
Thank you for reading the "Generative AI Industry Solution Guide" series of blogs. The whole series is divided into 4 articles. It will systematically introduce the generative AI solution guide and its typical scenarios in e-commerce, games, and pan-entertainment industries. application practice. The directory is as follows:
"Generative AI Industry Solution Guide and Deployment Guide"
"Application Scenario Practice of Generative AI in Pan-Entertainment Industry – Facilitating Stylized Video Content Creation" (this article)
background introduction
Since 2022, generative AI has developed rapidly, especially in the field of Vincent graphs. With the diffusion model as the mainstay and the support of other models, new Vincent graphs and graph-generated graph technologies have emerged in an endless stream. It has been widely used in the field of media and entertainment. The main scenarios are: 1. Scene script illustration; 2. Comic creation; 3. Concept map generation. And with the advancement of technology, a relatively complete tool chain has been formed.
Despite the impressive capabilities of diffusion models and their applications in generating images, the field of video generation has lagged behind. The main reasons are: there is no high-quality training set; there is no way to describe the video well; the training of the generative video model requires extremely high computing power.
So now the mainstream method of using the diffusion model to generate video is: use template video, disassemble it into video frame pictures, use various plug-ins to stylize frame by frame according to prompt words and picture features, and finally combine them into stylized video.
In this article, based on the generative AI industry solution guide, we aim at stylized video generation in the pan-entertainment industry, introduce the use and parameter configuration of generative AI, and cooperate with traditional tools to assist content creation and achieve certain creativity Effect.
Generative AI in video creation in pan-entertainment industry
In the pan-entertainment industry, short videos are the most popular form of content expression, which is characterized by low production costs and high transmission rates. The traditional ways of generating short videos include UGC mode and PGC mode. Although their production cycle and production cost are much lower than traditional media, they still cannot be separated from "planning-script-lines-casting-rehearsal-formal performance-recording" -check-edit-post-review-publish" these basic steps. In general, the average production time for a short video of about 5 minutes is about 2-3 days. The emergence of generative AI can greatly improve production efficiency, shorten the production cycle, and even simplify the production steps.
Now there are ways to generate stylized pictures and stylized videos. According to some existing pictures and videos, or videos taken in the early stage, directly enter the later steps. Stylization is an attempt to generate short videos. Although such videos still have problems such as flickering and jumping, the effect is getting better and better through the continuous progress of the community. Of course, this type of video itself has a high degree of freedom and strong creative attributes, so it has strong topicality and communication.
The mainstream method of producing stylized video is to use continuous stylized pictures as a series of video frames concatenated. include:
1) Extract each frame from the original video, generate a picture frame by frame through prompt words, and finally reassemble the pictures to generate a stylized video;
2) Generate several creative pictures as key frames, similar pictures as transition frames, and assemble them into a stylized video.
These two kinds of stylized videos can be realized through Stable Diffusion WebUI plug-ins. However, these two stylized video production methods still have certain problems that need to be solved, respectively:
1) Template video shooting still requires a certain amount of investment, including arrangement, performance, and copyright issues of the original video, etc.;
2) The subject of a stylized video is difficult to define.
This paper presents two ways to generate combined stylized videos, which can make full use of the current stylized video plug-ins and partially solve the above-mentioned problems in stylized video production:
A method of generating stylized video using the dynamic picture of the 3D model as a blueprint
A method to generate a stylized video with a certain theme using a short ordinary video as a starting point (or an intermediate node)
Architecture and working principle
This article is based on the generative AI industry solution guide, and its working principle is as follows:
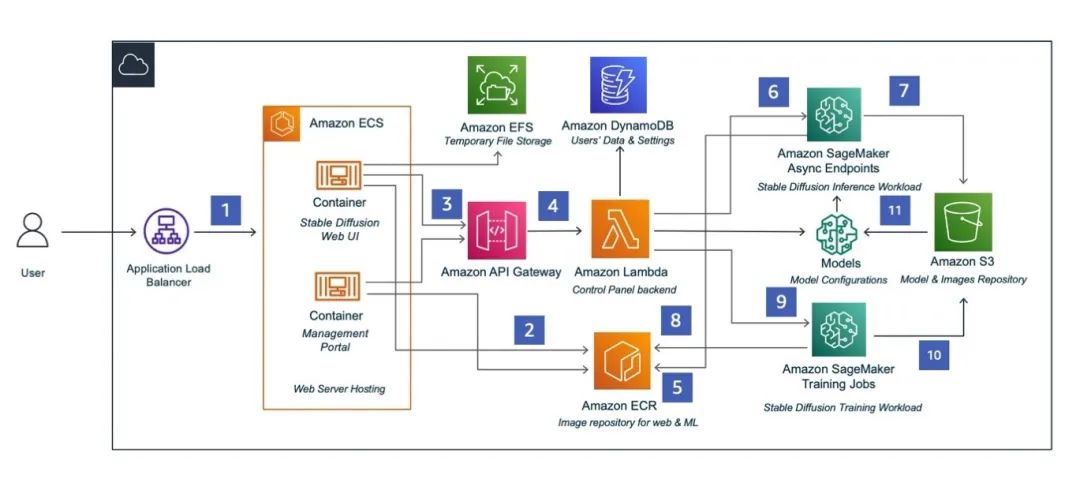
Generative AI industry solution guide, the front-end Stable Diffusion WebUI is deployed on the container service Amazon ECS, the back-end uses the serverless service Amazon Lambda for processing, and the front-end and back-end communicate through Amazon API Gateway calls. Model training and deployment are performed through Amazon SageMaker. At the same time, Amazon S3, Amazon EFS, and Amazon DynamoDB are used to store model data, temporary files, and usage data respectively. For the rapid deployment process, please refer to the first article of this series of blogs, and this article will not repeat them.
3D model as model to produce stylized video
First of all, let's understand the basic principle of converting the original video to a stylized video, as shown in the following figure:
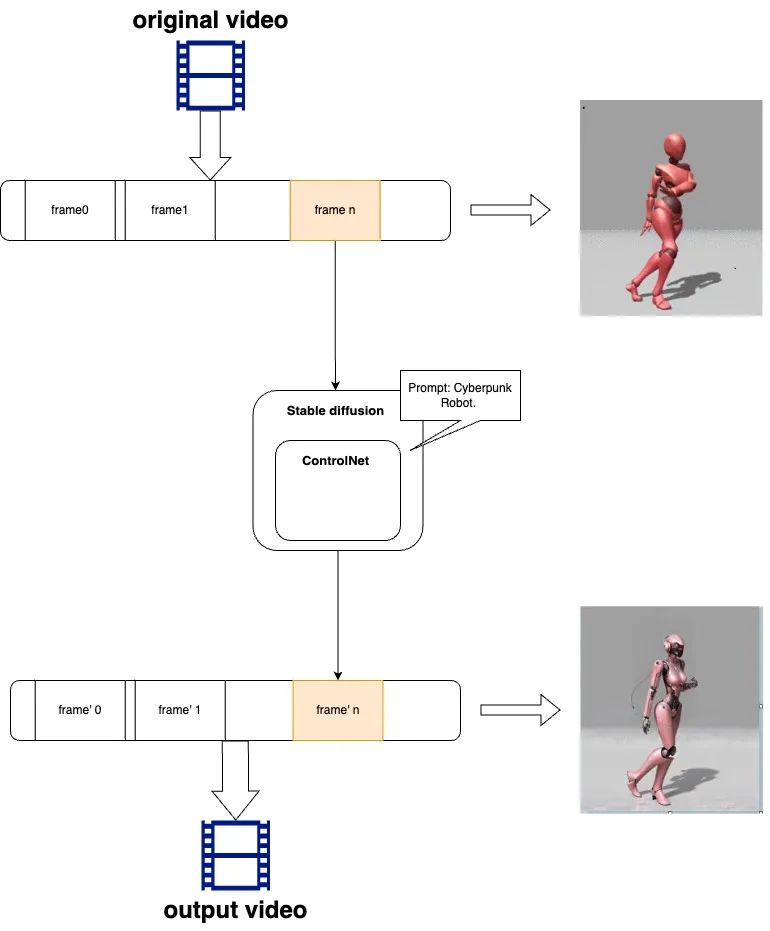
The reference steps are:
The original video is disassembled into a sequence of video frames
Stylize with Stable Diffusion for each frame, and use ControlNet to control the silhouette and pose of the character
Reassemble the generated new sequence frames into a video
From the perspective of video generation, the original video is only used to stylize the outline or action of the video, and the cost of using the original video shot by real people or real scenes is still relatively high; we might as well use some low-cost 3D models, such as only outlines and no textures , a color palette, a model with a very low face count, used as a blueprint for video generation. Here is an example: generate a cyberpunk girl dancing samba , which is different from general video stylization. In this example, the dance moves are more complicated, and the original video without copyright is used as a template. Then we can take the following specific steps:
1. Import the low-cost character model into Blender or Unity3D, and generate samba dance animation. Here we choose to download a model component of a character dancing from the mixamo.com website, and convert it to the original video as follows:

Build the basic WebUI environment and import the model. After deploying according to the generative AI solution guide, you can operate:
2. Import the video and enter prompt words
use prompt words
Hyper realistic painting of a beautiful girl in a cyberpunk plugsuit, hyper detaled ,anime trending on artstation with mask (masterpiece:1.4), (best quality:1.2), (ultra highres:1.2) ,(8k resolution:1.0)
reverse cue word
text, letters, logo, brand, close up, cropped, out of frame, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck
3. Perform video stylization and open the Mov2Mov plug-in. The recommended parameters here are as follows:
Sample steps=20-30,
Generate movie mode=XVID,
CFG scale=7-10,
Denoising strength=0.2-0.3,
Movie frames=30,
Maxframe=60-90,
Controlnet 选择enabled,
Control weight 0.2-0.25。
After clicking Generate, the comparison between the obtained video and the original video is as follows:



Stylized Videos with Themes
The Stable Diffusion community has a wealth of stylized video generation plug-ins, among which Deforum is one of the most popular plug-ins. Its principle is to determine the key frames on the timeline and use the creative images generated by clear Prompt, and the transition video frames between key frames adopt progressive combined with a certain 2D and 3D space rotation to produce a unique effect. The prompt words in this way are generally in the form of a script. The principle is shown in the figure:
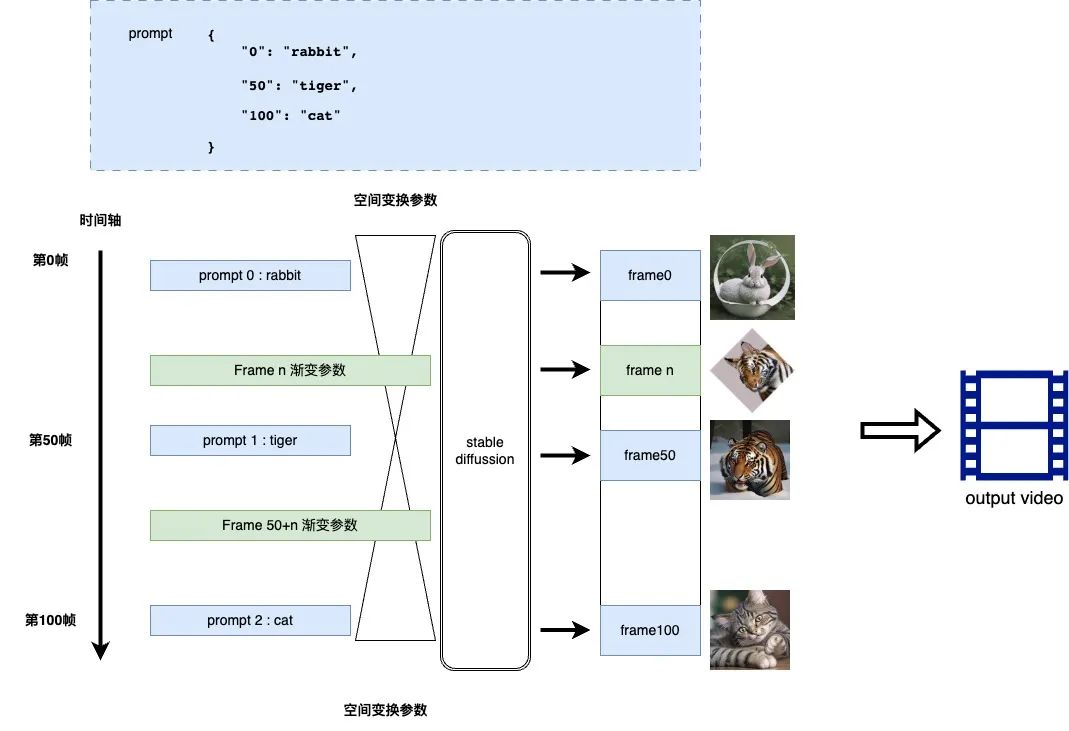
From the perspective of stylized video or creative video, through conversion of a certain script into a prompt, and then through Deforum series, the effect of a creative video expressing a certain theme can be achieved. From the perspective of production, there are still two difficulties:
It is difficult to connect realistic themes and creative videos by writing scripts out of thin air;
Creative video/stylized video effects are still connected by creative pictures, so it is difficult to control the effect, and video generation consumes much more computing power than image generation, resulting in waste of video and waste of computing power.
So here we might as well create with a simple way of cross-resonance between real video and creative video. The real video here may only need 2-3 seconds of mobile phone shooting video, and it can be used as the starting video. Here is an example: The author visited a Syrian cultural relics exhibition in a provincial museum, and suddenly felt emotional. I wanted to make a stylized short video of tens of seconds to express my feelings about the millennium changes when watching cultural relics . We can take the following specific steps:
1. Take a selfie video of 3-5 minutes, representing the initial theme, as the initial video. Since the goal is to post the creative video on social media, it needs to adapt to the size of the mobile phone, so the video resolution is 540*960
2. Prepare the basic environment of the Web UI, including models and plug-ins
3. Set a certain frame of the initial video as the initial frame, here we capture the last frame as the initial frame, the image resolution is 540*960, and set the initial frame in Deforum, select Use init in the init tab, and fill in the file address
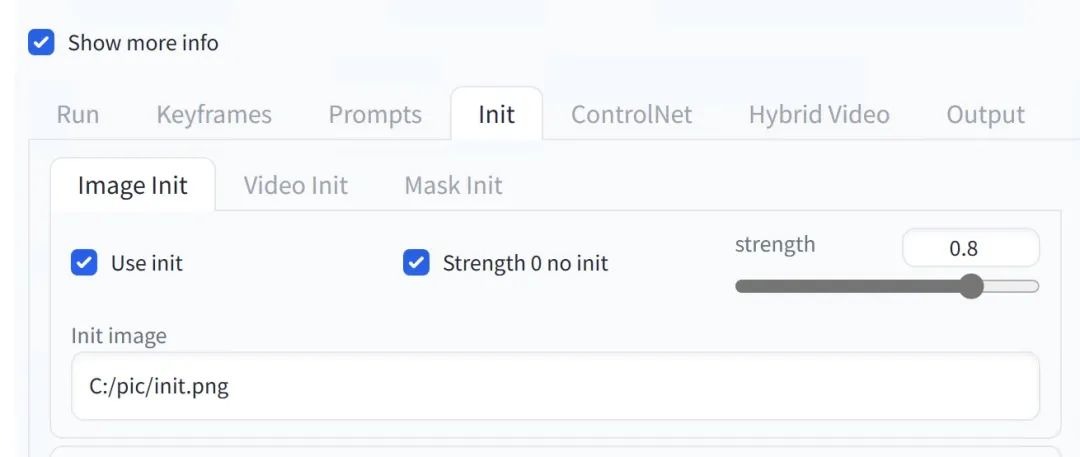
4. Set the prompt word and set the rotation parameter. Here is a list of parameters and recommended values in the following table
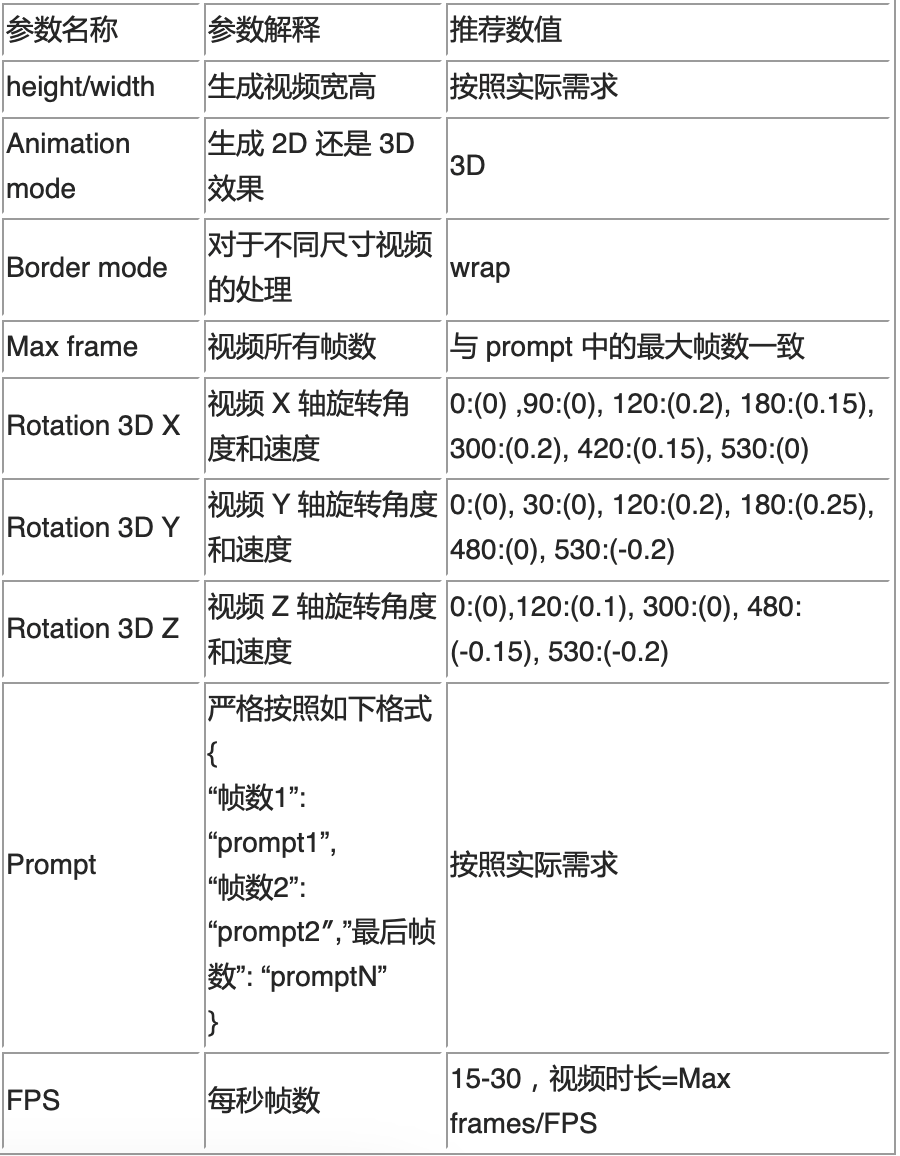
5. Arrange appropriate stylized prompts and generate a video. The prompts must be in JSON format. Based on this rule, arrange the plot of the video
The prompt words are as follows:
{
“0”: “A Warrior in desolate landscape in Syria, with cracked earth, under a dark and stormy sky, Picasso style”,
“50”: ” sunshine from the earth, ancient relics and mysterious symbols in Syria, Picasso style “,
“150”: “Egypt style building in Syria , Picasso style “,
“200”: “Rome style city with people from different races and cultures mingle and trade in the streets, markets in Syria, Picasso style “,
“250”: ” war between nations east and west of Syria, the kings are seeking to preserve the balance of nature and magic, the other wanting to exploit it for power and profit, Picasso style “,
“300”: “gun smoke and flowers ,generals speech, Picasso style “,
“450”: “bomb explosion on the sky, fires ,flames and smoke, blood and ashes , Picasso style -neg magnificent”,
“500”: “fate of people in the nation, peaceful hope, Picasso style”
}
Reverse cue words:
NSFW, worst quality, low quality, ugly, duplicate, morbid, mutilated, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck
6. Use the editing software to connect the real video and the creative video end-to-end to get a complete video. The reference is as follows:
Summarize
In this article, we briefly introduce the video content production scenarios in the pan-entertainment industry. Through the cooperation of different plug-ins and tools, the goal of generating stylized and creative videos can be achieved. Of course, this is just the tip of the iceberg. In the application of the pan-entertainment industry, by constantly tracking new plug-ins and models, we can achieve continuous innovation of pan-entertainment content according to technical iterations. At the same time, we can combine it with some standard media production tools. Continuous optimization to achieve the goal of efficiently producing creative content.
References
1. Generative AI Industry Solution Guide:
https://aws.amazon.com/cn/campaigns/aigc/
2. Generative AI Industry Solution Guide Workshop:
https://catalog.us-east-1.prod.workshops.aws/workshops/bae25a1f-1a1d-4f3e-996e-6402a9ab8faa
3. Stable-diffusion-webui:
https://github.com/AUTOMATIC1111/stable-diffusion-webui
4. Hugging Face:
https://huggingface.co/
The author of this article

Ming Qi
Amazon cloud technology industry solution architect, mainly responsible for media industry-related technical solutions, and is committed to the construction and promotion of innovative technologies and customer experience-related solutions in the pan-entertainment industry, including virtual reality, mixed reality, generative AI, digital In the direction of Ren et al., he has many years of experience in architecture design and product development.

white crane
Professor-level senior engineer, senior solution architect of Amazon cloud technology media industry, focusing on architecture design of converged media systems, content production platforms, ultra-high-definition encoding cloud native capabilities, etc., has rich experience in many fields around media digital transformation Experience.

Tang Zhe
Amazon cloud technology industry solution architect, responsible for the consulting and architecture design of cloud computing solutions based on Amazon Website Service, and is committed to the dissemination and popularization of Amazon cloud service knowledge system. He has practical experience in software development, security protection and other fields, and is currently focusing on the fields of e-commerce and live broadcast.


I heard, click the 4 buttons below
You will not encounter bugs!
