What are synchronous IO and asynchronous IO, blocking IO and non-blocking IO, and what are the differences?
In fact, different people may give different answers to this question. For example, Wiki believes that asynchronous IO and non-blocking IO are the same thing. This is actually because different people have different knowledge backgrounds, and the context when discussing this issue is also different. Therefore, in order to better answer this question, let me first limit the context of this article.
The background of this article's discussion is network IO in the Linux environment.
The most important reference for this article is Richard Stevens' "UNIX® Network Programming Volume 1, Third Edition: The Sockets Networking", Section 6.2 "I/O Models", in which Stevens explains in detail the characteristics and differences of various IOs , if your English is good enough, it is recommended to read it directly.
Stevens' writing style is famous for explaining things in simple terms, so don't worry about not being able to understand. The flow chart in this article is also taken from the reference.
Stevens compared a total of five IO Models in the article:
blocking IO nonblocking IO IO multiplexing signal driven IO asynchronous IO
Since signal driven IO is not commonly used in practice, I only mention the remaining four IO Models.
Let’s talk about the objects and steps involved when IO occurs.
For a network IO (here we take read as an example), it involves two system objects, one is the process (or thread) that calls this IO, and the other is the system kernel (kernel). When a read operation occurs, it goes through two stages:
Waiting for the data to be ready Copying the data from the kernel to the process
It is important to remember these two points, because the difference between these IO Models is that they have different situations in the two stages.
blocking IO
In Linux, all sockets are blocked by default. A typical read operation process is probably like this:
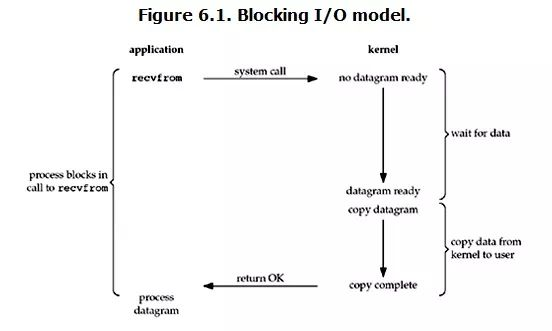
When the user process calls the recvfrom system call, the kernel begins the first phase of IO: preparing data.
For network io, many times the data has not arrived at the beginning (for example, a complete UDP packet has not been received). At this time, the kernel has to wait for enough data to arrive. On the user process side, the entire process will be blocked.
When the kernel waits until the data is ready, it copies the data from the kernel to the user memory, and then the kernel returns the result, and the user process unblocks the state and starts running again.
Therefore, the characteristic of blocking IO is that it is blocked in both stages of IO execution.
non-blocking IO
Under Linux, you can set the socket to make it non-blocking. When performing a read operation on a non-blocking socket, the process looks like this:
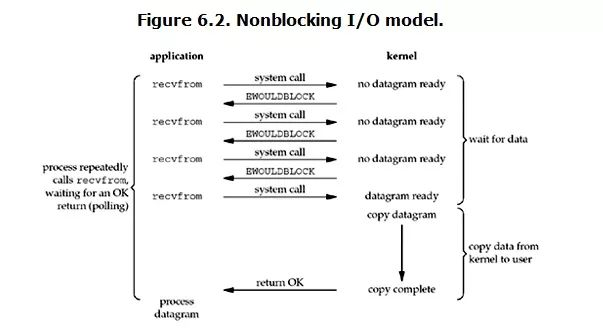
As can be seen from the figure, when the user process issues a read operation, if the data in the kernel is not ready yet, it will not block the user process, but will immediately return an error. From the perspective of the user process, after it initiates a read operation, it does not need to wait, but gets a result immediately.
When the user process determines that the result is an error, it knows that the data is not ready yet, so it can send the read operation again. Once the data in the kernel is ready and the system call from the user process is received again, it immediately copies the data to the user memory and then returns.
Therefore, the user process actually needs to constantly actively ask whether the kernel data is ready.
IO multiplexing
IO multiplexing这个词可能有点陌生,但是如果我说select,epoll,大概就都能明白了。有些地方也称这种IO方式为event driven IO。我们都知道,select/epoll的好处就在于单个process就可以同时处理多个网络连接的IO。
它的基本原理就是select/epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。它的流程如图:
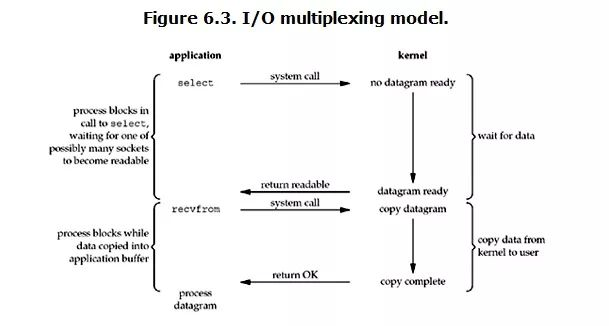
当用户进程调用了select,那么整个进程会被block,而同时,kernel会“监视”所有select负责的socket,当任何一个socket中的数据准备好了,select就会返回。这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。
这个图和blocking IO的图其实并没有太大的不同,事实上,还更差一些。因为这里需要使用两个system call (select 和 recvfrom),而blocking IO只调用了一个system call (recvfrom)。但是,用select的优势在于它可以同时处理多个connection。
多说一句。所以,如果处理的连接数不是很高的话,使用select/epoll的web server不一定比使用multi-threading + blocking IO的web server性能更好,可能延迟还更大。select/epoll的优势并不是对于单个连接能处理得更快,而是在于能处理更多的连接。
在IO multiplexing Model中,实际中,对于每一个socket,一般都设置成为non-blocking,但是,如上图所示,整个用户的process其实是一直被block的。只不过process是被select这个函数block,而不是被socket IO给block。
Asynchronous I/O
linux下的asynchronous IO其实用得很少。先看一下它的流程:
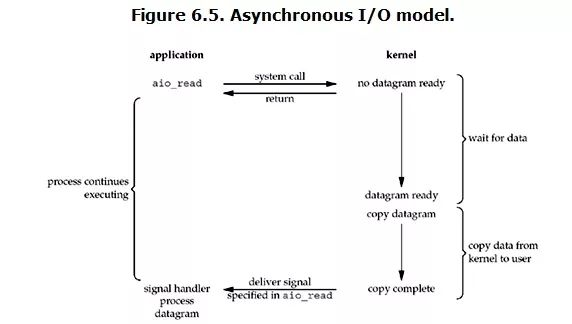
用户进程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从kernel的角度,当它受到一个asynchronous read之后,首先它会立刻返回,所以不会对用户进程产生任何block。
然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了。
到目前为止,已经将四个IO Model都介绍完了。现在回过头来回答最初的那几个问题:blocking和non-blocking的区别在哪,synchronous IO和asynchronous IO的区别在哪。
先回答最简单的这个:blocking vs non-blocking。前面的介绍中其实已经很明确的说明了这两者的区别。调用blocking IO会一直block住对应的进程直到操作完成,而non-blocking IO在kernel还准备数据的情况下会立刻返回。
在说明synchronous IO和asynchronous IO的区别之前,需要先给出两者的定义。Stevens给出的定义(其实是POSIX的定义)是这样子的:
A synchronous I/O operation causes the requesting process to be blocked until that I/O operation completes; An asynchronous I/O operation does not cause the requesting process to be blocked;
两者的区别就在于synchronous IO做”IO operation”的时候会将process阻塞。按照这个定义,之前所述的blocking IO,non-blocking IO,IO multiplexing都属于synchronous IO。
有人可能会说,non-blocking IO并没有被block啊。这里有个非常“狡猾”的地方,定义中所指的”IO operation”是指真实的IO操作,就是例子中的recvfrom这个system call。non-blocking IO在执行recvfrom这个system call的时候,如果kernel的数据没有准备好,这时候不会block进程。
但是,当kernel中数据准备好的时候,recvfrom会将数据从kernel拷贝到用户内存中,这个时候进程是被block了,在这段时间内,进程是被block的。而asynchronous IO则不一样,当进程发起IO 操作之后,就直接返回再也不理睬了,直到kernel发送一个信号,告诉进程说IO完成。在这整个过程中,进程完全没有被block。
各个IO Model的比较如图所示:

经过上面的介绍,会发现non-blocking IO和asynchronous IO的区别还是很明显的。在non-blocking IO中,虽然进程大部分时间都不会被block,但是它仍然要求进程去主动的check,并且当数据准备完成以后,也需要进程主动的再次调用recvfrom来将数据拷贝到用户内存。
而asynchronous IO则完全不同。它就像是用户进程将整个IO操作交给了他人(kernel)完成,然后他人做完后发信号通知。在此期间,用户进程不需要去检查IO操作的状态,也不需要主动的去拷贝数据。
最后,再举几个不是很恰当的例子来说明这四个IO Model:
有A,B,C,D四个人在钓鱼:
A用的是最老式的鱼竿,所以呢,得一直守着,等到鱼上钩了再拉杆; B的鱼竿有个功能,能够显示是否有鱼上钩,所以呢,B就和旁边的MM聊天,隔会再看看有没有鱼上钩,有的话就迅速拉杆; C用的鱼竿和B差不多,但他想了一个好办法,就是同时放好几根鱼竿,然后守在旁边,一旦有显示说鱼上钩了,它就将对应的鱼竿拉起来; D是个有钱人,干脆雇了一个人帮他钓鱼,一旦那个人把鱼钓上来了,就给D发个短信。
出处:https://dwz.cn/gg7wFJTh
本文由 mdnice 多平台发布