Artificial Intelligence (AI) has made great progress recently, especially large language models (Large Language Models, LLMs), such as ChatGPT and GPT-4, which have recently become popular all over the Internet. The GPT model has amazing results in various natural language processing tasks. As for how strong it is, I won't repeat it here. After doing AI research for so many years, I haven't been so excited for a long time. Friends who haven't tried it, try it now!

Review paper:
https://arxiv.org/pdf/2303.10158.pdf
Short introduction:
https://arxiv.org/abs/2301.04819
Github resource:
https://github.com/daochenzha/data-centric-AI

As the saying goes, "great efforts make miracles", and it has become a general consensus that adjusting the parameter amount to "big" can improve the performance of the model. But is it enough to just increase the model parameters? After carefully reading a series of GPT papers, it will be found that simply increasing the model parameters is not enough . Their success is also due in large part to the large and high-quality data used to train them .
In this article, we will analyze a series of GPT models from the perspective of data-centric artificial intelligence (we will use Data-centric AI later to avoid verbosity). Data-centric AI can be roughly divided into three goals: training data development, inference data development, and data maintenance. This article will discuss how the GPT model achieves (or may be about to achieve) these three goals. Interested readers are welcome to click the link below for more information.
1. What is a large language model?
What is the GPT model again?
This chapter will briefly introduce the large language model and the GPT model, and readers who are familiar with them can skip it. Large language models refer to a class of natural language processing models. As the name suggests, a large language model refers to a relatively "big" (neural network) language model. Language models have been studied for a long time in the field of natural language processing, and they are often used to infer the probability of words based on the above. For example, a basic function of large language models is to predict the occurrence probability of missing words or phrases based on the above. We often need to use a large amount of data to train the model so that the model can learn general laws.

Schematic diagram of predicting missing words through the above
The GPT model is a series of large language models developed by OpenAI, mainly including GPT-1, GPT-2, GPT-3, InstructGPT and the recently launched ChatGPT/GPT-4. Just like other large language models, the architecture of the GPT model is mainly based on the Transformer, which takes the vector of text and location information as input, and uses the attention mechanism to model the relationship between words.
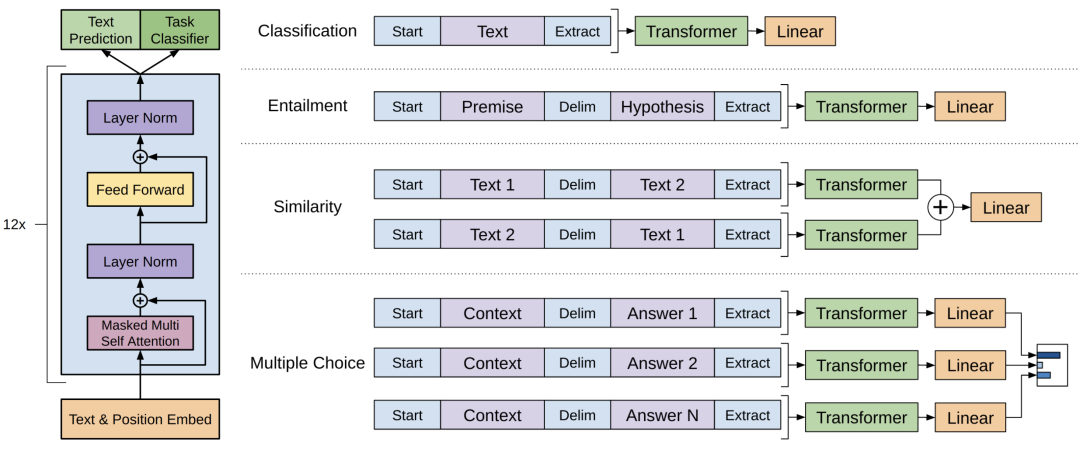
The network structure of the GPT-1 model, the picture comes from the original paper https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
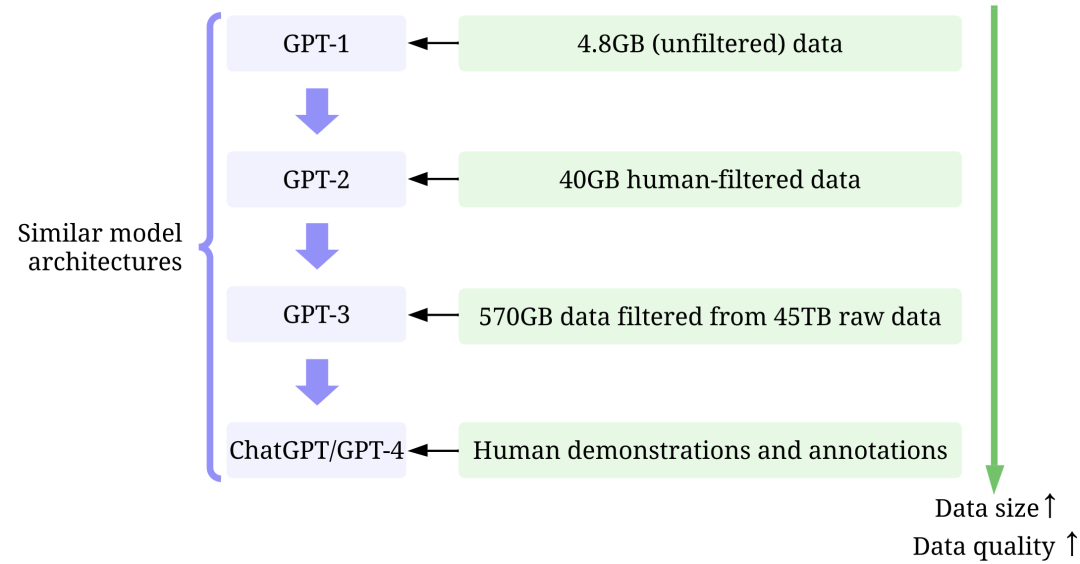
The subsequent GPT series model structures are generally similar to GPT-1, the main difference is more parameters (more layers, more hidden layer dimensions, etc.).

GPT series model size comparison
2. What is Data-centric AI?
Data-centric AI is a new concept of building an AI system, which is vigorously advocated by @吴恩达师. We quote his definition here:
Data-centric AI is the discipline of systematically engineering the data used to build an AI system.
— Andrew Ng
The traditional method of building an AI model is mainly to iterate the model, and the data is relatively fixed. For example, we usually focus on several benchmark data sets, and then design various models to improve the prediction accuracy. We call this approach model-centric. However, model-centric does not take into account various problems that may occur in data in practical applications, such as inaccurate labels, data duplication and abnormal data, etc. A model with high accuracy can only ensure that it "fits" the data well, and does not necessarily mean that it will perform well in practical applications.
Unlike model-centric, Data-centric focuses more on improving the quality and quantity of data. In other words, Data-centric AI focuses on the data itself, while the model is relatively fixed. The method using Data-centric AI will have greater potential in actual scenarios, because data largely determines the upper limit of model capabilities.
It should be noted that "Data-centric" and "Data-driven" are two fundamentally different concepts. The latter only emphasizes the use of data to guide the construction of AI systems, which still focuses on developing models rather than changing data.
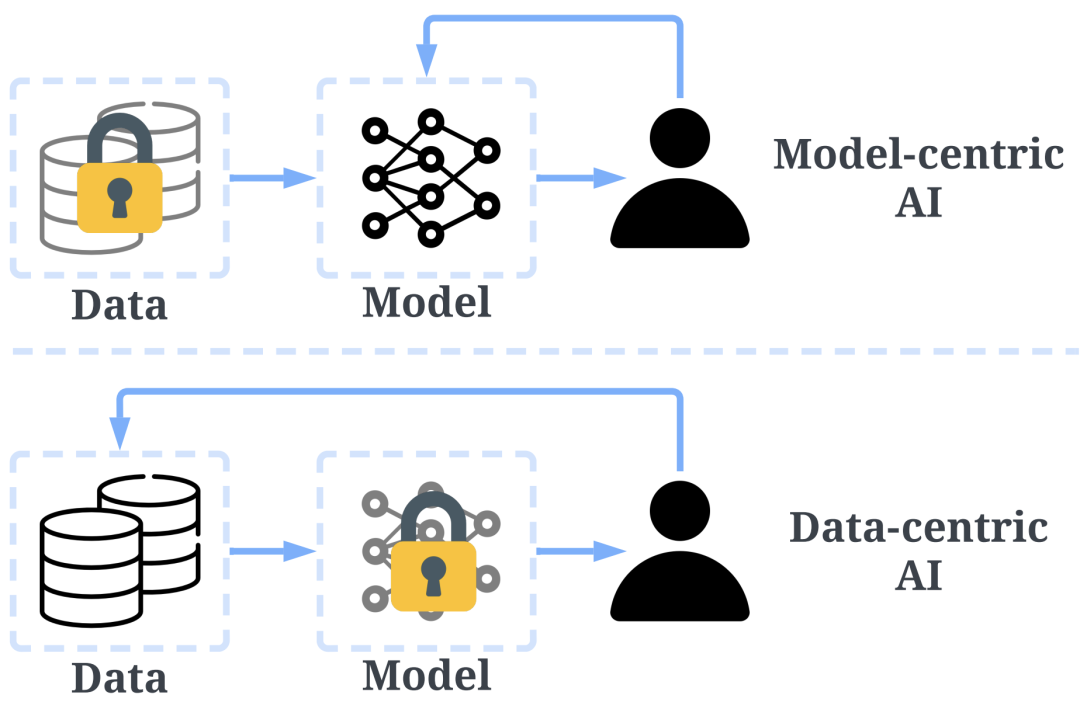
The difference between Data-centric AI and model-centric AI, the picture comes from https://arxiv.org/abs/2301.04819
The Data-centric AI framework includes three goals:
-
Training data development aims to build a sufficient amount of high-quality data to support the training of machine learning models.
-
Inference data development (inference data development) aims to construct model inference data, which is mainly used for the following two purposes:
to evaluate certain capabilities of the model, such as constructing Adversarial Attacks data to test the robustness of the model
to unlock the model Ability of some sort, such as Prompt Engineering -
Data maintenance aims to ensure the quality and reliability of data in a dynamic environment. In the actual production environment (production environment), we do not train the model only once, and the data and model need to be constantly updated. This process requires certain measures to maintain the data continuously.
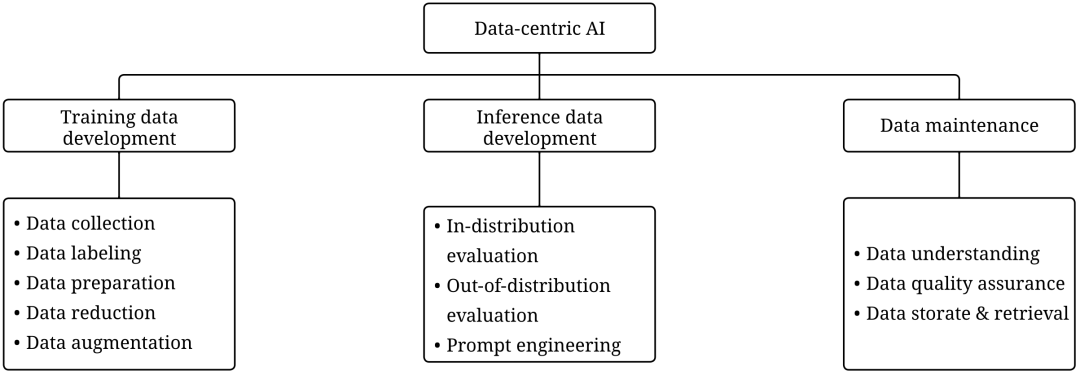
The second layer of the Data-centric AI framework is the goal, and the third layer is the sub-goal. The picture comes from https://arxiv.org/abs/2303.10158
3. Why Data-centric AI
Is it an important reason for the success of the GPT model?
A few months ago, Yann LeCun posted that ChatGPT is nothing new technically. Indeed, the methods used in ChatGPT and GPT-4, such as Transformer, "Reinforcement Learning from Human Feedback" (Reinforcement Learning from Human Feedback, RLHF), etc. are not new technologies. Even so, ChatGPT achieved amazing results that previous models could not match. So, what has driven its success?

Needless to say, increasing the number of model parameters is critical to the success of GPT models, but this is only one of the reasons. By reading the descriptions of the data in the GPT-1, GPT-2, GPT-3, InstructGPT and ChatGPT/GPT-4 papers in detail, we can clearly see that OpenAI engineers have spent a lot of effort to improve the quality and quantity of data . Below, we use the Data-centric AI framework to analyze from three dimensions.
Training data development: From GPT-1 to ChatGPT/GPT-4, through better data collection (data collection), data labeling (data labeling) and data preparation (data preparation) strategies, the amount of data used to train the GPT model and Quality has been significantly improved. The following brackets identify each specific strategy corresponding to the sub-goals in the Data-centric AI framework.
i. Data-centric AI strategy used: None.
ii. Results: After pre-training, fine-tuning on downstream tasks improves performance.
b. Use Dragnet and Newspaper to extract plain text (data collection)
c. Use some heuristic strategies to do deduplication and data cleaning, the specific strategies are not mentioned in the paper (data preparation)
ii. Results: After screening, 40 GB of text was obtained (about 8.6 times the data used by GPT-1). GPT-2 can achieve very good results even without fine-tuning.
a. Train a classifier to filter out low-quality documents. What is more interesting here is that OpenAI regards WebText as a standard and judges the quality based on the similarity between each document and WebText (data collection)
b. Use Spark's MinHashLSH to fuzzy and deduplicate documents (data preparation)
c. Added the previous WebText extension, and added books corpora and Wikipedia data (data collection)
ii. Results: After quality filtering of 45TB of plain text, 570GB of text was obtained (only 1.27% of the data was selected, which shows that the quality control is very strong, and the filtered text is about GPT-2 14.3 times) . The trained model is stronger than GPT-2.
i. Data-cen tric AI strategy used :
a. Use human-provided answers to fine-tune the model in a supervised manner. OpenAI is extremely strict in the selection of annotators. It has conducted tests on the annotators and even sent out questionnaires at the end to ensure that the annotators have a better experience. If my research project needs manual labeling, it would be nice if someone can take care of me, let alone exams and questionnaires (data labeling)
b. Collect comparative data (humans rank the generated answers in order of how good they are) to train a reward model, then use Reinforcement Learning from Human Feedback (RLHF) to fine-tune based on the reward model (data annotation)
ii. Results: InstructGPT produces results that are more realistic, less biased, and more in line with human expectations.
-
GPT-1: Training used the BooksCorpus dataset. This dataset contains 4629.00 MB of raw text, covering various genres of books such as adventure, fantasy, and romance, etc.
-
GPT-2: Training used the WebText dataset. This is an internal OpenAI dataset created by scraping outbound links from Reddit.
i. Data-centric AI strategy used:
a. Only screen and use links on Reddit with at least 3 karma and above (data collection)
-
GPT-3: The training mainly uses Common Crawl, a large but not very good data set.
i. Data-centric AI strategy used:
-
InstructGPT: Use human feedback to fine-tune the model on top of GPT-3, making the model match human expectations.
-
ChatGPT/GPT-4: At this point, the product is commercialized, and OpenAI is no longer "Open", and no specific details will be disclosed. What is known is that ChatGPT/GPT-4 largely follows the design of previous GPT models, and still uses RLHF to tune the model (possibly using more and higher quality data/labels). Given that the inference speed of GPT-4 is much slower than that of ChatGPT, and the number of parameters of the model is likely to increase, it is also very likely that a larger data set was used.
From GPT-1 to ChatGPT/GPT-4, the training data used has generally undergone the following changes: small data (small is for OpenAI, not small for ordinary researchers) -> larger high-quality data -> Larger and higher quality data -> High-quality data marked by high-quality humans (referring to annotators who can pass the exam). The model design has not changed significantly (except for more parameters to accommodate more data), which is in line with the concept of Data-centric AI. From the success of ChatGPT/GPT-4, we can find that high-quality annotation data is crucial . This is true in almost any subfield of AI, and even on many traditionally unsupervised tasks, annotated data can significantly improve performance, such as weakly supervised anomaly detection. OpenAI's emphasis on data and label quality is outrageous . It is this obsession that has created the success of the GPT model. By the way, I would like to recommend Potato, a visual text annotation tool made by a friend, which is very easy to use!
Inference data development: The current ChatGPT/GPT-4 model is strong enough that we only need to adjust the prompt (inference data) to achieve various purposes, while the model remains unchanged. For example, we can provide a long text, plus specific instructions, such as "summarize it" or "TL;DR", and the model can automatically generate a summary. In this emerging model, data-centric AI has become more important. In the future, many AI workers may no longer need to train models, but only for prompt engineering.

Prompt engineering example, the picture comes from https://arxiv.org/abs/2303.10158
Of course, tip engineering is a challenging task that relies heavily on experience. This review provides a good summary of the various approaches, and interested readers are encouraged to read on. At the same time, even for semantically similar prompts, the output can be very different. In this case, some strategies may be needed to reduce the variance of the output, such as Soft Prompt-Based Calibration.
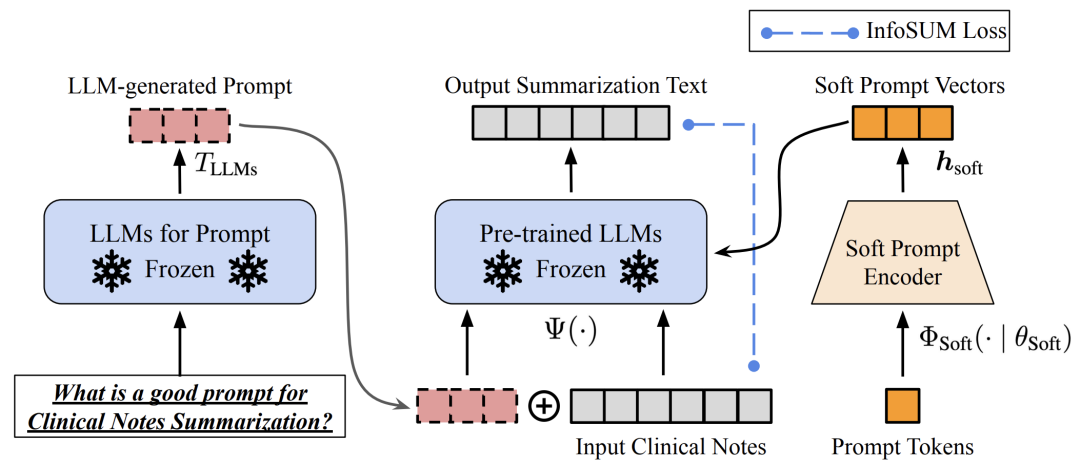
Soft prompt-based calibration, picture from https://arxiv.org/abs/2303.13035v1
Research on the development of inference data for large language models is still in its early stages. I believe that in the near future, the inference data development methods used in many other tasks will gradually be migrated to large language models, such as building Adversarial Attacks data to test the robustness of the model.
Data maintenance: As a commercial product, ChatGPT/GPT-4 must not be finished after just one training, but will be continuously updated and maintained. We have no way to know how OpenAI data maintenance is carried out externally. Therefore, we can only speculate. OpenAI may have adopted the following strategies:
-
Ongoing Data Collection: When we use ChatGPT/GPT-4, the hints we input and the feedback we provide can be used by OpenAI to further improve their models. During this process, model developers need to design indicators for monitoring data quality and strategies for maintaining data quality in order to collect higher quality data.
-
Data understanding tools: Developing various tools to visualize and understand user data can help to better understand user needs and guide future improvement directions.
-
Efficient data processing: With the rapid growth of the number of ChatGPT/GPT-4 users, an efficient data management system needs to be developed to help quickly obtain relevant data for training and testing.

ChatGPT/GPT-4 will collect user feedback
4. What can we learn from the success of large language models?
The success of the large language model can be said to be subversive. Looking ahead, I make a few predictions:
-
Data-centric AI becomes even more important. After years of research, the model design has been relatively mature, especially after the emergence of Transformer (we still don't seem to see the upper limit of Transformer). Improving the quantity and quality of data will be the key (or perhaps the only) way to improve the capabilities of AI systems in the future. Also, most people probably won't need to retrain models when they become sufficiently powerful. Instead, we only need to design appropriate inference data (hint engineering) to acquire knowledge from the model. Therefore, the research and development of Data-centric AI will continue to promote the progress of future AI systems.
-
Large language models will provide better solutions for Data-centric AI. Many tedious data-related tasks can now be done more efficiently with the help of large language models. For example, ChatGPT/GPT-4 can already write and run code to process and clean data. Furthermore, large language models can even be used to create training data. For example, recent studies have shown that using large language models to synthesize data can improve the performance of clinical text mining models.
-
The lines between data and models will become blurred. Historically, data and models were two separate concepts. However, when the model is powerful enough, the model becomes a kind of "data" or a "container" of data. When needed, we can design appropriate prompts and use large language models to synthesize the data we want. This synthetic data can in turn be used to train models. The feasibility of this method has been verified to a certain extent on GPT-4. In the report, a method called rule-based reward models (RBRMs) uses GPT-4 to judge whether the data is safe by itself. These labeled data are in turn used to train the reward model to fine-tune GPT-4. There is a feeling of left and right hands fighting each other. I've been wondering, will future models evolve themselves in this way? Think carefully...
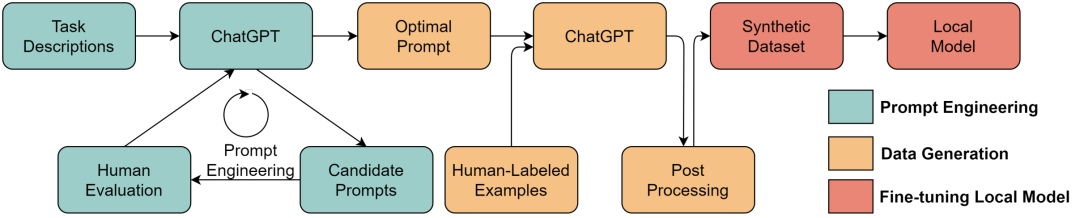
Use ChatGPT to synthesize data to train downstream models, the picture comes from https://arxiv.org/abs/2303.04360
Recalling five years ago, I was still struggling with "how to improve the accuracy of text classification". The experience of many failures once made me suspect that natural language processing had nothing to do with AI. Now the amazing ability of ChatGPT/GPT-4 allows me to witness history in advance!
Where will the development of AI go in the future? The progress of large language models is changing with each passing day. I often see some friends who study natural language processing worrying whether the emergence of large models will make AI research nowhere to go. I don't think there is any need to worry about that. Technology is always improving. The emergence of new technologies will inevitably replace old technologies (this is progress), but at the same time it will also give rise to more new research directions. For example, the rapid development of deep learning in recent years has not made traditional machine learning research impossible, on the contrary, it has provided more directions for research.
At the same time, a breakthrough in one subfield of AI will inevitably lead to the vigorous development of other subfields, and there are many new issues to be studied. For example, breakthroughs in large models represented by ChatGPT/GPT-4 are likely to lead to further improvements in computer vision, and will also inspire many AI-driven application scenarios, such as finance, medical care, and so on. No matter how the technology develops, improving the quality and quantity of data must be an effective way to improve AI performance, and the concept of Data-cen tric AI will become more and more important.
So is the large model necessarily the direction to achieve general artificial intelligence? I have reservations. Throughout the development of AI, the development of various AI sub-fields is often a spiral and mutually driven. The success of this large model is the result of the successful collision of multiple subfields, such as model design (Transformer), Data-centric AI (emphasis on data quality), reinforcement learning (RLHF), machine learning system (large-scale cluster training ) and so on, both are indispensable. In the era of large models, we still have great potential in all sub-fields of AI. For example, I think that reinforcement learning may have a higher upper limit than large models, because it can iterate itself, and we may witness more amazing results led by reinforcement learning than ChatGPT in the near future. Readers who are interested in reinforcement learning can pay attention to my previous article DouZero Fighting the Landlord AI In-depth Analysis, and the introduction of the RLCard toolkit.
In this era of rapid AI development, we need to keep learning. We have summarized the field of Data-centric AI, hoping to help you understand this field quickly and efficiently. For related links, see the beginning of this article. Given that Data-centric AI is a large field, our summary is difficult to cover. Interested readers are welcome to make corrections and supplements on our GitHub.
//
about the author

Cha Daochen
PhD candidate at Rice University
Daochen Zha is currently a doctoral student at Rice University, mainly engaged in research in reinforcement learning and data mining. His work has been published in major machine learning and data mining conferences, including ICML, NeurIPS, KDD, AAAI, etc. He is the author of several machine learning projects, including DouZero, RLCard, TODS, AutoVideo, etc., which have received more than 8,000 stars on GitHub in total. Winner of "2022 Celebrity List - Most Popular Speaker" in TechBeat technology community.
Author: Cha Daochen
Source: Zhihu article https://zhuanlan.zhihu.com/p/617057227
Illustration by IconScout Store from IconScout
-The End-