Liepin Big Data Research Institute released the "2022 Future Talent Employment Trend Report"
Judging from the ranking, the average annual salary of mid-to-high-end talents in various industries from January to April 2022, the average annual salary of mid-to-high-end talents in the artificial intelligence industry is the highest, at 310,400 yuan; the average annual salary of mid-to-high-end talents in the financial industry is 276,900 yuan. Second; the average annual salary of mid-to-high-end talents in the communication and big data industries is 275,100 yuan and 252,300 yuan, ranking third and fourth; the average annual salary of mid-to-high-end talents in the IT/Internet industry is 230,200 yuan, ranking seventh.
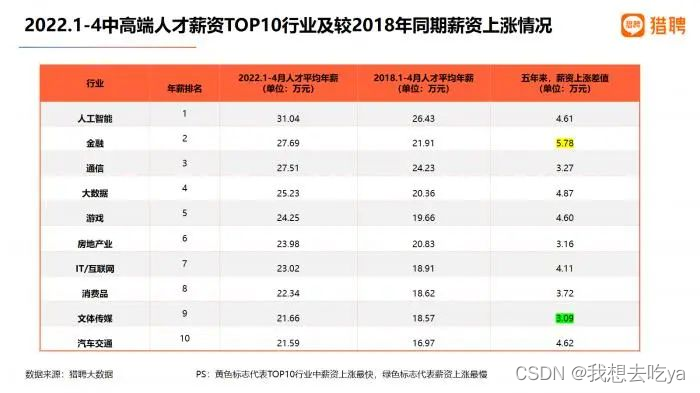
Chart source: "2022 Future Talent Employment Trend Report"
If you feel high, being averaged like this? Then open Boss direct employment, search for big data engineers:
let's do data analysis:
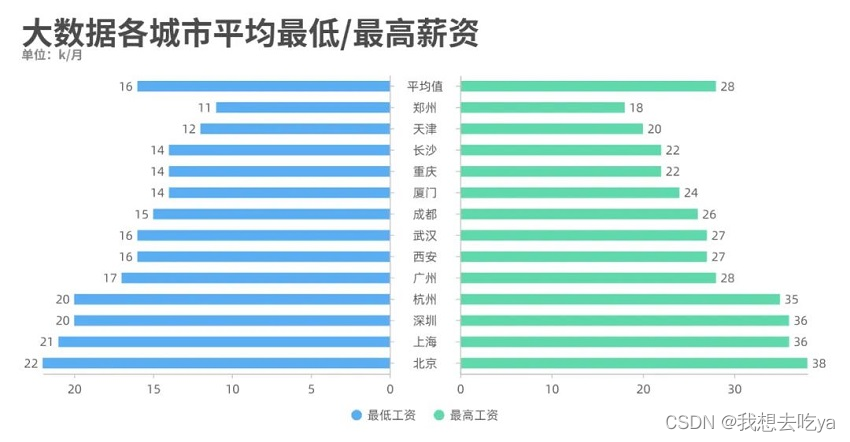
The salary column has a minimum salary and a maximum salary. We compared and analyzed different cities and found that Beijing has the highest salary level, with the lowest being 22k and the highest being 38k.
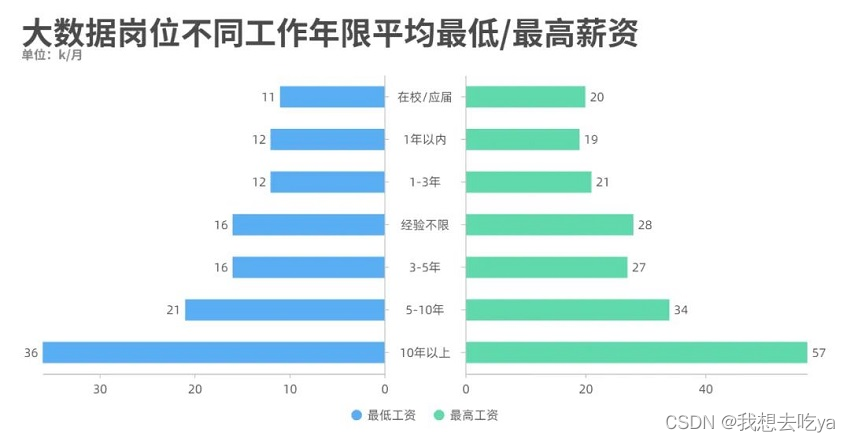
Working years are also a big factor that restricts salary levels. It can be seen from the figure that even if you have just graduated, you can reach a salary range of 11-20k.
As far as educational requirements are concerned, most of them are undergraduates, followed by junior colleges and masters, and others are so few that they are not shown in the figure. 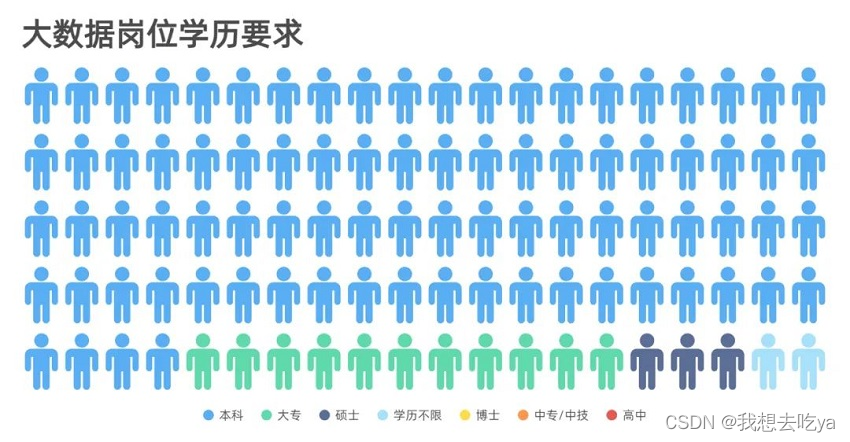
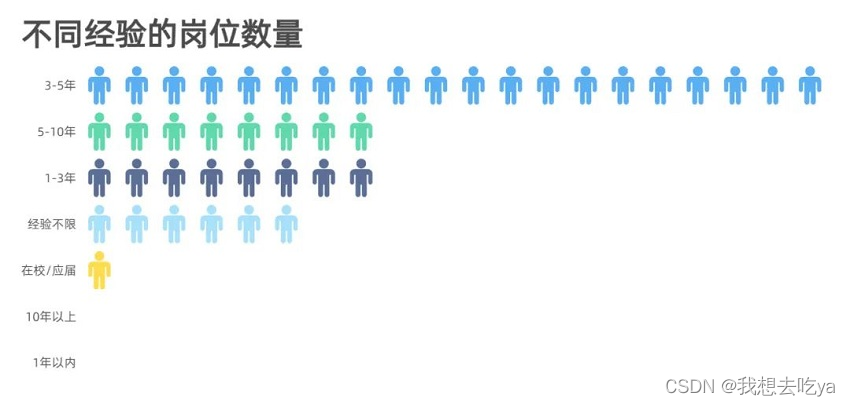
Most of the requirements of enterprises for different positions are 3-5 years. Of course, enterprises need employees with certain work experience, but in actual recruitment, if you have project experience and good theoretical knowledge, enterprises will relax the conditions.
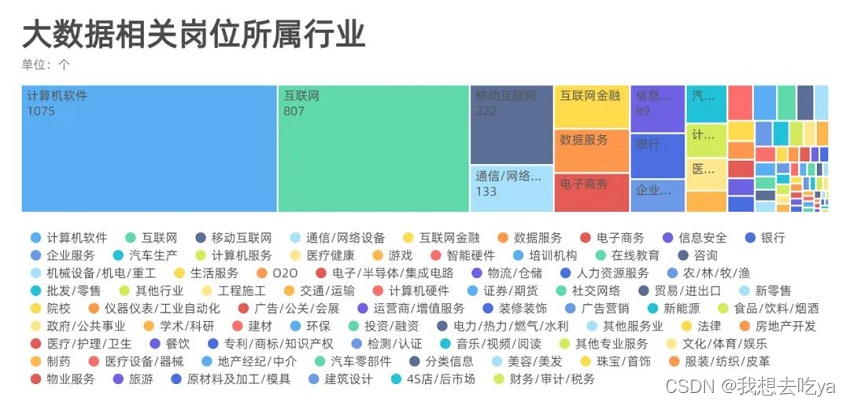
Analyzing different industries, we found that the demand for big data jobs is distributed in all walks of life, mainly in computer software and the Internet. It may also be determined by this recruitment software. After all, Boss direct employment is still mainly in the Internet industry.
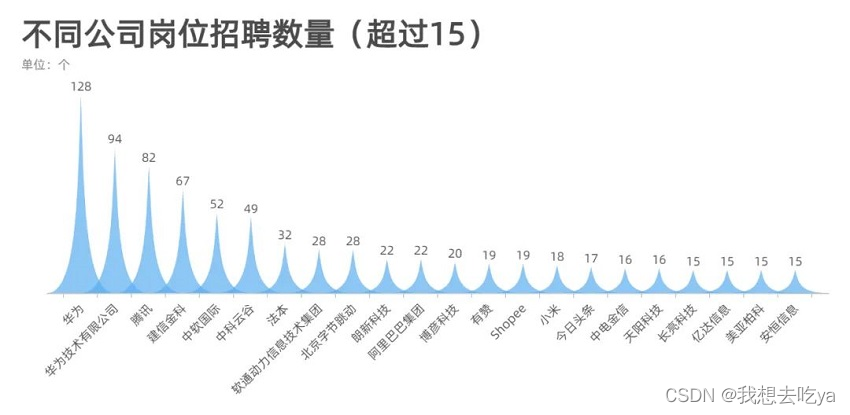
Let's take a look at which companies are recruiting for big data-related positions. Judging from the number of more than 15, Huawei, Tencent, Ali, Byte, these big companies still have a large demand for this position.
So what skills do these jobs require? Spark, Hadoop, Data Warehouse, Python, SQL, Mapreduce, Hbase, etc.

According to the domestic development situation, the future development prospects of big data will be very good. Since enterprises have started digital transformation in 2018, the demand for talents in the field of big data in first- and second-tier cities is very strong. In the next few years, the demand for talents in third- and fourth-tier cities will also increase significantly.
In the field of big data, domestic development is relatively late. Since 2016, only more than 200 universities have opened majors related to big data, which means that the first batch of graduates in 2020 have just entered the society. There is an urgent need for big data talents but insufficient talents, so there will be many employment opportunities in the big data field in the future.
High salaries and large gaps naturally become the "salary" choice for professionals in the workplace!
Any learning process requires a scientific and reasonable learning route in order to be able to complete our learning goals in an orderly manner. The content required to learn Python+big data is complex and difficult. We have compiled a comprehensive Python+big data learning roadmap for you to help you clarify your thinking and overcome difficulties!
Detailed introduction to Python+big data learning roadmap
Getting Started with Big Data Development in Phase 1
Pre-study guide: Start with traditional relational databases, master data migration tools, BI data visualization tools, and SQL, and lay a solid foundation for subsequent learning.
1. Big data data development foundation MySQL8.0 from entry to proficiency
MySQL is the entire IT basic course, and SQL runs through the entire IT life. As the saying goes, if SQL is well written, you can find a job easily. This course fully explains MySQL8.0 from zero to advanced level. After studying this course, you can have the SQL level required for basic development.
The core foundation of big data in the second stage
Pre-study guide: learn Linux, Hadoop, Hive, and master the basic technology of big data.
2022 Big Data Hadoop Introductory Tutorial
Hadoop Offline is the core and cornerstone of the big data ecosystem, an introduction to the entire big data development, and a course that lays a solid foundation for the later Spark and Flink. After mastering the three parts of the course: Linux, Hadoop, and Hive, you can independently realize the development of visual reports for offline data analysis based on the data warehouse.
The third stage of hundreds of billions of data warehouse technology
Pre-study guide: The course at this stage is driven by real projects, learning offline data warehouse technology.
Data offline data warehouse, enterprise-level online education project practice (complete process of Hive data warehouse project)
This course will establish a group data warehouse, unify the group data center, and centralize the storage and processing of scattered business data; the purpose is from demand research, design, Version control, R&D, testing, and launch, covering the complete process of the project; digging and analyzing massive user behavior data, customizing multi-dimensional data sets, and forming a data mart for use in various scene themes.
The fourth stage PB memory computing
Pre-study guide: Spark has officially adopted Python as the first language on its homepage. In the update of version 3.2, it highlights the built-in bundled Pandas; Spark content.
1. From entry to mastery of python (19 days)
Python basic learning courses, from building the environment. Judgment statements, and then to the basic data types, and then learn and master the functions, familiarize yourself with file operations, initially build an object-oriented programming idea, and finally lead students into the palace of python programming with a case.
2. Python programming advanced from zero to website building
After completing this course, you will master advanced Python syntax, multi-tasking programming, and network programming.
3.spark3.2 from basic to proficient
Spark is the star product of the big data system. It is a high-performance distributed memory iterative computing framework that can handle massive amounts of data. This course is developed based on Python language learning Spark3.2. The explanation of the course focuses on integrating theory with practice, which is efficient, fast, and easy to understand, so that beginners can quickly master it. Let experienced engineers also gain something.
4. Big data Hive+Spark offline data warehouse industrial project actual combat
Through the big data technology architecture, it solves the data storage and analysis, visualization, and personalized recommendation problems in the industrial Internet of Things manufacturing industry. The one-stop manufacturing project is mainly based on the Hive data warehouse layer to store the data of various business indicators, and based on sparkSQL for data analysis. The core business involves operators, call centers, work orders, gas stations, and warehousing materials.