# Preface
With the continuous development of artificial intelligence technology, especially the widespread application of deep learning technology, multi-modal data processing and large model training have become one of the current research hotspots. These technologies have also brought great benefits to the field of intelligent processing and analysis of document images. New development opportunities.
Recently, the 12th China Intelligent Industry Summit Forum 2023 (CIIS2023) opened in Nanchang, Jiangxi. Scholars and experts from all walks of life in government, enterprise, and research shared the stage to jointly promote intelligent technology to lead industry innovation and change in the sharing of results, collision of opinions, and mutual learning of experiences. , drive the rapid development of the digital economy.

Multimodal large model and document image processing
Multimodal large models refer to deep learning models that can process multiple input modal data (such as text, images, speech, etc.).
Traditional deep learning models usually can only process data of a single modality, such as text data or image data. But in the real world, we often encounter data in multiple modalities, such as a news report containing text and images, or a video containing images and speech. In order to better handle these multi-modal data, multi-modal large models emerged.
From ancient times to the present, documents have been one of the most common and important information carriers. How to extract useful information from document images and accurately understand and effectively apply it is a very difficult challenge that requires a lot of energy. Manpower and time.
The comprehensive use of multi-modal data to train large models can greatly improve the efficiency and accuracy of document image processing and analysis, thereby promoting the digital transformation and intelligent upgrade of related industries.
At the conference, Ding Kai, deputy general manager of Hehe Information Intelligent Technology Platform Division, gave an introduction and sharing at the multi-modal large model and document image intelligent understanding forum.
Document Image Technology Difficulties
Technical difficulties in document image analysis, recognition and understanding mainly include the following aspects:
- Diverse scenes and formats: Document images may come from different scenes and formats, such as newspapers, books, handwritten notes, etc. Each scene and format has different characteristics and challenges, requiring algorithms to adapt to different scenes and formats.
- Collection device uncertainty: Document images may be acquired through different collection devices, such as scanners, mobile phone cameras, etc. The imaging quality and parameters of different devices are different, resulting in differences in image quality and features. The algorithm needs to be robust and able to handle Images collected by different devices.
- Diversity of user needs: Users have different needs for document images. Some users may only need to extract text information, while some users may need to perform structured understanding and analysis. The algorithm needs to be able to meet the needs of different users.
- Severe degradation of document image quality: Due to the aging, damage or storage conditions of the document, the quality of the document image may be severely degraded, such as blur, noise, uneven lighting, etc., which will bring problems to tasks such as text detection and character recognition. difficulty.
- Difficulty in text detection and layout analysis: The text in the document image may have different fonts, sizes, colors, etc., and the text may be similar to the background color, making text detection and layout analysis difficult. The algorithm needs to have efficient and accurate text detection. and layout analysis capabilities.
- The recognition rate of unqualified text is low: Under unqualified conditions, the text in the document image may be distorted, deformed, blocked, etc., which will cause the accuracy of the traditional text recognition algorithm to decrease, and the algorithm needs to be able to detect unqualified conditions. The ability to accurately recognize text.
- Poor ability to understand structured intelligence: The information in document images is not just text, but also structured information such as tables, charts, and images. The algorithm needs to have the ability to understand structured intelligence and be able to extract and extract the structured information in the document. Analyze and understand.

Based on these problems, Hehe Information divided the research topic of intelligent document processing into the following six modules:
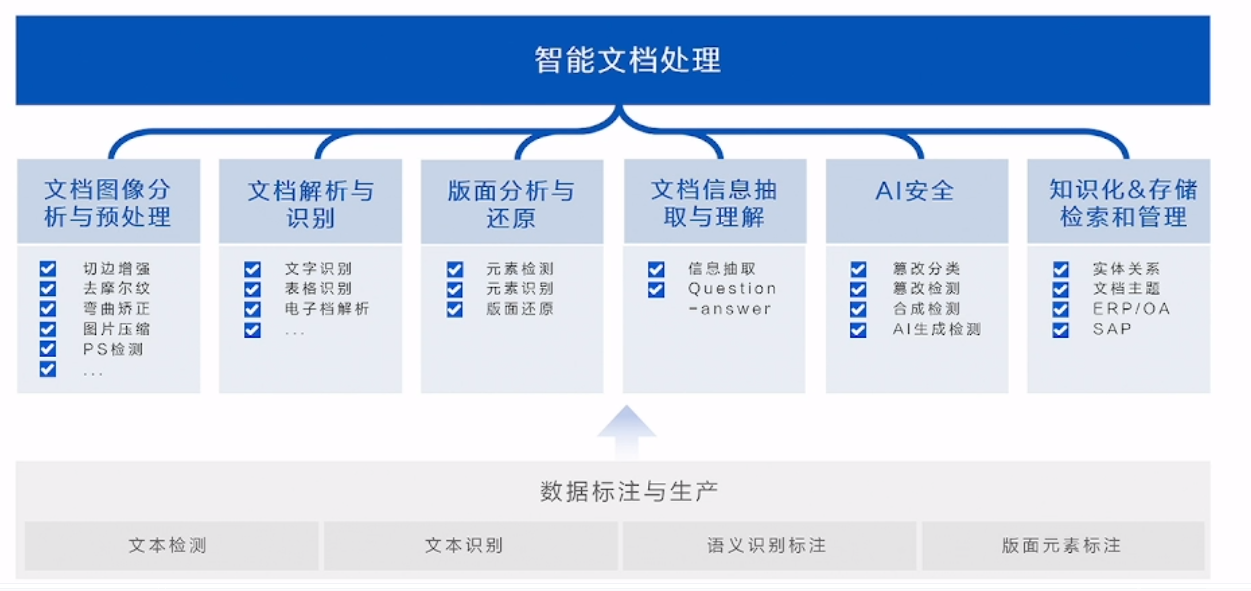
Hehe Information realizes the entire process of intelligent document processing through image analysis, document analysis, layout analysis, information extraction, security assurance and knowledge management, and provides efficient, accurate and safe document processing services.
- Document image analysis and preprocessing: Use image processing technology to analyze and preprocess document images, remove noise, adjust image brightness and contrast, etc., to improve the accuracy and effect of subsequent processing.
- Document parsing and recognition: After image preprocessing, optical character recognition (OCR) technology is used to parse and identify the document, and the text in the image is converted into an editable and searchable text format for subsequent processing and analysis.
- Layout analysis and restoration: Perform layout analysis to identify elements such as titles, paragraphs, tables, images, etc. in the document, and restore the original layout structure of the document to facilitate subsequent information extraction and understanding.
- Document information extraction and understanding: Use natural language processing (NLP) and machine learning technology to extract and understand key information in documents to obtain key information needed for actual business scenarios.
- AI security: Check document images for traces of tampering, synthesis, and generation to ensure document image security.
- Knowledgeization & Storage, Retrieval and Management: The processed document information is transformed into knowledge to facilitate subsequent storage, retrieval and management, so that users can quickly find the required documents or information.
Hehe information document image proprietary large model
Hehe Information's document image-specific large model is a large language model developed based on deep learning technology and is specially used to process document image-related tasks.
This model is based on a deep neural network structure, has been trained and optimized with massive data, and has powerful document image processing capabilities. It can identify and extract text, tables, graphics and other information in documents to achieve automated document parsing and understanding. It has a wide range of applications in many fields, such as finance, law, medical, etc. It can help companies and individuals automate document processing, improve work efficiency, and reduce labor costs.
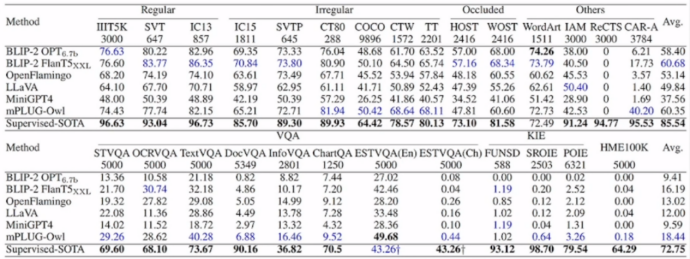
Currently, limited by the resolution of the visual encoder and training data, existing large multi-modal models handle salient text well, but handle fine-grained text poorly:
To this end, Hehe Information conducted in-depth discussions with South China University of Technology:

First, data of different modalities have different characteristics and expression methods. How to effectively integrate and interact them is a key issue. Secondly, large multi-modal models need to process more complex and massive data, which places higher demands on computing resources and model design. In addition, labeling and training multi-modal data is also a challenge, because the correlation and alignment between different modalities require more sophisticated processing.
Researchers believe that various tasks of document image recognition and analysis can be defined as sequence predictions (text, paragraph, layout analysis, tables, formulas, etc.), and then different prompts are used to guide the model to complete different OCR tasks and support chapters. Level document image recognition and analysis, output Markdown/HTML/Text and other standard formats, and finally leave the work related to document understanding to LLM.
In general, the document image large model mainly includes the following functions:
Text recognition and extraction: It can accurately identify text in document images and extract text content. Whether printed or handwritten, multiple languages can be recognized.
Document structure analysis: It can intelligently analyze the structure of the document and identify different structural elements such as titles, paragraphs, lists, tables, etc. to help users better understand the organizational structure of the document.
Table parsing and extraction: It can automatically identify and parse the table structure in the document, extract the data in the table, and convert it into a structured data form to facilitate subsequent data processing and analysis.
Key information extraction: Key information can be extracted from documents, such as date, amount, company name, etc., helping users quickly obtain important content in the document.
Document classification and retrieval: Documents can be classified and indexed based on their content and characteristics, making it easier for users to manage and retrieve documents and improve work efficiency.
R&D process
Taking the SPTS document image large model proposed in 2022 as an example,
For scene text, end-to-end detection and recognition is defined as a picture-to-sequence prediction task. Single-point annotation is used to indicate the text position, which greatly reduces the annotation cost and eliminates the need for Rol sampling and complex post-processing operations. It truly integrates detection and recognition. One body.

Subsequently, in the research of SPTS v2, enterprises and universities focused on the issue of speed optimization.
Still targeting scene text, detection and recognition are decoupled into autoregressive single-point detection and parallel text recognition. IAD autoregressively obtains the single point coordinates of each text based on the visual encoder features. PRD obtains the recognition results of each text in parallel based on the single point features of IAD.
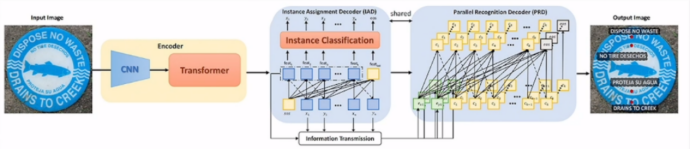
After several rounds of iterations , the SPTS-based OCR unified model (SPTS v3) has successfully expanded the input from scene text to tables, formulas, chapter documents, etc.
Multiple OCR tasks are defined as sequence predictions, and different prompts are used to guide the model to complete different OCR tasks. The model follows the picture-to-sequence structure of SPTS's CNN+TransformerEncoder+Transformer Decoder.

SPTS v3 currently focuses on the following tasks: end-to-end detection and recognition, table structure recognition, and handwritten mathematical formula recognition.

Research result


Looking to the future
As an industry-leading artificial intelligence and big data technology company, Hehe Information is deeply involved in the fields of intelligent text recognition, image processing, natural language processing and big data mining. The intelligent image processing engine it develops provides a variety of image intelligent processing black technologies, such as Image edge enhancement, PS tampering detection, and image correction have all been implemented and served in various industries.
In the future, Hehe Information will continue to work in the direction of document image processing, allowing new technologies to be applied in multiple scenarios.
The research results of Hehe Information are of great significance in the intelligent industry. At the same time, the exploration of these results and issues will also provide new ideas and directions for the development of the intelligent industry.