1. Prétraitement des fonctionnalités
Le but de l'ingénierie des fonctionnalités : convertir les données en données plus faciles à reconnaître pour les machines
scikit-learn : Fournit plusieurs fonctions utilitaires et classes de transformateurs communes pour transformer les vecteurs de caractéristiques brutes en représentations plus adaptées aux estimateurs en aval. Autrement dit, grâce à certaines fonctions de conversion, les données de caractéristiques sont converties en un processus de données de caractéristiques
L'unité ou la taille de la caractéristique est assez différente, ou la variance d'une certaine caractéristique est supérieure de plusieurs ordres de grandeur à d'autres caractéristiques, ce qui est facile à affecter (dominer) le résultat cible , rendant certains algorithmes incapables d'apprendre d'autres caractéristiques, donc une normalisation/standardisation est nécessaire
Certaines méthodes doivent être utilisées pour la conversion sans dimension , afin que les données de différentes spécifications puissent être converties dans la même spécification , y compris la normalisation et la standardisation
Deuxièmement, la normalisation
Normalisation : mapper les données sur (par défaut [0,1]) en transformant les données d'origine
La formule est la suivante

Agit sur chaque colonne, max est la valeur maximale d'une colonne, min est la valeur minimale d'une colonne, puis X'' est le résultat final, mx, mi sont les valeurs d'intervalle spécifiées, par défaut mx est 1, mi est 0, les exemples sont les suivants
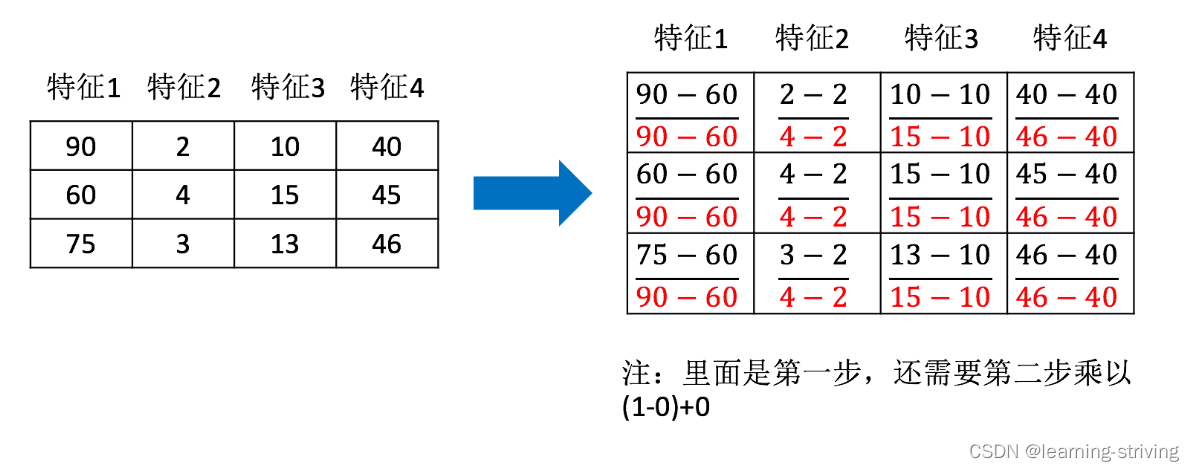
Utilisez la fonction API comme suit
- sklearn.preprocessing.MinMaxScaler (feature_range=(0,1)… ): feature_range spécifie la plage
- MinMaxScalar.fit_transform(X)
- X : données au format de tableau numpy [n_samples, n_features]
- Valeur de retour : tableau converti avec la même forme
- MinMaxScalar.fit_transform(X)
Le code est le suivant, le fichier date.txt des données de rencontres d'Helen peut être vu à la fin de l'article sur le lien du disque réseau
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
data = pd.read_csv("../data/dating.txt")
print(data)
transfer = MinMaxScaler(feature_range=(0, 1)) # 实例化一个转换器类
minmax_data = transfer.fit_transform(data[['milage', 'Liters', 'Consumtime']]) # 调用fit_transform
print("最小值最大值归一化处理后的结果:\n", minmax_data)
-------------------------------------------------------------
输出:
milage Liters Consumtime target
0 40920 8.326976 0.953952 3
1 14488 7.153469 1.673904 2
2 26052 1.441871 0.805124 1
3 75136 13.147394 0.428964 1
4 38344 1.669788 0.134296 1
.. ... ... ... ...
995 11145 3.410627 0.631838 2
996 68846 9.974715 0.669787 1
997 26575 10.650102 0.866627 3
998 48111 9.134528 0.728045 3
999 43757 7.882601 1.332446 3
[1000 rows x 4 columns]
最小值最大值归一化处理后的结果:
[[0.44832535 0.39805139 0.56233353]
[0.15873259 0.34195467 0.98724416]
[0.28542943 0.06892523 0.47449629]
...
[0.29115949 0.50910294 0.51079493]
[0.52711097 0.43665451 0.4290048 ]
[0.47940793 0.3768091 0.78571804]]Les valeurs maximales et minimales changent et sont facilement affectées par les valeurs aberrantes. Cette méthode est donc moins robuste et ne convient qu'aux scénarios traditionnels de petites données précises.
3. Normalisation
Normalisation : en transformant les données d'origine, les données sont transformées en données avec une moyenne de 0 et un écart type de 1.
La formule est la suivante

Agit sur chaque colonne, la moyenne est la moyenne, σ est l'écart type
- Pour la normalisation : s'il y a des valeurs aberrantes qui affectent les valeurs maximales et minimales, le résultat changera évidemment
- Pour la normalisation : s'il y a des valeurs aberrantes, en raison d'une certaine quantité de données, un petit nombre de valeurs aberrantes ont peu d'effet sur la valeur moyenne, donc le changement de variance est faible
L'API est la suivante
- sklearn.preprocessing.StandardScaler( ): Après traitement, pour chaque colonne, toutes les données sont rassemblées autour de la moyenne 0 et l'écart type est 1
- StandardScaler.fit_transform(X)
- X : données au format de tableau numpy [n_samples, n_features]
- Valeur de retour : tableau converti avec la même forme
- StandardScaler.fit_transform(X)
from sklearn.preprocessing import StandardScaler
import pandas as pd
data = pd.read_csv("../data/dating.txt")
print(data)
transfer = StandardScaler() # 实例化一个转换器
minmax_data = transfer.fit_transform(data[['milage', 'Liters', 'Consumtime']]) # 调用fit_transform
print("最小值最大值标准化处理后的结果:\n", minmax_data)
print("每一列特征的平均值:\n", transfer.mean_)
print("每一列特征的方差:\n", transfer.var_)
-------------------------------------------------------
输出:
milage Liters Consumtime target
0 40920 8.326976 0.953952 3
1 14488 7.153469 1.673904 2
2 26052 1.441871 0.805124 1
3 75136 13.147394 0.428964 1
4 38344 1.669788 0.134296 1
.. ... ... ... ...
995 11145 3.410627 0.631838 2
996 68846 9.974715 0.669787 1
997 26575 10.650102 0.866627 3
998 48111 9.134528 0.728045 3
999 43757 7.882601 1.332446 3
[1000 rows x 4 columns]
最小值最大值标准化处理后的结果:
[[ 0.33193158 0.41660188 0.24523407]
[-0.87247784 0.13992897 1.69385734]
[-0.34554872 -1.20667094 -0.05422437]
...
[-0.32171752 0.96431572 0.06952649]
[ 0.65959911 0.60699509 -0.20931587]
[ 0.46120328 0.31183342 1.00680598]]
每一列特征的平均值:
[3.36354210e+04 6.55996083e+00 8.32072997e-01]
每一列特征的方差:
[4.81628039e+08 1.79902874e+01 2.46999554e-01]La normalisation est relativement stable lorsqu'il y a suffisamment d'échantillons et convient aux scénarios de données volumineuses
4. Prédiction des espèces d'iris
API d'algorithme du plus proche voisin
- sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm='auto')
- n_neighbors : int, optionnel (défaut = 5), nombre de voisins à utiliser par défaut pour les requêtes k_neighbors
- algorithm : {'auto', 'ball_tree', 'kd_tree', 'brute'} : algorithme de recherche rapide des k voisins les plus proches, le paramètre par défaut est auto , ce qui peut être compris comme l'algorithme décide lui-même de l'algorithme de recherche approprié. En outre, les utilisateurs peuvent également spécifier les algorithmes de recherche suivants pour rechercher
- Arbre à billes : il a été inventé pour surmonter l'échec de haute latitude de l'arbre kd. Son processus de construction divise l'espace échantillon par le centre de gravité C et le rayon r, et chaque nœud est une hypersphère.
- kd_tree : une structure de données arborescente qui construit un arbre kd pour stocker des données en vue d'une récupération rapide. L'arbre kd est également un arbre binaire dans la structure de données. L'arbre construit par segmentation médiane, dont chaque nœud est un super rectangle, est efficace lorsque la dimension est inférieure à 20.
- Brute : il s'agit d'une recherche par force brute, c'est-à-dire d'un balayage linéaire. Lorsque l'ensemble d'apprentissage est grand, le calcul prend beaucoup de temps.
Jeu de données Iris
- Nombre d'instances : 150 (50 pour chacune des trois classes)
- Nombre d'attributs : 4 (numérique, numérique, attribut et classe pour aider à prédire)
- attribut, valeur de caractéristique
- longueur des sépales : longueur des sépales (cm)
- largeur des sépales : largeur des sépales (cm)
- longueur des pétales : longueur des pétales (cm)
- largeur des pétales : largeur des pétales (cm)
- type, valeur cible
- Iris-Setosa : Iris des montagnes
- Iris-Versicolor : Variation Iris
- Iris-Virginica : Iris de Virginie
spectacle de code comme ci-dessous
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier # 导入模块
# 1.获取数据集
iris = load_iris()
# 2.数据基本处理
# x_train,x_test,y_train,y_test为训练集特征值、测试集特征值、训练集目标值、测试集目标值
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22) # 划分数据集
# 3.特征工程:标准化
transfer = StandardScaler() # 实例化转换器
x_train = transfer.fit_transform(x_train) # 调用方法,标准化
x_test = transfer.transform(x_test)
# 4.机器学习(模型训练)
estimator = KNeighborsClassifier(n_neighbors=2) # 实例化一个估计器,n_neighbors为选定参考的邻居数
estimator.fit(x_train, y_train) # 模型训练
# 5.模型评估
# 方法1:比对真实值和预测值
y_predict = estimator.predict(x_test)
print("预测结果为:", y_predict)
print("比对真实值和预测值:", y_predict == y_test)
# 方法2:直接计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:", score)
-----------------------------------------------
输出:
预测结果为: [0 2 1 2 1 1 1 2 1 0 2 1 2 2 0 2 1 1 1 1 0 2 0 1 2 0 2 2 2 2]
比对真实值和预测值: [ True True True True True True True True True True True True
True True True True True True False True True True True True
True True True True True True]
准确率为: 0.9666666666666667Téléchargez les données de rencontres d'Helen dating.txt : https://pan.baidu.com/s/1JFrp-3YQyH_zFBwWulNqmQ?pwd=68ww
Apprendre à naviguer : http://xqnav.top/