How to efficiently learn Python's third-party libraries, I summarize here as follows.
general idea
The overall idea starts from the following perspectives:
Read the documentation: Third-party libraries usually have corresponding documentation, which will introduce the library's functions, usage methods, etc., so be sure to read the documentation carefully.
Install and run sample code: Third-party libraries usually provide some sample code, you can install the library first, and then run the sample code to understand the usage of the library.
Try to write code yourself: Based on reading the documentation and running the sample code, try to write some code yourself to consolidate what you have learned.
Find other resources: If the documentation and sample code are not enough, you can find other resources, such as blog posts, video tutorials, etc., to learn more about the library.

Take learning crawler framework scrapy as an example
It is meaningful to learn the crawler framework Scrapy, which can help us quickly develop crawler projects.
You can start from the following aspects:
Install Scrapy: Before learning Scrapy, you need to install it first. You can install it with the pip command, for example: pip install scrapy
Read the documentation: Scrapy has a very detailed documentation. Before you start learning, you can read the documentation to understand the functions and basic usage of Scrapy.
Try to run the sample code: Scrapy has some sample code, you can try to run these codes to understand the usage of Scrapy.
Try to write code yourself: Based on reading the documentation and running the sample code, try to write some code yourself to consolidate what you have learned.
This is a simple Scrapy example that crawls the names and ratings of Douban movies:
import scrapy
class MovieSpider(scrapy.Spider):
name = 'movie'
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
for movie in response.css('ol.grid_view li'):
yield {
'name': movie.css('span.title::text').extract_first(),
'rating': movie.css('span.rating_num::text').extract_first()
}
First, we define a MovieSpider class, inherited from the scrapy.Spider class. Then we define some properties, such as the name of the crawler and the start URL start_urls.
Then we defined a parse method, which is a callback function in Scrapy, which will be called when the crawler crawls to each page. In this method, we use the selector in Scrapy to extract the movie name and rating, and then use the yield statement to output this information.
This is just a simple example, Scrapy has many features, such as handling AJAX, automatically following links, using proxies, etc.
Take learning the kivy framework as an example
Kivy is a Python framework for developing mobile apps, games, and desktop applications. It uses a cross-platform graphics library that allows you to develop applications on platforms such as Windows, Linux, MacOS, Android, and iOS.
Here's a simple Kivy example that displays a window with a button:
import kivy
kivy.require('1.9.0')
from kivy.app import App
from kivy.uix.button import Button
class MyApp(App):
def build(self):
return Button(text='Hello World')
if __name__ == '__main__':
MyApp().run()
First, we imported the Kivy module and called the kivy.require function to check the Kivy version. We then imported the App and Button classes and created a class called MyApp that inherits from the App class.
In the MyApp class, we define a build method, which is a callback function in Kivy that is called when the application starts. In this method, we create a Button object and return it.
Finally, we call the run method of the MyApp class to start the application.
This is just a simple example, Kivy has many features, such as layout, touch events, animation, etc., you can learn more about it in the official documentation.
About Python Technical Reserve
It is good to learn Python whether it is employment or sideline business to make money, but to learn Python, you still need a study plan. Finally, everyone will share a full set of Python learning materials to help those who want to learn Python!
1. Python Learning Outline
The technical points in all directions of Python are sorted out to form a summary of knowledge points in various fields. Its usefulness lies in that you can find corresponding learning resources according to the above knowledge points to ensure that you can learn more comprehensively.
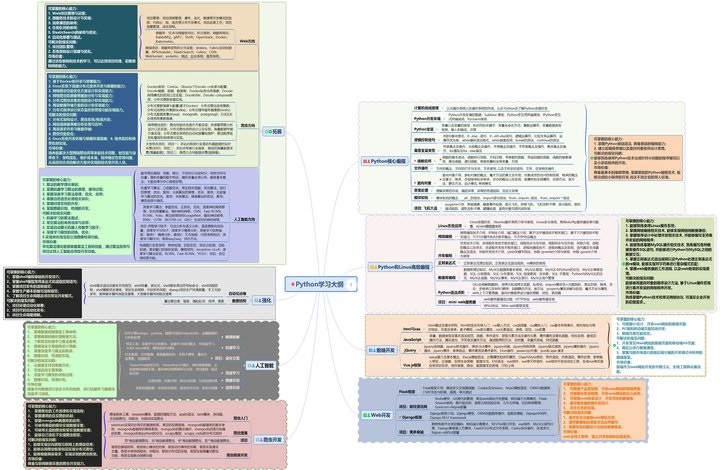
Due to limited space, only part of the information is shown, you need to click the link below to get it
2. Essential development tools for Python
3. Introductory learning video
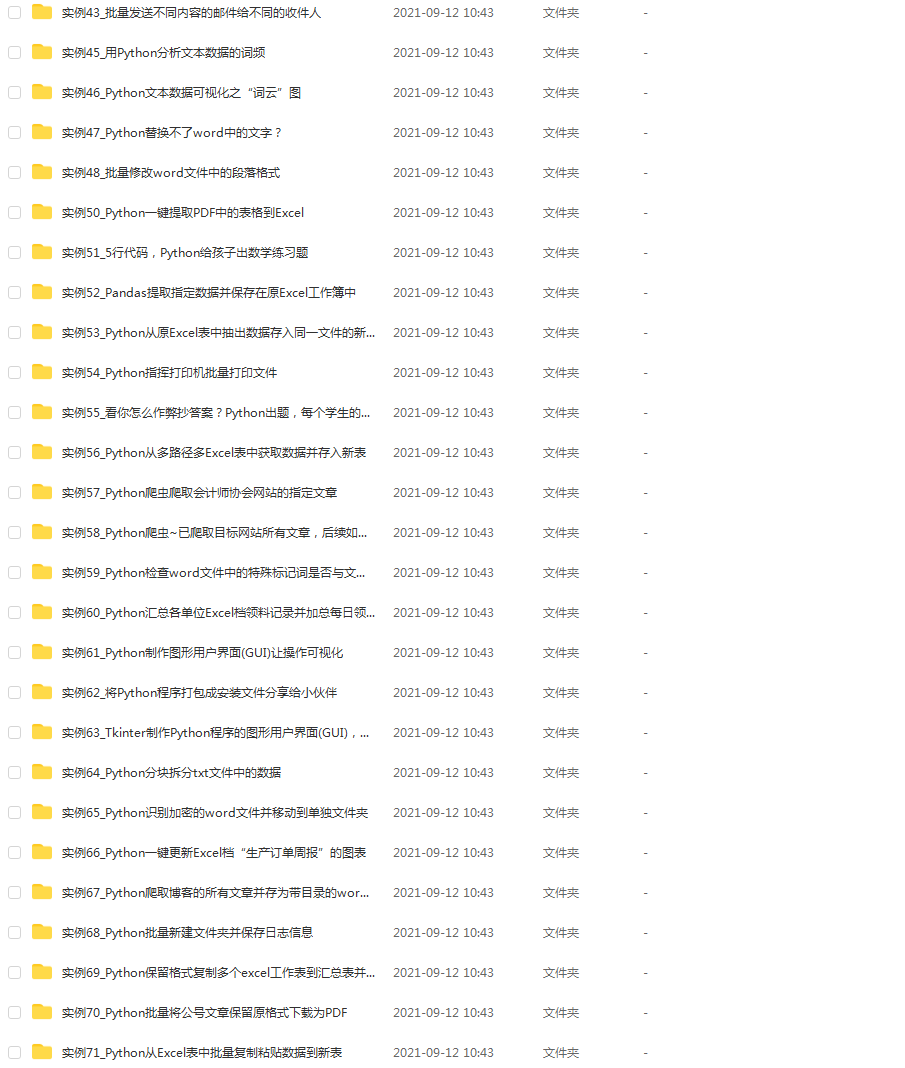
4. Practical cases
Optical theory is useless, you have to learn to follow along, and you have to do it yourself, so that you can apply what you have learned to practice. At this time, you can learn from some actual combat cases.
5. Python sideline part-time and full-time routes
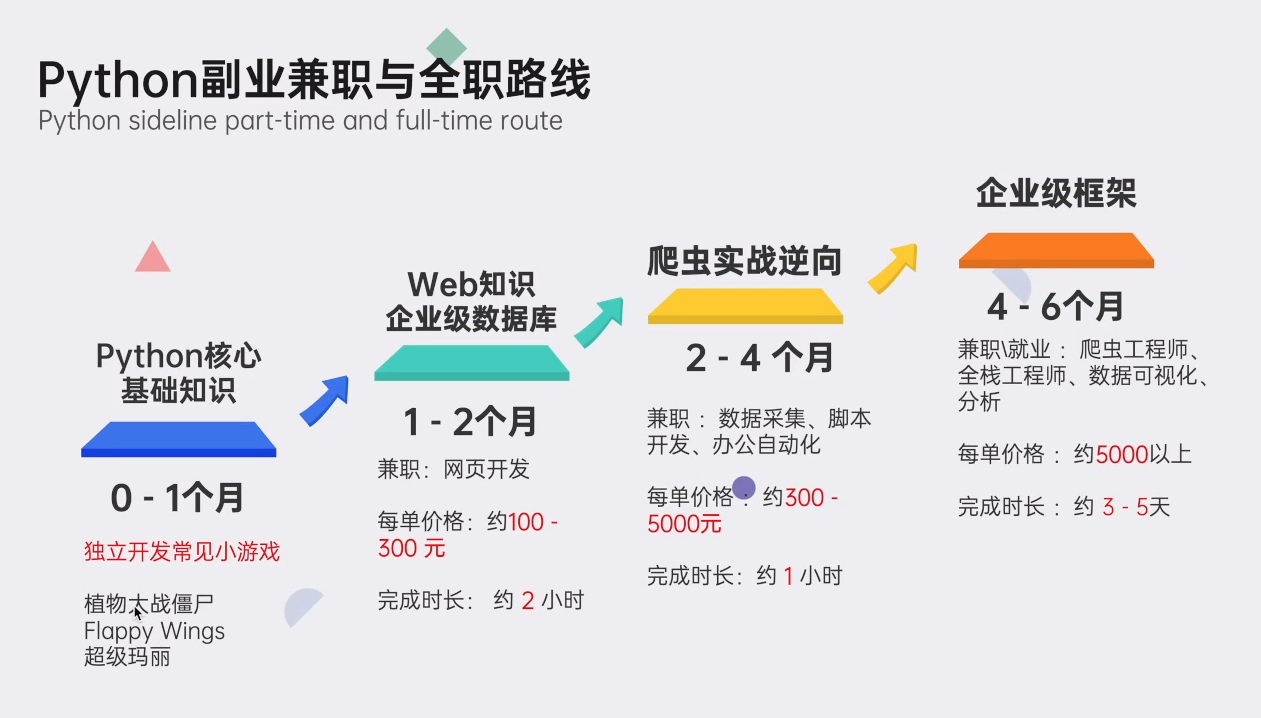
6. Internet company interview questions
We must learn Python to find high-paying jobs. The following interview questions are the latest interview materials from first-line Internet companies such as Ali, Tencent, and Byte, and Ali bosses have given authoritative answers. After finishing this set The interview materials believe that everyone can find a satisfactory job.
This complete set of learning materials for Python has been uploaded to CSDN. If you need it, you can also scan the official QR code of CSDN below or click the WeChat card at the bottom of the homepage and article to get the collection method. [Guaranteed 100% free]
