Table of contents
In which file is MySQL data stored?
What is the structure of the table space file?
What are the InnoDB row formats?
What does the COMPACT line format look like?
Additional information recorded
1. Variable length field length list
What is the maximum value of n in varchar(n)?
How does MySQL handle row overflow?
In which file is MySQL data stored?
The storage behavior of MySQL is implemented by the storage engine. MySQL supports multiple storage engines, and different storage engines save different files .
InnoDB is our commonly used storage engine and the default storage engine of MySQL . Therefore, this article mainly focuses on the InnoDB storage engine.
Query the directory where the files of the MySQL database are stored:
mysql> SHOW VARIABLES LIKE 'datadir';
+---------------+-----------------+
| Variable_name | Value |
+---------------+-----------------+
| datadir | /var/lib/mysql/ |
+---------------+-----------------+
1 row in set (0.00 sec)Every time we create a database (database), we will create a directory named database in the datadir directory, and then the files that save the table structure and table data will be stored in this directory.
For example, there is a database named my_test, and there is a database table named t_order in the database.

Then, we enter the /var/lib/mysql/my_test directory and see what files are there?
[root@xiaolin ~]#ls /var/lib/mysql/my_test
db.opt
t_order.frm
t_order.ibdAs you can see, there are three public files, which represent:
- db.opt, used to store the default character set and character verification rules of the current database
- t_order.frm, the table structure of t_order will be saved in this file. Creating a table in MySQL will generate a .frm file . This file is used to save the metadata information of each table and mainly contains table structure definitions .
- t_order.ibd, the table data of t_order will be saved in this file. Table data can be stored in a shared table space file (file name: ibdata1) or in an exclusive table space file (file name: table name.ibd). This behavior is controlled by the parameter innodb_file_per_table. If the parameter innodb_file_per_table is set to 1, the stored data, indexes and other information will be stored separately in an exclusive table space. Starting from MySQL version 5.6.6, its default value is 1 . , so from this version onwards, the data of each table in MySQL is stored in a separate .ibd file .
Summary: Every time a table is created , three files, .opt , .frm , and .ibd , are generated . .opt stores the character set and character verification rules; .frm stores the table structure definition; .ibd stores the data of each table.
What is the structure of the table space file?
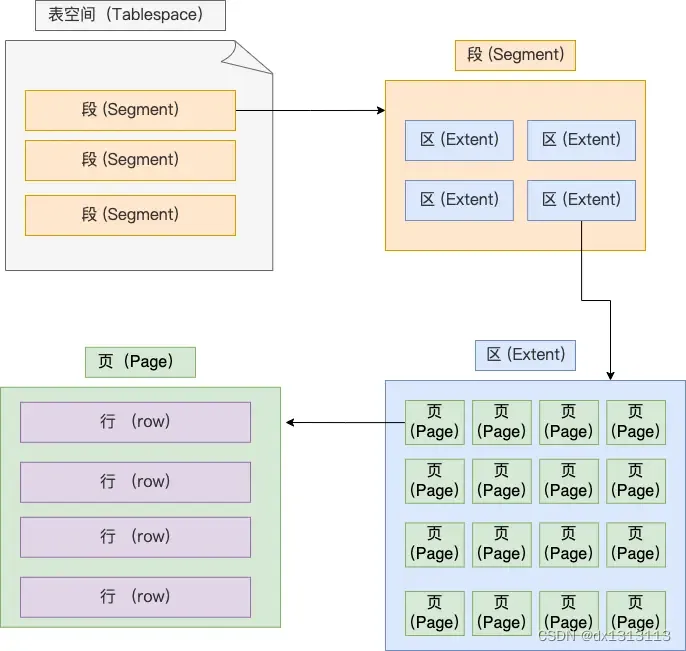
The table space is composed of segments, extents, pages, and rows. The logical structure of the InnoDB storage engine is roughly as shown below:
1. row
Records in the data table are stored in rows, and each record has a different storage structure according to different row formats.
2. Page
Records are stored in rows, but database reads are not in units of [row], otherwise one read (that is, one I/O operation) can only process one row of data, and the efficiency will be very low.
Therefore, InnoDB data is read and written in units of [page] , that is to say, when a record needs to be read, the record is not read from the disk, but the entire record is read in in units of pages. Memory.
The default size of each page is 16 KB , which means that a maximum of 16 KB of continuous storage space can be guaranteed.
Page is the smallest unit of disk management of the InnoDB storage engine , which means that each read and write of the database is in units of 16KB. At least 16K content is read from the disk to the memory at a time, and at least 16K content in the memory is refreshed at a time. to disk.
There are many types of pages, common ones include data pages, undo log pages, overflow pages, etc. The pages in the data table are managed using [Data Page].
3. Extent
The InnoDB storage engine uses B+ trees to organize data.
Each level in the B+ tree is connected through a doubly linked list. If storage space is allocated in units of pages, the physical locations between two adjacent pages in the linked list are not continuous and may be very far apart. , then there will be a lot of random I/O during disk query, and random I/O is very slow.
Solving this problem is also very simple, that is, making the physical locations of adjacent pages in the linked list also adjacent, so that sequential I/O can be used, and the performance will be very high when performing range queries (scanning leaf nodes).
Solution:
When the amount of data in the table is large, when allocating space for an index, it is no longer allocated in units of pages, but in units of extents. The size of each area is 1MB. For a 16KB page, 64 consecutive pages will be divided into one area, so that the physical locations of adjacent pages in the linked list are also adjacent, and sequential I/O can be used. .
4. Segment
The table space is composed of segments, and the segments are composed of multiple extents. Segments are generally divided into data segments, index segments and rollback segments.
- Index segment: a collection of areas that store non-leaf nodes of the B+ tree
- Data segment: a collection of leaf nodes that store the B+ tree
- Rollback segment: A collection of areas that store rollback data
What are the InnoDB row formats?
Row format (row_format) is the storage structure of a record.
InnoDB provides 4 row formats, namely Redundant, Compact, Dynamic and Compressed row formats.
- Redundant is a very old row format. The row format used before MySQL 5.0 version is basically no longer used.
- Since Redundant is not a compact row format, MySQL 5.0 introduced the Compact row record storage method. Compact is a compact row format. The original intention of the design is to allow more row records to be stored in one data page . After MySQL 5.1 version, the row format is set to Compact by default.
- Dynamic and Compressed are both compact line formats, and their line formats are similar to Compact, because they are both based on Compact with some improvements. Starting from MySQL version 5.7, the Dynamic row format is used by default .
What does the COMPACT line format look like?

As you can see, a complete record is divided into two parts: [recorded additional information] and [recorded real data].
Additional information recorded
The additional information of the record contains three parts: a variable-length field length list, a NULL value list, and record header information.
1. Variable length field length list
The difference between varchar(n) and char(n): char is fixed-length, varchar is variable-length, and the length (size) of the actual data stored in the variable-length field is not fixed.
Therefore, when storing data, the size occupied by the data must also be stored in the [Variable Field Length List]. When reading data, the corresponding length can be read based on this [Variable Field Length List]. data. Other variable-length fields such as TEXT and BLOB are also implemented in this way.
In order to show how [variable-length field length list] specifically saves [the number of bytes occupied by the real data of variable-length fields], we first create such a table, the character set is ascii (so each character occupies 1 word section), the row format is Compact, and the name and phone fields in the t_user table are both variable-length fields:
CREATE TABLE `t_user` (
`id` int(11) NOT NULL,
`name` VARCHAR(20) DEFAULT NULL,
`phone` VARCHAR(20) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB DEFAULT CHARACTER SET = ascii ROW_FORMAT = COMPACT;There are now three records in the t_user table:
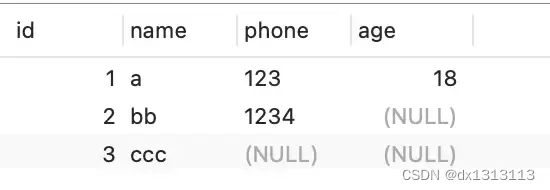
Next, let's take a look at how the [variable field length list] in the row format of these three records is stored?
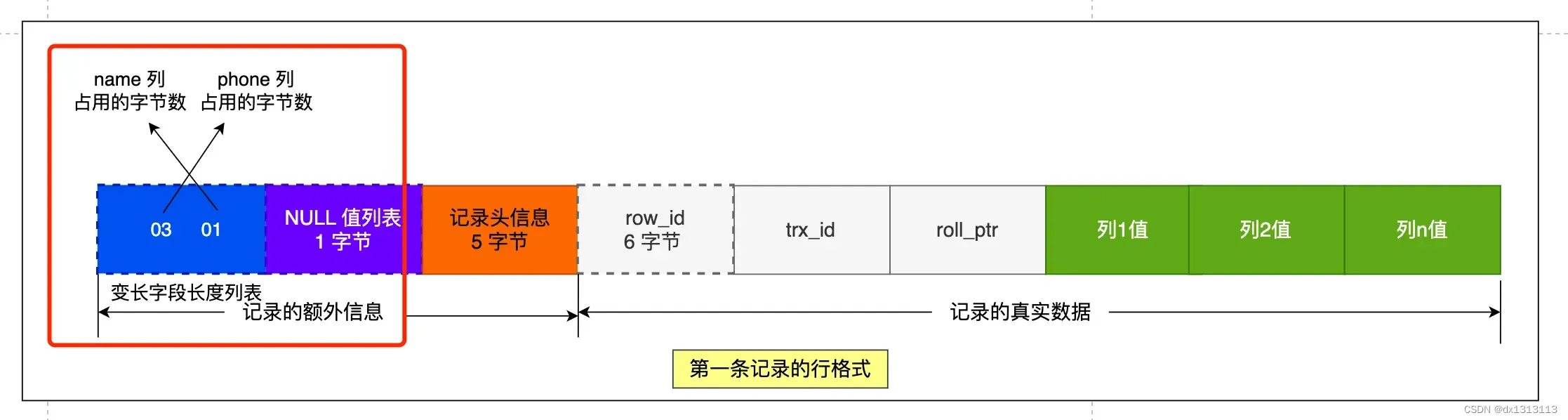
First record:
- The value of the name column is a, and the number of bytes occupied by the real data is 1 byte, hexadecimal 0x01;
- The value of the phone column is 123, and the number of bytes occupied by the real data is 3 bytes, hexadecimal 0x03;
- The age column and id column are constant-length fields, so you don’t need to worry about them here.
The number of bytes occupied by the real data of these variable-length fields will be stored in reverse column order , so the content in [Variable-length field length list] is [03 01], not [01 03].
Similarly, it can be concluded that in the row format of the second record, the content in [Variable Field Length List] is [04 02], as shown below:

The column value of phone in the third record is NULL. NULL will not be stored in the real data part recorded in the row format , so there is no need to store variable-length fields with NULL values in the [Variable field length list]. length.
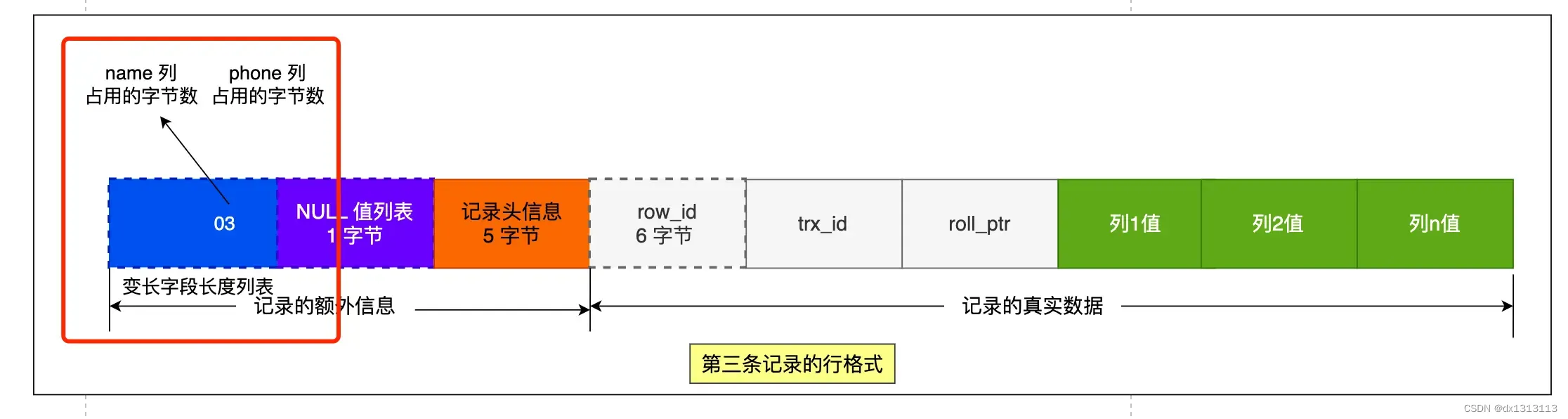
Why should the information of [Variable Field Length List] be stored in reverse order?
Mainly because the pointer to the next record in [Record Header Information] points to the position between [Record Header Information] and [Real Data] of the next record . The advantage of this is that reading to the left is the record header information. Reading to the right is the real data, which is more convenient.
The reason why the information in [Variable Field Length List] should be stored in reverse order is because this allows the real data of the records at the front and the field length information corresponding to the data to be in the same CPU Cache Line at the same time , which can improve the CPU Cache hit rate .
In the same way, the information of the NULL value list also needs to be stored in reverse order.
Does the row format of each database table have a [variable-length field byte count list]?
The variable length field byte list is not required.
When the data table does not have variable-length fields, for example, all fields are of type int, then the row format in the table will not have a [variable-length field length list], because it is unnecessary, so it is better to remove it to save space .
Therefore [variable-length field length list] only appears when there are variable-length fields in the data table.
2. NULL value list
Some columns in the table may store NULL values. It will waste space if these NULL values are placed in the real data of the record, so the Compact row format stores these columns with NULL values in a NULL value list.
If there are columns that allow NULL values, each column corresponds to a binary bit (bit) , and the binary bits are arranged in reverse order of the column .
- When the binary bit value is 1, it means that the value of the column is NULL.
- When the binary bit value is 0, it means that the value of the column is not NULL.
In addition, the value list of NULL must be represented by an integer number of bytes (8 bits per byte). If the number of binary bits used is less than an integer number of bytes, 0 will be added to the high bit of the byte.
Let’s take these three records in the t_user table as an example:

Next, look at how the list of NULL values is stored in the row format of these three records:
Let’s look at the first record first . All columns of the first record have values and there are no NULL values, so the binary representation is as follows:
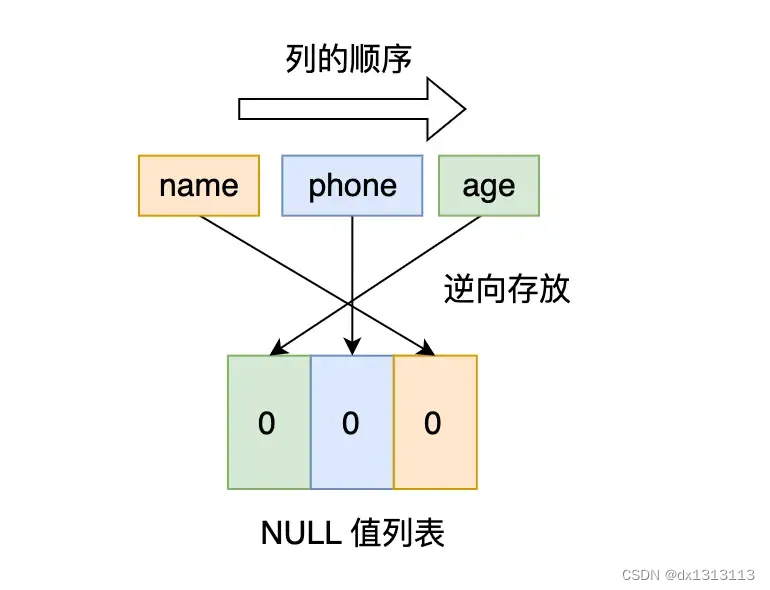
However, InnoDB uses integer bytes in binary to represent the NULL value list, which is now less than 8 bits, so 0 must be added to the high bits. The final binary representation looks like this:

Therefore, for the first piece of data, the hexadecimal representation of the NULL value list is 0x00.
Second record : The age column of the second record is a NULL value, so for the second data, the NULL value list is 0x04 in hexadecimal.
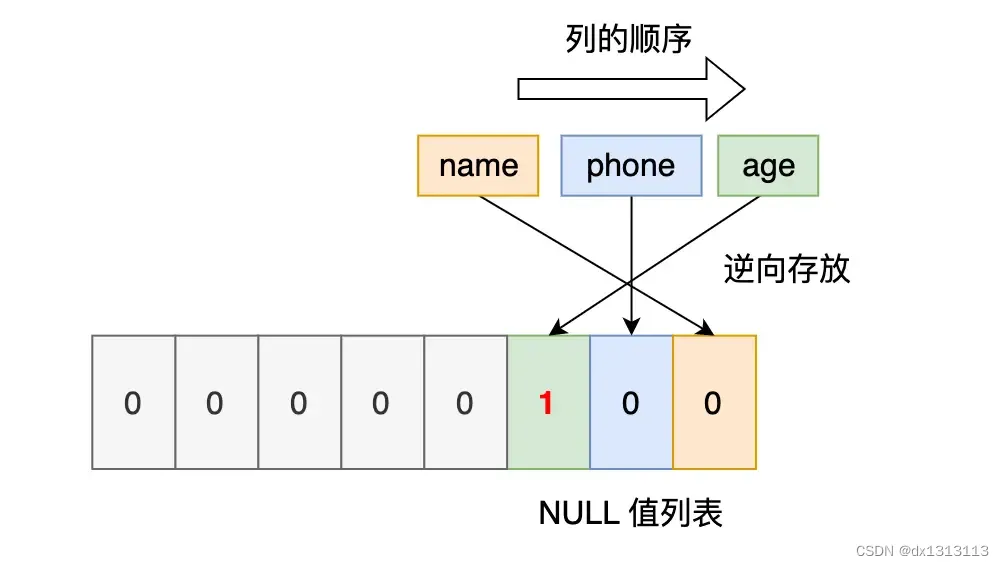
Third record: The phone column and age column of the third record are NULL values. Therefore, for the third data, the NULL value list is expressed in hexadecimal as 0x06.
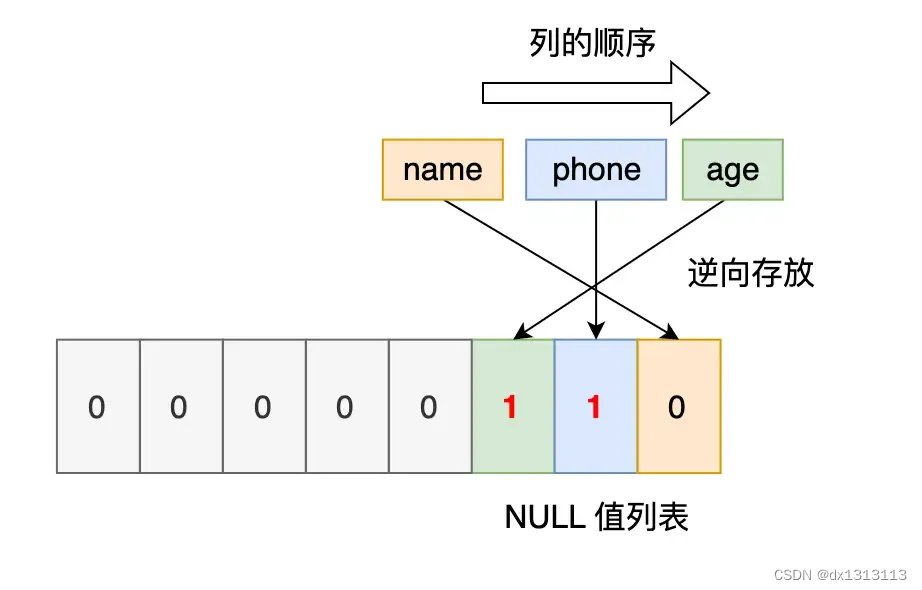
After filling in the NULL value lists of the three records, their row format is as follows:

Does every database table row format have [NULL value list]?
A list of NULL values is also not required.
When all fields in the database are defined as NOT NULL, the row format in the table will not have a NULL value list.
Therefore, when designing a database table, it is usually recommended to set the field to NOT NULL, which can save at least 1 byte of space (the NULL value list occupies at least 1 byte of space).
Is [NULL value list] fixed at 1 byte? If this is the case, nine field values in a record are all NULL. How to express this?
The space of [NULL value list] is not fixed at 1 byte.
When a record has 9 field values that are all NULL, then a [NULL value list] of 2 bytes will be created, and so on.
3. Record header information
Record header information contains a lot of content, here are a few important ones:
- delete_mask: Identifies whether this piece of data is deleted. From here we can know that when we execute delete to delete a record, we will not actually delete the record, but just mark the record's delete_mask as 1.
- next_record: The position of the next record. From here we can know that records are organized through linked lists. As mentioned before, it points to the position between the [record header information] and [real data] of the next record.
- record_type: indicates the type of the current record, 0 indicates a normal record, 1 indicates a B+ tree non-leaf node record, 2 indicates the minimum record, and 3 indicates the maximum record.
recorded real information
In addition to the fields we defined, the real data part of the record also has three hidden fields, namely row_id, trx_id, and roll_pointer.

- row_id: If the primary key or unique constraint column is specified when creating the table, then there will be no row_id hidden field. If neither the primary key nor the unique constraint is specified, InnoDB will record and add the row_id hidden field. row_id is not required and takes up 6 bytes
- trx_id: transaction id, indicating which transaction this data was generated by. trx_id is required and takes up 6 bytes.
- roll_pointer: Pointer to the previous version of this record. roll_pointer is required and takes up 7 bytes.
What is the maximum value of n in varchar(n)?
MySQL stipulates that except for large object types such as TEXT and BLOBs, the total byte length occupied by all other columns (including hidden columns and record header information) cannot exceed 65535 bytes.
In other words, except for TEXT and BLOBs type columns, a row of records is limited to a maximum of 65535 bytes . Note that the total length of a row is not one column.
PS: n in the varchar(n) field type represents the maximum number of characters stored, not the byte size .
To calculate the maximum number of bytes that varchar(n) can store, you also need to look at the character set of the database table, because the character set represents how many bytes one character occupies. For example, in the ASCII character set, one character occupies 1 byte. , then varchar(100) means that a maximum of 100 bytes of data can be stored. If it is a UTF-8 character set, a Chinese character occupies 3 bytes and an English character occupies 1 byte.
Single field case
Earlier, we learned that a row of records can only store a maximum of 65535 bytes of data.
Assume that the database table has only one column of type varchar(n) and the character set is ascii. In this case, is the maximum value of n in varchar(n) 65535?
We define a field of type varchar(65535), and the character set is ascii database table
CREATE TABLE test (
`name` VARCHAR(65535) NULL
) ENGINE = InnoDB DEFAULT CHARACTER SET = ascii ROW_FORMAT = COMPACT;See if you can successfully create a table:

As you can see, the creation failed
From the error message, we can know that the maximum number of bytes in a row of data is 65535 (excluding large object types such as TEXT and BLOBs), which includes storage overhead .
Storage overhead is actually [variable-length field length list] and [NULL value list], which means that the maximum number of bytes in a row of data is 65535, which actually includes [variable-length field length list] and [NULL value list]. Number of bytes . Therefore, when calculating the maximum value of n in varchar(n), you need to subtract the number of bytes occupied by storage overhead .
This is because when we store data with field type varchar(n), it is actually divided into three parts for storage:
- real data
- Number of bytes occupied by real data
- NULL flag, if NULL is not allowed, this part is not needed
In this example, how many bytes does [NULL value list] occupy?
When we create the table, fields are allowed to be NULL, and the number of row fields does not exceed 8, so 1 byte is used to represent [NULL value list].
In this example, how many bytes does [variable field length list] occupy?
The number of bytes occupied by [variable-length field length list] = the sum of the number of bytes occupied by all [variable-length field length].
Therefore, we need to first know how many bytes the [variable field length] of each variable-length field needs to be represented? The specific situations are divided into:
- Condition 1: If the maximum number of bytes allowed to be stored in a variable-length field is less than or equal to 255 bytes, 1 byte will be used to represent [variable-length field length]
- Condition 2: If the maximum number of bytes allowed to be stored in a variable-length field is greater than 255 bytes, 2 bytes will be used to represent [variable-length field length];
Because our case has only 1 variable-length field, the "variable-length field length list" = the number of bytes occupied by 1 "variable-length field length", which is 2 bytes .
Because when calculating the maximum value of n in varchar(n), it is necessary to subtract the number of bytes occupied by "variable field length list" and "NULL value list". Therefore, when the database table has only one varchar(n) field and the character set is ascii, the maximum value of n in varchar(n) = 65535 - 2 - 1 = 65532 .

As you can see, the creation was successful. Therefore, when calculating the maximum value of n in varchar(n), you need to subtract the number of bytes occupied by the "variable field length list" and "NULL value list" .
Of course, the above example is for the case where the character set is ascii. If UTF-8 is used, the calculation method for the maximum data that varchar(n) can store is different:
- Under the UTF-8 character set, a character requires up to 3 bytes, and the maximum value of n in varchar(n) is 65532/3 = 21844.
The above mentioned is only for the calculation method of one field.
Multiple fields
If there are multiple fields, ensure that the length of all fields + the number of bytes occupied by the variable-length field byte list + the number of bytes occupied by the NULL value list <= 65535
How does MySQL handle row overflow?
The basic unit of interaction between disk and memory in MySQL is a page. The size of a page is generally 16KB, that is 16384字节, a varchar(n) type column can store up to 100% 65532字节. Some large objects such as TEXT and BLOB may store more data. This At this time, one page may not be able to store one record. At this time, row overflow will occur, and excess data will be stored in another "overflow page" .
If a data page cannot store a record, the InnoDB storage engine will automatically store the overflow data in the "overflow page". Under normal circumstances, InnoDB data is stored in "data pages". But when a row overflow occurs, the overflow data will be stored in the "overflow page"
When a row overflow occurs, only part of the data of the column will be saved in the real data of the record, and the remaining data will be placed in the [overflow page], and then 20 bytes of the real data will be used to store the address pointing to the overflow page, thus The page where the remaining data is located can be found .
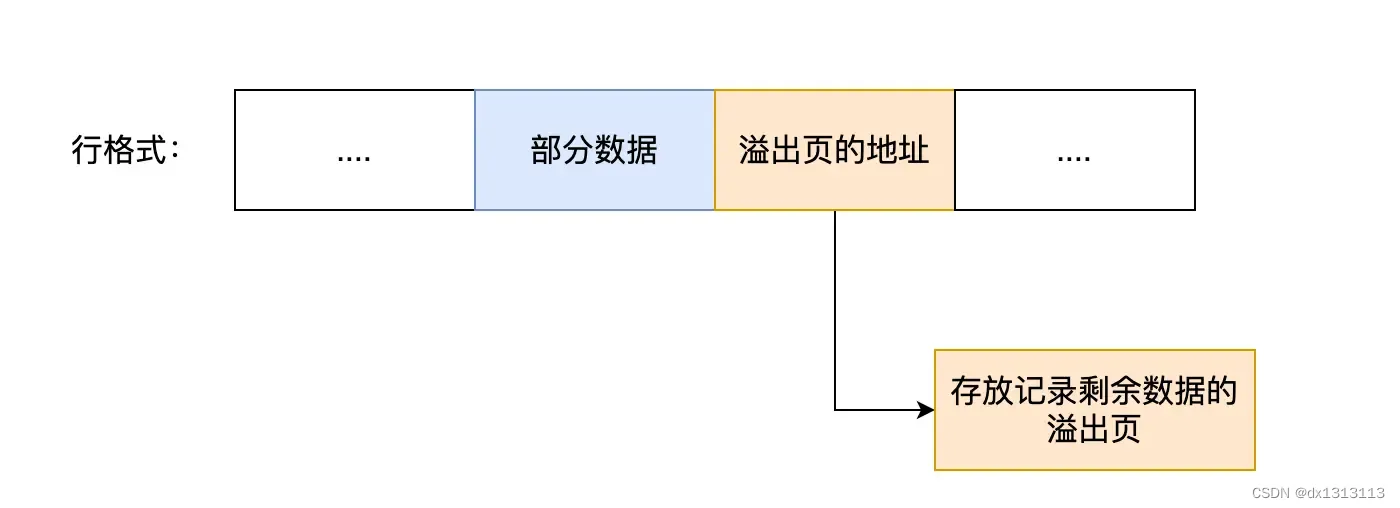
The above is the processing of Compact row format after row overflow occurs.
The two row formats, Compressed and Dynamic, are very similar to Compact. The main difference lies in the processing of row overflow data.
These two formats adopt a complete row overflow method. The real data recorded will not store part of the data of the column, but only store a 20-byte pointer to point to the overflow page. The actual data is stored in the overflow page, which looks like the following
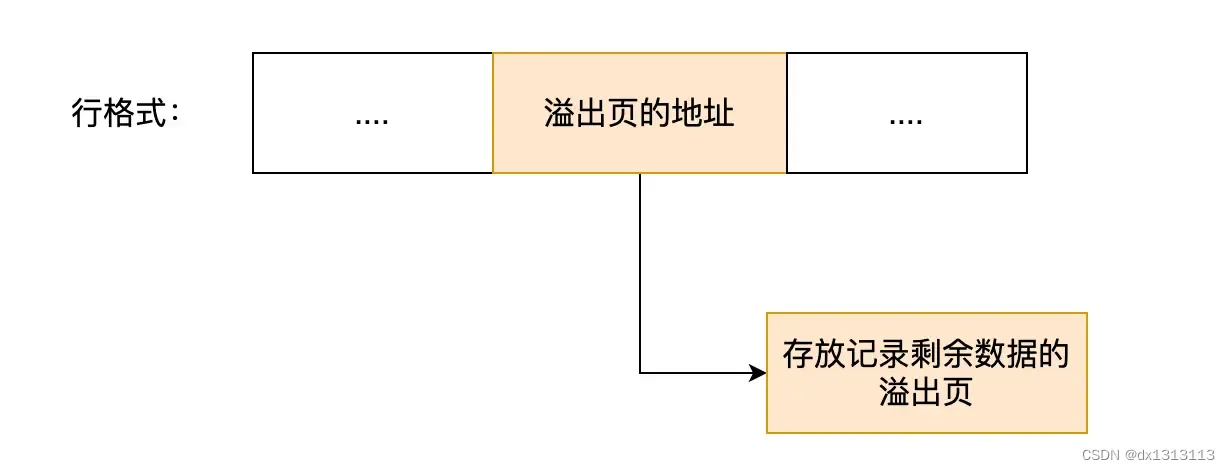
Summarize
How are NULL values stored in MySQL?
In MySQL's Compact row format, [NULL value list] is used to mark columns with NULL values. NULL values are not stored in the actual data part of the row format.
The NULL value list will occupy 1 byte of space. When all fields in the table are defined as NOT NULL, there will be no NULL value list in the row format, which can save 1 byte of space.
How does MySQL know the actual data size occupied by varchar(n)?
In MySQL's Compact row format, [variable-length field length list] is used to store the actual data size occupied by variable-length fields.
What is the maximum value of n in varchar(n)?
A row of records can store up to 65535 bytes of data, but this includes "the number of bytes occupied by the variable-length field byte list" and "the number of bytes occupied by the NULL value list". Therefore, when we calculate the maximum value of n in varchar(n), we need to subtract the number of bytes occupied by these two lists.
If a table has only one varchar(n) field and NULL is allowed, the character set is ascii. The maximum value of n in varchar(n) is 65535 (maximum row storage) - 2 (variable field length list) - 1 (NULL value list) = 65532.
If there are multiple fields, ensure that the length of all fields + the number of bytes occupied by the variable-length field byte list + the number of bytes occupied by the NULL value list <= 65535.
ps: When calculating, you need to consider three parts: character set, NULL value list and variable-length field list.
How does MySQL handle row overflow?
If a data page cannot store a record, the InnoDB storage engine will automatically store the overflow data in the [overflow page]
Compact row format: When a row overflow occurs, only part of the data of the column will , and the remaining data will be placed in the "overflow page" , and then the real data will be stored with 20 bytes pointing to the overflow page. address so that the page where the remaining data is located can be found.
The two formats, Compressed and Dynamic, adopt a complete row overflow method. The real data recorded will not store part of the data of the column , but only store a 20-byte pointer to point to the overflow page . The actual data is stored in overflow pages .