This project that got 34k stars on GitHub? Do CSDN programmers only visit Baidu, not GitHub?
This project is legendary . It has been praised by countless people on GitHub as a must-learn project for novices , but it can be used on any platform and version of the IDE without any modification . Great project, bar none!
In order to respect the original author, please go to the project to check it out, it is definitely a monument in the history of computers.
What I said above is not my own evaluation, it is all comments from netizens:
 This is also the first project I have seen that was praised by Chinese and foreign elders with fancy language, such as Book Siyi (incredible), and many people even praised it with: Dao Ke Dao, Very Dao, Promise, Staring at the Abyss, which is very philosophical.
This is also the first project I have seen that was praised by Chinese and foreign elders with fancy language, such as Book Siyi (incredible), and many people even praised it with: Dao Ke Dao, Very Dao, Promise, Staring at the Abyss, which is very philosophical.
In the entire GitHub, even on a larger scale, you can’t find a second project like this on the entire Internet!
Project name: nocode
Project address: https://github.com/kelseyhightower/nocode
Waiting for you to calm down, after reading the project carefully, you will understand that this project implements the original meaning of the word git.
And programmers actually have three realms:
1. If you have code in your eyes, typing on the keyboard will help you.
2. There is a code in the heart, and there is a code without a code. The understanding of the code is close to the Tao.
3. There is no code in the heart, there is code and there is no code, he is the Tao.
Only when you reach the third stage can you pass the threshold of 35 years old
My thoughts after watching this project:
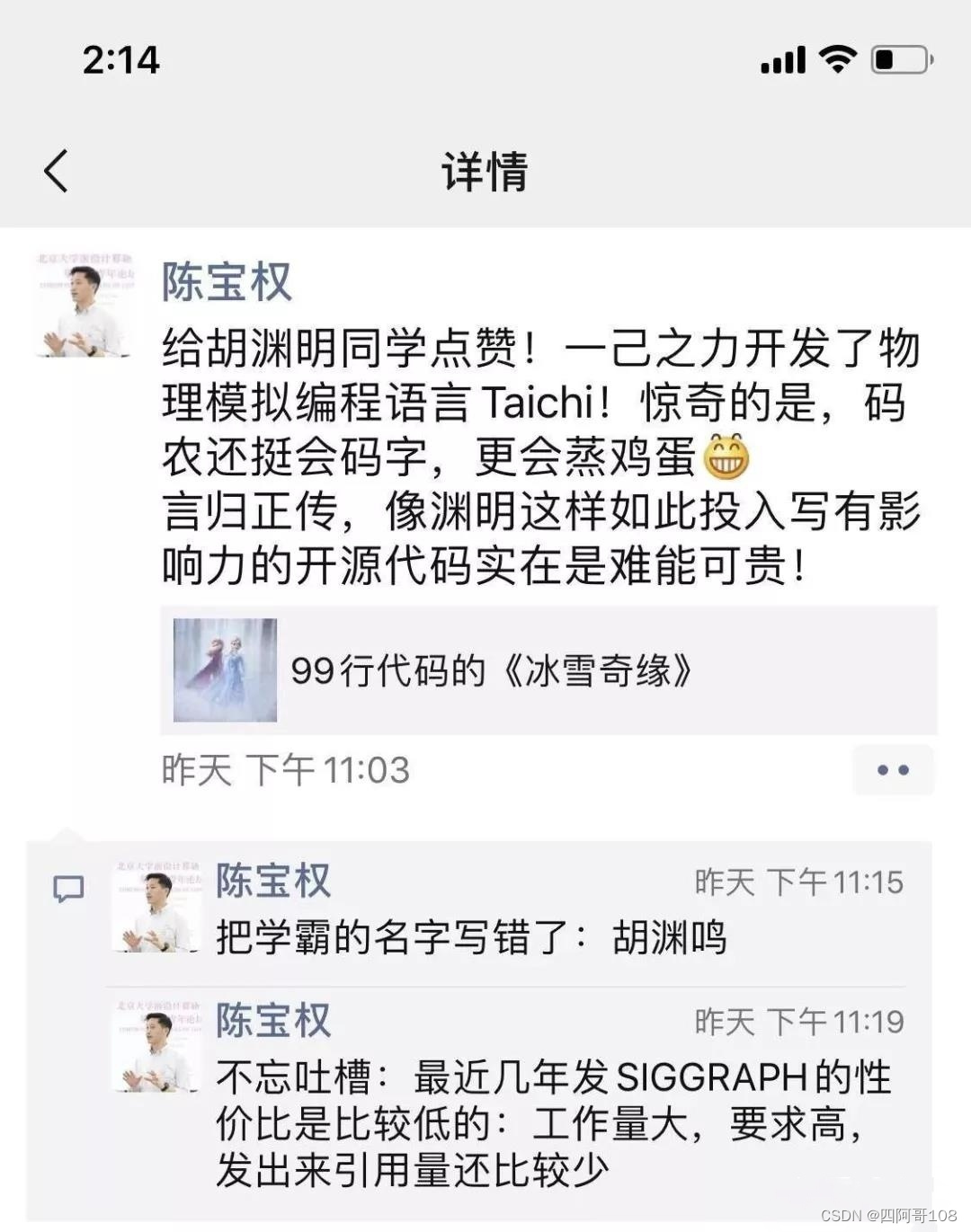
Another hardcore project for everyone: 99 lines of code to realize "Frozen"!
"Frozen" has no real actors, but the budget is as high as 150 million U.S. dollars, and every second of the shot is burning money. It is unimaginable for ordinary people to use computers to make CG special effects.
However, recently an MIT Ph.D. from China developed a physics simulation programming language: Taichi
The cost is greatly reduced.
Chen Baoquan, a well-known scholar in computer graphics and a professor at Peking University, gave a high evaluation:
#import taichi as ti
quality = 1 # Use a larger value for higher-res simulations
n_particles, n_grid = 9000 * quality ** 2, 128 * quality
dx, inv_dx = 1 / n_grid, float(n_grid)
dt = 1e-4 / quality
p_vol, p_rho = (dx * 0.5)**2, 1
p_mass = p_vol * p_rho
E, nu = 0.1e4, 0.2 # Young's modulus and Poisson's ratio
mu_0, lambda_0 = E / (2 * (1 + nu)), E * nu / ((1+nu) * (1 - 2 * nu)) # Lame parameters
x = ti.Vector(2, dt=ti.f32, shape=n_particles) # position
v = ti.Vector(2, dt=ti.f32, shape=n_particles) # velocity
C = ti.Matrix(2, 2, dt=ti.f32, shape=n_particles) # affine velocity field
F = ti.Matrix(2, 2, dt=ti.f32, shape=n_particles) # deformation gradient
material = ti.var(dt=ti.i32, shape=n_particles) # material id
Jp = ti.var(dt=ti.f32, shape=n_particles) # plastic deformation
grid_v = ti.Vector(2, dt=ti.f32, shape=(n_grid, n_grid)) # grid node momemtum/velocity
grid_m = ti.var(dt=ti.f32, shape=(n_grid, n_grid)) # grid node mass
ti.cfg.arch = ti.cuda # Try to run on GPU
@ti.kernel
def substep():
for i, j in ti.ndrange(n_grid, n_grid):
grid_v[i, j] = [0, 0]
grid_m[i, j] = 0
for p in range(n_particles): # Particle state update and scatter to grid (P2G)
base = (x[p] * inv_dx - 0.5).cast(int)
fx = x[p] * inv_dx - base.cast(float)
# Quadratic kernels [http://mpm.graphics Eqn. 123, with x=fx, fx-1,fx-2]
w = [0.5 * ti.sqr(1.5 - fx), 0.75 - ti.sqr(fx - 1), 0.5 * ti.sqr(fx - 0.5)]
F[p] = (ti.Matrix.identity(ti.f32, 2) + dt * C[p]) @ F[p] # deformation gradient update
h = ti.exp(10 * (1.0 - Jp[p])) # Hardening coefficient: snow gets harder when compressed
if material[p] == 1: # jelly, make it softer
h = 0.3
mu, la = mu_0 * h, lambda_0 * h
if material[p] == 0: # liquid
mu = 0.0
U, sig, V = ti.svd(F[p])
J = 1.0
for d in ti.static(range(2)):
new_sig = sig[d, d]
if material[p] == 2: # Snow
new_sig = min(max(sig[d, d], 1 - 2.5e-2), 1 + 4.5e-3) # Plasticity
Jp[p] *= sig[d, d] / new_sig
sig[d, d] = new_sig
J *= new_sig
if material[p] == 0: # Reset deformation gradient to avoid numerical instability
F[p] = ti.Matrix.identity(ti.f32, 2) * ti.sqrt(J)
elif material[p] == 2:
F[p] = U @ sig @ V.T() # Reconstruct elastic deformation gradient after plasticity
stress = 2 * mu * (F[p] - U @ V.T()) @ F[p].T() + ti.Matrix.identity(ti.f32, 2) * la * J * (J - 1)
stress = (-dt * p_vol * 4 * inv_dx * inv_dx) * stress
affine = stress + p_mass * C[p]
for i, j in ti.static(ti.ndrange(3, 3)): # Loop over 3x3 grid node neighborhood
offset = ti.Vector([i, j])
dpos = (offset.cast(float) - fx) * dx
weight = w[i][0] * w[j][1]
grid_v[base + offset] += weight * (p_mass * v[p] + affine @ dpos)
grid_m[base + offset] += weight * p_mass
for i, j in ti.ndrange(n_grid, n_grid):
if grid_m[i, j] > 0: # No need for epsilon here
grid_v[i, j] = (1 / grid_m[i, j]) * grid_v[i, j] # Momentum to velocity
grid_v[i, j][1] -= dt * 50 # gravity
if i < 3 and grid_v[i, j][0] < 0: grid_v[i, j][0] = 0 # Boundary conditions
if i > n_grid - 3 and grid_v[i, j][0] > 0: grid_v[i, j][0] = 0
if j < 3 and grid_v[i, j][1] < 0: grid_v[i, j][1] = 0
if j > n_grid - 3 and grid_v[i, j][1] > 0: grid_v[i, j][1] = 0
for p in range(n_particles): # grid to particle (G2P)
base = (x[p] * inv_dx - 0.5).cast(int)
fx = x[p] * inv_dx - base.cast(float)
w = [0.5 * ti.sqr(1.5 - fx), 0.75 - ti.sqr(fx - 1.0), 0.5 * ti.sqr(fx - 0.5)]
new_v = ti.Vector.zero(ti.f32, 2)
new_C = ti.Matrix.zero(ti.f32, 2, 2)
for i, j in ti.static(ti.ndrange(3, 3)): # loop over 3x3 grid node neighborhood
dpos = ti.Vector([i, j]).cast(float) - fx
g_v = grid_v[base + ti.Vector([i, j])]
weight = w[i][0] * w[j][1]
new_v += weight * g_v
new_C += 4 * inv_dx * weight * ti.outer_product(g_v, dpos)
v[p], C[p] = new_v, new_C
x[p] += dt * v[p] # advection
import random
group_size = n_particles // 3
for i in range(n_particles):
x[i] = [random.random() * 0.2 + 0.3 + 0.10 * (i // group_size), random.random() * 0.2 + 0.05 + 0.32 * (i // group_size)]
material[i] = i // group_size # 0: fluid 1: jelly 2: snow
v[i] = [0, 0]
F[i] = [[1, 0], [0, 1]]
Jp[i] = 1
import numpy as np
gui = ti.GUI("Taichi MLS-MPM-99", res=512, background_color=0x112F41)
for frame in range(20000):
for s in range(int(2e-3 // dt)):
substep()
colors = np.array([0x068587, 0xED553B, 0xEEEEF0], dtype=np.uint32)
gui.circles(x.to_numpy(), radius=1.5, color=colors[material.to_numpy()])
gui.show() # Change to gui.show(f'{frame:06d}.png') to write images to diskThis code runs with Python 3. Before running, install taichi according to the operating system and CUDA version (if CUDA is available) :
# CPU 版本 (支持Linux, OS X and Windows)
python3 -m pip install taichi-nightly
# GPU (CUDA 10.0) (只支持Linux)
python3 -m pip install taichi-nightly-cuda-10-0
# GPU (CUDA 10.1) (只支持Linux)
python3 -m pip install taichi-nightly-cuda-10-1
Although these 99 lines of code are short, the story behind them is very long.
Although the syntax looks like Python, its computing part will be taken over by a complete compilation system, and finally output executable x86_64 or PTX instructions, which can run efficiently on CPU/GPU.
Project address: https://github.com/taichi-dev/difftaichi