Table of Contents of Series Articles
Table of contents

Preface
This project is based on the convolutional neural network (CNN) model to train the collected cat image data. By using data augmentation technology and combining residual networks, it aims to improve the performance of the model to achieve accurate identification of different cat types.
First, the project utilizes a CNN model, a deep learning model specifically designed for image recognition tasks. Through multiple convolution and pooling layers, this model can effectively capture features in images and provide powerful learning capabilities for cat category recognition.
Secondly, by training on the collected data, this project aims to build a model that can accurately identify cat types. Images of a variety of cats are included to ensure the model can generalize to different species and scenarios.
To further improve model performance, data augmentation techniques were employed. Data augmentation generates more variants by rotating, flipping, scaling and other operations on the images in the training set, which helps the model better adapt to different viewing angles and conditions.
At the same time, introducing the idea of residual network can help solve the problem of gradient disappearance in deep network training and improve the training effect of the model. This combined approach makes the model more robust and accurate.
Finally, through this project, the goal of accurately identifying cat types was achieved. This has the potential for practical application in the pet field, zoological research, etc., providing an efficient and reliable tool for related fields.
overall design
This part includes the overall system structure diagram and system flow chart.
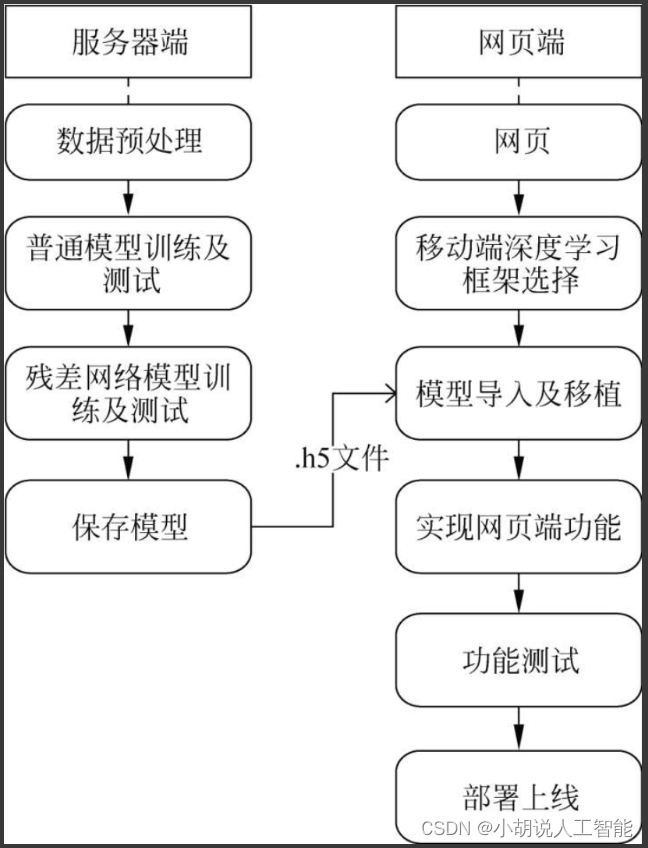
Overall system structure diagram
The overall structure of the system is shown in the figure.
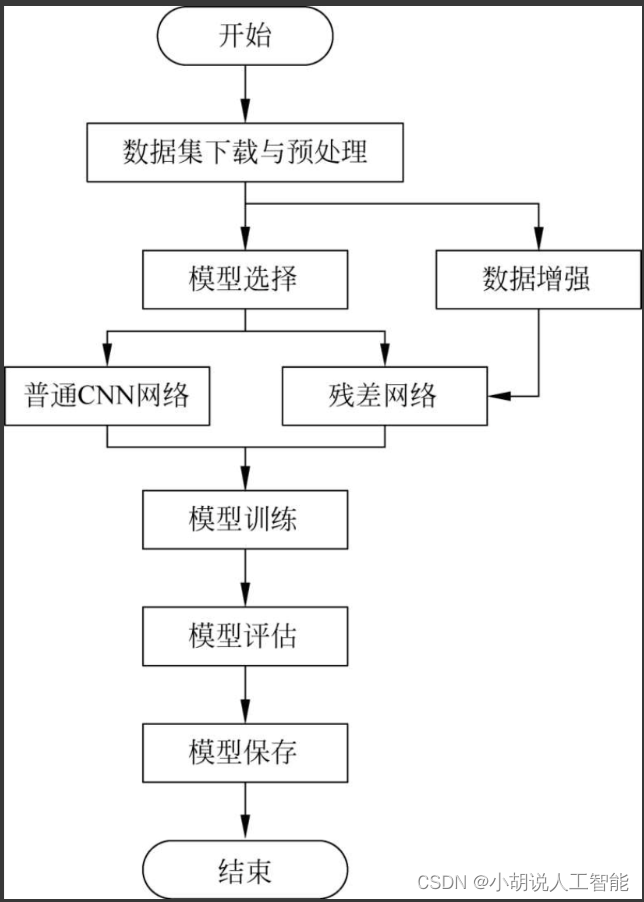
System flow chart
The system flow is shown in the figure.
Operating environment
This part includes computing cloud servers, Python environment, TensorFlow environment and MySQL environment.
详见行客.
Module implementation
This project includes 5 modules: data preprocessing, data enhancement, ordinary CNN model, residual network model, and model generation. The function introduction and related codes of each module are given below.
1. Data preprocessing
Open your browser and search for pictures of Ragdoll, Bombay, Siamese and British Shorthair cats. Use the batch downloader to download images and select images with obvious features as a data set. The pictures used include 101 Ragdoll cats, 97 Bombay cats, 101 Parrot cats and 85 British Shorthair cats, for a total of 384 pictures. (Among them /cat_kind_model/cat_data_100 and /cat_kind_model/cat_data_224 in the project code can also be downloaded)
Preprocess the data set, including modifying the picture name, adjusting the format and size, and dividing the pictures into a training set and a test set in proportion.
import os #导入各种模块
from PIL import Image
import argparse
from tqdm import tqdm
class PrepareData: #准备数据类
def __init__(self, options): #初始化
self.moudle_name = "prepare data"
self.options = options
self.src_images_dir = self.options.src_images_dir
self.save_img_with = self.options.out_img_size[0]
self.save_img_height = self.options.out_img_size[1]
self.save_dir = self.options.save_dir
#统一图片类型
def renameJPG(self, filePath, kind): #图片重命名
#filePath:图片文件的路径,kind: 图片的种类标签
images = os.listdir(filePath)
for name in images:
if (name.split('_')[0] in ['0', '1', '2', '3']):
continue
else:
os.rename(filePath + name, filePath + kind + '_' + str(name).split('.')[0] + '.jpg')
#调用图片处理
def handle_rename_covert(self): #重命名处理
save_dir = self.save_dir
#调用统一图片类型
list_name = list(os.listdir(self.src_images_dir))
print(list_name)
train_dir = os.path.join(save_dir, "train")
test_dir = os.path.join(save_dir, "test")
#1.如果已经有存储文件夹,执行则退出
if not os.path.exists(save_dir):
os.mkdir(save_dir)
os.mkdir(train_dir)
os.mkdir(test_dir)
list_source = [x for x in os.listdir(self.src_images_dir)]
#2.获取所有图片总数
count_imgs = 0
for i in range(len(list_name)):
count_imgs += len(os.listdir(os.path.join(self.src_images_dir, list_name[i])))
#3.开始遍历文件夹,并处理每张图片
for i in range(len(list_name)):
count = 1
count_of_each_kind = len(os.listdir(os.path.join(self.src_images_dir, list_name[i])))
handle_name = os.path.join(self.src_images_dir, list_name[i] + '/')
self.renameJPG(handle_name, str(i))
#调用统一图片格式
img_src_dir = os.path.join(self.src_images_dir, list_source[i])
for jpgfile in tqdm(os.listdir(handle_name)):
img = Image.open(os.path.join(img_src_dir, jpgfile))
try:
new_img = img.resize((self.save_img_with, self.save_img_height), Image.BILINEAR)
if (count > int(count_of_each_kind * self.options.split_rate)):
new_img.save(os.path.join(test_dir, os.path.basename(jpgfile)))
else:
new_img.save(os.path.join(train_dir, os.path.basename(jpgfile)))
count += 1
except Exception as e:
print(e)
#参数设置
def main_args():
parser = argparse.ArgumentParser()
parser.add_argument('--src_images_dir', type=str, default='../dataOrig/',help="训练集和测试集的源图片路径")
parser.add_argument("--split_rate", type=int, default=0.9, help='将训练集二和测试集划分的比例,0.9表示训练集占90%')
parser.add_argument('--out_img_size', type=tuple, default=(100, 100),help='保存图片的大小,如果使用简单网络结构参数大小为(100,100),如果使用resnet大小参数为(224,224)')
parser.add_argument("--save_dir", type=str, default='../cat_data_100', help='训练数据的保存位置')
options = parser.parse_args()
return options
if __name__ == "__main__":
#获取参数对象
options = main_args()
#获取类对象
pd_obj = PrepareData(options)
pd_obj.handle_rename_covert()
2. Data enhancement
The so-called data enhancement is to expand the existing data set through operations such as flipping, rotating, scaling, random cropping, shifting, and adding noise. The amount of data in this project is small and it is impossible to extract the deep features of the image. When using a deep residual network, it is easy to cause the model to overfit.
from keras.preprocessing.image import ImageDataGenerator, img_to_array, load_img
import argparse, os
from PIL import Image
from tqdm import tqdm #进度条模块
datagen = ImageDataGenerator(
rotation_range=40, #整数,数据提升时图片随机转动的角度
width_shift_range=0.2,#浮点数,图片宽度的某个比例,数据提升时图片水平偏移的幅度
height_shift_range=0.2,#浮点数,图片高度的某个比例,数据提升时图片竖直偏移的幅度
rescale=1. / 255, #重放缩因子,默认为None
shear_range=0.2, #浮点数,剪切强度(逆时针方向的剪切变换角度)
zoom_range=0.2, #浮点数或形如[lower,upper]的列表,随机缩放的幅度
#若为浮点数,则相当于[lower,upper] = [1 - zoom_range, 1+zoom_range]
horizontal_flip=True, #布尔值,进行随机水平翻转
vertical_flip=False, #布尔值,进行随机竖直翻转
fill_mode='nearest', #‘constant’,‘nearest’,‘reflect’或‘wrap’之一,
#进行变换时超出边界的点将根据本参数给定的方法进行处理
cval=0, #浮点数或整数,当fill_mode=constant时,指定要向超出边界的点填充值
channel_shift_range=0, #随机通道转换的范围
)
def data_aug(img_path, save_to_dir, agu_num):
img = load_img(img_path)
#获取被扩充图片的文件名部分,作为扩充结果图片的前缀
save_prefix = os.path.basename(img_path).split('.')[0]
x = img_to_array(img)
x = x.reshape((1,) + x.shape)
i = 0
for batch in datagen.flow(x, batch_size=1, save_to_dir=save_to_dir,
save_prefix=save_prefix, save_format='jpg'):
i += 1
#保存agu_num张数据增强图片
if i >= agu_num:
break
#读取文件夹下的图片,并进行数据增强,将结果保存到dataAug文件夹下
def handle_muti_aug(options):
src_images_dir = options.src_images_dir
save_dir = options.save_dir
list_name = list(os.listdir(src_images_dir))
for name in list_name:
if not os.path.exists(os.path.join(save_dir, name)):
os.mkdir(os.path.join(save_dir, name))
for i in range(len(list_name)):
handle_name = os.path.join(src_images_dir, list_name[i] + '/')
#tqdm()为数据增强添加进度条
for jpgfile in tqdm(os.listdir(handle_name)):
#将被扩充的图片保存到增强的文件夹下
Image.open(handle_name+jpgfile).save(save_dir+'/'+list_name[i]+'/'+jpgfile)
#调用数据增强过程函数
data_aug(handle_name+jpgfile, os.path.join(options.save_dir, list_name[i]), options.agu_num)
def main_args():
parser = argparse.ArgumentParser()
parser.add_argument('--src_images_dir', type=str, default='../source_images/', help="需要被增强训练集的源图片路径")
parser.add_argument("--agu_num", type=int, default=19, help='每张训练图片需要被增强的数量,这里设置为19,加上本身的1张,每张图片共计变成20张')
parser.add_argument("--save_dir", type=str, default='../dataAug', help='增强数据的保存位置')
options = parser.parse_args()
return options
if __name__ == "__main__":
options = main_args()
handle_muti_aug(options)
The data augmentation progress is shown in the figure.

The data set is expanded to 20 times the original size, as shown in the figure.

Other related blogs
Project source code download
For details, please see my blog resource download page
Download other information
If you want to continue to understand the learning routes and knowledge systems related to artificial intelligence, you are welcome to read my other blog " Heavy | Complete Artificial Intelligence AI Learning - Basics Knowledge learning route, all materials can be downloaded directly from the network disk without following any routines》
This blog refers to Github’s well-known open source platform, AI technology platform and experts in related fields : Datawhale, ApacheCN, AI Youdao and Dr. Huang Haiguang have about 100G of related information. I hope it can help all my friends.