Annuaire d'articles
- 1. Introduction au C++11
- 2. Initialisation de la liste unifiée
- 3. Déclaration
- 4. Références Rvalue et sémantique de déplacement
-
- 4.1 Références Lvalue et références rvalue
- 4.2 Comparaison des références lvalue et des références rvalue
- 4.3 Scénarios d'utilisation et significations des références rvalue
- 4.4 La référence Rvalue fait référence à lvalue et à une analyse plus approfondie des scénarios d'utilisation
- 4.5 Transmission parfaite
- 5 nouvelles fonctions de classe
- 6. Modèles variés
- 7. expression lambda
- 8. Emballage
- 9. Bibliothèque de fils de discussion
1. Introduction au C++11
C++11 est une version mise à jour majeure du langage C++. Elle a été publiée en 2011. Elle contient de nouvelles fonctionnalités très utiles, offrant aux développeurs de meilleurs outils de programmation et une meilleure expérience de programmation, rendant l'écriture efficace et fiable. est plus facile.
Certaines des nouvelles fonctionnalités de C++11 incluent :
- Les énumérations de types forcés rendent le comportement habituel des types énumérés plus fiable et plus facile à contrôler.
- L'inférence de type automatique (auto) peut déduire automatiquement des types de variables en fonction des conditions réelles, rendant le code plus concis et plus facile à lire.
- Les expressions Lambda, qui prennent en charge les fonctions anonymes, offrent un moyen simple et puissant de définir et d'utiliser des objets fonction.
- La déduction globale des types de fonctions peut déduire automatiquement les types de retour de fonction pour éviter les définitions répétées.
- Les références Rvalue peuvent améliorer les performances et l'efficacité du programme, tout en implémentant mieux certaines techniques de programmation avancées, telles que la sémantique des déplacements.
- Bibliothèque de concurrence conçue pour rendre l'écriture de programmes multithread plus facile et plus sûre.
En outre, C++11 introduit également de nombreuses autres nouvelles fonctionnalités, telles que des pointeurs intelligents, des fonctions de suppression par défaut, des opérateurs de conversion explicites et des itérateurs d'intervalle.
De C++0x à C++11, le standard C++ évolue depuis 10 ans, et le deuxième véritable standard est arrivé tardivement. Par rapport à C++98/03, C++11 a apporté un nombre considérable de changements, dont environ 140 nouvelles fonctionnalités et corrections d'environ 600 défauts dans la norme C++03, ce qui fait que C++11 ressemble davantage à un nouveau langage né de C++98/03. En comparaison, C++11 peut être mieux utilisé pour le développement de systèmes et de bibliothèques, la syntaxe est plus générale et simplifiée, plus stable et sécurisée, non seulement la fonction est plus puissante, mais peut également améliorer l'efficacité de développement des programmeurs. En fait, l'entreprise est également fréquemment utilisée dans le développement de projets, nous devrions donc l'étudier en priorité .
Dans l'ensemble, C++11 est une énorme amélioration du langage C++, nous fournissant de meilleurs outils de programmation et des méthodes d'écriture de code plus efficaces, plus lisibles et plus maintenables. Par conséquent, l'apprentissage de C++11 est un avantage tout au long de la vie.
Documentation officielle C++11
histoire courte:
1998 a été la première année de création du Comité des normes C++. Il était initialement prévu de mettre à jour la norme tous les cinq ans en fonction des besoins réels. Lorsque le Comité international des normes C++ étudiait la prochaine version de C++03, il avait initialement prévu de publiez-le en 2007, donc initialement cette norme s'appelle C++07. Mais en 2006, les responsables pensaient que C++07 ne serait certainement pas achevé en 2007, et les responsables estimaient qu'il ne le serait peut-être pas en 2008. En fin de compte, cela s’appelait simplement C++ 0x. x signifie que je ne sais pas si cela sera terminé en 2007, 2008 ou 2009. En conséquence, il n’a pas été achevé en 2010 et la norme C++ a finalement été achevée en 2011. Il a donc finalement été nommé C++11. (Java est vraiment diligent à cet égard)
2. Initialisation de la liste unifiée
2.1 {}Initialisation
En C++98, la norme autorise l'utilisation d'accolades {} pour l'initialisation de liste uniforme d'éléments de tableau ou de structure. Par exemple:
struct Point { int _x; int _y; }; int main() { int array1[] = { 1, 2, 3, 4, 5 }; int array2[5] = { 0 }; Point p = { 1, 2 }; return 0; }C++11 étend le champ d'utilisation de la liste entre accolades (liste d'initialisation), afin qu'elle puisse être utilisée pour tous les types intégrés et les types définis par l'utilisateur. Lorsque vous utilisez la liste d'initialisation, vous pouvez ajouter un égal signe (=), ou Ne pas ajouter .
struct Point { int _x; int _y; }; int main() { int x1 = 1; int x2{ 2 }; int array1[]{ 1, 2, 3, 4, 5 }; int array2[5]{ 0 }; Point p{ 1, 2 }; // C++11中列表初始化也可以适用于new表达式中 int* pa = new int[4]{ 0 }; return 0; }Bien entendu, lors de la création d'un objet, vous pouvez également utiliser l'initialisation de liste pour appeler l'initialisation du constructeur.
class Date { public: Date(int year, int month, int day) :_year(year) , _month(month) , _day(day) { cout << "Date(int year, int month, int day)" << endl; } private: int _year; int _month; int _day; }; int main() { Date d1(2022, 1, 1); // C++11支持的列表初始化,这里会调用构造函数初始化 Date d2{ 2022, 1, 2 }; Date d3 = { 2022, 1, 3 }; return 0; }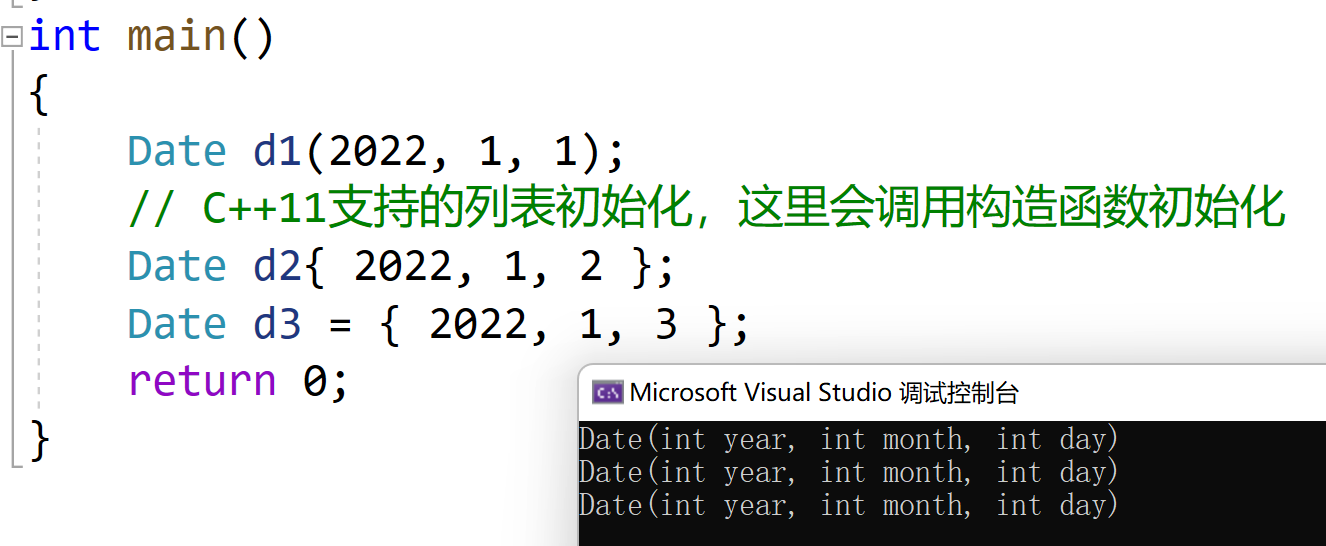
2.2 std :: initializer_list
Documentation d'introduction pour std :: initializer_list
De quel type est std::initializer_list :
int main() { auto il = { 1,3,2,5 }; cout << typeid(il).name() << endl;//class std::initializer_list<int> return 0; }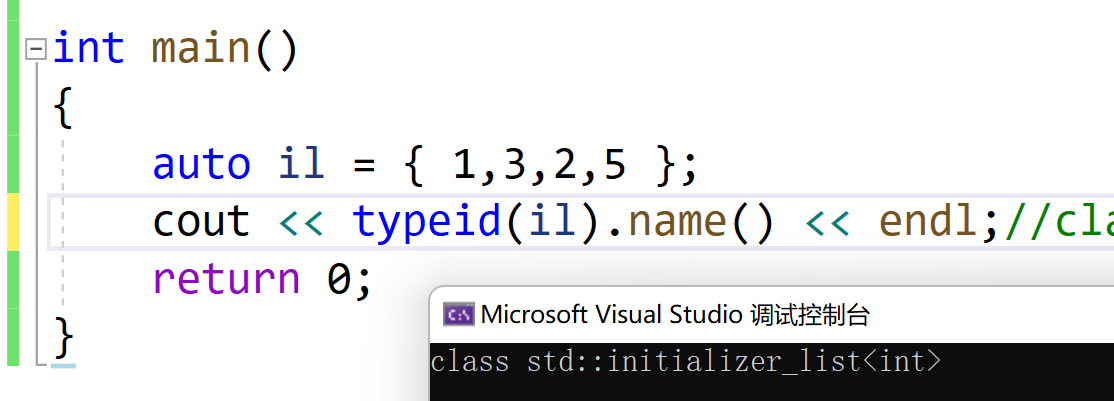
Scénarios d'utilisation de std::initializer_list :
std::initializer_list est généralement utilisé comme paramètre du constructeur. C++11 ajoute std::initializer_list comme paramètre constructeur pour de nombreux conteneurs en STL, afin qu'il soit plus pratique d'initialiser l'objet conteneur. Il peut également être utilisé comme paramètre de l'opérateur =, afin que les valeurs puissent être attribuées à l'aide d'accolades.
Ce qui suit est une introduction à la documentation des constructeurs de certains conteneurs. La plupart d'entre eux prennent en charge la construction std::initializer_list.
Ce sera très pratique pour les conteneurs de cartes
Par exemple:
int main() { vector<int> v = { 1,2,3,4 }; list<int> lt = { 1,2 }; // 这里{"sort", "排序"}会先初始化构造一个pair对象 map<string, string> dict = { { "sort", "排序"}, { "insert", "插入"} }; // 使用大括号对容器赋值 v = { 10, 20, 30 }; return 0; }Laissez le vecteur simulé prendre également en charge l'initialisation et l'affectation {}
vector(std::initializer_list<T> il) :_start(nullptr) , _finish(nullptr) , _end_of_storage(nullptr) { for (const auto& e : il) { push_back(e); } }
3. Déclaration
C++11 propose plusieurs façons de simplifier les déclarations, notamment lors de l'utilisation de modèles.
3.1 automatique
En C++98, auto est un spécificateur de type de stockage, indiquant que la variable est un type de stockage automatique local, mais les variables locales définies dans le champ local sont par défaut le type de stockage automatique, donc auto a peu de valeur. L'utilisation originale de auto est abandonnée en C++11 et utilisée pour implémenter le jugement de type automatique. Cela nécessite une initialisation explicite, permettant au compilateur de définir le type de l'objet défini sur le type de la valeur initialisée .
int main() { int i = 10; auto p = &i;// 推导为int*类型 auto pf = "apple";//推导为const char* 类型 cout << typeid(p).name() << endl; cout << typeid(pf).name() << endl; map<string, string> dict = { { "apple", "苹果"}, { "banana", "香蕉"} }; //map<string, string>::iterator it = dict.begin(); auto it = dict.begin(); return 0; }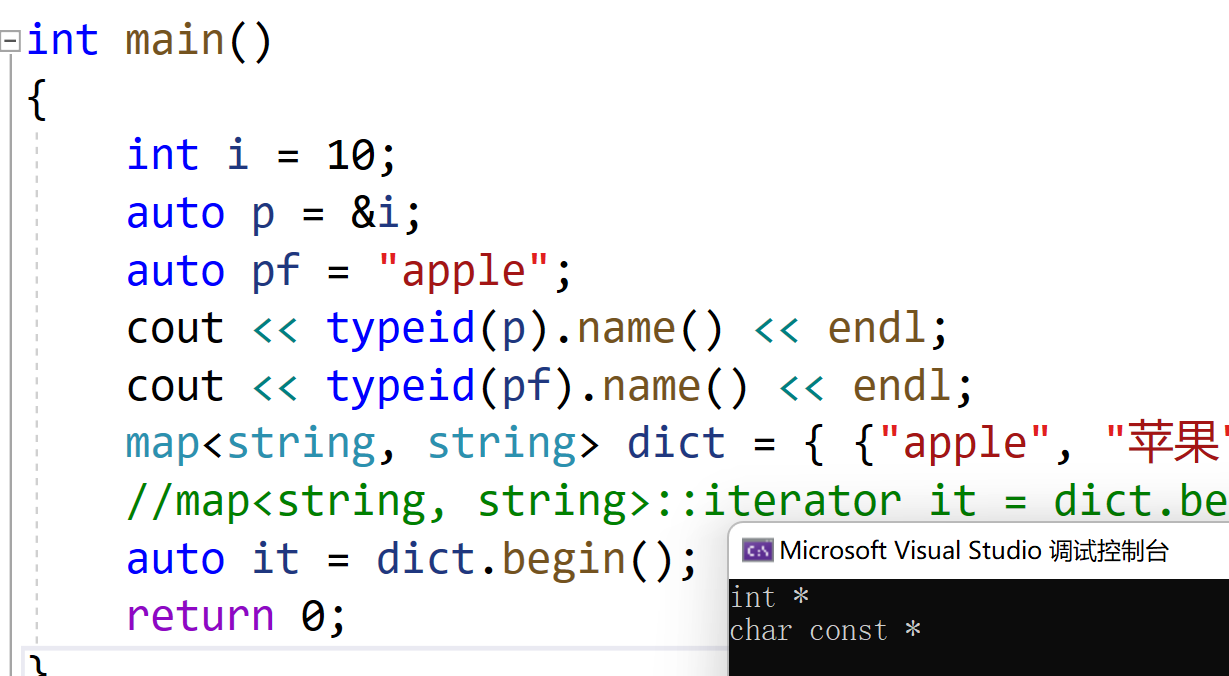
3.2 typedécl
Le mot clé decltype déclare que le type d'une variable est le type spécifié par l'expression.
// decltype的一些使用使用场景 template<class T1, class T2> void F(T1 t1, T2 t2) { decltype(t1 * t2) ret; cout << typeid(ret).name() << endl; } int main() { const int x = 1; double y = 2.2; decltype(x * y) ret; // ret的类型是double decltype(&x) p; // p的类型是int* cout << typeid(ret).name() << endl; cout << typeid(p).name() << endl; F(1, 'a');//int 和 char --》int return 0; }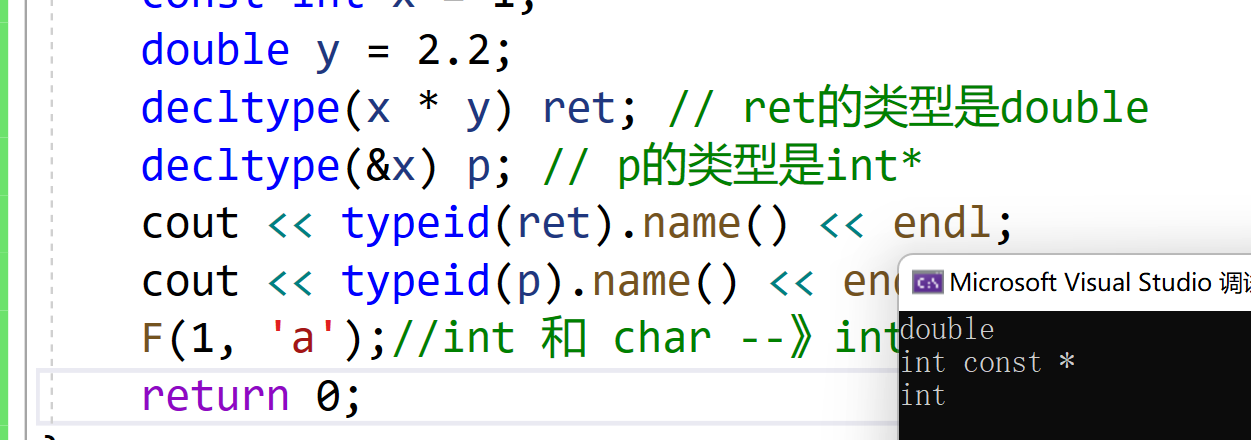
3.3 Différence entre auto et decltype
decltype et auto sont deux nouveaux mots clés fournis par C++ 11. Leur fonction est de permettre au compilateur de déduire automatiquement le type des variables.
auto peut être utilisé pour la déduction automatique de type des variables locales et des valeurs de retour de fonction. Le compilateur déduira le type de la variable en fonction du type de l'expression. Par exemple:
auto i = 10; // 推导为int类型 auto s = "hello"; // 推导为const char*类型Le decltype est utilisé pour obtenir le type d’expression, y compris le type de valeur de retour des variables et des expressions. Par exemple:
int i = 10; decltype(i) j; // 推导类型为int double getValue(); decltype(getValue()) d; // 推导类型为doubleComme vous pouvez le voir, decltype doit spécifier une expression ou un nom de variable lors de son utilisation, mais pas auto. De plus, le type de valeur de retour decltype a un type complètement précis, comprenant les qualificatifs const, référence et cv, etc., tandis que auto ne peut déduire que le type nu, et la combinaison de la déduction de type et des modificateurs constants est nécessaire pour déduire le type complet.
En bref, decltype et auto peuvent être utilisés pour déduire des types de variables, mais leurs fonctions sont légèrement différentes. auto est principalement utilisé pour la déduction automatique de type de variables locales et de valeurs de retour de fonction, tandis que decltype est utilisé pour obtenir le type exact de l'expression, y compris const, référence et autres qualificatifs.
3.4 nullptr
Puisque NULL en C++ est défini comme le littéral 0, cela peut poser certains problèmes, car 0 peut représenter à la fois une constante de pointeur et une constante entière. Par conséquent, par souci de clarté et de sécurité, nullptr est ajouté en C++11 pour représenter un pointeur nul.
#ifndef NULL #ifdef __cplusplus #define NULL 0 #else #define NULL ((void *)0) #endif #endif
4. Références Rvalue et sémantique de déplacement
4.1 Références Lvalue et références rvalue
Il existe une syntaxe de référence dans la syntaxe C++ traditionnelle et la nouvelle fonctionnalité de syntaxe de référence rvalue dans C++11, donc à partir de maintenant, la référence que nous avons apprise auparavant est appelée une référence lvalue. Qu'il s'agisse d'une référence lvalue ou d'une référence rvalue, un alias est donné à l'objet.
Alors, qu’est-ce qu’une lvalue exactement ? Qu'est-ce qu'une rvalue ? Qu'est-ce qu'une référence lvalue ? Qu'est-ce qu'une référence rvalue ?
lvaleurC'est une expression représentant des données (comme un nom de variable ou un pointeur déréférencé), on peut obtenir son adresse + lui attribuer une valeur, la valeur de gauche peut apparaître sur le côté gauche du symbole d'affectation, et la rvalue ne peut pas apparaître sur le côté gauche du symbole d'affectation . La lvalue après le modificateur const, lorsqu'elle est définie, ne peut pas se voir attribuer une valeur, mais son adresse peut être prise. Une référence lvalue est une référence à une lvalue et un alias est donné à la lvalue.
int main() { // 以下的p、b、c、*p都是左值 int* p = new int(0); int b = 1; const int c = 2; // 以下几个是对上面左值的左值引用 int*& rp = p; int& rb = b; const int& rc = c; int& pvalue = *p; return 0; }rvaleurIl s'agit également d'une expression représentant des données, telles que : une constante littérale, une valeur de retour d'expression, une valeur de retour de fonction (cela ne peut pas être un retour de référence lvalue), etc. Les valeurs R peuvent apparaître sur le côté droit des symboles d'affectation, mais ne peuvent pas apparaître dans symboles d'affectation A gauche, les rvalues ne peuvent pas prendre d'adresses. Une référence rvalue est une référence à une rvalue, donnant un alias à la rvalue.
int main() { double x = 1.1, y = 2.2; // 以下几个都是常见的右值 10; x + y; fmin(x, y); // 以下几个都是对右值的右值引用 int&& rr1 = 10; double&& rr2 = x + y; double&& rr3 = fmin(x, y); // 这里编译会报错:error C2106: “=”: 左操作数必须为左值 10 = 1; x + y = 1; fmin(x, y) = 1; return 0; }
Il convient de noter que l'adresse de la rvalue ne peut pas être prise, mais une fois l'alias donné à la rvalue, la rvalue sera stockée dans un emplacement spécifique, et l'adresse de l'emplacement peut être prise, c'est-à-dire pour exemple : la valeur littérale 10 ne peut pas être prise comme adresse, mais une fois rr1 référencé, l'adresse de rr1 peut être obtenue, ou rr1 peut être modifié. Si vous ne souhaitez pas que rr1 soit modifié, vous pouvez utiliser const int&& rr1 pour y faire référence. Est-ce que cela semble incroyable ? Ce n'est pas le cas pour comprendre l'utilisation réelle des références rvalue, et cette fonctionnalité n'est pas importante.
int main() { double x = 1.1, y = 2.2; int&& rr1 = 10; const double&& rr2 = x + y; rr1 = 20; rr2 = 5.5; // 报错 return 0; }


4.2 Comparaison des références lvalue et des références rvalue
Résumé des références lvalue :
Une référence lvalue ne peut faire référence qu’à une lvalue, pas à une rvalue.
Mais une référence const lvalue peut faire référence à la fois à une lvalue et à une rvalue.
int main() { // 左值引用只能引用左值,不能引用右值。 int a = 10; int& ra1 = a; // ra为a的别名 //int& ra2 = 10; // 编译失败,因为10是右值 // const左值引用既可引用左值,也可引用右值。 const int& ra3 = 10; const int& ra4 = a; return 0; }Résumé des références rvalue :
Les références Rvalue ne peuvent faire référence qu’à des rvalues, pas à des lvalues.
Mais les références rvalue peuvent déplacer des lvalues ultérieures.
int main() { // 右值引用只能右值,不能引用左值。 int&& r1 = 10; // error C2440: “初始化”: 无法从“int”转换为“int &&” // message : 无法将左值绑定到右值引用 int a = 10; int&& r2 = a;//报错:“初始化”: 无法从“int”转换为“int &&” // 右值引用可以引用move以后的左值 int&& r3 = std::move(a); return 0; }
4.3 Scénarios d'utilisation et significations des références rvalue
Nous avons vu plus tôt que les références lvalue peuvent référencer à la fois les lvalues et les rvalues, alors pourquoi C++11 propose-t-il également des références rvalue ? Est-ce superflu ? Jetons un coup d'œil aux défauts des références lvalue et comment les références rvalue peuvent compenser ces défauts !
Scénarios d'utilisation des références lvalue :
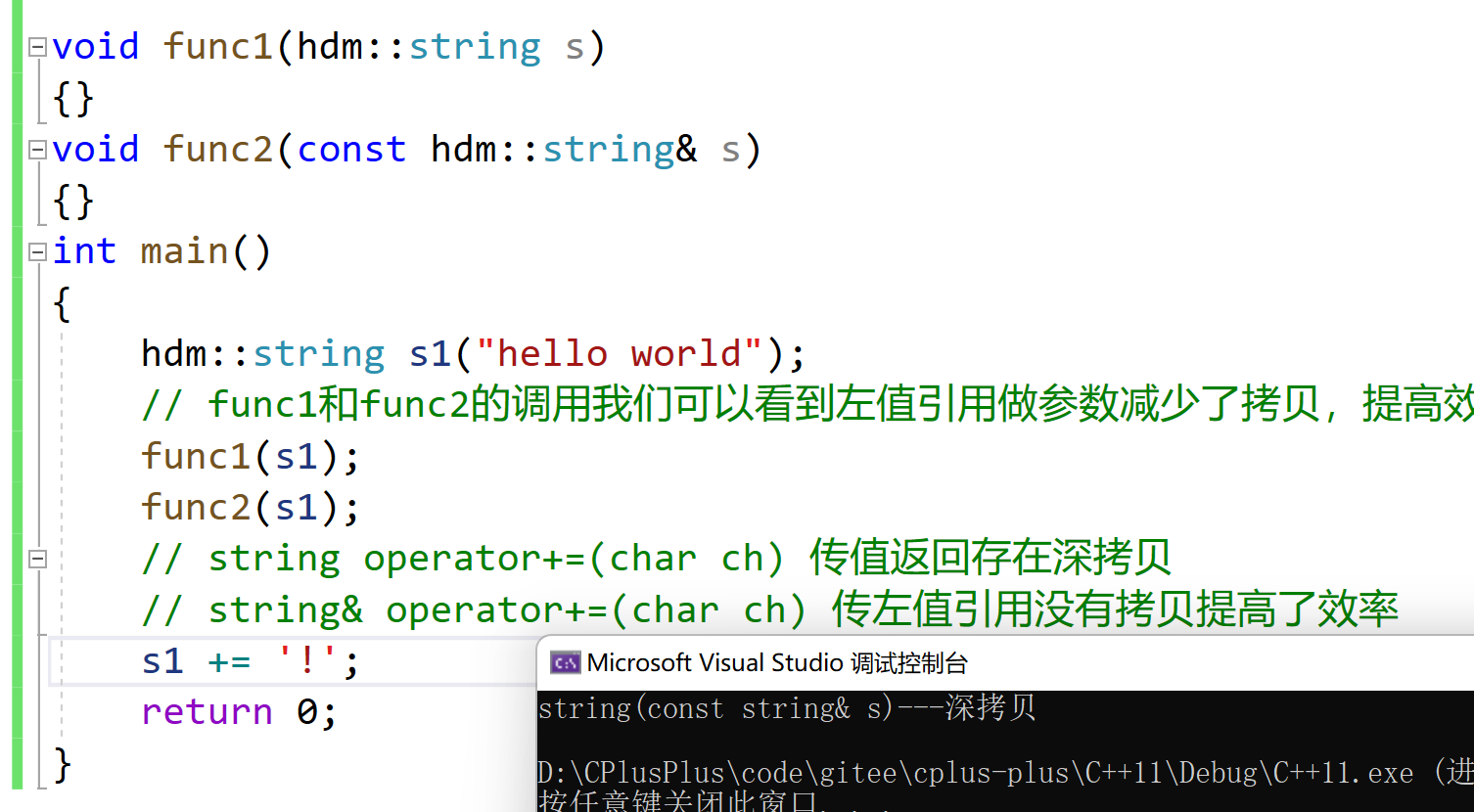
La création de paramètres et la création de valeurs de retour peuvent améliorer l'efficacité .void func1(hdm::string s) { } void func2(const hdm::string& s) { } int main() { hdm::string s1("hello world"); // func1和func2的调用我们可以看到左值引用做参数减少了拷贝,提高效率的使用场景和价值 func1(s1); func2(s1); // string operator+=(char ch) 传值返回存在深拷贝 // string& operator+=(char ch) 传左值引用没有拷贝提高了效率 s1 += '!'; return 0; }
Remarque : Nous devons utiliser notre propre implémentation simulée de la chaîne pour qu'elle puisse être imprimée. Il nous suffit d'ajouter un code d'entrée lors de la copie profonde. L'exemple suivant est le même
//现代写法 string& operator=(string s) { swap(s); cout << "string& operator=(string s) --- 深拷贝" << endl; return *this; }Lacunes des références lvalue :
Mais lorsque l'objet de retour de fonction est une variable locale, il n'existe pas en dehors de la portée de la fonction, vous ne pouvez donc pas utiliser la référence lvalue pour revenir et ne pouvez retourner que par valeur. Par exemple : comme vous pouvez le voir dans la fonction hdm::string to_string(int value), seul le retour par valeur peut être utilisé ici, et le retour par valeur provoquera au moins une construction de copie (s'il s'agit de compilateurs plus anciens, cela peut être deux constructions de copie).

Les références Rvalue et la sémantique de déplacement résolvent les problèmes ci-dessus :
Ajoutez une construction de déplacement à hdm::string. L'essence de la construction de déplacement est de voler les ressources du paramètre rvalue. Si l'espace réservé est déjà là, il n'est pas nécessaire de faire une copie complète. C'est donc ce qu'on appelle un déplacement construire, ce qui signifie voler les ressources des autres pour construire les vôtres .
string(string&& s) :_str(nullptr), _capacity(0), _size(0) { cout << "string(string&& s)---移动构造" << endl; swap(s); }Si nous exécutons les deux appels à hdm::to_string ci-dessus, nous constaterons que la structure de copie de la copie profonde n'est pas appelée ici, mais la structure de déplacement est appelée. Il n'y a pas de nouvel espace pour ouvrir et copier des données dans la structure de déplacement, donc l'efficacité est améliorée.

Non seulement déplacer la construction, mais aussi déplacer l'affectation :
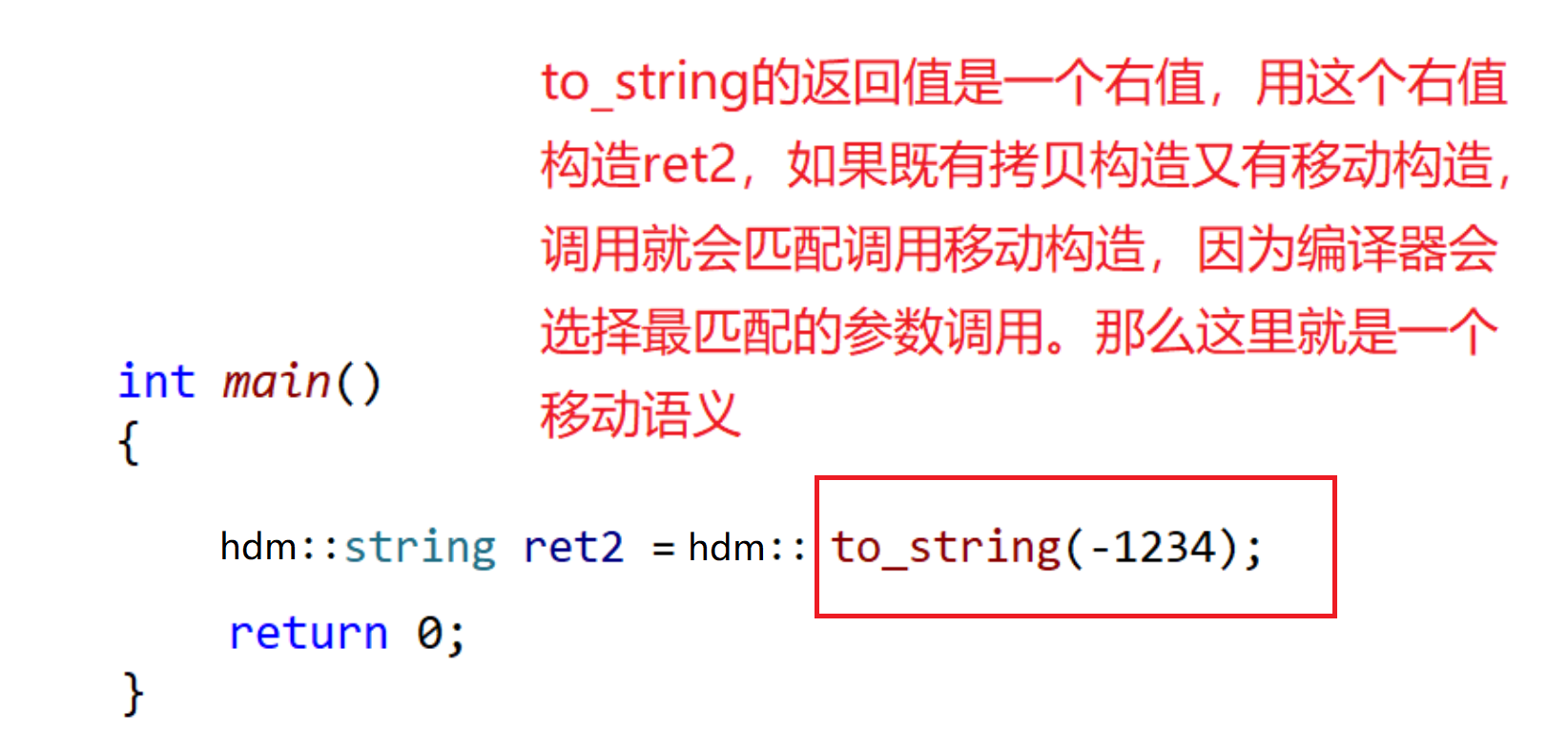
Ajoutez une fonction d'affectation de déplacement à la classe bit::string, puis appelez hdm::to_string(1234), mais cette fois, l'objet rvalue renvoyé par hdm::to_string(1234) est affecté à l'objet ret1. l'appel est une construction mobile
string& operator=(string&& s) { cout << "string operator=(string&& s)---移动赋值" << endl; swap(s); return *this; } int main() { hdm::string ret1; ret1 = hdm::to_string(1234); return 0; } // 运行结果: // string(string&& s) -- 移动构造 // string& operator=(string&& s) -- 移动赋值Après avoir exécuté cela, nous voyons qu'un constructeur de déplacement et une affectation de déplacement sont appelés. Car si un objet existant est utilisé pour le recevoir, le compilateur ne peut pas l'optimiser. La fonction hdm::to_string utilisera d'abord la construction de génération str pour générer un objet temporaire, mais nous pouvons voir que le compilateur est suffisamment intelligent pour reconnaître str comme une rvalue et appeler la construction move. Attribuez ensuite cet objet temporaire à ret1 comme valeur de retour de l'appel de fonction hdm::to_string et de l'affectation de déplacement appelée ici.
Ce n'est que dans le cas suivant que le compilateur l'optimisera directement dans une construction de déplacement
int main() { hdm::string ret1 = hdm::to_string(1234); return 0; } // 运行结果: // string(string&& s) -- 移动构造


4.4 La référence Rvalue fait référence à lvalue et à une analyse plus approfondie des scénarios d'utilisation
Selon la syntaxe, les références rvalue ne peuvent référencer que des rvalues, mais les références rvalue ne doivent-elles pas faire référence à des lvalues ?
Parce que : dans certains scénarios, vous devrez peut-être vraiment utiliser des rvalues pour référencer des lvalues afin d'implémenter la sémantique de déplacement. Lorsque vous devez utiliser une référence rvalue pour faire référence à une lvalue, vous pouvez convertir la lvalue en rvalue via la fonction de déplacement. En C++11, la fonction std::move() se trouve dans le fichier d'en-tête. Le nom de cette fonction prête à confusion. Elle ne déplace rien. Sa seule fonction est de forcer une lvalue dans une référence rvalue, puis d'implémenter le mouvement.Sémantique.
int main() { hdm::string s1("hello world"); // 这里s1是左值,调用的是拷贝构造 hdm::string s2(s1); // 这里我们把s1 move处理以后, 会被当成右值,调用移动构造 // 但是这里要注意,一般是不要这样用的,因为我们会发现s1的 // 资源被转移给了s3,s1被置空了。 hdm::string s3(std::move(s1)); return 0; }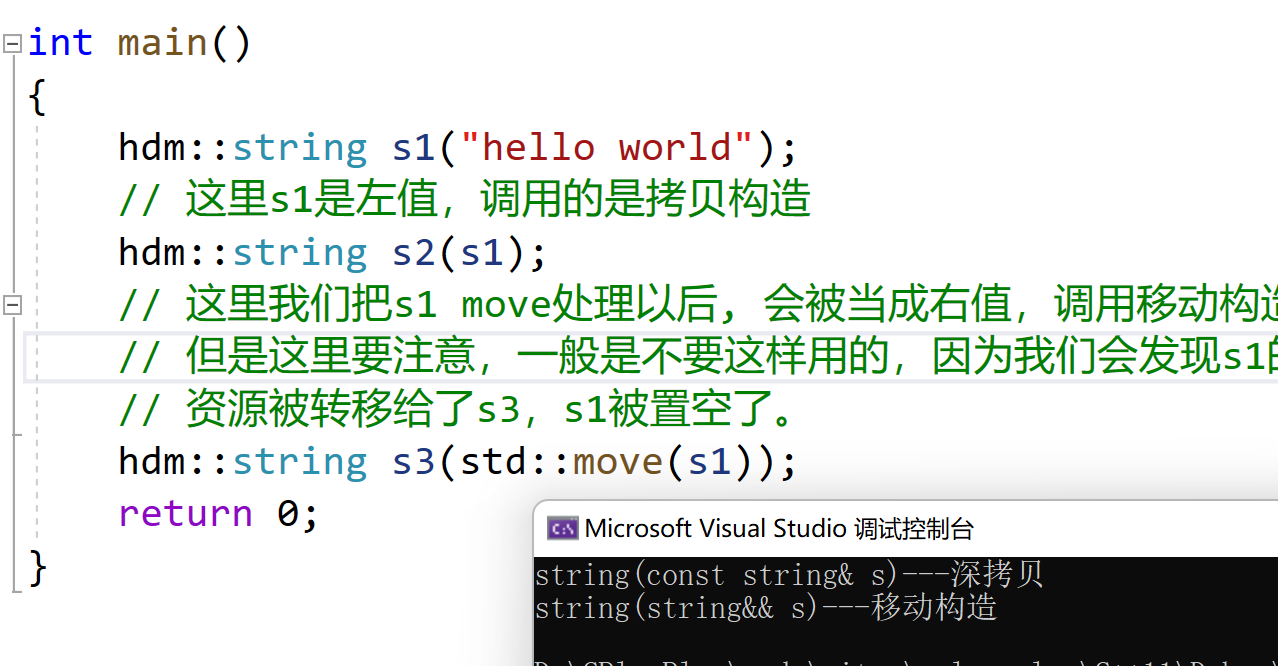
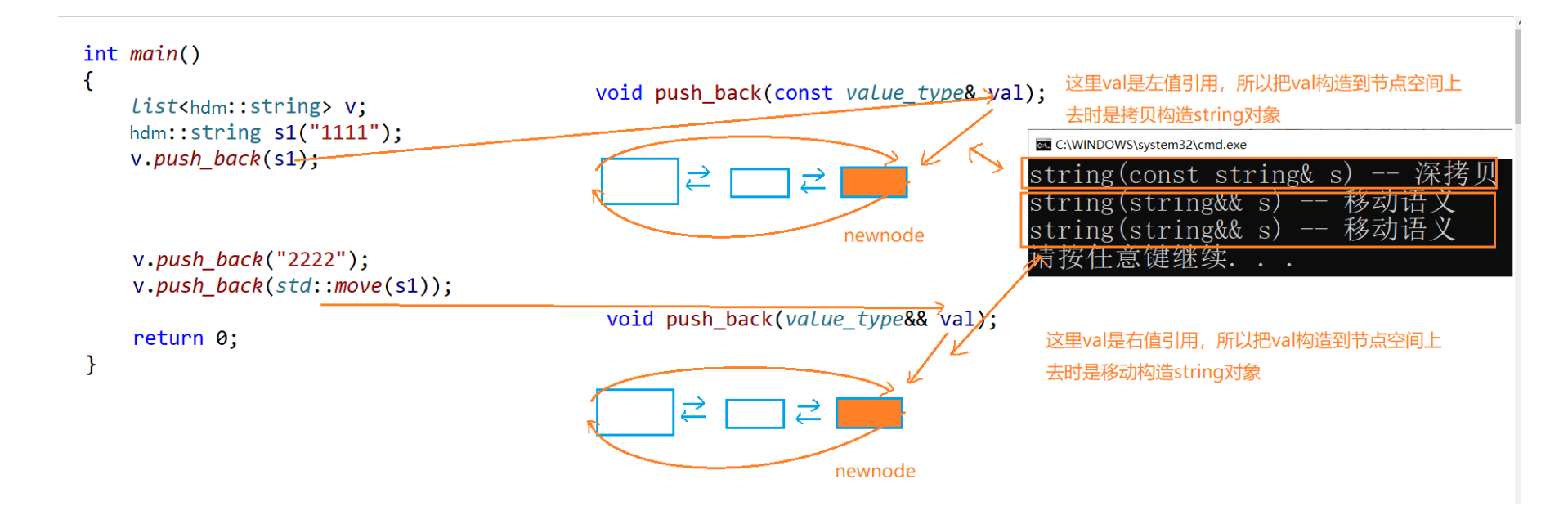
La fonction d'interface d'insertion de conteneur STL ajoute également une version de référence rvalue :
document STL-listint main() { list<hdm::string> lt; hdm::string s1("1111"); // 这里调用的是拷贝构造 lt.push_back(s1); // 下面调用都是移动构造 lt.push_back("2222"); lt.push_back(std::move(s1)); return 0; }
4.5 Transmission parfaite
&& référence universelle dans le modèle
void Fun(int& x) { cout << "左值引用" << endl; } void Fun(const int& x) { cout << "const 左值引用" << endl; } void Fun(int&& x) { cout << "右值引用" << endl; } void Fun(const int&& x) { cout << "const 右值引用" << endl; } // 模板中的&&不代表右值引用,而是万能引用,其既能接收左值又能接收右值。 // 模板的万能引用只是提供了能够接收同时接收左值引用和右值引用的能力, // 但是引用类型的唯一作用就是限制了接收的类型,后续使用中都退化成了左值, // 我们希望能够在传递过程中保持它的左值或者右值的属性, 就需要用我们下面学习的完美转发 template<typename T> void PerfectForward(T&& t) { Fun(t); } int main() { PerfectForward(10); // 右值 int a; PerfectForward(a); // 左值 PerfectForward(std::move(a)); // 右值 const int b = 8; PerfectForward(b); // const 左值 PerfectForward(std::move(b)); // const 右值 return 0; }Pour être correct : le contenu de la sortie devrait être le contenu écrit dans le commentaire ci-dessus, mais en fait ce n'est pas le cas. La raison en est que l'objet passé à t lors du processus de passage des paramètres est devenu une lvalue lorsque Fun est ensuite appelé , parce que l'objet est passé à l'objet t, une fois que t a reçu la valeur, il est enregistré dans la valeur t et tout t est devenu une lvalue
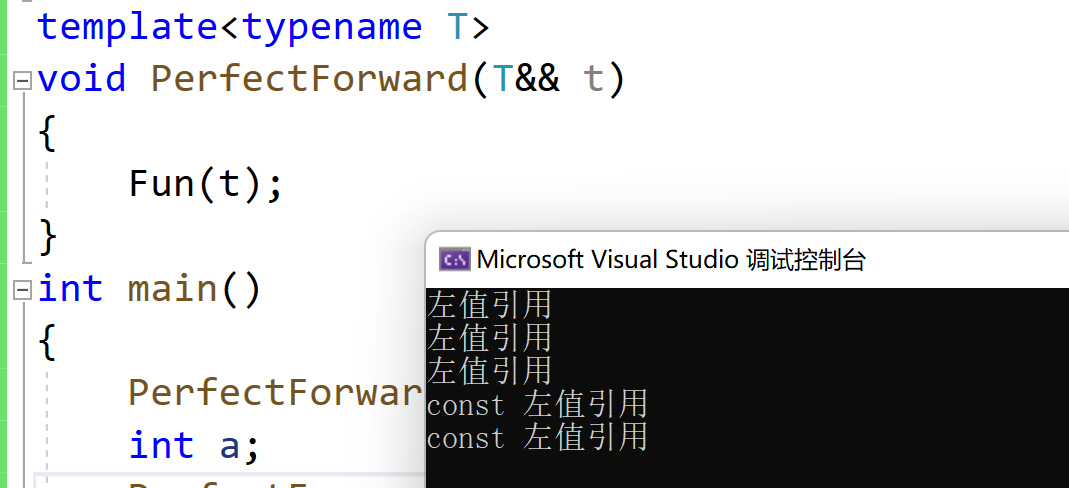
Solution : utilisez std::forward, transfert parfait pour conserver les attributs de type natifs de l'objet pendant le processus de transfert de paramètres.
template<typename T> void PerfectForward(T&& t) { // std::forward<T>(t)在传参的过程中保持了t的原生类型属性 Fun(std::forward<T>(t)); }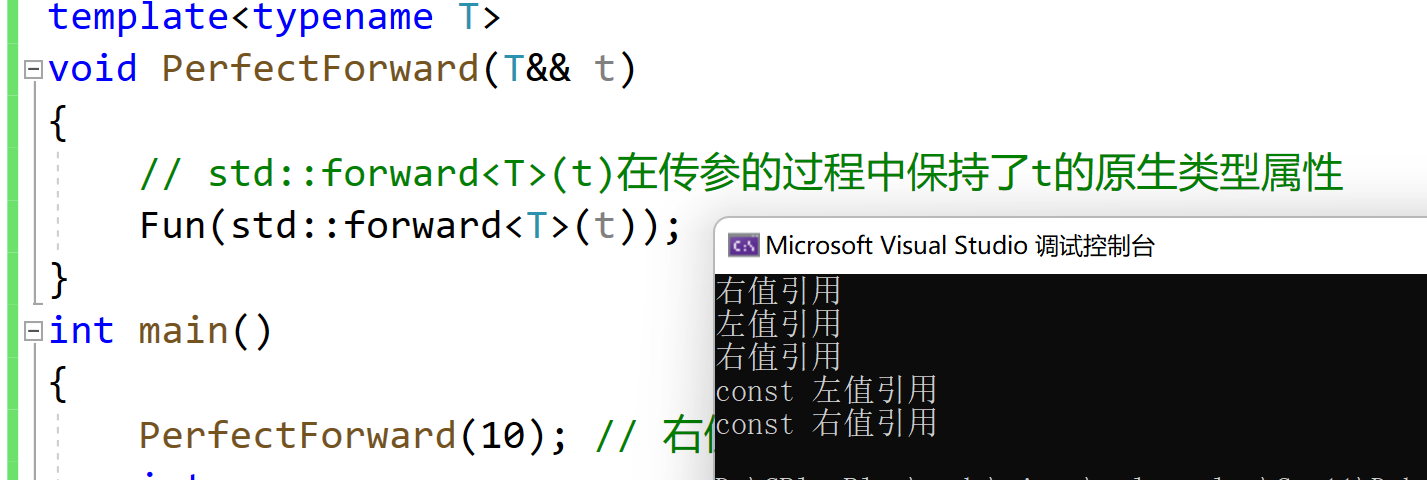
Scénarios d'utilisation réels de transfert parfait :
template<class T> struct ListNode { ListNode* _next = nullptr; ListNode* _prev = nullptr; T _data; }; template<class T> class List { typedef ListNode<T> Node; public: List() { _head = new Node; _head->_next = _head; _head->_prev = _head; } void PushBack(T&& x) { //Insert(_head, x); Insert(_head, std::forward<T>(x)); } void PushFront(T&& x) { //Insert(_head->_next, x); Insert(_head->_next, std::forward<T>(x)); } void Insert(Node* pos, T&& x) { Node* prev = pos->_prev; Node* newnode = new Node; newnode->_data = std::forward<T>(x); // 关键位置 // prev newnode pos prev->_next = newnode; newnode->_prev = prev; newnode->_next = pos; pos->_prev = newnode; } void Insert(Node* pos, const T& x) { Node* prev = pos->_prev; Node* newnode = new Node; newnode->_data = x; // 关键位置 // prev newnode pos prev->_next = newnode; newnode->_prev = prev; newnode->_next = pos; pos->_prev = newnode; } private: Node* _head; }; int main() { List<hdm::string> lt; lt.PushBack("1111"); lt.PushFront("2222"); return 0; } //运行结果 //string operator=(string&& s)---移动赋值 //string operator=(string&& s)-- - 移动赋值
5 nouvelles fonctions de classe
Fonctions membres par défaut
Il existe 6 fonctions membres par défaut dans la classe C++ d'origine :
Constructeur
destructeur
constructeur de copie
surcharge des devoirs de copie
prendre une surcharge d'adresses
const prend l'adresse et surcharge.
Les quatre derniers qui sont importants sont les quatre premiers, et les deux derniers sont de peu d'utilité. La fonction membre par défaut est une fonction par défaut que le compilateur générera si nous ne l'écrivons pas. C++ 11 en ajoute deux nouveaux : la surcharge du constructeur de déplacement et de l'opérateur d'affectation de déplacement.Il y a quelques points à noter concernant la surcharge des constructeurs de déplacement et des opérateurs d'affectation de déplacement, comme suit :
Si vous n'implémentez pas le constructeur de déplacement vous-même et n'implémentez aucun des destructeurs, de la construction de copie et de la surcharge d'affectation de copie. Ensuite, le compilateur générera automatiquement un constructeur de déplacement par défaut. Le constructeur de déplacement généré par défaut effectuera une copie membre par membre, octet par octet, pour les membres de type intégré. Pour les membres de type personnalisé, vous devez vérifier si le membre implémente la construction de déplacement. S'il est implémenté, appelez move construction. Dans le cas contraire, appelez copy construction.
Si vous n'implémentez pas vous-même la fonction de surcharge d'affectation de déplacement et n'implémentez aucune des surcharges de destructeur, de construction de copie et d'affectation de copie, le compilateur générera automatiquement une affectation de déplacement par défaut. Le constructeur de déplacement généré par défaut effectuera une copie membre par membre, octet par octet, pour les membres de type intégré. Pour les membres de type personnalisé, vous devez vérifier si le membre implémente l'affectation de déplacement. Si c'est le cas, appelez l'affectation de déplacement. Dans le cas contraire, appelez l'affectation de copie. (L'affectation de déplacement par défaut est complètement similaire à la construction de déplacement ci-dessus)
Si vous fournissez une construction de déplacement ou une affectation de déplacement, le compilateur ne fournira pas automatiquement la construction de copie et l'affectation de copie.
// 以下代码在vs2013中不能体现,在vs2019下才能演示体现上面的特性。 class Person { public: Person(const char* name = "", int age = 0) :_name(name) , _age(age) { } //-----------------------------------// //如果没有自己实现下面任意一个,那么编译器就会帮我们默认生成一个移动构造和移动赋值 /*Person(const Person& p) :_name(p._name) ,_age(p._age) {}*/ /*Person& operator=(const Person& p) { if(this != &p) { _name = p._name; _age = p._age; } return *this; }*/ /*~Person() {}*/ //-----------------------------------// private: hdm::string _name; int _age; }; int main() { Person s1; Person s2 = s1; Person s3 = std::move(s1); Person s4; s4 = std::move(s2); return 0; } //运行结果: //string(const string& s)---深拷贝 //string(string&& s)---移动构造 //string operator=(string&& s)---移动赋值Le mot clé default qui force la génération d'une fonction par défaut :
C++11 vous donne plus de contrôle sur les fonctions par défaut utilisées. Supposons que vous souhaitiez utiliser une fonction par défaut, mais que pour une raison quelconque, cette fonction n'est pas générée par défaut. Par exemple : si nous fournissons une structure de copie, la structure de déplacement ne sera pas générée, alors nous pouvons utiliser le mot-clé par défaut pour afficher la génération de la structure de déplacement spécifiée.
class Person { public: Person(const char* name = "", int age = 0) :_name(name) , _age(age) { } Person(const Person& p) :_name(p._name) , _age(p._age) { } Person(Person&& p) = default; private: hdm::string _name; int _age; }; int main() { Person s1; Person s2 = s1; Person s3 = std::move(s1);//使用了默认生成的移动构造 return 0; } //运行结果 //string(const string& s)-- - 深拷贝 //string(string && s)-- - 移动构造Suppression de mots-clés interdisant de générer des fonctions par défaut :
Si vous souhaitez limiter la génération de certaines fonctions par défaut, en C++98, la fonction est définie sur private, et uniquement déclarée mais non définie, de sorte qu'une erreur sera signalée tant que d'autres voudront l'appeler. C'est plus simple en C++11, il suffit d'ajouter =delete à la déclaration de fonction, cette syntaxe demande au compilateur de ne pas générer de version par défaut de la fonction correspondante, et la fonction modifiée par =delete est appelée une fonction de suppression.
class Person { public: Person(const char* name = "", int age = 0) :_name(name) , _age(age) { } Person(const Person& p) = delete; private: hdm::string _name; int _age; }; int main() { Person s1; Person s2 = s1; Person s3 = std::move(s1); return 0; } //运行报错 //error C2280: “Person::Person(const Person &)”: 尝试引用已删除的函数
6. Modèles variés
Le nouveau modèle de paramètre variable de fonctionnalité de C++11 vous permet de créer des modèles de fonction et des modèles de classe pouvant accepter des paramètres variables. Par rapport à C++98/03, les modèles de classe et les modèles de fonction ne peuvent contenir qu'un nombre fixe de paramètres de modèle. , variable les paramètres du modèle constituent sans aucun doute une énorme amélioration. Cependant, comme les paramètres variables du modèle sont relativement abstraits et nécessitent certaines compétences pour être utilisés, ces connaissances restent relativement obscures. À ce stade, il suffit de maîtriser quelques fonctionnalités de base des modèles de paramètres variables. Nous nous arrêterons ici. Si nécessaire, vous pourrez en apprendre davantage en profondeur.
Ce qui suit est un modèle de fonction de paramètre variable de base
// Args是一个模板参数包,args是一个函数形参参数包 // 声明一个参数包Args...args,这个参数包中可以包含0到任意个模板参数。 template <class ...Args> void ShowList(Args... args) { }Le paramètre args ci-dessus est précédé de points de suspension, il s'agit donc d'un paramètre de modèle variable. Nous appelons le paramètre avec une ellipse un "paquet de paramètres", qui contient 0 à N (N>=0) paramètres de modèle. Nous ne pouvons pas obtenir directement chaque paramètre dans le package de paramètres args. Nous ne pouvons obtenir chaque paramètre dans le package de paramètres qu'en développant le package de paramètres. C'est une caractéristique principale de l'utilisation de paramètres de modèle variable, et c'est aussi la plus grande difficulté, c'est-à-dire comment pour développer les paramètres de modèle variadiques. Étant donné que la syntaxe ne prend pas en charge l'utilisation de args[i] pour obtenir des paramètres variables, nous utilisons des astuces étranges pour obtenir les valeurs du package de paramètres une par une.
Extension de la fonction récursive du pack de paramètres
template<class T> void showList(T val) { cout << val << endl; } template<class T,class ...Args> void showList(T value, Args... args) { cout << value << " "; showList(args...); } int main() { showList(1); showList(1,'a'); showList(1,'a',"string"); return 0; }Pack de paramètres d'extension d'expression virgule
Cette méthode d'extension du pack de paramètres n'a pas besoin de terminer la fonction par récursion, elle est directement développée dans le corps de la fonction d'expansion, printarg n'est pas une fonction de terminaison récursive, mais une fonction qui traite chaque paramètre du pack de paramètres. La clé de cette expansion sur place des packages de paramètres est l’expression virgule. Nous savons que les expressions virgules exécuteront les expressions précédant la virgule dans l’ordre. L'expression virgule dans la fonction d'expansion : (printarg(args), 0), suit également cette séquence d'exécution, exécutez d'abord printarg(args), puis obtenez le résultat 0 de l'expression virgule. Dans le même temps, une autre fonctionnalité de la liste d'initialisation C++ 11 est utilisée. Pour initialiser un tableau de longueur variable via la liste d'initialisation, {(printarg(args), 0)...} sera développé en ((printarg (arg1), 0 ), (printarg(arg2),0), (printarg(arg3),0), etc… ), finira par créer un tableau int arr[sizeof… (Args)] dont les valeurs des éléments sont toutes 0. Puisqu'il s'agit d'une expression virgule, lors du processus de création d'un tableau, printarg(args) devant l'expression virgule sera d'abord exécuté pour
imprimer les paramètres, c'est-à-dire que le pack de paramètres sera développé lors de la construction de le tableau int. Le but de ce tableau est uniquement d'étendre le package de paramètres pendant le processus de construction du tableau.template<class T> void PrintArg(T value) { cout << value << " "; } template<class ...Args> void showList( Args... args) { int arr[] = { (PrintArg(args),0)... }; cout << endl; } int main() { showList(1000); showList(1000,'a'); showList(1000,'a',"string"); return 0; }
7. expression lambda
7.1 Un exemple en C++98
En C++98, si vous souhaitez trier les éléments d'une collection de données, vous pouvez utiliser la méthode std::sort.
#include <algorithm> #include <functional> void PrintArr(int arr[],int size){ for (int i=0;i<size;++i){ cout << arr[i] << " "; } cout << endl; } int main(){ int arr[] = { 3,2,1,5,6,4,7,8,0 }; // 默认按照小于比较,排出来结果是升序 std::sort(arr, arr + sizeof(arr) / sizeof(arr[0])); PrintArr(arr, sizeof(arr) / sizeof(arr[0])); // 如果需要降序,需要改变元素的比较规则 std::sort(arr, arr + sizeof(arr) / sizeof(arr[0]), greater<int>()); PrintArr(arr, sizeof(arr) / sizeof(arr[0])); return 0; } //运行结果 //0 1 2 3 4 5 6 7 8 //8 7 6 5 4 3 2 1 0Si les éléments à trier sont d'un type personnalisé, l'utilisateur doit définir les règles de comparaison pour le tri :
struct Goods{ string _name; // 名字 double _price; // 价格 int _evaluate; // 评价 Goods(const char* str, double price, int evaluate) :_name(str) , _price(price) , _evaluate(evaluate) { } }; struct ComparePriceLess//比较方式的仿函数{ bool operator()(const Goods& gl, const Goods& gr){ return gl._price < gr._price; } }; struct ComparePriceGreater{ bool operator()(const Goods& gl, const Goods& gr){ return gl._price > gr._price; } }; int main(){ vector<Goods> v = { { "苹果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2,3 }, { "菠萝", 1.5, 4 } }; sort(v.begin(), v.end(), ComparePriceLess()); sort(v.begin(), v.end(), ComparePriceGreater()); return 0; }Avec le développement de la grammaire C++, les gens ont commencé à penser que la méthode d'écriture ci-dessus était trop compliquée. Chaque fois que pour implémenter un algorithme, une nouvelle classe doit être réécrite. Si la logique de chaque comparaison est différente, plusieurs classes doivent être implémenté. En particulier, le fait de nommer la même classe apporte de grands inconvénients aux programmeurs. Par conséquent, les expressions Lambda sont apparues dans la syntaxe C++11 .
7.2expressions lambda
manifestation
int main(){ vector<Goods> v = { { "苹果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2,3 }, { "菠萝", 1.5, 4 } }; //根据价格排升序 sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) { return g1._price < g2._price; }); //根据价格排降序 sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) { return g1._price > g2._price; }); //根据评价排升序 sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) { return g1._evaluate < g2._evaluate; }); //根据评价排降序 sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2) { return g1._evaluate > g2._evaluate; }); return 0; }Le code ci-dessus est résolu à l'aide de l'expression lambda en C++ 11. On peut voir que l'expression lambda est en fait une fonction anonyme.
7.3 Syntaxe des expressions Lambda
Format d'écriture d'expression Lambda : [capture-list] (paramètres) mutable -> return-type {instruction}
- Explication de chaque partie de l'expression lambda
- [capture-list] : Capture list . Cette liste apparaît toujours au début de la fonction lambda. Le compilateur utilise [] pour déterminer si le code suivant est une fonction lambda. La liste de capture peut capturer des variables dans le contexte pour une utilisation par le fonction lambda .
- (paramètres) : une liste de paramètres. Conformément à la liste des paramètres d'une fonction ordinaire , si le passage des paramètres n'est pas requis, vous pouvez l'omettre avec ()
- mutable : Par défaut, une fonction lambda est toujours une fonction const, et mutable peut annuler sa constance. Lors de l'utilisation de ce modificateur, la liste des paramètres ne peut pas être omise (même si le paramètre est vide).
- ->returntype : type de valeur de retour. Utilisez le formulaire de type de retour de suivi pour déclarer le type de valeur de retour de la fonction. Cette partie peut être omise s'il n'y a pas de valeur de retour. Si le type de valeur de retour est clair, il peut également être omis et le compilateur en déduira le type de retour .
- {instruction} : corps de la fonction. Dans le corps de la fonction, en plus de ses paramètres, toutes les variables capturées sont disponibles.
Remarque :
Dans la définition de la fonction lambda, la liste de paramètres et le type de valeur de retour sont des parties facultatives, et la liste de capture et le corps de la fonction peuvent être vides. Ainsi, la fonction lambda la plus simple en C++11 est : []{}; Cette fonction lambda ne peut rien faire .int main(){ // 最简单的lambda表达式, 该lambda表达式没有任何意义 [] { }; // 省略参数列表和返回值类型,返回值类型由编译器推导为int int a = 3, b = 4; [=] { return a + 3; }; // 省略了返回值类型,无返回值类型 auto fun1 = [&](int c) { b = a + c; }; fun1(10); cout << a << " " << b << endl; // 相对完善的lambda函数 auto fun2 = [=, &b](int c)->int { return b += a + c; }; cout << fun2(10) << endl; // 复制捕捉x int x = 10; auto add_x = [x](int a) mutable { x *= 2; return a + x; }; cout << add_x(10) << endl; return 0; }
- Description de la liste de capture
La liste de capture décrit quelles données du contexte peuvent être utilisées par le lambda et si elles sont transmises par valeur ou par référence .
- [var] : indique que la méthode de transfert de valeur capture la variable var
- [=] : indique que la méthode de transmission de valeur capture toutes les variables de la portée parent (y compris celle-ci)
- [&var] : indique que la variable de capture var est passée par référence
- [&] : indique que le transfert de référence capture toutes les variables de la portée parent (y compris celle-ci)
- [this] : indique que la méthode de transfert de valeur capture le courant de ce pointeur
Avis:
a. La portée parent fait référence au bloc d'instructions contenant la fonction lambda.
b. Syntaxiquement, la liste de capture peut être composée de plusieurs éléments de capture, séparés par des virgules.
Par exemple : [=, &a, &b] : capturez les variables a et b par référence et capturez toutes les autres variables par valeur [&,
a, this] : capturez les variables a et this par valeur et capturez les autres variables par référence
- La liste de capture c ne permet pas de transmettre des variables à plusieurs reprises, sinon cela provoquerait des erreurs de compilation.
Par exemple : [=, a] : = a capturé toutes les variables par transfert de valeur, capture une répétition
dLa liste de capture des fonctions lambda en dehors de la portée du bloc doit être vide.
e La fonction lambda dans la portée du bloc ne peut capturer que les variables locales dans la portée parent, et la capture de toute variable hors portée ou
non locale entraînera des erreurs de compilation.Les expressions lambda ne peuvent pas être attribuées les unes aux autres, même si elles semblent être du même type
void (*PF)(); int main(){ auto f1 = [] { cout << "hello world" << endl; }; auto f2 = [] { cout << "hello world" << endl; }; //f1 = f2; // 编译失败--->提示找不到operator=() // 由于 Lambda 表达式是匿名的,因此不能直接将一个 Lambda 对象赋值给另一个 Lambda 对象。这是因为 Lambda 表达式没有默认的拷贝构造函数或赋值运算符重载,因此无法像普通的对象一样进行拷贝或赋值。 // 允许使用一个lambda表达式拷贝构造一个新的副本 auto f3(f2); f3(); // 可以将lambda表达式赋值给相同类型的函数指针 PF = f2; PF(); return 0; }
7.4 Objets fonction et expressions lambda
Un objet fonction, également appelé foncteur, est un objet qui peut être utilisé comme une fonction, c'est-à-dire un objet de classe qui surcharge l'opérateur Operator() dans la classe.
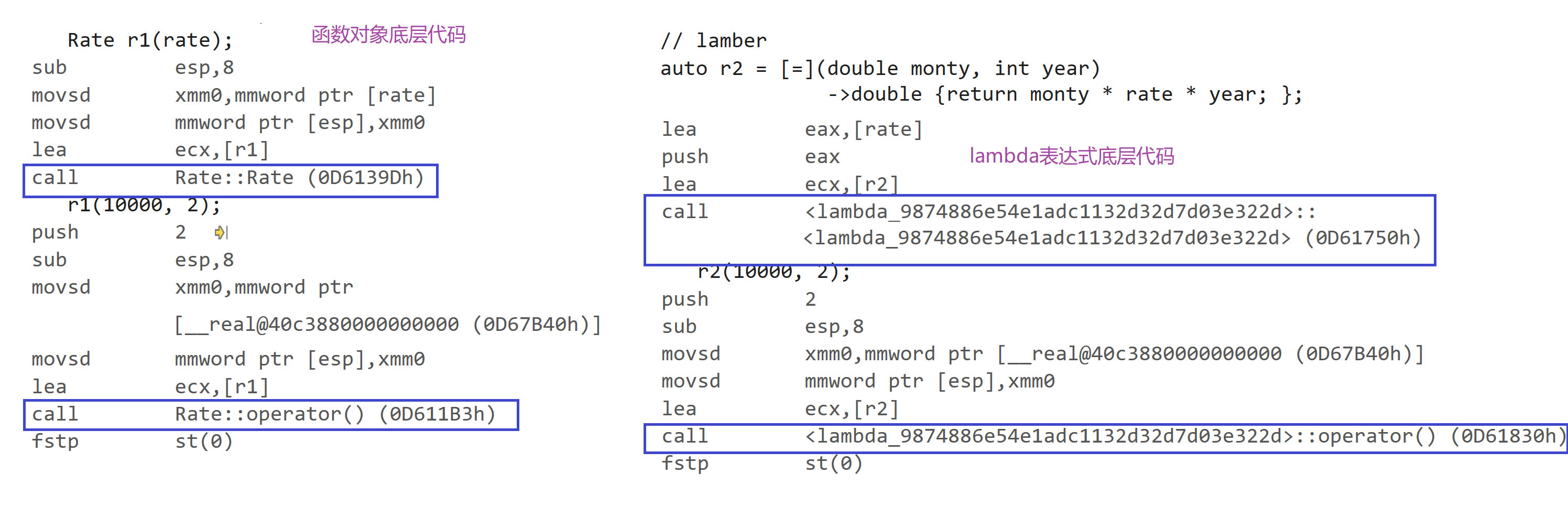
class Rate{ public: Rate(double rate) : _rate(rate){ } double operator()(double money, int year){ return money * _rate * year; } private: double _rate; }; int main(){ // 函数对象 double rate = 0.5; Rate r1(rate); cout << r1(10000, 2) << endl; // lamber auto r2 = [=](double monty, int year)->double { return monty * rate * year;}; cout << r2(10000, 2) << endl; return 0; } //运行结果 //10000 //10000En termes d'utilisation, les objets fonction sont exactement les mêmes que les expressions lambda.
L'objet fonction a rate comme variable membre, et la valeur initiale peut être donnée lors de la définition de l'objet, et l'expression lambda peut capturer directement la variable via la liste de capture.
En fait, la façon dont le compilateur sous-jacent gère les expressions lambda est complètement à la manière des objets fonction, c'est-à-dire que si une expression lambda est définie, le compilateur générera automatiquement une classe dans laquelle opérateur ( ).
8. Emballage
Wrappers de fonctions
Les wrappers de fonctions sont également appelés adaptateurs. La fonction en C++ est essentiellement un modèle de classe et un wrapper.
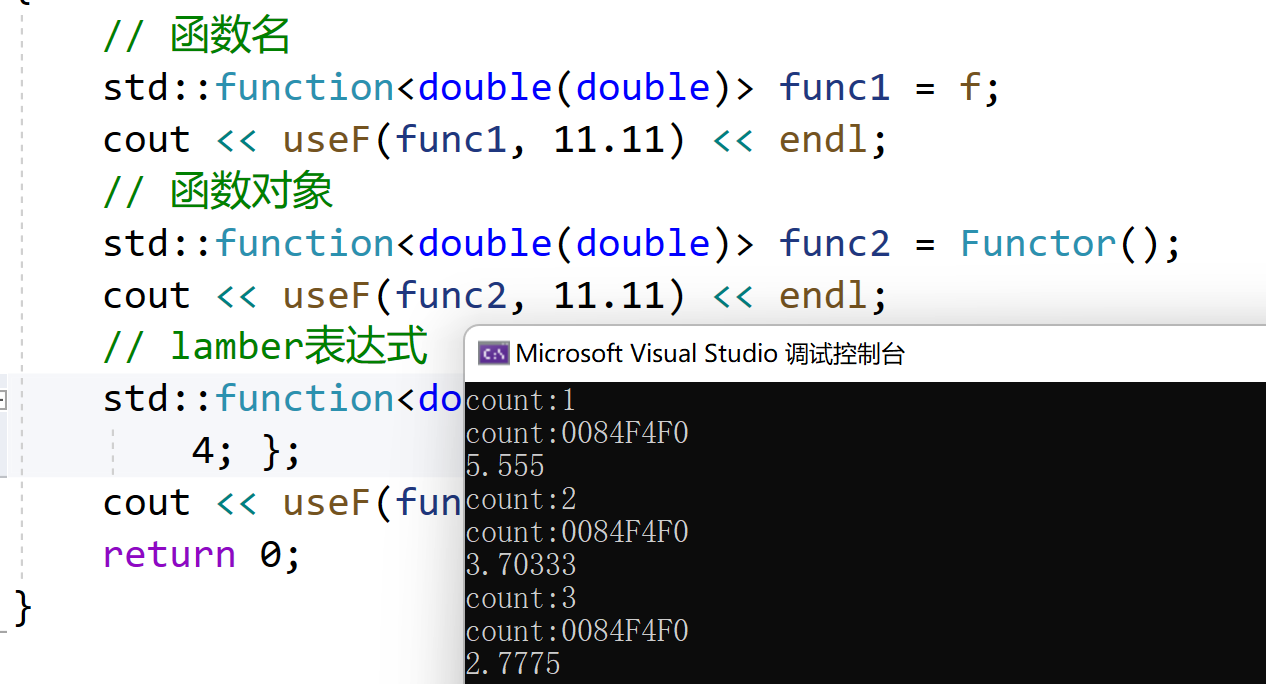
Alors jetons un coup d'œil : pourquoi avons-nous besoin de fonction ?//ret = func(x); // 上面func可能是什么呢?那么func可能是函数名?函数指针?函数对象(仿函数对象)?也有可能 //是lamber表达式对象?所以这些都是可调用的类型!如此丰富的类型,可能会导致模板的效率低下! //为什么呢?我们继续往下看 template<class F, class T> T useF(F f, T x){ static int count = 0; cout << "count:" << ++count << endl; cout << "count:" << &count << endl; return f(x); } double f(double i){ return i / 2; } struct Functor{ double operator()(double d){ return d / 3; } }; int main(){ // 函数名 cout << useF(f, 11.11) << endl; // 函数对象 cout << useF(Functor(), 11.11) << endl; // lamber表达式 cout << useF([](double d)->double { return d / 4; }, 11.11) << endl; return 0; }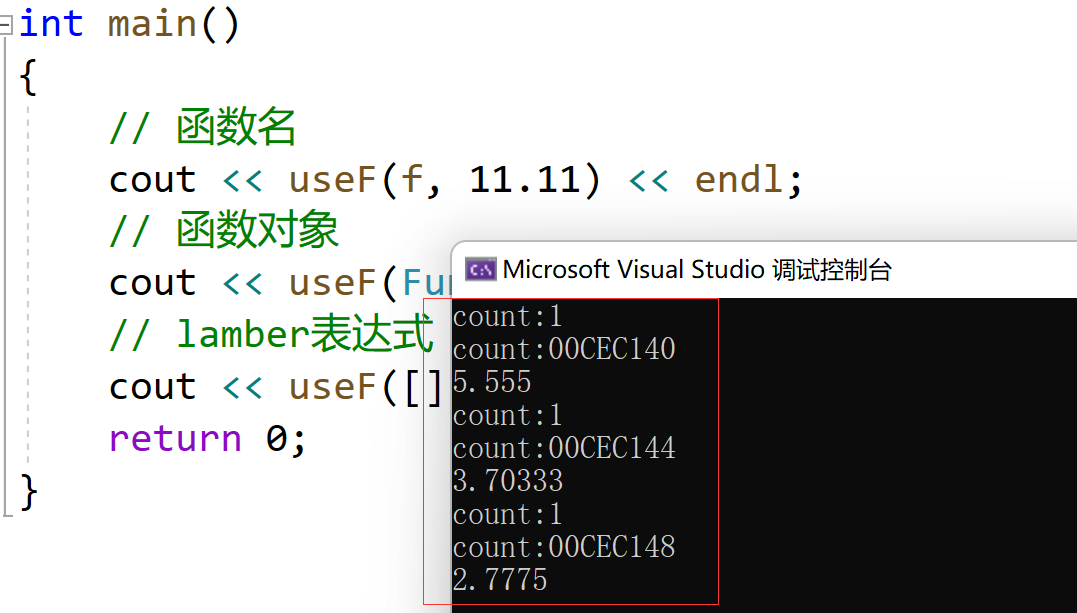
Grâce à la vérification du programme ci-dessus, nous constaterons que le modèle de fonction useF est instancié trois fois.
Le wrapper peut très bien résoudre les problèmes ci-dessus
std::function在头文件<functional> // 类模板原型如下 template <class T> function; // undefined template <class Ret, class... Args> class function<Ret(Args...)>; 模板参数说明: Ret: 被调用函数的返回类型 Args…:被调用函数的形参// 使用方法如下: #include <functional> int f(int a, int b){ return a + b; } struct Functor{ public: int operator() (int a, int b){ return a + b; } }; class Plus{ public: static int plusi(int a, int b){ return a + b; } double plusd(double a, double b){ return a + b; } }; using func_t = std::function<int(int, int)>; int main(){ // 函数名(函数指针) func_t func1 = f; cout << func1(1, 2) << endl; // 函数对象 func_t func2 = Functor(); cout << func2(1, 2) << endl; // lamber表达式 func_t func3 = [](const int a, const int b) { return a + b; }; cout << func3(1, 2) << endl; // 类的成员函数 func_t func4 = &Plus::plusi; cout << func4(1, 2) << endl; std::function<double(Plus, double, double)> func5 = &Plus::plusd; cout << func5(Plus(), 1.1, 2.2) << endl; return 0; } //运行结果 //3 //3 //3 //3 //3.3Avec le wrapper, comment résoudre le problème de la faible efficacité des modèles et des instanciations multiples ?
#include <functional> template<class F, class T> T useF(F f, T x){ static int count = 0; cout << "count:" << ++count << endl; cout << "count:" << &count << endl; return f(x); } double f(double i){ return i / 2; } struct Functor{ double operator()(double d){ return d / 3; } }; int main(){ // 函数名 std::function<double(double)> func1 = f; cout << useF(func1, 11.11) << endl; // 函数对象 std::function<double(double)> func2 = Functor(); cout << useF(func2, 11.11) << endl; // lamber表达式 std::function<double(double)> func3 = [](double d)->double { return d / 4; }; cout << useF(func3, 11.11) << endl; return 0; }
lier
La fonction std::bind est définie dans le fichier d'en-tête et est un modèle de fonction. C'est comme un wrapper de fonction (adaptateur), acceptant un objet appelable (objet appelable) et générant un nouvel objet appelable pour "s'adapter" à l'original liste des paramètres de l'objet. D'une manière générale, nous pouvons l'utiliser pour prendre une fonction fn qui a initialement reçu N paramètres, et renvoyer une nouvelle fonction qui reçoit M paramètres (M peut être supérieur à N, mais cela n'a pas de sens de le faire) en liant certains paramètres . Dans le même temps, la fonction std::bind peut également être utilisée pour ajuster l'ordre des paramètres et d'autres opérations.
// 原型如下: template <class Fn, class... Args> /* unspecified */ bind (Fn&& fn, Args&&... args); // with return type (2) template <class Ret, class Fn, class... Args> /* unspecified */ bind (Fn&& fn, Args&&... args);Considérez la fonction bind comme un adaptateur de fonction générique qui prend un objet appelable et produit un nouvel objet appelable qui « correspond » à la liste d'arguments de l'objet d'origine.
La forme générale d'appel de bind : auto newCallable = bind(callable, arg_list); Parmi eux, newCallable lui-même est un objet appelable et arg_list est une liste de paramètres séparés par des virgules correspondant aux paramètres de l'appelable donné. Lorsque nous appelons newCallable, newCallable appellera callable et lui transmettra les paramètres dans arg_list.
Les paramètres dans arg_list peuvent contenir des noms de la forme _n, où n est un entier. Ces paramètres sont des "espaces réservés" qui représentent les paramètres de newCallable, et ils occupent la "position" des paramètres passés à newCallable. La valeur n représente la position des paramètres dans l'objet appelable généré : _1 est le premier paramètre de newCallable, _2 est le deuxième paramètre, et ainsi de suite.void Print(const char* str, int value) { cout << str << value << endl; } int main() { const char* str = "bind---"; int value = 1; Print(str, value);//正常用法 auto func1 = std::bind(Print, str, std::placeholders::_1);//绑定一个参数 func1(value + 1); auto func2 = std::bind(Print, str, value+2);//绑定两个参数 func2(); return 0; } //运行结果 //bind-- - 1 //bind-- - 2 //bind-- - 3
9. Bibliothèque de fils de discussion
9.1 Une brève introduction à la classe thread
Avant C++11, les problèmes de multithreading étaient liés à la plateforme. Par exemple, Windows et Linux avaient chacun leur propre interface, ce qui rendait le code moins portable. La fonctionnalité la plus importante de C++11 est la prise en charge des threads, de sorte que C++ n'a pas besoin de s'appuyer sur des bibliothèques tierces lors de la programmation en parallèle, et le concept de classes atomiques est également introduit dans les opérations atomiques. Pour utiliser les threads de la bibliothèque standard, le fichier d'en-tête <thread> doit être inclus.
Nom de la fonction Fonction fil de discussion() Construisez un objet thread sans aucune fonction de thread qui lui est associée, c'est-à-dire qu'aucun thread n'est démarré. fil de discussion (fn, args1, args2, …) Construisez un objet thread et associez la fonction thread fn, args1, args2,... comme paramètres de la fonction thread get_id() Obtenir l'identifiant du fil jionable() Que le thread soit toujours en cours d'exécution, joinable représente un thread en cours d'exécution. jion() Une fois cette fonction appelée, le thread sera bloqué. Lorsque le thread se termine, le thread principal continue son exécution. détacher() Appelé immédiatement après la création de l'objet thread, il est utilisé pour séparer le thread créé de l'objet thread, et le thread séparé devient un thread d'arrière-plan, et la "vie et la mort" du thread créé n'a rien à voir avec le thread principal Avis:
Thread est un concept du système d'exploitation. Un objet thread peut être associé à un thread et utilisé pour contrôler le thread et obtenir l'état du thread.
Lorsqu'un objet thread est créé, aucune fonction de thread n'est fournie et l'objet ne correspond réellement à aucun thread.
#include <thread> int main(){ std::thread t1; cout << t1.get_id() << endl; return 0; } //运行结果 //0Le type de valeur de retour de get_id() est le type id. Le type id est en fait une classe encapsulée dans l'espace de noms std::thread. Cette classe contient une structure :
// vs下查看 typedef struct { /* thread identifier for Win32 */ void *_Hnd; /* Win32 HANDLE */ unsigned int _Id; } _Thrd_imp_t;
- Lorsqu'un objet thread est créé et qu'une fonction de thread est associée au thread, le thread est démarré et s'exécute avec le thread principal.
Les fonctions de thread peuvent généralement être fournies des trois manières suivantes :
pointeur de fonction
expression lambda
objet de fonction
#include <thread> #include <windows.h> void ThreadFun(int value){ cout << "thread" << value << endl; } class TF{ public: void operator()(int value){ cout << "thread" << value << endl; } }; int main(){ std::thread t1(ThreadFun, 1); Sleep(1); TF tf; std::thread t2(tf, 2); Sleep(1); std::thread t3([](int value) { cout << "thread" << value << endl; }, 3); t1.join(); t2.join(); t3.join(); cout << "Main thread!" << endl; return 0; } //运行结果 //thread1 //thread2 //thread3 //Main thread!
La classe thread est anti-copie, ne permet pas la construction et l'affectation de copie, mais peut déplacer la construction et déplacer l'affectation, c'est-à-dire transférer l'état d'un thread associé à un objet thread à d'autres objets thread, et n'a pas l'intention d'exécuter le thread pendant le transfert.
Vous pouvez utiliser la fonction jionable() pour déterminer si le thread est valide. Si l'une des situations suivantes se produit, le thread n'est pas valide.
Objet Thread construit à l'aide d'un constructeur sans argument
L'état de l'objet thread a été transféré à d'autres objets thread
Le fil de discussion s'est terminé en appelant jion ou detach.
9.2 Paramètres de la fonction Thread
Les paramètres de la fonction thread sont copiés dans l'espace de la pile de threads sous forme de copie de valeur , donc : même si le paramètre du thread est un type référence, le paramètre externe réel ne peut pas être modifié après avoir été modifié dans le thread, car il fait en fait référence à la copie dans la pile de threads, plutôt qu'aux arguments externes.
#include <thread> void ThreadFunc1(int& x){ x += 10; } void ThreadFunc2(int* x){ *x += 100; } int main(){ int a = 10; // 在线程函数中对a修改,不会影响外部实参,因为:线程函数参数虽然是引用方式,但其实际 //引用的是线程栈中的拷贝 /*thread t1(ThreadFunc1, a); t1.join(); cout << a << endl;*/ //如果想要通过形参改变外部实参时,必须借助std::ref()函数,否则程序会报错(vs2019) thread t2(ThreadFunc1, std::ref(a)); t2.join(); cout << a << endl; // 地址的拷贝 thread t3(ThreadFunc2, &a); t3.join(); cout << a << endl; return 0; } //运行结果 //20 //120Remarque : Si une fonction membre de classe est utilisée comme paramètre de thread, elle doit être utilisée comme paramètre de fonction de thread.
9.4 Bibliothèque d'opérations atomiques (atomique)
Le principal problème du multithreading est le problème causé par les données partagées (c'est-à-dire la sécurité des threads) . Si les données partagées sont en lecture seule, alors pas de problème, car les opérations en lecture seule n'affecteront pas les données, et encore moins ne les modifieront pas, donc tous les threads obtiendront les mêmes données. Cependant, lorsqu'un ou plusieurs threads souhaitent modifier des données partagées, de nombreux problèmes potentiels surviennent . Par exemple:
int sum = 0; void fun(int size){ for (int i = 0; i < size; ++i) { sum++; } } int main(){ cout << "运行之前的sum=" << sum << endl; //分别让两个线程同时对同一个变量sum++ thread t1(fun,100000); thread t2(fun,100000); t1.join(); t2.join(); cout << "运行之后的sum=" << sum << endl; return 0; } //运行结果:sum运行之后的值<=200000La solution traditionnelle en C++98 : les données modifiées partagées peuvent être verrouillées et protégées
#include <mutex> std::mutex mt;//创建一把锁 //分别让两个线程同时对同一个变量sum++ int sum = 0; void fun(int size){ for (int i = 0; i < size; ++i){ mt.lock(); sum++; mt.unlock(); } } int main(){ cout << "运行之前的sum=" << sum << endl; thread t1(fun, 100000); thread t2(fun, 100000); t1.join(); t2.join(); cout << "运行之后的sum=" << sum << endl; return 0; } //运行结果 //运行之前的sum = 0 //运行之后的sum = 200000Bien que le verrouillage puisse être résolu, un inconvénient du verrouillage est que tant qu'un thread traite sum++, les autres threads seront bloqués, ce qui affectera l'efficacité du fonctionnement du programme. De plus, si le verrouillage n'est pas bien contrôlé, il peut facilement provoquer une impasse.
Les opérations atomiques ont donc été introduites en C++11. L'opération dite atomique : c'est-à-dire une ou une série d'opérations qui ne peuvent pas être interrompues. Le type d'opération atomique introduit par C++11 rend la synchronisation des données entre les threads très efficace.
Remarque : lorsque vous devez utiliser les variables d'opération atomiques ci-dessus, vous devez ajouter un fichier d'en-tête
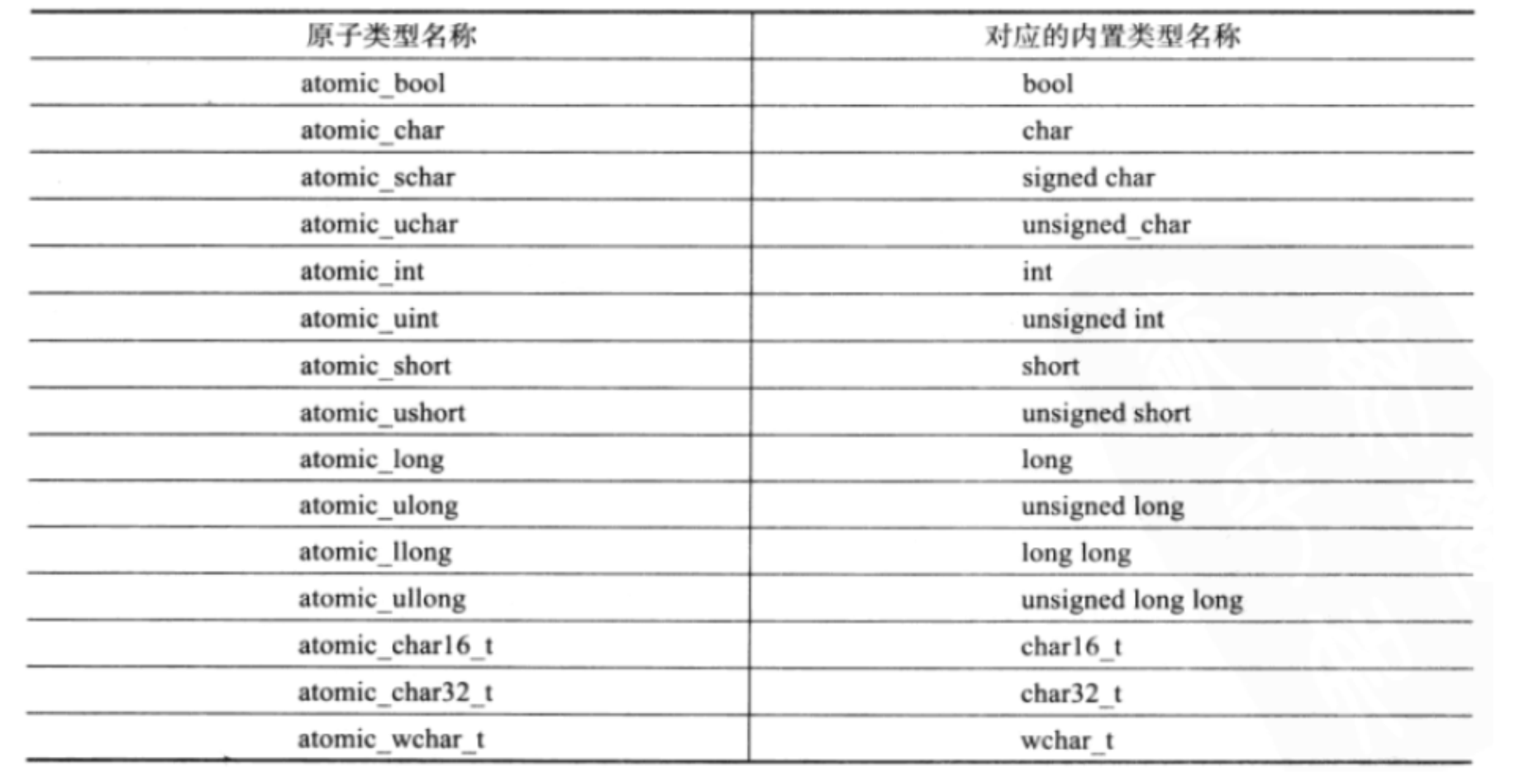
#include <atomic> atomic_int sum = 0; void fun(int size){ for (int i = 0; i < size; ++i){ sum++;// 原子操作 } } int main(){ cout << "运行之前的sum=" << sum << endl; thread t1(fun, 100000); thread t2(fun, 100000); t1.join(); t2.join(); cout << "运行之后的sum=" << sum << endl; return 0; } //运行结果 //运行之前的sum = 0 //运行之后的sum = 200000En C++11, les programmeurs n'ont pas besoin de verrouiller et de déverrouiller les variables de type atomique, et les threads peuvent avoir un accès mutuellement exclusif aux variables de type atomique . Plus généralement, les programmeurs peuvent utiliser le modèle de classe atomique pour définir tout type atomique nécessaire.
atomic<T> t; // 声明一个类型为T的原子类型变量tRemarque : Les types atomiques appartiennent généralement à des données de « ressource », et plusieurs threads ne peuvent accéder qu'à une copie d'un seul type atomique. Par conséquent, en C++ 11, les types atomiques ne peuvent être construits qu'à partir de leurs paramètres de modèle, et les types atomiques ne le sont pas. autorisé à être copié.Construction, construction de déplacement, opérateur =, etc. , afin d'éviter les accidents, la bibliothèque standard a supprimé par défaut la construction de copie, la construction de déplacement et la surcharge de l'opérateur d'affectation dans la classe de modèle atomique .
#include <atomic> int main() { atomic<int> a1(0); //atomic<int> a2(a1); // 编译失败,尝试引用已删除的函数 atomic<int> a2(0); //a2 = a1; // 编译失败,尝试引用已删除的函数 return 0; }
9.5 lock_guard et unique_lock
Dans un environnement multithread, si vous souhaitez garantir la sécurité d'une certaine variable, il vous suffit de la définir sur le type atomique correspondant, ce qui est efficace et non sujet aux problèmes de blocage. Mais dans certains cas, nous pouvons avoir besoin d’assurer la sécurité d’un morceau de code, de sorte qu’il ne puisse être contrôlé qu’au moyen de verrous.
Par exemple : un thread ajoute 100 fois au nombre variable et l'autre soustrait 100 fois. Après que chaque opération ajoute 1 ou soustrait 1, le résultat du nombre est affiché. Condition : la valeur finale du nombre est 0.#include <thread> #include <mutex> int number = 0; mutex g_lock; int ThreadProc1(){ for (int i = 0; i < 100; i++){ g_lock.lock(); ++number; cout << "thread 1 :" << number << endl; g_lock.unlock(); } return 0; } int ThreadProc2(){ for (int i = 0; i < 100; i++){ g_lock.lock(); --number; cout << "thread 2 :" << number << endl; g_lock.unlock(); } return 0; } int main(){ thread t1(ThreadProc1); thread t2(ThreadProc2); t1.join(); t2.join(); cout << "number:" << number << endl; return 0; }Défauts du code ci-dessus : Lorsque le verrou n'est pas bien contrôlé, cela peut provoquer un blocage . Les plus courants sont le retour du code au milieu du verrou, ou une exception est levée dans la portée du verrou . Par conséquent : C++11 utilise RAII pour encapsuler les verrous, à savoir lock_guard et unique_lock.
int ThreadProc1() { for (int i = 0; i < 100; i++) { //lock_guard<mutex> lock(g_lock); unique_lock<mutex> lock(g_lock); ++number; cout << "thread 1 :" << number << endl; } return 0; } int ThreadProc2() { for (int i = 0; i < 100; i++) { //lock_guard<mutex> lock(g_lock); unique_lock<mutex> lock(g_lock); --number; cout << "thread 2 :" << number << endl; } return 0; }
9.5.1 Types de mutex
9.5.1 Types de mutex
- std::mutex
est le mutex le plus basique fourni par C++ 11. Les objets de cette classe ne peuvent pas être copiés ou déplacés. Les trois fonctions les plus couramment utilisées du mutex
:
Nom de la fonction fonction fonction verrouillage() lock : verrouille le mutex ouvrir() unlock : libérer la propriété du mutex try_lock() Essayez de verrouiller le mutex. Si le mutex est occupé par un autre thread, le thread actuel ne sera pas bloqué. Notez que lorsque la fonction thread appelle lock(), les trois situations suivantes peuvent se produire :
Si le mutex n'est pas actuellement verrouillé, le thread appelant verrouille le mutex et maintient le verrou jusqu'à ce que unlock soit appelé.
Si le mutex actuel est verrouillé par un autre thread, le thread appelant actuel est bloqué
Si le mutex actuel est verrouillé par le thread appelant actuel, un blocage se produira.
Lorsqu'une fonction de thread appelle try_lock(), les trois situations suivantes peuvent se produire :
Si le mutex actuel n'est pas occupé par d'autres threads, le thread verrouille le mutex jusqu'à ce que le thread appelle unlock pour libérer le mutex.
Si le mutex actuel est verrouillé par un autre thread, le thread appelant actuel renvoie false et ne sera pas bloqué.
std::recursive_mutex (mutex récursif)
Il permet au même thread de verrouiller le mutex plusieurs fois (c'est-à-dire de le verrouiller de manière récursive) pour obtenir plusieurs couches de propriété de l'objet mutex. Lors de la libération du mutex, il doit appeler unlock() le même nombre de fois que la hiérarchie de verrouillage. deep , sauf que les caractéristiques de std::recursive_mutex sont à peu près les mêmes que celles de std::mutex.
std :: timed_mutex
Il existe deux fonctions membres de plus que std::mutex, try_lock_for() et try_lock_until().
try_lock_for()
accepte une plage de temps, ce qui signifie que le thread sera bloqué s'il n'acquiert pas le verrou dans ce laps de temps (différent de try_lock() de std::mutex, try_lock renvoie directement false si le verrou n'est pas acquis lorsqu'il est appelé), si d'autres threads libèrent le verrou pendant cette période, le thread peut acquérir le verrou sur le mutex, et s'il expire (c'est-à-dire que le verrou n'est pas acquis dans le délai spécifié), il renvoie false.try_lock_until()
accepte un point temporel comme paramètre. Si le thread n'acquiert pas le verrou avant l'arrivée du point temporel spécifié, il sera bloqué. Si d'autres threads libèrent le verrou pendant cette période, le thread peut acquérir le verrou sur le mutex . Si Timeout (c'est-à-dire que le verrou n'est pas obtenu dans le délai spécifié), alors false est renvoyé.std :: récursive_timed_mutex
9.5.2 lock_guard
std::lock_gurad est une classe de modèle définie en C++11. La définition est la suivante :
template<class _Mutex> class lock_guard { public: // 在构造lock_gard时,_Mtx还没有被上锁 explicit lock_guard(_Mutex& _Mtx) : _MyMutex(_Mtx) { _MyMutex.lock(); } // 在构造lock_gard时,_Mtx已经被上锁,此处不需要再上锁 lock_guard(_Mutex& _Mtx, adopt_lock_t) : _MyMutex(_Mtx) { } ~lock_guard() _NOEXCEPT { _MyMutex.unlock(); } lock_guard(const lock_guard&) = delete; lock_guard& operator=(const lock_guard&) = delete; private: _Mutex& _MyMutex; };Comme le montre le code ci-dessus, le modèle de classe lock_guard encapsule principalement le mutex qu'il gère via RAII. Lorsqu'un verrou doit être ajouté, il vous suffit d' instancier un lock_guard avec n'importe quel mutex introduit ci-dessus .
L'inconvénient de lock_guard est qu'il est trop simple et que les utilisateurs n'ont aucun moyen de contrôler le verrou , donc C++11 fournit unique_lock.
9.5.3 verrouillage_unique
Semblable à lock_gard, le modèle de classe unique_lock utilise également RAII pour encapsuler le verrou et gère également les opérations de verrouillage et de déverrouillage des objets mutex de manière exclusive, c'est-à-dire qu'aucune copie entre objets ne peut se produire . Lors de la construction (ou du déplacement (déplacement) de l'affectation), l'objet unique_lock doit passer un objet Mutex comme paramètre, et l'objet unique_lock nouvellement créé est responsable des opérations de verrouillage et de déverrouillage de l'objet Mutex entrant. Lorsque vous utilisez les types de mutex ci-dessus pour instancier un objet unique_lock, le constructeur est automatiquement appelé pour le verrouiller, et lorsque l'objet unique_lock est détruit, le destructeur est automatiquement appelé pour le déverrouiller, ce qui peut facilement éviter les problèmes de blocage .
Différent de lock_guard, unique_lock est plus flexible et fournit plus de fonctions membres :
Opérations de verrouillage/déverrouillage : lock, try_lock, try_lock_for, try_lock_until et unlock
Opérations de modification : déplacement d'affectation, échange (swap : échange de propriété du mutex géré par un autre objet unique_lock), release (release : renvoie un pointeur vers l'objet mutex qu'il gère, et libération de propriété)
Récupérer les attributs : owns_lock (renvoie si l'objet courant est verrouillé), Operator bool() (même fonction que owns_lock()), mutex (renvoie le pointeur vers le mutex géré par le unique_lock actuel).
9.6 Variables de condition
Documentation pour les variables de condition
Cette section démontre principalement l'utilisation de condition_variable
Exemple : prend en charge deux threads pour imprimer alternativement, l'un imprime les nombres impairs et l'autre les nombres pairs.
#include <iostream> #include <thread> #include <condition_variable> using namespace std; int main(){ mutex mtx; std::condition_variable con;//条件变量 int i = 1; int flag = true; //打印奇数 thread t1([&] { while (i < 100){ unique_lock<mutex> lock(mtx); while (!flag)con.wait(lock);//这里必须是while,不能用if cout <<"t1----" <<this_thread::get_id()<<"-----" << i++ << endl; flag = false; con.notify_one();//通知另一个线程 } }); //打印偶数 thread t2([&] { while (i<=100){ unique_lock<mutex> lock(mtx); while(flag)con.wait(lock); cout << "t2----" << this_thread::get_id() << "-----" << i++ << endl; flag = true; con.notify_one();//通知另一个线程 } }); t1.join(); t2.join(); return 0; }