Artificial intelligence data labeling is the process of labeling metadata such as text, video, and images, and the labeled data will be used to train machine learning models. Common data annotation types include text annotation, semantic segmentation, and image and video annotation. These labeled training data sets can be used to train artificial intelligence application scenarios such as autonomous driving, chat robots, translation systems, intelligent customer service, and search engines. In this article, we'll explore six different types of data annotation and their most common uses in machine learning.
What is artificial intelligence data annotation?
Data labeling is the process of adding metadata to a training dataset. This metadata usually takes the form of tags and can be added to any type of data, including text, images, and video. Adding high-quality and accurate labels is a critical process in developing training datasets for machine learning. AI data labeling is an integral stage in data preprocessing because supervised machine learning models can learn to recognize recurring patterns in labeled data. When an algorithm has processed a large amount of labeled data, the algorithm can recognize the same patterns when new, unlabeled data emerges. Therefore, data scientists need to use cleaned labeled data to train machine learning models.
Types of data annotation
Different data annotation types are suitable for different annotation scenarios, and different annotation scenarios are also aimed at different AI application scenarios. Next, we will introduce some of the more common annotation types, which are suitable for common annotation scenarios. For you who are new to data annotation, read the following annotation types to get you started with data annotation:
semantic annotation
Semantic annotation is the task of labeling various concepts in text, such as people, objects, or company names. Machine learning models use semantically annotated data to learn how to classify new concepts in new text. This can help improve search relevance and train chatbots.
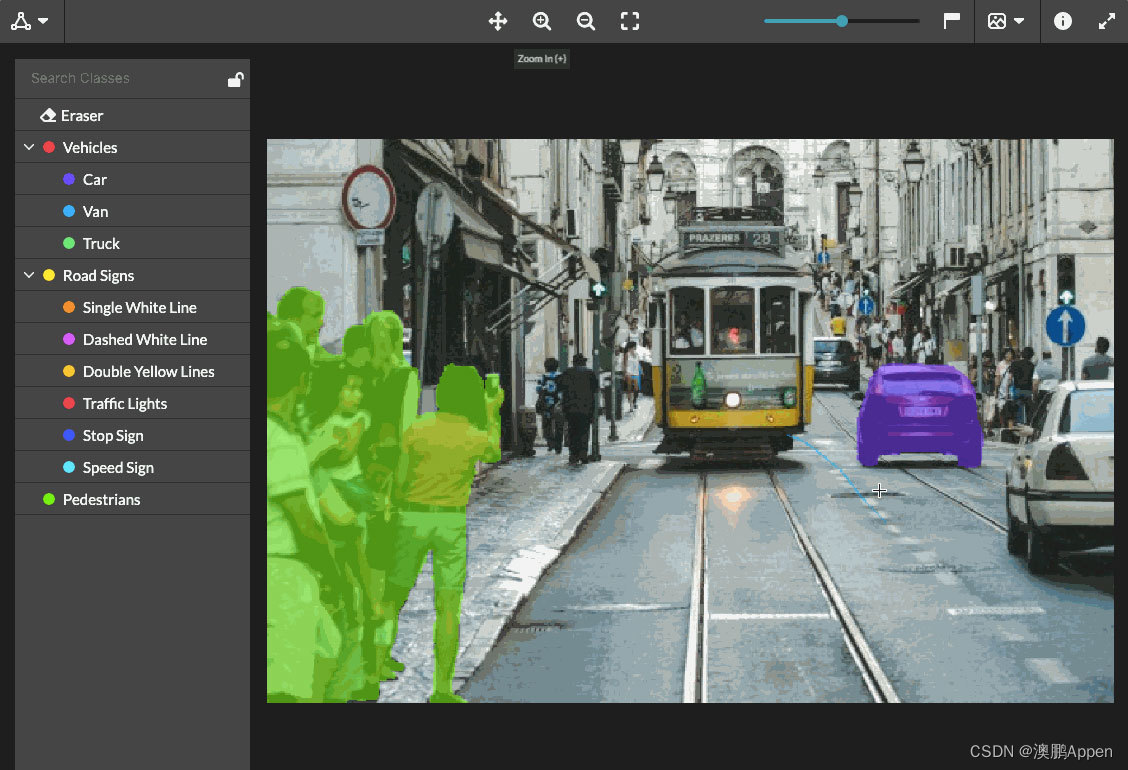
Image and Video Annotation
You must have wondered, why can a car be driverless? Why can two twins unlock each other's phones? This is the concept of computer vision that you may have heard of , and enabling machines to have "vision" is inseparable from the training of image annotation data. There are many forms of image annotation, from drawing frames (also known as bounding boxes) to images, to semantic segmentation, and each pixel in the image is given a meaning. This label often helps the machine learning model recognize the labeled region as a different type of object. This type of data is often used as the ground truth for image recognition models that can identify and mask sensitive content, guide autonomous vehicles, or perform facial recognition tasks. For more information on image annotation, please check the article: How to use image annotation to build AI? ![]() https://www.appen.com.cn/blog/what-is-image-annotation-and-how-is-it-used-to-build-ai-models/ Similar to image annotation, video annotation usually involves Add bounding boxes, polygons, or keypoints to content. This can be done on a frame-by-frame basis, and the frames are then stitched together to help track the motion of the annotated object, or using video annotation tools directly on the video itself. This type of data also plays a vital role in developing computer vision models, for example for tasks such as object tracking and localization. For more information about video annotation, please check the article: What is video annotation? How is it different from image annotation?
https://www.appen.com.cn/blog/what-is-image-annotation-and-how-is-it-used-to-build-ai-models/ Similar to image annotation, video annotation usually involves Add bounding boxes, polygons, or keypoints to content. This can be done on a frame-by-frame basis, and the frames are then stitched together to help track the motion of the annotated object, or using video annotation tools directly on the video itself. This type of data also plays a vital role in developing computer vision models, for example for tasks such as object tracking and localization. For more information about video annotation, please check the article: What is video annotation? How is it different from image annotation? ![]() https://www.appen.com.cn/blog/video-annotation-what-is-it-and-how-automation-can-help/
https://www.appen.com.cn/blog/video-annotation-what-is-it-and-how-automation-can-help/
Text Categorization
Text classification and content classification refer to the task of assigning predefined categories to documents. For example, you can tag sentences or paragraphs in a document by topic, or organize news articles by topics such as national, international, sports, or entertainment. As the ability of machines to interpret human language continues to improve, the importance of using high-quality text data for training becomes more and more indisputable. In any case, preparing accurate training data must start with accurate and comprehensive text annotations .
Entity annotation
Entity labeling is the process of labeling unstructured sentences with information so that machines can read them. Entity labeling can be classified according to specific needs, so the types of entity labeling are very extensive. Let's cite a few of the most common types of entity annotations:
- NER Named Entity Recognition: It refers to element extraction and classification of named entities existing in text information. These entities are tagged based on predefined categories such as people, organizations, and places. Named entity recognition models add semantic knowledge to content, making it easy for individuals and systems to quickly identify and understand the topics of any given text.
- Entity Linking: This is the process of annotating the relationship between two parts of text. For example, you could tag companies and employees, or people and their hometowns as related concepts.
intent extraction
For chatbots, when a user enters a query, the algorithm's ability to accurately determine the user's intent can affect the lifecycle of the product. For example, if you want to cancel a reservation at a popular Michelin restaurant when you are abroad, the phone line has been busy for 500 years, and you can only hook up with the chatbot first: "I want to pay the cancellation fee and cancel the reservation." " Cancellation fee How much?" "Are you going to charge cancellation fees for people who make an appointment but no-show?" All three examples include the phrase "cancellation fee," but all have different intentions. In the first sentence, the intent is for the chatbot to take one action: cancel the booking. The second and third sentences have a different intent: to receive more information about the restaurant's cancellation fee policy. If the chatbot doesn’t recognize this, it might mistakenly cancel the user’s restaurant reservation. Intent extraction is a technical solution to solve the above problems. For intent extraction, we explicitly annotate user intent at the phrase or sentence level in the data. That way, the algorithm has a library of how people phrase certain requests, and it can start to infer new sentences based on this ground truth.