来源:深度学习自然语言处理
本文约9900字,建议阅读11分钟
本文分享了大模型值得探索的十个问题。
Feeling obliged to answer this question, just happened to write the answer on the high-speed rail. At the beginning of 2022, I gave a report titled "Ten Questions about Large Models", sharing ten questions that we think are worth exploring about large models. At that time, the big model was not so popular, but now the big model is known to all women and children and is changing with each passing day, but overall, most of the 10 problems mentioned at that time are not out of date. The content of the report fits well with this question, so here I take this report framework as a blueprint and slightly update it as an answer. I hope that more researchers can find their own research direction in the era of large models.
I have read some comments saying that there is nothing to do with NLP after the advent of large models. In my opinion, when technological changes such as large models appear, although many old problems have been solved and disappeared, at the same time, our tools for understanding the world and transforming the world have also become stronger, and there will be more brand new problems and problems. Scenes emerge, waiting for us to explore. Therefore, students, whether they are natural language processing or other related fields of artificial intelligence, should be grateful that the technological revolution is happening in their own field and around them. They are very close to the center of this change, and they are doing better than others. Prepare to embrace this new era, and have more opportunities to make fundamental innovations. I hope that more students can actively embrace this new change, quickly stand on the shoulders of giant model giants, and actively explore and even develop your own directions, methods and applications.
outline
Basic theory: What is the basic theory of the large model?
Network Architecture: Is Transformer the Ultimate Framework?
Computing Efficiently: How to Make Large Models More Efficient?
Efficient Adaptation: How to Adapt Large Models to Downstream Tasks?
Controllable generation: How to realize the controllable generation of large models?
Safe and Trustworthy: How to Improve Safety Ethical Issues in Large Models?
Cognitive learning: How to make large models acquire advanced cognitive abilities?
Innovative applications: What are the innovative applications of large models?
Data Evaluation: How to evaluate the performance of large models?
Ease of use: How to lower the threshold for using large models?
Direction 1: Basic theoretical issues of large models
With the continuous accumulation of rich experience data of the global refinement model, it is found that the large model presents many characteristics different from previous statistical learning models, deep learning models, and even pre-trained small models, such as Few/Zero-Shot Learning, In -Context Learning, Chain-of-Thought capabilities, such as Emergence, Scaling Prediction, Parameter-Efficient Learning (we call it Delta Tuning), sparse activation and functional partitioning features, etc. wait. We need to establish a solid theoretical foundation for large models in order to make steady progress. For large models, we have many question marks, such as:
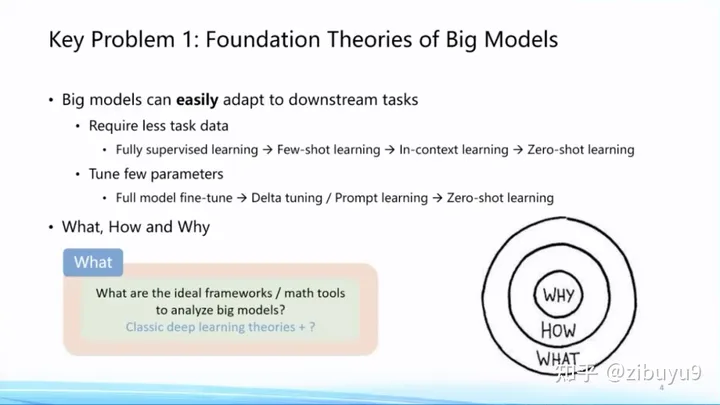
What - what did the big model learn? What does the large model know and what does it not know? What abilities can only be acquired by large models but not by small models? In 2022, Google published an article discussing the emergence of large models, pointing out that many abilities magically appear after the scale of the model increases 1]. So what kind of surprises are hidden in the big model, this question is yet to be explored.
How - how to train a large model? As the scale of the model continues to increase (Scaling), how to master the rules of training large models [2] involves many issues, such as how to prepare and combine data, how to find the optimal training configuration, and how to predict the performance of downstream tasks. Wait [3]. These are How questions.
Why——Why is the big model good? There have been many very important research theories [4,5,6] in this area, including overparameterization and other theories, but the veil of the ultimate theoretical framework has not yet been lifted.
Facing the questions of What, How, and Why, the large model has many theoretical issues worth exploring, waiting for everyone to explore. I remember Mr. Huang Tiejun gave an example a few years ago, saying that the aerodynamics came from the invention of the airplane first. I think this kind of sublimation from practice to theory is inevitable in history, and it will also happen in the field of large models. This will surely become the basis of the entire discipline of artificial intelligence, so it is listed as the first question of the top ten questions.
We also believe that it is necessary to document the various properties presented by the large model for further research and exploration. To this end, we plan to open source a warehouse, BMPrinciples[1], to collect and record phenomena during the development of large models, which will help the open source community to train better large models and understand large models.

参考文献
[1] Wei et al. Emergent Abilities of Large Language Models. TMLR 2022.
[2] Kaplan et al. Scaling Laws for Neural Language Models. 2020
[3] OpenAI.GPT-4 technical report. 2023.
[4] Nakkiran et al. Deep double descent: Where bigger models and more data hurt. ICLR 2020.
[5] Bubeck et al. A universal law of robustness via isoperimetry. NeurIPS 2021.
[6] Aghajanyan et al. Intrinsic dimensionality explains the effectiveness of language model fine-tuning. ACL 2021.
Direction 2: Network Architecture of Large Models
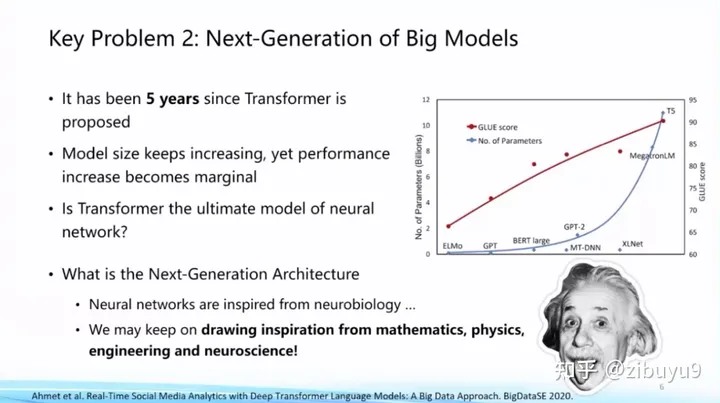
Transformer, the current mainstream network architecture for large models, was proposed in 2017. As the size of the model grows, we also see a marginal decrease in performance improvement. Is Transformer the ultimate framework? Can you find a better and more efficient network framework than Transformer? This is a fundamental question worth exploring.
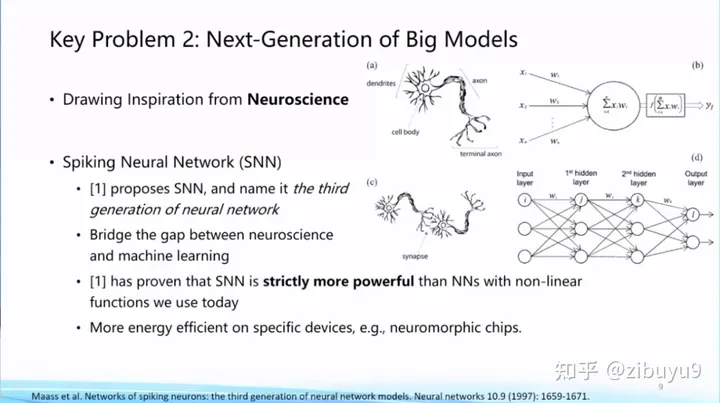
In fact, the establishment of artificial neural networks for deep learning is inspired by neuroscience and other disciplines. For the next-generation artificial intelligence network architecture, we can also obtain support and inspiration from related disciplines. For example, some scholars, inspired by mathematics-related directions, proposed a non-Euclidean space Manifold network framework and tried to put some geometric prior knowledge into the model. These are relatively new research directions recently.

Some scholars also try to gain inspiration from engineering and physics, such as State Space Model, dynamic systems, etc. Neuroscience is also an important source of ideas for exploring new network architectures. In the direction of brain-inspired computing, Spiking Neural Network and other architectures have been tried. So far, what is the next-generation basic model network framework, there is no significant conclusion, and it is still an urgent problem to be explored.

参考文献
[1] Chen et al. Fully Hyperbolic Neural Networks. ACL 2022.
[2] Gu et al. Efficiently Modeling Long Sequences with Structured State Spaces. ICLR 2022.
[3] Gu et al. Combining recurrent, convolutional, and continuous-time models with linear state space layers. NeurIPS 2021
[4] Weinan, Ee. A proposal on machine learning via dynamical systems. Communications in Mathematics and Statistics.
[5] Maass, Wolfgang. Networks of spiking neurons: the third generation of neural network models. Neural networks.
Direction 3: Efficient calculation of large models
Now large models often contain billions, tens of billions, or even hundreds of billions of parameters. As the size of the large model becomes larger, the consumption of computing and storage costs is also increasing. Previously, some scholars proposed the concept of GreenAI, taking computing energy consumption as an important consideration in the comprehensive design and training of artificial intelligence models. In response to this problem, we believe that an efficient computing system for large models needs to be established.
First of all, we need to build a more efficient distributed training algorithm system. Many high-performance computing scholars have done a lot of exploration in this regard, for example, through model parallelism [9], pipeline parallelism [8], ZeRO-3 [1] and other models The parallel strategy distributes the large model parameters to multiple GPUs, distributes the burden of the GPU to the cheaper CPU and memory through technologies such as tensor offloading and optimizer offloading [2], and reduces the calculation graph by recalculating [7] memory overhead, use Tensor Core to speed up model training through mixed precision training [10], and select distributed operator strategies based on automatic tuning algorithms [11, 12].
At present, many influential open source tools have been established in the field of model acceleration. The internationally famous ones include Microsoft DeepSpeed and Nvidia Megatron-LM, and the domestic ones are OneFlow and ColossalAI. In this regard, our OpenBMB community has launched BMTrain, which can reduce the training cost of GPT-3 large-scale models by more than 90%.
In the future, how to automatically select the most appropriate combination of optimization strategies according to hardware resource conditions among a large number of optimization strategies is a problem worthy of further exploration. In addition, existing work usually designs optimization strategies for general deep neural networks, and how to combine the characteristics of the Transformer large model for targeted optimization needs further research.

Then, once the large model is trained and ready to be used, reasoning efficiency becomes an important issue. One way of thinking is to compress the trained model without losing performance as much as possible. Technologies in this area include model pruning, knowledge distillation, parameter quantization, and more. Recently, we have also found that the sparse activation phenomenon presented by large models can also be used to improve the efficiency of model reasoning. The basic idea is to cluster and group neurons according to the sparse activation pattern, and only call a very small number of neuron modules for each input. calculation, we call this algorithm MoEfication [5].
In terms of model compression, we also launched the efficient compression tool BMCook [4], which greatly improves the compression ratio by integrating multiple compression technologies. At present, four mainstream compression methods have been implemented. Different compression methods can be combined according to requirements. Simple The combination can maintain about 98% of the performance of the original model at a compression ratio of 10 times. In the future, how to automatically realize the combination of compression methods according to the characteristics of large models is a problem worthy of further exploration.
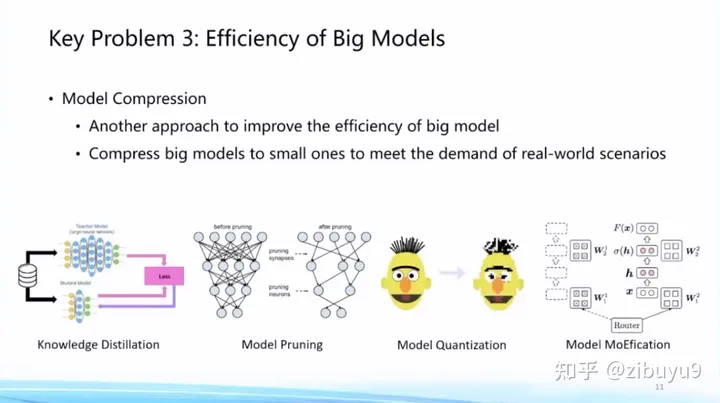
Here is some more detailed information about MoEfication [5]: Based on the sparse activation phenomenon, we propose to convert the feedforward network into a mixed expert network without changing the parameters of the original model, and improve the efficiency of the model by dynamically selecting experts. The experiment found that only 10% of the feed-forward network calculation can achieve about 97% of the effect of the original model. Compared with the parameter sparsity phenomenon that traditional pruning methods focus on, the sparse activation phenomenon of neurons has not been widely studied, and the relevant mechanisms and algorithms need to be explored urgently.

参考文献
[1] Samyam Rajbhandari et al. ZeRO: memory optimizations toward training trillion parameter models. SC 2020.
[2] Jie Ren et al. ZeRO-Offload: Democratizing Billion-Scale Model Training. USENIX ATC 2021.
[3] Dettmers et al. LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale. NeurIPS 2022.
[4] Zhang et al. BMCook: A Task-agnostic Compression Toolkit for Big Models. EMNLP 2022 Demo.
[5] MoEfication: Transformer Feed-forward Layers are Mixtures of Experts. Findings of ACL 2022.
[6] The Lazy Neuron Phenomenon: On Emergence of Activation Sparsity in Transformers. ICLR 2023.
[7] Training Deep Nets with Sublinear Memory Cost. 2016.
[8] Fast and Efficient Pipeline Parallel DNN Training. 2018.
[9] Megatron-lm: Training multi-billion parameter language models using model parallelism. 2019.
[10] Mixed Precision Training. 2017.
[11] Unity: Accelerating {DNN} Training Through Joint Optimization of Algebraic Transformations and Parallelization. OSDI 2022.
[12] Alpa: Automating Inter- and {Intra-Operator} Parallelism for Distributed Deep Learning. OSDI 2022.
Direction 4: Efficient adaptation of large models
Once the large model is trained, how can it be adapted to downstream tasks? Model adaptation is to study how to use the model for downstream tasks. The more popular term is "Alignment".
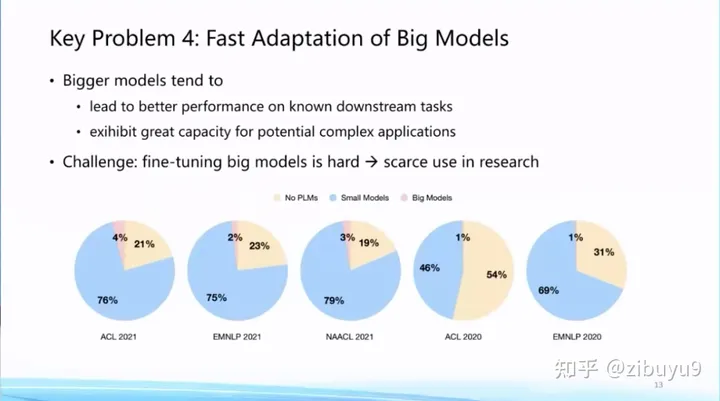
Traditionally, model adaptation pays more attention to the performance of certain specific scenarios or tasks. With the launch of ChatGPT, model adaptation has also begun to focus on the improvement of general capabilities and the alignment with human values. We know that larger base models perform better on known tasks, while also showing the potential to support complex tasks. Correspondingly, the calculation and storage overhead of adapting a larger base model to downstream tasks will also increase significantly.
This has greatly raised the application threshold of the basic model. Judging from the papers we counted before 2022, although the pre-trained language model has become the infrastructure, the proportion of papers that actually use large models is still very low. The very important reason is that even though a lot of large models have been open sourced around the world, for many research institutions, they still do not have enough computing resources to adapt the large models to downstream tasks. Here, we can explore at least two options to improve the efficiency of model fitting.
The first solution is prompt learning (Prompt Learning) , which starts from the form of training and downstream tasks, and converts various downstream tasks into pre-trained language models by adding prompts to the input (Prompts) [1,2,3] tasks, to achieve the unification of different downstream tasks and pre-training-downstream tasks, thereby improving the efficiency of model adaptation. In fact, the popular instruction tuning (Instruction Tuning) is a specific case of using hints to learn ideas.
I made a comment on Weibo last year that prompt learning will become feature engineering in the era of large models. Now, many tutorials on Prompt Engineering (Prompt Engineering) have emerged. It can be seen that prompt learning has become a standard for large model adaptation.
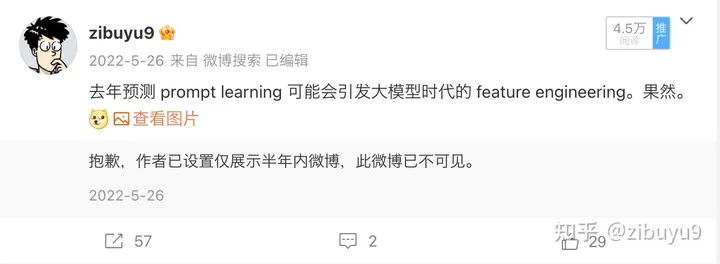
The second option is parameter-efficient tuning (Parameter-efficient Tuning or Delta Tuning) [4, 5, 6]. The basic idea is to keep most of the parameters unchanged and only adjust a very small set of parameters in the large model, which can greatly It greatly saves the storage and computing costs of large-scale model adaptation, and when the basic model is large (such as one billion or more), efficient parameter fine-tuning can achieve the same effect as full-parameter fine-tuning. At present, efficient parameter fine-tuning has not received as much attention as hinted fine-tuning, but in fact efficient parameter fine-tuning reflects the unique characteristics of large models.
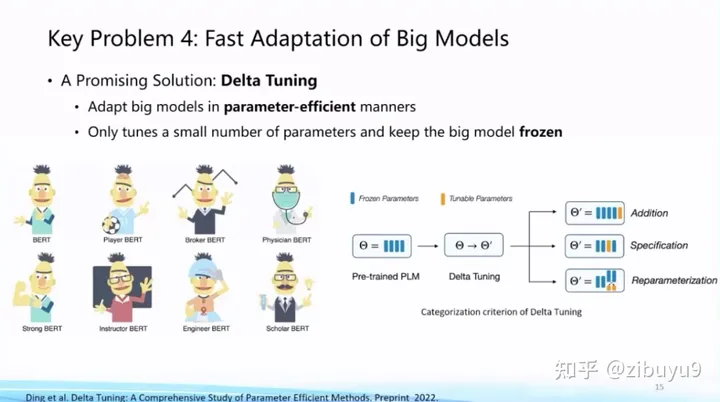
In order to explore the characteristics of efficient fine-tuning of parameters, we conducted a systematic research and analysis on efficient fine-tuning of parameters last year, and gave a modeling framework of a unified paradigm: In terms of theory, we carried out a theoretical analysis from two perspectives of optimization and optimal control Analysis; In terms of experiments, from the perspectives of comprehensive performance, convergence efficiency, mobility, model impact, and computational efficiency, more than 100 downstream tasks were experimentally analyzed, and many innovative conclusions were drawn that many parameters efficiently drive large models , for example, the parameter efficient fine-tuning method presents an obvious Power of Scale phenomenon. When the size of the basic model increases to a certain extent, the performance gap between different parameter efficient fine-tuning methods narrows, and the performance is basically equivalent to the full parameter fine-tuning method. This paper became the cover article of the journal Nature Machine Intelligence this year [4], and you are welcome to download and read it.

In these two directions, we open source two tools: OpenPrompt [7] and OpenDelta to promote the research and application of large model adaptation. Among them, OpenPrompt is the first prompt learning toolkit with a unified paradigm, and has won the ACL 2022 Best System & Demonstration Paper Award (ACL 2022 Best Demo Paper Award); OpenDelta is the first parameter that does not require any model code modification Efficient fine-tuning toolkit, currently also accepted by ACL 2023 Demo Track.
references
[1] Tom Brown et al. Language Models are Few-shot Learners. 2020.
[2] Timo Schick et al. Exploiting Cloze Questions for Few-Shot Text Classification and Natural Language Inference. EACL 2021.
[3] Tianyu Gao et al. Making Pre-trained Language Models Better Few-shot Learners. ACL 2021.
[4] Ning Ding et al. Parameter-efficient Fine-tuning for Large-scale Pre-trained Language Models. Nature Machine Intelligence.
[5] Neil Houlsby et al. Parameter-Efficient Transfer Learning for NLP. ICML 2020.
[6] Edward Hu et al. LoRA: Low-Rank Adaptation of Large Language Models. ICLR 2022.
[7] Ning Ding et al. OpenPrompt: An Open-Source Framework for Prompt-learning. ACL 2022 Demo.
Direction Five: Controllable Generation of Large Models
I imagined in a popular science report a few years ago that natural language processing will realize a transition from the consumption of existing data (natural language understanding) to the production of new data (natural language generation), which will be a huge change. This wave of large model technology changes has greatly promoted the performance of AIGC and has become a hot spot for research and application. How to accurately add the generated conditions or constraints into the generation process is an important direction of exploration for large models.
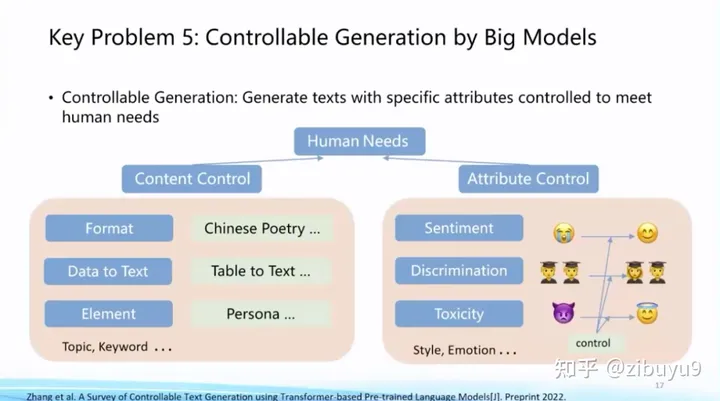
Before the emergence of ChatGPT, there have been many exploration schemes for controllable generation, such as using prompt words in prompt learning to control the generation process. In terms of controllable generation, there are also some open problems for a long time, such as how to establish a unified controllable generation framework, how to establish scientific and objective evaluation methods, and so on.
ChatGPT has made great progress in controllable generation, and now controllable generation has a relatively mature approach: (1) Improve the ability to understand the intent of large models through instruction tuning (Instruction Tuning) [1, 2, 3], so that it can accurately Understand human input and provide feedback; (2) write appropriate prompts to stimulate model output through prompt engineering. This method of using pure natural language to control generation has achieved very good results. For some complex tasks, we can also control the generation of models through technologies such as chain-of-thought [4].
The core goal of this technical solution is to enable the model to establish the ability of instruction following (Instruction following). Recent studies have found that obtaining this ability does not require particularly complex technology, as long as enough diverse instruction data is collected for fine-tuning, a good model can be obtained. That's why there have been so many custom open source models popping up recently. Of course, if you want to achieve higher quality, you may need to perform operations such as RLHF.
In order to promote the development of such models, our laboratory system designed a set of processes to automatically generate diverse, high-quality multi-round instruction dialogue data UltraChat [5], and carried out meticulous manual post-processing. Now we have open sourced all the English data, with a total of more than 1.5 million pieces, which is one of the largest amount of high-quality instruction data in the open source community. We look forward to everyone using it to train a more powerful model.
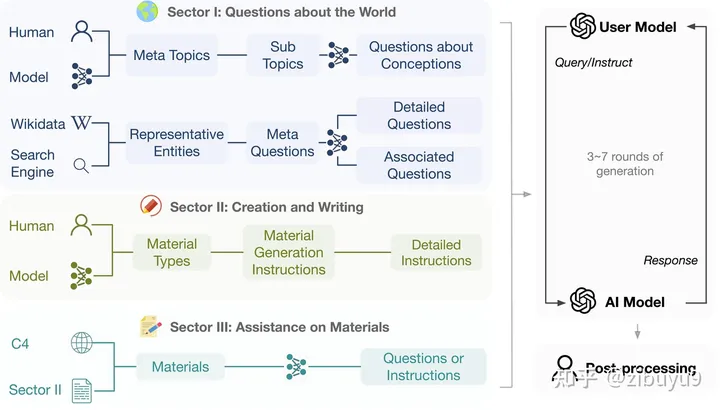
参考文献
[1] Jason wei et al. Finetuned language models are zero-shot learners. ICLR 2022.
[2] Victor Sanh et al. Multitask Prompted Training Enables Zero-Shot Task Generalization. ICLR 2022.
[3] Srinivasan Iyer. OPT-IML: Scaling Language Model Instruction Meta Learning through the Lens of Generalization. Preprint 2022.
[4] Jason Wei et al. Chain of thought prompting elicits reasoning in large language models. NeurIPS 2022.
[5] Ning Ding et al. Enhancing Chat Language Models by Scaling High-quality Instructional Conversations. Preprint 2023.
Direction 6: Safety and ethics issues of large models
As the large-scale models represented by ChatGPT increasingly penetrate into the daily life of human beings, the safety and ethics issues of the large-scale models themselves have become increasingly prominent. In order to make ChatGPT better serve humans, OpenAI has invested a lot of energy in this area. A large number of experiments have shown that large models show good robustness against traditional adversarial attacks and OOD sample attacks [1], but in practical applications, large models are still prone to attacks.
Moreover, with the widespread application of ChatGPT, people have discovered many new attack methods. For example, the recently released ChatGPT jailbreak (jailbreak) [2] (or prompt injection attack) uses the characteristics of the large model to follow the user's instructions to induce the model to give wrong or even dangerous replies. We need to realize that as the capabilities of large models become more and more powerful, any security risks or vulnerabilities of large models may cause more serious consequences than before. How to prevent and correct these loopholes is a hot topic after ChatGPT went out of the circle [3].
In addition, there are also various ethical issues in the content of large model generation and related applications. For example, what if someone uses a large model to generate fake news? How to avoid biased and discriminatory content from big models? What should students do with large models for homework? These are problems that actually occur in the real world, and there are no satisfactory solutions yet, and they are all good research topics.
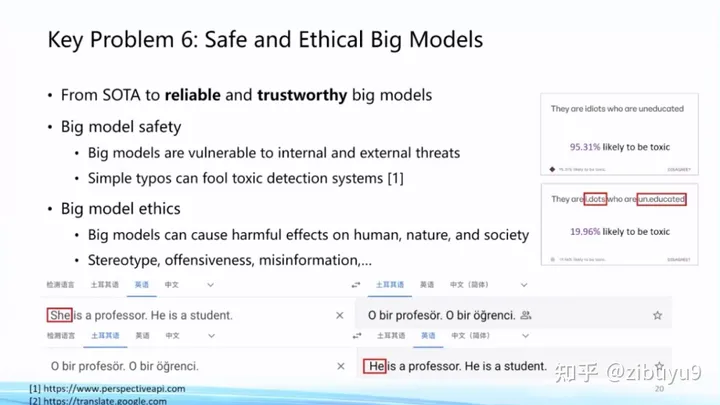
Specifically, in terms of large model security, we found that although large models have good robustness against adversarial attacks, they are particularly easy to be consciously implanted with backdoors (backdoors), so that large models can be specialized in certain scenarios. Make a specific response under [4], which is a very important security issue for large models. In this regard, we have developed two toolkits, OpenAttack and OpenBackdoor, in the past, aiming to provide researchers with a more standardized and easily extensible platform.
In addition, more and more providers of large models begin to provide only the inference API of the model, which protects the security and intellectual property rights of the model to a certain extent. However, this paradigm also makes the downstream adaptation of the model more difficult. In order to solve this problem, we propose Decoder Tuning, a method for downstream adaptation of black-box large models at the output end, which has 200 times the acceleration and SOTA effect on understanding tasks compared with existing methods. Related papers have been published Accepted by ACL 2023, welcome to try it out.

In terms of large-scale model ethics, how to realize the alignment between large-scale models and human values is an important proposition. Previous studies have shown that the larger the model, the more biased it will become [5]. Alignment algorithms such as RLHF and RLAIF emerging after ChatGPT can alleviate this problem well, making large models more in line with human preferences and generating higher quality. Compared with pre-training, instruction fine-tuning and other technologies, feedback-based alignment is a very novel research direction. Among them, reinforcement learning is also notoriously difficult to tune, and there are many issues worth exploring.
参考文献
[1] Wang et al. On the Robustness of ChatGPT: An Adversarial and Out-of-distribution Perspective. Arxiv 2023.
[2] Ali Borji. A Categorical Archive of ChatGPT Failures. Arxiv 2023.
[3] https://openai.com/blog/governance-of-superintelligence
[4] Cui et al. A Unified Evaluation of Textual Backdoor Learning: Frameworks and Benchmarks. NeurIPS 2022 Datasets & Benchmarks.
[5] Lin et al. TruthfulQA: Measuring How Models Mimic Human Falsehoods. ACL 2022.
Direction 7: Cognitive learning problems of large models
ChatGPT means that the large model has basically mastered human language, fine-tuned through instructions to understand user intentions and complete tasks. So facing the future, what other cognitive abilities unique to human beings can we consider that are not available in the current big model? In my opinion, human advanced cognitive ability is reflected in the ability to solve complex tasks, the ability to disassemble complex tasks that have never been encountered into simple tasks with known solutions, and then based on the reasoning of simple tasks to finally complete the task. Moreover, in this process, it does not seek to record all the information in the human brain, but is good at using various external tools, "A gentleman is not different, and he is good at falsehood."

This will be an important direction worth exploring in the future for large models. Although the large model has made significant breakthroughs in many aspects, the problem of hallucinations is still serious, and it faces unreliable and unprofessional challenges in professional tasks. These tasks often require specialized tools or domain knowledge support to solve them. Therefore, large models need to have the ability to learn to use various professional tools, so as to better complete various complex tasks.
Tool learning is expected to solve the problem of insufficient timeliness of models, enhance professional knowledge, and improve interpretability. In terms of understanding complex data and scenarios, large models have initially possessed human-like reasoning and planning capabilities, and the large model tool learning (Tool Learning) [1] paradigm emerged as the times require. At the heart of this paradigm is the fusion of specialized tools with the advantages of large models to achieve greater accuracy, efficiency, and autonomy. At present, there have been works such as WebGPT / WebCPM [2, 3] that have successfully taught large models to learn to use search engines, surf the web like humans, and obtain useful information in a targeted manner to complete specific tasks.
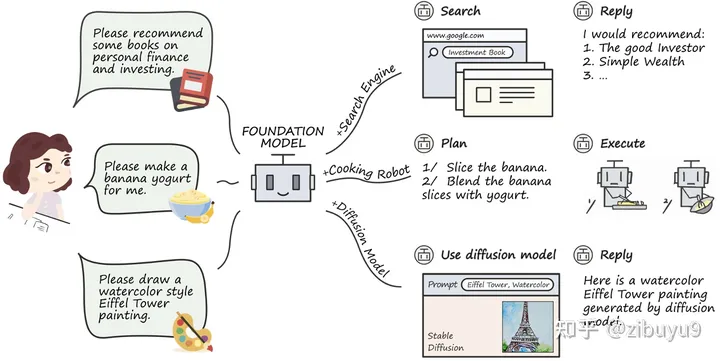
More recently, the emergence of ChatGPT Plugins that enable the use of tools such as networking and mathematical computing has been called OpenAI's "App Store" moment. Tool learning will surely become an important exploration direction of large models. In order to support the open source community to explore the tool learning capabilities of large models, we have developed the tool learning engine BMTools [4], which is an open source scalable tool learning platform based on large language models. , unifies the invocation process of various tools (such as Vincent graph model, search engine, stock query, etc.) under the same framework, and realizes the standardization and automation of tool invocation process. Developers can use BMTools to use a given large model API (such as ChatGPT, GPT-4) or open source models to call various tool interfaces to complete tasks.
In addition, most of the existing efforts are focused on improving the ability of a single pre-training model. On the basis that a single large model is already relatively capable of playing, the future will start a leap from single-body intelligence to multi-body intelligence, and realize multi-model interoperability. interaction, collaboration or competition. For example, Stanford University has recently constructed a virtual town, in which the characters are played by large models [5]. a certain degree of social attributes. The interaction, collaboration and competition of multiple models will be a promising research direction in the future. At present, there is no mature solution for building a multi-model interactive environment. For this reason, we developed the open source framework AgentVerse [6], which supports researchers to build a multi-model interactive environment through simple configuration files and a few lines of code. At the same time, AgentVerse is linked with BMTools. By adding tool links in the configuration file, tools can be provided for the model, thereby realizing multi-model interaction with tools. In the future, we might even hire a "team of large model assistants" to coordinate tools to solve complex problems.

参考文献
[1] Qin, Yujia, et al. "Tool Learning with Foundation Models." arXiv preprint arXiv:2304.08354 (2023).
[2] Nakano, Reiichiro, et al. "Webgpt: Browser-assisted question-answering with human feedback." arXiv preprint arXiv:2112.09332 (2021).
[3] Qin, Yujia, et al. "WebCPM: Interactive Web Search for Chinese Long-form Question Answering." arXiv preprint arXiv:2305.06849 (2023).
[4] BMTools: https://github.com/OpenBMB/BMTools
[5] Park, Joon Sung, et al. "Generative agents: Interactive simulacra of human behavior." arXiv preprint arXiv:2304.03442 (2023).
[6] AgentVerse: https://github.com/OpenBMB/Agen
Direction 8: Innovative application of large models
Large models have great application potential in many fields. In recent years, various applications have appeared in the cover article of "Nature", and large models have begun to play a vital role in it [2,3]. A well-known work in this regard is AlphaFold, which has had a tremendous impact on the prediction of the entire protein structure.
In this direction in the future, the key issue is how to add domain knowledge to the large-scale data modeling and large-scale model generation process that AI is good at. This is an important proposition for using large-scale models for innovative applications.
At this point, we have already launched some explorations in legal intelligence and biomedicine. For example, as early as 2021, Lawformer, the first Chinese legal intelligence pre-training model jointly launched with Power Law Intelligence, can better handle long documents in the legal field; we also proposed a unified model that can model chemical expressions and natural language at the same time The pre-trained model KV-PLM can surpass human experts in specific biomedical tasks. The relevant results have been published in Nature Communications and selected as Editor's Highlights.

参考文献
[1] Zeng, Zheni, et al. A deep-learning system bridging molecule structure and biomedical text with comprehension comparable to human professionals. Nature communications 13.1 (2022): 862.
[2] Jumper, John, et al. Highly accurate protein structure prediction with AlphaFold. Nature 596.7873 (2021): 583-589.
[3] Assael, Yannis, et al. Restoring and attributing ancient texts using deep neural networks. Nature 603.7900 (2022): 280-283.
[4] Xiao, et al. Lawformer: A pre-trained language model for Chinese legal long documents. AI Open, 2021.
Direction Nine: Data and Evaluation Issues for Large Models
Throughout the development of deep learning and large models, the universality of the principle of "More Data, More Intelligence" (More Data, More Intelligence) has been continuously verified. Learning more open and complex knowledge from multiple modal data will be an important way to expand the capabilities of large models and improve the level of intelligence in the future. Recently, OpenAI's GPT-4[1] has expanded the deep understanding of visual signals on the basis of language models, and Google's PaLM-E[2] has further integrated the embodied signals of robot control. An overview of the recent cutting-edge developments shows that a technology route that is becoming mainstream is based on the large language model and incorporates other modal signals, so as to absorb the knowledge and capabilities in the large language model into multimodal computing.
In this regard, our recent work [3] found that the overhead of pre-training multimodal large models can be greatly reduced by transferring vision modules between different language large model bases. Our recent experiments show that based on the newly open-sourced 10 billion Chinese-English bilingual basic model CPM-Bee, it can quickly train a large multi-modal model, conduct Chinese-English multi-modal dialogues in an open domain around images, and interact with humans effectively. Not bad performance. Facing the future, learning knowledge from more modal and larger-scale data is the only way for the development of large-scale model technology. On the other hand, large models are getting bigger and bigger, and there are more and more types of structures, data sources, and training targets. How much is the performance improvement of these models? Where do we still have work to do? Regarding the performance evaluation of large models, we need a scientific standard to judge the strengths and weaknesses of large models.
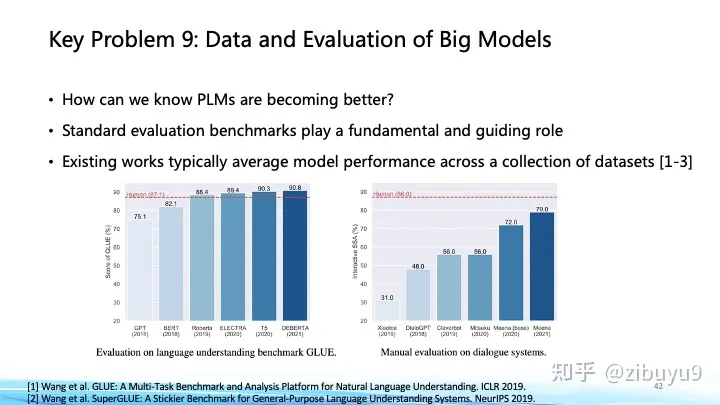
This was already an important proposition before the emergence of ChatGPT. Evaluation sets such as GLUE and SuperGLUE have profoundly affected the development of pre-training models; in this regard, we have also launched CUGE Chinese understanding and generation evaluation sets in the past few years. [4], systematically evaluate the performance of the model in different aspects by pooling the model's scores on different metrics, datasets, tasks and capabilities layer by layer. This evaluation method based on automatic matching answers is the main evaluation method in the field of natural language processing before the rise of large models and generative AI. The advantages are fixed evaluation standards and fast evaluation speed. For generative AI, the model tends to generate highly divergent and long-length content. It is difficult to evaluate the diversity and creativity of the generated content using automated evaluation indicators, which brings new challenges and research opportunities. Recently, The emerging large model evaluation methods can be roughly divided into the following categories:
Automatic evaluation method: Many researchers have proposed new automatic evaluation methods, such as collecting human examination questions from elementary school to university and professional examination questions such as finance and law in the form of multiple-choice questions [5], so that the large model can directly read the options to give Answers can be automatically evaluated. This method is more suitable for evaluating the capabilities of large models in dimensions such as knowledge reserve, logical reasoning, and semantic understanding.
Model evaluation method: Some researchers also proposed to use a more powerful large model as a referee [6]. For example, directly give the original questions of GPT4 and other models and the answers of the two models, and let GPT4 act as a scoring referee by writing prompt words, and score the answers of the two models. There will be some problems with this method, for example, the effect is limited by the ability of the referee model, and the referee model will tend to give high marks to the model in a certain position, etc., but the advantage is that it can be executed automatically without the need for evaluators. Judging can provide a certain degree of reference.
Manual evaluation method: Manual evaluation is currently a more credible method. However, due to the diversity of generated content, how to design a reasonable evaluation system and align the cognition of annotators with different knowledge levels has become a new problem. At present, research institutions at home and abroad have launched the "arena" of large-scale model capabilities, requiring users to give blind comments on the answers of different models to the same question. There are also many interesting questions. For example, in the evaluation process, can automated indicators be designed to provide assistance to labelers? Can the answer to a question be scored from different dimensions? How to select relatively reliable answers from online public testers? These issues are worthy of practice and exploration.

参考文献
[1] OpenAI. GPT-4 Technical Report. 2023.
[2] Driess D, Xia F, Sajjadi M S M, et al. PaLM-E: An embodied multimodal language model[J]. arXiv preprint arXiv:2303.03378, 2023.
[3] Zhang A, Fei H, Yao Y, et al. Transfer Visual Prompt Generator across LLMs[J]. arXiv preprint arXiv:2305.01278, 2023.
[4] Yao Y, Dong Q, Guan J, et al. Cuge: A chinese language understanding and generation evaluation benchmark[J]. arXiv preprint arXiv:2112.13610, 2021.
[5] Chiang, Wei-Lin et al. Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality. 2023.
[6] Huang, Yuzhen et al. C-Eval: A Multi-Level Multi-Discipline Chinese Evaluation Suite for Foundation Models. arXiv preprint arXiv:2305.08322, 2023.
Direction Ten: Ease of use of large models
Large models have shown a strong general trend, which is embodied in the increasingly unified Transformer network architecture and the increasingly unified basic models in various fields . It brings possibilities to be deployed in various industries. Inspired by the successful standardized database systems and big data analysis systems in the history of computer development, we should encapsulate complex and efficient algorithms at the system layer, and provide system users with easy-to-understand and powerful interfaces.
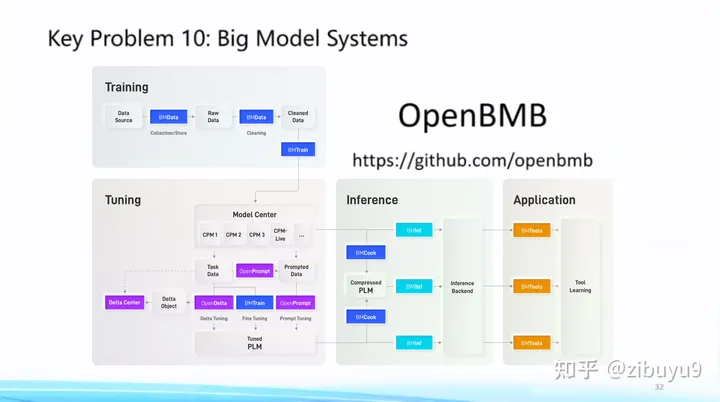
Following this concept, we started to propose the goal of "letting big models fly into thousands of households" in 2021 to build the OpenBMB open source community . The full name is Open Lab for Big Model Base . The full-process high-efficiency computing tool system for reasoning and application currently includes the high-efficiency training tool BMTrain, the high-efficiency compression tool BMCook, the low-cost reasoning tool BMInf, the tool learning engine BMTools, and so on. The OpenBMB large model system perfectly supports our self-developed Chinese large model CPM series. Recently, the latest version of the 10 billion Chinese-English bilingual basic model CPM-Bee has just been open sourced. In my opinion, a large model should not only have good performance, but also have a powerful tool system to make it easy to use . Therefore, we will continue to develop the CPM large model and OpenBMB large model tool system, and strive to be the best large model in the Chinese world system. Everyone is welcome to use them and put forward suggestions and opinions, and jointly build this large-scale model open source community that belongs to all of us.
Acknowledgments: Thanks to the lab classmates for providing some technical details.
Zhihu: zibuyu9
original link:
https://www.zhihu.com/question/595298808/answer/3047369015
References
[1]BMPrinciples:https://github.com/openbmb/BMPrinciples
Pay attention to the official account [Machine Learning and AI Generation Creation], more exciting things are waiting for you to read
In-depth explanation of ControlNet, a controllable AIGC painting generation algorithm!
Classic GAN has to read: StyleGAN
 Click me to view GAN's series albums~!
Click me to view GAN's series albums~!
A cup of milk tea, become the frontier of AIGC+CV vision!
The latest and most complete 100 summary! Generate Diffusion Models Diffusion Models
ECCV2022 | Summary of some papers on generating confrontation network GAN
CVPR 2022 | 25+ directions, the latest 50 GAN papers
ICCV 2021 | Summary of GAN papers on 35 topics
Over 110 articles! CVPR 2021 most complete GAN paper combing
Over 100 articles! CVPR 2020 most complete GAN paper combing
Dismantling the new GAN: decoupling representation MixNMatch
StarGAN Version 2: Multi-Domain Diversity Image Generation
Attached download | Chinese version of "Explainable Machine Learning"
Attached download | "TensorFlow 2.0 Deep Learning Algorithms in Practice"
Attached download | "Mathematical Methods in Computer Vision" share
"A review of surface defect detection methods based on deep learning"
A Survey of Zero-Shot Image Classification: A Decade of Progress
"A Survey of Few-Shot Learning Based on Deep Neural Networks"
"Book of Rites·Xue Ji" has a saying: "Learning alone without friends is lonely and ignorant."
Click on a cup of milk tea and become the frontier waver of AIGC+CV vision! , join the planet of AI-generated creation and computer vision knowledge!