Hallo zusammen, ich bin Mr. CV, macht Ihnen die Geschwindigkeit von Deep-Learning-Algorithmen Sorgen? Dieses Mal widmete sich Herr CV dem Teilen einer hervorragenden Methode, die das Geschwindigkeitsproblem durch das Ähnlichkeits- und Verfolgungsschema optimiert und die Stabilität der Erkennungs- und Segmentierungsalgorithmen verbessert, mit angehängtem Code, lasst uns zusammen aufstehen~
Heute werde ich Ihnen eine vollständige Erklärung des Bildähnlichkeitsalgorithmus und des Tracking-Algorithmus geben. Einfach ausgedrückt handelt es sich um einen Algorithmus zur Beurteilung, ob zwei Bilder, Videos und Bilder ähnlich sind.
was kann getan werden
1: Wenn Ihr Chef sagt, dass Ihr Objekterkennungsalgorithmus zeitaufwändig, leistungsaufwändig und speicherintensiv ist : Bitte fügen Sie unbedingt den Ähnlichkeitsalgorithmus hinzu! Ultraniedriger Energieverbrauch, ultraschnelle Geschwindigkeit, geeignet für einige Szenarien: Wenn Ihr Erkennungsalgorithmus langsam und der Stromverbrauch hoch ist, müssen Sie tatsächlich nicht jede Sekunde erkennen. Die Ähnlichkeit ist zu gering: Das heißt, nachdem sich der Bildschirm zu stark verändert hat, wird er erneut erkannt oder nach einigen Sekunden erneut erkannt und verfolgt, und der Stromverbrauch wird stark reduziert.
2: Beurteilen, ob sich der Bildschirm ändert , jemand in Ihr Haus einbricht, und wenn es dunkel ist, ist es für den maskierten Dieb schwierig, vom Ziel erkannt und am Gesicht erkannt zu werden.
3: Wenn die Kamera eine Vorschau anzeigt, ob sich das Bild ändert: Fokus, Objektbewegung, ob das Bild vergrößert oder verkleinert wird und ob sich der Gimbal dreht.
4: Ob das Bild stabil ist.
5: Wer ist sich zwischen den Bildern am ähnlichsten und am wenigsten ähnlich?
6: Es wird für Superauflösung, Entnebelung, Regenentfernung, Reibungsentfernung, Bildwiederherstellung und verschiedene Bildanpassungen verwendet, um die größtmögliche Ähnlichkeit mit Ihrem GT zu erreichen, und es wird zur Verlustberechnung verwendet.
usw.
Vollständige Lösung des Ähnlichkeitsalgorithmus
1. Cosinus-Ähnlichkeitsberechnung
Stellen Sie das Bild als Vektor dar und charakterisieren Sie die Ähnlichkeit zweier Bilder, indem Sie den Kosinusabstand zwischen den Vektoren berechnen.
# -*- coding: utf-8 -*-
# !/usr/bin/env python
# 余弦相似度计算
from PIL import Image
from numpy import average, dot, linalg
# 对图片进行统一化处理
def get_thum(image, size=(64, 64), greyscale=False):
# 利用image对图像大小重新设置, Image.ANTIALIAS为高质量的
image = image.resize(size, Image.ANTIALIAS)
if greyscale:
# 将图片转换为L模式,其为灰度图,其每个像素用8个bit表示
image = image.convert('L')
return image
# 计算图片的余弦距离
def image_similarity_vectors_via_numpy(image1, image2):
image1 = get_thum(image1)
image2 = get_thum(image2)
images = [image1, image2]
vectors = []
norms = []
for image in images:
vector = []
for pixel_tuple in image.getdata():
vector.append(average(pixel_tuple))
vectors.append(vector)
# linalg=linear(线性)+algebra(代数),norm则表示范数
# 求图片的范数
norms.append(linalg.norm(vector, 2))
a, b = vectors
a_norm, b_norm = norms
# dot返回的是点积,对二维数组(矩阵)进行计算
res = dot(a / a_norm, b / b_norm)
return res
image1 = Image.open('010.jpg')
image2 = Image.open('011.jpg')
cosin = image_similarity_vectors_via_numpy(image1, image2)
print('图片余弦相似度', cosin)
# 输出结果
# 图片余弦相似度 0.98584161582533342. Hash-Algorithmus zur Berechnung der Ähnlichkeit von Bildern
Mr. cv kurze Einführung Hash- Hash-Algorithmus ist ein allgemeiner Begriff für eine Klasse von Algorithmen, einschließlich aHash, pHash, dHash. Wie der Name schon sagt, berechnet Hashing den Hashwert nicht streng, sondern eher relativ, da "Ähnlichkeit" oder nicht eine relative Beurteilung ist.
Vergleich mehrerer Hashwerte:
-
aHash: Durchschnittlicher Hash. Schneller, aber oft weniger genau.
-
pHash: Wahrnehmungs-Hashing. Die Genauigkeit ist relativ hoch, aber die Geschwindigkeit ist relativ schlecht.
-
dHash: Differenzwert-Hash. Hohe Genauigkeit und sehr schnelle Geschwindigkeit
Wert-Hash-Algorithmus , Differenz-Hash-Algorithmus und Wahrnehmungs-Hash-Algorithmus haben alle kleinere Werte, eine höhere Ähnlichkeit, und der Wert ist 0-64, das heißt, wie viele verschiedene 64-Bit-Hash-Werte sich in der Hamming-Distanz befinden. Der Wert des Drei-Histogramms und des Einzelkanal-Histogramms ist 0–1, je größer der Wert, desto höher die Ähnlichkeit.

Mr. cv gibt auch die Zeit des Algorithmus aus. Wir skalieren die Bilder für die Ähnlichkeitsberechnung auf 8 * 8. Zu diesem Zeitpunkt dauert die Cosinus-Ähnlichkeit 16,9 ms, während der Hash-Algorithmus nahe bei 0 ms liegt, das 3-Kanal-Histogramm 5 ms und das Einkanal-Histogramm 1 ms dauert auf den folgenden beiden Bildern erkennen kann, gibt es ein paar Unterschiede, aber die Gesamtähnlichkeit, subjektiv denken wir, dass sie sich auf den ersten Blick sehr ähnlich sind, aber wenn Sie genau hinsehen, werden Sie feststellen, dass es mehrere Unterschiede gibt, also die Ähnlichkeit, mehrere Methoden sind unterschiedlich Nicht ganz gleich.
Wir brauchen jedoch einen stabilen Algorithmus, der ähnlich sein sollte und nicht ähnlich sein sollte.
Durch umfangreiche Experimente empfiehlt Mr. CV, dass Sie ein einkanaliges Histogrammschema verwenden. Oder Wahrnehmungs-Hashing.

der Code
# -*- coding: utf-8 -*-
# !/usr/bin/env python
# 余弦相似度计算
from PIL import Image
from numpy import average, dot, linalg
import time
# 对图片进行统一化处理
def get_thum(image, size=(8, 8), greyscale=False):
# 利用image对图像大小重新设置, Image.ANTIALIAS为高质量的
image = image.resize(size, Image.ANTIALIAS)
if greyscale:
# 将图片转换为L模式,其为灰度图,其每个像素用8个bit表示
image = image.convert('L')
return image
# 计算图片的余弦距离
def image_similarity_vectors_via_numpy(image1, image2):
image1 = get_thum(image1)
image2 = get_thum(image2)
images = [image1, image2]
vectors = []
norms = []
for image in images:
vector = []
for pixel_tuple in image.getdata():
vector.append(average(pixel_tuple))
vectors.append(vector)
# linalg=linear(线性)+algebra(代数),norm则表示范数
# 求图片的范数
norms.append(linalg.norm(vector, 2))
a, b = vectors
a_norm, b_norm = norms
# dot返回的是点积,对二维数组(矩阵)进行计算
res = dot(a / a_norm, b / b_norm)
return res
image1 = Image.open('1.jpg')
image2 = Image.open('2.jpg')
time1 = time.time()
cosin = image_similarity_vectors_via_numpy(image1, image2)
print('图片余弦相似度', cosin, '时间:', time.time() - time1)
import cv2
import numpy as np
from PIL import Image
import requests
from io import BytesIO
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
def aHash(img):
# 均值哈希算法
# 缩放为8*8
img = cv2.resize(img, (8, 8))
# 转换为灰度图
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# s为像素和初值为0,hash_str为hash值初值为''
s = 0
hash_str = ''
# 遍历累加求像素和
for i in range(8):
for j in range(8):
s = s + gray[i, j]
# 求平均灰度
avg = s / 64
# 灰度大于平均值为1相反为0生成图片的hash值
for i in range(8):
for j in range(8):
if gray[i, j] > avg:
hash_str = hash_str + '1'
else:
hash_str = hash_str + '0'
return hash_str
def dHash(img):
# 差值哈希算法
# 缩放8*8
img = cv2.resize(img, (9, 8))
# 转换灰度图
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
hash_str = ''
# 每行前一个像素大于后一个像素为1,相反为0,生成哈希
for i in range(8):
for j in range(8):
if gray[i, j] > gray[i, j + 1]:
hash_str = hash_str + '1'
else:
hash_str = hash_str + '0'
return hash_str
def pHash(img):
# 感知哈希算法
# 缩放32*32
img = cv2.resize(img, (32, 32)) # , interpolation=cv2.INTER_CUBIC
# 转换为灰度图
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 将灰度图转为浮点型,再进行dct变换
dct = cv2.dct(np.float32(gray))
# opencv实现的掩码操作
dct_roi = dct[0:8, 0:8]
hash = []
avreage = np.mean(dct_roi)
for i in range(dct_roi.shape[0]):
for j in range(dct_roi.shape[1]):
if dct_roi[i, j] > avreage:
hash.append(1)
else:
hash.append(0)
return hash
def calculate(image1, image2):
# 灰度直方图算法
# 计算单通道的直方图的相似值
hist1 = cv2.calcHist([image1], [0], None, [256], [0.0, 255.0])
hist2 = cv2.calcHist([image2], [0], None, [256], [0.0, 255.0])
# 计算直方图的重合度
degree = 0
for i in range(len(hist1)):
if hist1[i] != hist2[i]:
degree = degree + \
(1 - abs(hist1[i] - hist2[i]) / max(hist1[i], hist2[i]))
else:
degree = degree + 1
degree = degree / len(hist1)
return degree
def classify_hist_with_split(image1, image2, size=(256, 256)):
# RGB每个通道的直方图相似度
# 将图像resize后,分离为RGB三个通道,再计算每个通道的相似值
image1 = cv2.resize(image1, size)
image2 = cv2.resize(image2, size)
sub_image1 = cv2.split(image1)
sub_image2 = cv2.split(image2)
sub_data = 0
for im1, im2 in zip(sub_image1, sub_image2):
sub_data += calculate(im1, im2)
sub_data = sub_data / 3
return sub_data
def cmpHash(hash1, hash2):
# Hash值对比
# 算法中1和0顺序组合起来的即是图片的指纹hash。顺序不固定,但是比较的时候必须是相同的顺序。
# 对比两幅图的指纹,计算汉明距离,即两个64位的hash值有多少是不一样的,不同的位数越小,图片越相似
# 汉明距离:一组二进制数据变成另一组数据所需要的步骤,可以衡量两图的差异,汉明距离越小,则相似度越高。汉明距离为0,即两张图片完全一样
n = 0
# hash长度不同则返回-1代表传参出错
if len(hash1) != len(hash2):
return -1
# 遍历判断
for i in range(len(hash1)):
# 不相等则n计数+1,n最终为相似度
if hash1[i] != hash2[i]:
n = n + 1
return n
def getImageByUrl(url):
# 根据图片url 获取图片对象
html = requests.get(url, verify=False)
image = Image.open(BytesIO(html.content))
return image
def PILImageToCV():
# PIL Image转换成OpenCV格式
path = "/Users/waldenz/Documents/Work/doc/TestImages/t3.png"
img = Image.open(path)
plt.subplot(121)
plt.imshow(img)
print(isinstance(img, np.ndarray))
img = cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR)
print(isinstance(img, np.ndarray))
plt.subplot(122)
plt.imshow(img)
plt.show()
def CVImageToPIL():
# OpenCV图片转换为PIL image
path = "/Users/waldenz/Documents/Work/doc/TestImages/t3.png"
img = cv2.imread(path)
# cv2.imshow("OpenCV",img)
plt.subplot(121)
plt.imshow(img)
img2 = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plt.subplot(122)
plt.imshow(img2)
plt.show()
def bytes_to_cvimage(filebytes):
# 图片字节流转换为cv image
image = Image.open(filebytes)
img = cv2.cvtColor(np.asarray(image), cv2.COLOR_RGB2BGR)
return img
def runAllImageSimilaryFun(para1, para2):
# 均值、差值、感知哈希算法三种算法值越小,则越相似,相同图片值为0
# 三直方图算法和单通道的直方图 0-1之间,值越大,越相似。 相同图片为1
# t1,t2 14;19;10; 0.70;0.75
# t1,t3 39 33 18 0.58 0.49
# s1,s2 7 23 11 0.83 0.86 挺相似的图片
# c1,c2 11 29 17 0.30 0.31
if para1.startswith("http"):
# 根据链接下载图片,并转换为opencv格式
img1 = getImageByUrl(para1)
img1 = cv2.cvtColor(np.asarray(img1), cv2.COLOR_RGB2BGR)
img2 = getImageByUrl(para2)
img2 = cv2.cvtColor(np.asarray(img2), cv2.COLOR_RGB2BGR)
else:
# 通过imread方法直接读取物理路径
img1 = cv2.imread(para1)
img2 = cv2.imread(para2)
time1 = time.time()
hash1 = aHash(img1)
hash2 = aHash(img2)
n1 = cmpHash(hash1, hash2)
print('均值哈希算法相似度aHash:', n1, '时间:', time.time() - time1)
time1 = time.time()
hash1 = dHash(img1)
hash2 = dHash(img2)
n2 = cmpHash(hash1, hash2)
print('差值哈希算法相似度dHash:', n2, '时间:', time.time() - time1)
time1 = time.time()
hash1 = pHash(img1)
hash2 = pHash(img2)
n3 = cmpHash(hash1, hash2)
print('感知哈希算法相似度pHash:', n3, '时间:', time.time() - time1)
time1 = time.time()
n4 = classify_hist_with_split(img1, img2)
print('三直方图算法相似度:', n4, '时间:', time.time() - time1)
time1 = time.time()
n5 = calculate(img1, img2)
print("单通道的直方图", n5, '时间:', time.time() - time1)
print("%d %d %d %.2f %.2f " % (n1, n2, n3, round(n4[0], 2), n5[0]))
print("相似概率|均值: %.2f 差值: %.2f 感知: %.2f 三直方图: %.2f 单通道: %.2f " % (1 - float(n1 / 64), 1 -
float(n2 / 64), 1 - float(n3 / 64), round(n4[0], 2), n5[0]))
plt.subplot(121)
plt.imshow(Image.fromarray(cv2.cvtColor(img1, cv2.COLOR_BGR2RGB)))
plt.subplot(122)
plt.imshow(Image.fromarray(cv2.cvtColor(img2, cv2.COLOR_BGR2RGB)))
plt.show()
if __name__ == "__main__":
p1 = "1.jpg"
p2 = "2.jpg"
runAllImageSimilaryFun(p1, p2)3. Histogramm zur Berechnung der Bildähnlichkeit
Wird das Histogramm zur Berechnung der Ähnlichkeit des Bildes verwendet, wird es nach der globalen Verteilung der Farbe betrachtet und die Lokalfarbe kann nicht analysiert werden Wird das gleiche Bild in ein Graustufenbild umgewandelt, ist die Lücke bei der Berechnung noch größer sein Histogramm. Für das Graustufenbild kann das Bild gleichmäßig geteilt werden, und dann wird die Ähnlichkeit des Bildes berechnet.
Der Code ist auch oben, hier ist eine zusätzliche Größe (64, 64)
# 将图片转化为RGB
def make_regalur_image(img, size=(64, 64)):
gray_image = img.resize(size).convert('RGB')
return gray_image
# 计算直方图
def hist_similar(lh, rh):
assert len(lh) == len(rh)
hist = sum(1 - (0 if l == r else float(abs(l - r)) / max(l, r)) for l, r in zip(lh, rh)) / len(lh)
return hist
# 计算相似度
def calc_similar(li, ri):
calc_sim = hist_similar(li.histogram(), ri.histogram())
return calc_sim
if __name__ == '__main__':
image1 = Image.open('123.jpg')
image1 = make_regalur_image(image1)
image2 = Image.open('456.jpg')
image2 = make_regalur_image(image2)
print("图片间的相似度为", calc_similar(image1, image2))4. SSIM (Structural Similarity Measure) berechnet die Ähnlichkeit von Bildern (Hervorhebung)
Dies ist eine wichtige Methode zur Bildwiederherstellung und wird häufig in Verlustfunktionen verwendet
SSIM ist ein Vollreferenzindex zur Bewertung der Bildqualität, der die Bildähnlichkeit anhand von drei Aspekten misst: Helligkeit, Kontrast und Struktur. Der Wertebereich von SSIM ist [0, 1] Je größer der Wert, desto geringer die Bildverzerrung. In praktischen Anwendungen kann das Schiebefenster verwendet werden, um das Bild in Blöcke zu unterteilen, und die Gesamtzahl der Blöcke ist N. Unter Berücksichtigung des Einflusses der Fensterform auf die Blöcke wird die Gaußsche Gewichtung verwendet, um den Mittelwert, die Varianz und die Kovarianz von zu berechnen jedes Fenster, und dann den entsprechenden Block berechnen. Als strukturelles Ähnlichkeitsmaß der beiden Bilder wird die strukturelle Ähnlichkeit SSIM der beiden Bilder und schließlich der Mittelwert verwendet, dh die durchschnittliche strukturelle Ähnlichkeit SSIM.
import numpy
import numpy as np
import math
import cv2
import torch
import pytorch_ssim
from torch.autograd import Variable
original = cv2.imread("1.jpg") # numpy.adarray
original = cv2.resize(original, (256, 256))
contrast = cv2.imread("2.jpg",1)
contrast = cv2.resize(contrast, (256, 256))
def psnr(img1, img2):
mse = numpy.mean( (img1 - img2) ** 2 )
if mse == 0:
return 100
PIXEL_MAX = 255.0
return 20 * math.log10(PIXEL_MAX / math.sqrt(mse))
def ssim_2(img1, img2):
"""Calculate SSIM (structural similarity) for one channel images.
It is called by func:`calculate_ssim`.
Args:
img1 (ndarray): Images with range [0, 255] with order 'HWC'.
img2 (ndarray): Images with range [0, 255] with order 'HWC'.
Returns:
float: ssim result.
"""
C1 = (0.01 * 255)**2
C2 = (0.03 * 255)**2
img1 = img1.astype(np.float64)
img2 = img2.astype(np.float64)
kernel = cv2.getGaussianKernel(11, 1.5)
window = np.outer(kernel, kernel.transpose())
mu1 = cv2.filter2D(img1, -1, window)[5:-5, 5:-5]
mu2 = cv2.filter2D(img2, -1, window)[5:-5, 5:-5]
mu1_sq = mu1**2
mu2_sq = mu2**2
mu1_mu2 = mu1 * mu2
sigma1_sq = cv2.filter2D(img1**2, -1, window)[5:-5, 5:-5] - mu1_sq
sigma2_sq = cv2.filter2D(img2**2, -1, window)[5:-5, 5:-5] - mu2_sq
sigma12 = cv2.filter2D(img1 * img2, -1, window)[5:-5, 5:-5] - mu1_mu2
# 公式二计算
ssim_map = ((2 * mu1_mu2 + C1) *
(2 * sigma12 + C2)) / ((mu1_sq + mu2_sq + C1) *
(sigma1_sq + sigma2_sq + C2))
return ssim_map.mean()
psnrValue = psnr(original,contrast)
ssimValue = ssim_2(original,contrast)
print('PSNR: ', psnrValue)
print('SSIM: ',ssimValue)SSIM als Pytorch-Verlustfunktionscode: Berechnen Sie ssim und ms-ssim basierend auf Pytorch
psnr und ssim können Sie auf die Online-Referenz verweisen, die häufig in der Verlustfunktion verwendet wird. Sie können sich die Pytorch-Version von SSIM und PSNR ansehen

Je größer der PSNR ist, desto ähnlicher ist er.Im Allgemeinen macht es nicht viel Sinn, wenn er über 30 liegt, und der Unterschied ist mit bloßem Auge fast unsichtbar. Zu diesem Zeitpunkt werden andere Indikatoren benötigt.
SSIM ist näher an 1, je ähnlicher. Die Hälfte davon wird für Restaurierungsaufgaben wie Rauschunterdrückung verwendet.Hier sind wir: Finden Sie verschiedene Aufgaben, und die Abweichung ist groß~ Folgen Sie dem Schreiben von Artikeln im Bereich der Bildrestaurierung~
gegenseitige Information
Gegenseitige Informationen sind ein nützliches Maß für Informationen in der Informationstheorie . Sie können als die Menge an Informationen angesehen werden, die in einer Zufallsvariablen
Normalisierte gegenseitige Informationen (NMI) sollen die gegenseitigen Informationen zwischen [0,1]
from sklearn import metrics as mr
img1 = cv2.imread('1.jpg')
img2 = cv2.imread('2.jpg')
img2 = cv2.resize(img2, (img1.shape[1], img1.shape[0]))
nmi = mr.normalized_mutual_info_score(img1.reshape(-1), img2.reshape(-1))
print('nmi: ', nmi)Der NMI liegt nahe bei 1 für volle Punktzahl.
Pixelübereinstimmung
Verwenden Sie die Übereinstimmung zwischen Pixeln, um die Ähnlichkeit zu berechnen. In Bezug auf die Geschwindigkeit beträgt das folgende Beispiel 7 ms, was immer noch relativ langsam, aber relativ genau ist. Sie können wissen, welche Pixel der beiden Bilder nicht sehr ähnlich sind, und dann markieren Das Ergebnis ist in der Abbildung dargestellt:

Das obige Bild ist das gleiche wie die beiden Bilder, und es wird in heller Farbe angezeigt, was darauf hinweist, dass sie genau gleich sind; wenn es Unterschiede gibt, werden sie umrandet. Das Bild unten ist das Ergebnis des folgenden Codes:

#第一步:
# pip install pixelmatch
#第二步:
from PIL import Image
from pixelmatch.contrib.PIL import pixelmatch
img_a = Image.open("1.jpg").resize((64, 64))
img_b = Image.open("2.jpg").resize((64, 64))
img_diff = Image.new("RGBA", img_a.size)
# note how there is no need to specify dimensions
time1 = time.time()
mismatch = pixelmatch(img_a, img_b, img_diff, includeAA=True)
print('pixelmatch Time: ', time.time() - time1)
img_diff.save("diff1.png")md5
Der grobe md5-Vergleich gibt zurück, ob sie genau gleich sind, und die verwendete Hash-Methode kann nur herausfinden, ob sie genau gleich sind.
def md5_similarity(img1_path, img2_path):
file1 = open(img1_path, "rb")
file2 = open(img2_path, "rb")
md = hashlib.md5()
md.update(file1.read())
res1 = md.hexdigest()
md = hashlib.md5()
md.update(file2.read())
res2 = md.hexdigest()
if __name__ == "__main__":
p1 = "1.jpg"
p2 = "2.jpg"
print('md5_similarity:', md5_similarity(p1, p2))Es gibt auch einige, wie zum Beispiel den auf dem Bloom-Filter basierenden Bildähnlichkeitsalgorithmus, der im Wesentlichen eine modifizierte Version des auf Hash basierenden Algorithmus ist.Es ist immer noch etwas kompliziert zu implementieren, da sein Kern darin besteht, die Datensuche zu filtern. Beschleunigen Sie die Suche.
2. Deep-Learning-Methoden
Idee: tiefe Merkmalsextraktion + Merkmalsvektor-Ähnlichkeitsberechnung
Kurze Einführung von Herrn Lebenslauf: Es soll auf die Feature-Map-Ebene umgeschaltet werden, um Ähnlichkeitsberechnungen und -vergleiche durchzuführen. Nichts Besonderes.
Referenz:
2.1 Papier 1
-
名称: Lernen, Bildpatches über Convolutional Neural Networks zu vergleichen
-
Erläuterung: https://blog.csdn.net/hjimce/article/details/50098483
2.2 Papier 2
-
名称: Die unvernünftige Effektivität von Deep Features als Wahrnehmungsmetrik
-
Erläuterung: https://blog.csdn.net/weixin_41605888/article/details/88887416
Das Papier schlägt ein Verfahren zur Messung der wahrnehmungsbezogenen Ähnlichkeit vor

Es gibt mehr als zehn Arten von Tracking, Prinzipien und Codes, wie wir im nächsten Kapitel sagen werden, es ist wunderbar, sie in Verbindung damit zu verwenden.
Zusammenfassung der Ähnlichkeitsalgorithmen
-
Das Berechnungsergebnis des Einkanal-Histogramms entspricht nicht der intuitiven Vorstellung, aber Genauigkeit und Geschwindigkeit sind sehr gut. empfehlen
-
Kosinusähnlichkeit hat eine hohe Genauigkeit, ist aber zu zeitaufwändig. Nicht empfohlen.
-
Das Verfahren der gegenseitigen Information ist hinsichtlich Zeitaufwand und Genauigkeit zwischen Histogramm und Kosinusähnlichkeit grob einzuhalten und zu empfehlen.
-
Der perzeptive Hash-Algorithmus ist zeitaufwändiger und die Vergleichsergebnisse sind differenzierter und entsprechen dem intuitiven Sehen. empfehlen.
-
Für SSIM und PSNR wird empfohlen, Loss für Deep-Learning-Reparaturaufgaben zu verwenden, die eine Kombination mehrerer Verluste erfordern
-
Das Verfahren der gegenseitigen Information ist hinsichtlich Zeitaufwand und Genauigkeit zwischen Histogramm und Kosinusähnlichkeit grob einzuhalten und zu empfehlen.
Schiene
Tracking-Algorithmen sind in der Regel zeitaufwändig und Jahrzehnte alt. Es gibt 2D- und 3D-Tracking-Algorithmen;
Einführung in die schnelle, genaue und stabile 2D-Tracking-Methode
2D wie Sort, Ungarn, Deepsort, Iou-Tracking, Schätzung des optischen Flusses, STC-Tracker, KF, KCF, CSRT, Mosse, Medianflow, TLD, Mil, Boosting und der diesjährige neue ByteTrack.
Lassen Sie uns nicht über das oben Gesagte sprechen, Sort ist extrem schnell (256 Eingabeschätzungen benötigen nur 3-4 ms), relativ genau (7 Punkte) , aber es wird gesendet, wenn das Objekt das Sichtfeld verlässt oder blockiert ist! Es hat das gleiche Problem wie sort: STC tracker, KF, KCF, CSRT, mosse, medianflow, tld, mil, boosting (und diese sind langsamer (natürlich sind einige schneller, aber die Genauigkeitsrate kann nur 6-7 betragen Punkte)), diese müssen das Modell nicht speichern und lesen und können Plug-and-Play sein. Unterstützt nur Einzelzielverfolgung;
Für traditionelles Tracking können Sie diesen Artikel von mir lesen, mit Code (Tracking für Quellcode): [Die ursprüngliche Version des Projekts mit einer 10-fachen Effizienzsteigerung! 】Deep-Learning-Daten automatischer Tagger Open-Source-Zielerkennung und Bildklassifizierung (hohe Präzision und hohe Effizienz)_cvjuns Blog-CSDN-Blog
Die Deep-Learning-Methode von Deepsort hat die Merkmalsextraktion durchgeführt und dann die verbesserte Sortierung zum Verfolgen verwendet. Die Geschwindigkeit beträgt 10-20 ms und die Genauigkeitsrate beträgt 9 Punkte. Je nach Eingabegröße ist die Verfolgung genauer und Anti-Okklusion Nachteil ist, dass die Geschwindigkeit langsam ist und das Modell gespeichert und gelesen werden muss. ;
Deepsort kann meinen Artikel lesen: [AI Full Stack 2] Videostream Multi-Target Multi-Kategorie Keine Verzögerung Hochpräzise High-Recall Zielverfolgung YOLO+Deepsort full solution_cvjun's blog-CSDN blog
Auf die Verfolgung der optischen Flussschätzungsmethode möchte ich mich konzentrieren. Die Geschwindigkeit ist relativ schnell, 8-13 ms 256 Eingaben, die Genauigkeitsrate ist sehr hoch, 9 Punkte; es unterstützt die Verfolgung mehrerer Ziele
Ursprünglich bei der Schätzung von sich bewegenden Punkten verwendet, können Sie den Code ändern in: jede Objektverfolgung, jede Formverfolgung: Alle oben genannten 2D-Methoden können nur Rechtecke verfolgen und keine geneigten Vierecke akzeptieren (da einige rotierende Zielerkennung sind), tun dies nicht Akzeptieren: Dreiecke, Erkennen und Verfolgen von zufälligen viereckigen, kreisförmigen und punktförmigen Objekten,
Und es kann eine optische Flussverfolgung erreicht werden (kein Modell erforderlich)
Mr. CV hat es auf die Verfolgung der Zielerkennungsversion geändert.Aus Gründen der Vertraulichkeit wird eine Online-Referenzversion für alle zum Lernen bereitgestellt~
Offizielle Idee:
Schritt 1: Erkenne die Schlüsselpunkte des ersten Rahmens basierend auf dem Eckenerkennungsalgorithmus;
Schritt 2: LK spärlicher optischer Fluss verfolgt diese Schlüsselpunkte;
Somit wird die Punktverfolgung realisiert
Rechteckige Zielerkennung + Ideen zur optischen Flussverfolgung:
Da es einige Lücken zwischen dem rechteckigen Begrenzungsrahmen für die Zielerkennung und dem Objekt und der optischen Flusspunktschätzung gibt, müssen wir den Bewegungspunkt erhalten, da die Zielerkennung direkt eine Lücke hat. Wenn der Punkt also in die Lücke fällt, erfolgt die Verfolgung Das Ergebnis wird verzerrt sein: Einige Punkte verfolgen den Hintergrund und einige Punkte verfolgen das Objekt, sodass Ihr Zielframe im nächsten Frame abweichen wird.
Es ist also schwierig, den optischen Fluss zu verwenden, deshalb verwendet ihn niemand in der Branche
Mein Lösungsvorschlag:
Schritt 1: Ersetzen Sie den Mittelpunkt des Rechtecks durch den vorherigen Schritt 1;
Schritt 2: Folgen Sie dem LK-Algorithmus auf die gleiche Weise;
Schritt 3: Berechnen Sie die neue Tracking-Frame-Position anhand des Abstands von den vorherigen Umgebungspunkten zum Mittelpunkt (verändert durch Bewegung);
Ideen für Polygone, geneigte Zielerkennung + optische Flussverfolgung:
Das Erkennungsergebnis dieser Art von Polygon fällt im Wesentlichen auf die Boxgrenze des sich bewegenden Objekts oder einige Pixel außerhalb, wir können:
planen:
Schritt 1, Verwenden der Grenzpunkte als Merkmalspunkte;
Die nächsten Schritte sind die gleichen wie oben
Bildsegmentierung + optische Flussverfolgung:
Das Segmentierungsergebnis ist die Kante des Objekts, sodass die Grenzpunkte direkt als Merkmalspunkte betrachtet werden und die nachfolgenden Schritte die gleichen sind;

# -*- coding:utf-8 -*-
__author__ = 'Microcosm'
import cv2
import numpy as np
cap = cv2.VideoCapture("E:/python/Python Project/opencv_showimage/videos/visionface.avi")
# 设置 ShiTomasi 角点检测的参数
feature_params = dict( maxCorners=100,
qualityLevel=0.3,
minDistance=7,
blockSize=7 )
# 设置 lucas kanade 光流场的参数
# maxLevel 为使用图像金字塔的层数
lk_params = dict( winSize=(15,15),
maxLevel=2,
criteria=(cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 10, 0.03))
# 产生随机的颜色值
color = np.random.randint(0,255,(100,3))
# 获取第一帧,并寻找其中的角点
ret, old_frame = cap.read()
old_gray = cv2.cvtColor(old_frame, cv2.COLOR_BGR2GRAY)
p0 = cv2.goodFeaturesToTrack(old_gray, mask=None, **feature_params)
# 创建一个掩膜为了后面绘制角点的光流轨迹
mask = np.zeros_like(old_frame)
while(1):
ret, frame = cap.read()
if ret:
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 计算能够获取到的角点的新位置
p1, st, err = cv2.calcOpticalFlowPyrLK(old_gray, frame_gray, p0, None, **lk_params)
# 选取好的角点,并筛选出旧的角点对应的新的角点
good_new = p1[st == 1]
good_old = p0[st == 1]
# 绘制角点的轨迹
for i,(new,old) in enumerate(zip(good_new,good_old)):
a,b = new.ravel()
c,d = old.ravel()
cv2.line(mask, (a,b), (c,d), color[i].tolist(), 2)
cv2.circle(frame, (a,b), 5, color[i].tolist(), -1)
img = cv2.add(frame, mask)
cv2.imshow("frame", img)
k = cv2.waitKey(30) & 0xff
if k == 27:
break
# 更新当前帧和当前角点的位置
old_gray = frame_gray.copy()
p0 = good_new.reshape(-1,1,2)
else:
break
cv2.destroyAllWindows()
cap.release()
3D-Tracking-Algorithmus
Für 3D können Sie die Rangliste des KIITI-Datensatzes überprüfen und einige hochrangige finden:

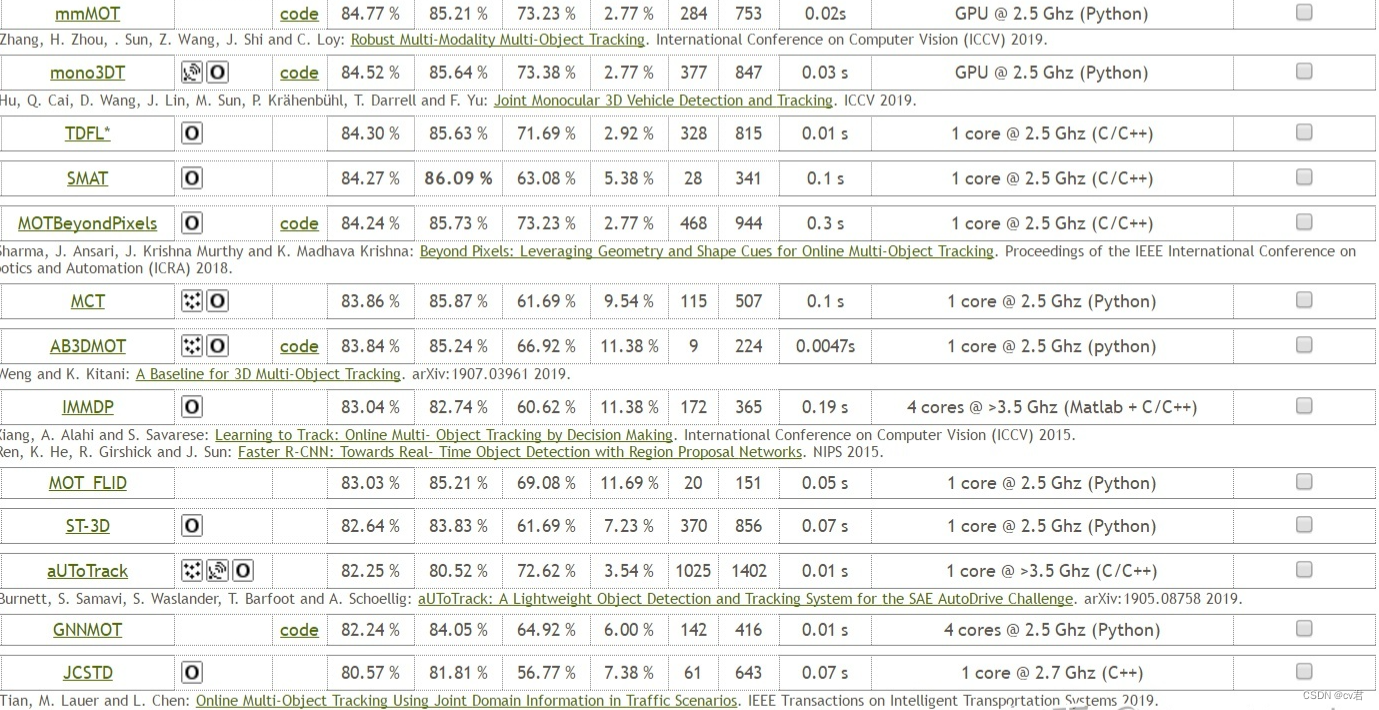
Der schnellere ist der AB3DMOT im zweiten Bild, GPU 5ms, sehr schnell, immerhin ist es Multi-Point-Tracking, und die Dimension ist viel mehr als 2D;
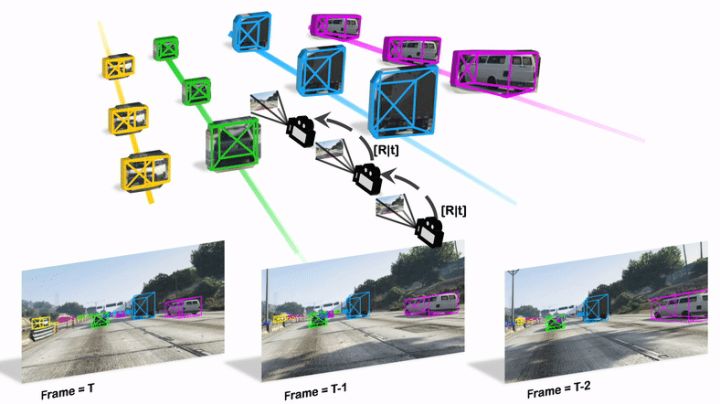
Monocular Quasi-Dense 3D Object Tracking (QD-3DT) ist ein Online-Framework zum Erkennen und Verfolgen von 3D-Objekten mithilfe eines quasi-dichten Objektschemas in 2D-Bildern
Die vollständigen 3D-Bounding-Box-Informationen werden aus einer Folge von 2D-Bildern geschätzt, die auf einer mobilen Plattform aufgenommen wurden. Object Association nutzt quasi-dichtes Ähnlichkeitslernen, um Objekte in verschiedenen Posen und Blickwinkeln nur mit Erscheinungshinweisen zu erkennen. Nach der anfänglichen 2D-Assoziation verwenden wir weiterhin 3D-Bounding-Box-Tiefensortierungsheuristiken für eine robuste Instanzassoziation und bewegungsbasierte 3D-Trajektorienvorhersage für die Reidentifikation von okkludierten Fahrzeugen. Schließlich aggregiert ein LSTM-basiertes Zielgeschwindigkeits-Lernmodul langfristige Trajektorieninformationen für eine präzisere Bewegungsextrapolation. Experimente mit unseren vorgeschlagenen simulierten Daten und realen Benchmarks (einschließlich KITTI-, nuScenes- und Waymo-Datensätzen) zeigen, dass unser Tracking-Framework eine robuste Objektzuordnung und Verfolgung in städtischen Fahrszenarien bietet . Beim Waymo Open Benchmark legen wir die ersten Nur-Kamera-Baselines zu den Herausforderungen von 3D-Tracking und 3D-Erkennung fest. Unsere quasi-dichte 3D-Tracking-Pipeline erzielt beeindruckende Verbesserungen gegenüber dem nuScenes 3D-Tracking-Benchmark und erreicht unter allen veröffentlichten Methoden fast die fünffache Tracking-Genauigkeit der besten Nur-Vision-Übermittlung.
Zusammenfassen
Ähnlichkeitsalgorithmus + Tracking-Algorithmus unterstützt Zielerkennung und Bildsegmentierung. Die Regeln sind gut gestaltet, was nicht nur schmerzlos beschleunigen, sondern auch die Stabilität verbessern kann (Tracking-Stabilität). Warum nicht? Herr Lebenslauf bietet technische Unterstützung, Sie können mich kostenlos konsultieren, meine Kontaktinformationen sind unten ~ willkommen, die Blogger-Kolumne zu abonnieren ~ einfach ohne Geld essen. hahaha