updated to keep up with changes in language use and context.
Computing power
Computing power refers to the ability of data processing and calculation, which can be measured by the number of floating point operations per second (Flops). At present, large AI models mainly rely on GPU or CPU+FPGA, ASIC and other computing chips to achieve efficient operation. These computing power chips are specially designed to accelerate artificial intelligence algorithms. They are also called AI accelerators or computing cards and are the basis of AI computing power.
ChatGPT requires a veryamount of computing power (chips) to support its training and deployment. According to Microsoft news, the AI supercomputer that provides computing support for ChatGPT is a large-scale top-level supercomputer built by Microsoft with an investment of US$1 billion in 2019. It is equipped with tens of thousands of NVIDIA A100 GPUs, and is also equipped with more than 60 data centers and deployed Assisted by hundreds of thousands of NVIDIA GPUs.

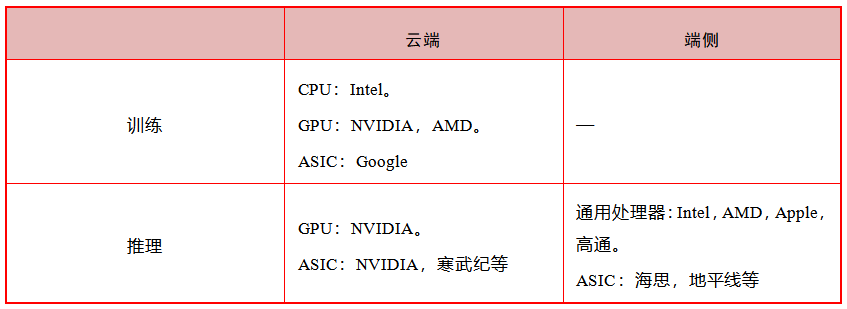
The huge number of user visits also puts huge performance and cost pressure on computing power. According to Similarweb data, the number of visits to OpenAI reached 1.1 billion in February this year. According to Fortune data, the cost of cloud computing power generated by users each time they interact with ChatGPT is about US$0.01. If calculated at a lower level, each visit to the website only costs 0.01 US dollars. For one interaction, the computing power cost alone would be US$11 million per month.
Questions and expectations
Although ChatGPT already has strong capabilities, as more and more people use it after it goes online, many problems have been discovered. For complex reasoning, analysis and calculation tasks, the probability of answering incorrectly is still very high. In addition, during the training process of ChatGPT, RLHF is used to guide the model to learn according to human preferences. However, this learning style can also lead to models that overly cater to human preferences and ignore correct answers. Therefore, you can see that ChatGPT often talks serious nonsense. There is also data privacy and security.
Although ChatGPT is currently the most popular large-scale language model, more competition is likely to emerge in the next few years. For example, Google's Bard, Facebook's Llama 2, Writer's Palmyra LLM and Anthropic's Claude.
Rather than problems, we are more looking forward to the future of ChatGPT. They will continue to become better at understanding and responding to us humans, so efficient that they can be used on almost any device, such as mobile phones and even small devices. They'll also become experts in specific fields, like medicine or law, which is pretty cool.
Also, these language models will be able to process not just text, but also images and sounds, and will work with languages from around the world. Additionally, efforts are being made to ensure these AI models are fair and accountable, to make them more open and less biased.
The most exciting thing is that these language models will become our amazing companions, helping us complete various tasks and making our lives easier in countless ways.
参考资料:
1、https://jalammar.github.io/illustrated-transformer/
2、https://zapier.com/blog/how-to-use-google-bard/
3、https://openai.com/chatgpt
4、https://www.zdnet.com/article/what-is-chatgpt-and-why-does-it-matter-heres-everything-you-need-to-know/
5、https://www.yunliebian.com/yingxiao/article-44223-1.html
6、https://www.vinayiyengar.com/2022/08/04/the-promise-and-perils-of-large-language-models/
7、https://babylm.github.io/