From the perspective of Java compilation principles, this article goes deep into bytecode and class files, and understands the principles and usage of syntactic sugar in Java. It will help you understand the principles behind these syntactic sugars while learning how to use Java syntactic sugar.
1 syntactic sugar
Syntactic Sugar, also known as sugar-coated grammar, is a term invented by British computer scientist Peter.J.Landin. It refers to a certain grammar added to a computer language. This grammar has no effect on the function of the language. But it is more convenient for programmers to use. In short, syntactic sugar makes programs more concise and more readable.
Interestingly, in the field of programming, in addition to grammatical sugar, there are also terms of grammatical salt and grammatical saccharin, and the space is limited so I won’t expand it here.
Almost all programming languages we know have syntactic sugar. The author believes that the amount of grammatical sugar is one of the criteria for judging whether a language is powerful enough.
Many people say that Java is a "low-sugar language". In fact, since Java 7, various sugars have been added to the Java language level, mainly developed under the "Project Coin" project. Although some people in Java still think that the current Java is low-sugar, it will continue to develop in the direction of "high-sugar" in the future.
2 solution to syntactic sugar
As mentioned earlier, the existence of syntactic sugar is mainly for the convenience of developers. But in fact, the Java virtual machine does not support these syntactic sugars. These grammatical sugars will be reduced to simple basic grammatical structures during the compilation phase, and this process is the solution of grammatical sugars.
Speaking of compilation, everyone must know that in the Java language, the javac command can compile a source file with a suffix of .java into a bytecode with a suffix of .class that can run on a Java virtual machine.
If you look at the source code of com.sun.tools.javac.main.JavaCompiler, you will find that one of the steps in compile() is to call desugar(), which is responsible for the realization of syntactic sugar solution.
The most commonly used syntactic sugar in Java mainly includes generics, variable length parameters, conditional compilation, automatic unboxing, inner classes, etc. This article mainly analyzes the principles behind these grammatical sugars. Step by step to peel back the icing and see what it is.
3 Candy Introduction
3.1 switch supports String and enumeration
As mentioned earlier, starting from Java 7, the syntactic sugar in the Java language is gradually enriched. One of the more important ones is that switch in Java 7 starts to support String.
Before starting coding, let’s popularize science. The switch in Java itself supports basic types. Such as int, char, etc.
For the int type, compare the values directly. For the char type, compare its ascii code.
Therefore, for the compiler, only integers can be used in the switch, and any type of comparison must be converted to an integer. For example byte. short, char (ackii code is integer) and int.
Then let's look at the switch's support for String, with the following code:
public class switchDemoString {
public static void main(String[] args) {
String str = "world";
switch (str) {
case "hello":
System.out.println("hello");
break;
case "world":
System.out.println("world");
break;
default:
break;
}
}
}After decompilation, the content is as follows:
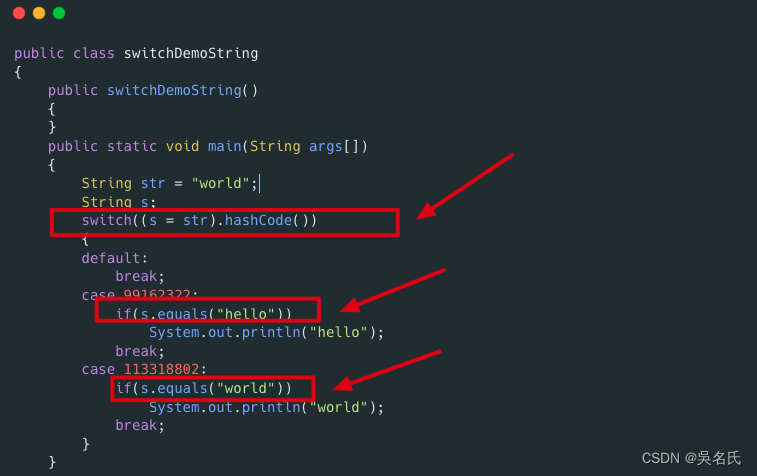
public class switchDemoString
{
public switchDemoString()
{
}
public static void main(String args[])
{
String str = "world";
String s;
switch((s = str).hashCode())
{
default:
break;
case 99162322:
if(s.equals("hello"))
System.out.println("hello");
break;
case 113318802:
if(s.equals("world"))
System.out.println("world");
break;
}
}
}Seeing this code, you know that the switch of the original string is implemented through the equals() and hashCode() methods. Fortunately, the hashCode() method returns an int, not a long.
If you look carefully, you can find that the actual switch is the hash value, and then the security check is performed by using the equals method to compare. This check is necessary because the hash may collide. So it's not as performant as switching with an enum or using a plain integer constant, but it's not bad either.
3.2 Generics
We all know that many languages support generics, but what many people don't know is that different compilers handle generics in different ways.
Typically, a compiler handles generics in two ways: Code specialization and Code sharing.
C++ and C# use the processing mechanism of Code specialization, while Java uses the mechanism of Code sharing.
The code sharing method creates a unique bytecode representation for each generic type, and maps instances of the generic type to this unique bytecode representation. The mapping of multiple generic type instances to unique bytecode representations is accomplished through type erasure.
In other words, for the Java virtual machine, he does not know the syntax of Map<String, String> map at all. It is necessary to desyntactic sugar through type erasure at the compilation stage.
The main process of type erasure is as follows:
1. Replace all generic parameters with their leftmost boundary (topmost parent type) type.
2. Remove all type parameters.
The following code:
Map<String, String> map = new HashMap<String, String>();
map.put("name", "hollis");
map.put("wechat", "Hollis");
map.put("blog", "www.hollischuang.com"); After desugaring the syntactic sugar, it will become:
Map map = new HashMap();
map.put("name", "hollis");
map.put("wechat", "Hollis");
map.put("blog", "www.hollischuang.com"); The following code:
public static <A extends Comparable<A>> A max(Collection<A> xs) {
Iterator<A> xi = xs.iterator();
A w = xi.next();
while (xi.hasNext()) {
A x = xi.next();
if (w.compareTo(x) < 0)
w = x;
}
return w;
}After type erasure it becomes:
public static Comparable max(Collection xs){
Iterator xi = xs.iterator();
Comparable w = (Comparable)xi.next();
while(xi.hasNext())
{
Comparable x = (Comparable)xi.next();
if(w.compareTo(x) < 0)
w = x;
}
return w;
}There are no generics in the virtual machine, only ordinary classes and ordinary methods. The type parameters of all generic classes will be erased at compile time, and generic classes do not have their own unique Class objects. For example, there is no List<String>.class or List<Integer>.class, but only List.class.
3.3 Automatic boxing and unboxing
Autoboxing means that Java automatically converts primitive type values into corresponding objects, such as converting an int variable into an Integer object. This process is called boxing. Conversely, converting an Integer object into an int type value is called unboxing.
Because the boxing and unboxing here is an automatic non-human conversion, it is called automatic boxing and unboxing.
The encapsulation classes corresponding to the primitive types byte, short, char, int, long, float, double and boolean are Byte, Short, Character, Integer, Long, Float, Double, Boolean.
Let's first look at the code for automatic boxing:
public static void main(String[] args) {
int i = 10;
Integer n = i;
}The decompiled code is as follows:
public static void main(String args[])
{
int i = 10;
Integer n = Integer.valueOf(i);
}Let's look at the code for automatic unboxing:
public static void main(String[] args) {
Integer i = 10;
int n = i;
}The decompiled code is as follows:
public static void main(String args[])
{
Integer i = Integer.valueOf(10);
int n = i.intValue();
}It can be seen from the decompiled content that the valueOf(int) method of Integer is automatically called when boxing. The intValue method of Integer is automatically called when unboxing.
Therefore, the boxing process is realized by calling the valueOf method of the wrapper, and the unboxing process is realized by calling the xxxValue method of the wrapper.
3.4 Method variable length parameters
Variable arguments (variable arguments) is a feature introduced in Java 1.5. It allows a method to take any number of values as parameters.
Look at the following variable parameter code, where the print method receives variable parameters:
public static void main(String[] args)
{
print("Holis", "公众号:Hollis", "博客:www.hollischuang.com", "QQ:907607222");
}
public static void print(String... strs)
{
for (int i = 0; i < strs.length; i++)
{
System.out.println(strs[i]);
}
}Decompiled code:
public static void main(String args[])
{
print(new String[] {
"Holis", "\u516C\u4F17\u53F7:Hollis", "\u535A\u5BA2\uFF1Awww.hollischuang.com", "QQ\uFF1A907607222"
});
}
// transient 不能修饰方法,这里应该是反编译错误了?
public static transient void print(String strs[])
{
for(int i = 0; i < strs.length; i++)
System.out.println(strs[i]);
}It can be seen from the decompiled code that when a variable parameter is used, it first creates an array whose length is the number of actual parameters passed by calling the method, and then puts all the parameter values into this Array, and then pass this array as a parameter to the called method.
3.5 Enumeration
Java SE5 provides a new type - Java's enumeration type. The keyword enum can create a limited set of named values as a new type, and these named values can be used as regular program components. This is a very useful feature.
If you want to see the source code, you must first have a class, so what kind of class is the enumeration type? Is it an enum?
The answer is obviously not, enum is just like class, it is just a keyword, it is not a class.
So what class is the enumeration maintained by? We simply write an enumeration:
public enum t {
SPRING,SUMMER;
}Then we use decompilation to see how this code is implemented. After decompilation, the content of the code is as follows:
public final class T extends Enum
{
private T(String s, int i)
{
super(s, i);
}
public static T[] values()
{
T at[];
int i;
T at1[];
System.arraycopy(at = ENUM$VALUES, 0, at1 = new T[i = at.length], 0, i);
return at1;
}
public static T valueOf(String s)
{
return (T)Enum.valueOf(demo/T, s);
}
public static final T SPRING;
public static final T SUMMER;
private static final T ENUM$VALUES[];
static
{
SPRING = new T("SPRING", 0);
SUMMER = new T("SUMMER", 1);
ENUM$VALUES = (new T[] {
SPRING, SUMMER
});
}
}After decompiling the code, we can see that the public final class T extends Enum indicates that this class inherits the Enum class, and the final keyword tells us that this class cannot be inherited.
When we use enmu to define an enumeration type, the compiler will automatically create a final type class for us to inherit the Enum class, so the enumeration type cannot be inherited.
3.6 Inner classes
The inner class is also called the nested class, and the inner class can be understood as an ordinary member of the outer class.
The reason why an inner class is also syntactic sugar is because it is only a compile-time concept.
An inner class inner is defined in outer.java. Once compiled successfully, two completely different .class files will be generated, namely outer.class and outer$inner.class. So the name of the inner class can be the same as its outer class name.
public class OutterClass {
private String userName;
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
public static void main(String[] args) {
}
class InnerClass{
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
}After the above code is compiled, two class files will be generated: OutterClass$InnerClass.class and OutterClass.class.
When we try to use jad to decompile the OutterClass.class file, the command line will print the following:
Parsing OutterClass.class...
Parsing inner class OutterClass$InnerClass.class...
Generating OutterClass.jadHe will decompile all the two files, and then generate an OutterClass.jad file together. The content of the file is as follows:
public class OutterClass
{
class InnerClass
{
public String getName()
{
return name;
}
public void setName(String name)
{
this.name = name;
}
private String name;
final OutterClass this$0;
InnerClass()
{
this.this$0 = OutterClass.this;
super();
}
}
public OutterClass()
{
}
public String getUserName()
{
return userName;
}
public void setUserName(String userName){
this.userName = userName;
}
public static void main(String args1[])
{
}
private String userName;
}3.7 Conditional compilation
—Under normal circumstances, each line of code in the program must participate in compilation. But sometimes, for the sake of program code optimization, you want to compile only part of the content. At this time, you need to add conditions to the program, so that the compiler can only compile the code that meets the conditions, and compile the code that does not meet the conditions. Abandoned, this is conditional compilation.
As in C or CPP, conditional compilation can be achieved through prepared statements. In fact, conditional compilation can also be implemented in Java. Let's look at a piece of code first:
public class ConditionalCompilation {
public static void main(String[] args) {
final boolean DEBUG = true;
if(DEBUG) {
System.out.println("Hello, DEBUG!");
}
final boolean ONLINE = false;
if(ONLINE){
System.out.println("Hello, ONLINE!");
}
}
}The decompiled code is as follows:
public class ConditionalCompilation
{
public ConditionalCompilation()
{
}
public static void main(String args[])
{
boolean DEBUG = true;
System.out.println("Hello, DEBUG!");
boolean ONLINE = false;
}
}First of all, we found that there is no System.out.println("Hello, ONLINE!"); in the decompiled code, which is actually conditional compilation.
When if(ONLINE) is false, the compiler does not compile the code in it.
Therefore, the conditional compilation of Java grammar is realized by the if statement whose judgment condition is constant. According to the true or false of the if condition, the compiler directly eliminates the code block whose branch is false. The conditional compilation realized by this method must be realized in the method body, and the conditional compilation cannot be performed on the structure of the entire Java class or the attributes of the class.
This is indeed more limited than C/C++'s conditional compilation. At the beginning of the Java language design, the function of conditional compilation was not introduced. Although there are limitations, it is better than nothing.
3.8 Affirmations
In Java, the assert keyword was introduced from JAVA SE 1.4. In order to avoid errors caused by using the assert keyword in the old version of Java code, Java does not enable assertion checking by default when executing (at this time, all Assertion statements are ignored!).
If you want to enable assertion checking, you need to use the switch -enableassertions or -ea to enable it.
Consider a piece of code that contains assertions:
public class AssertTest {
public static void main(String args[]) {
int a = 1;
int b = 1;
assert a == b;
System.out.println("公众号:Hollis");
assert a != b : "Hollis";
System.out.println("博客:www.hollischuang.com");
}
}The decompiled code is as follows:
public class AssertTest {
public AssertTest()
{
}
public static void main(String args[])
{
int a = 1;
int b = 1;
if(!$assertionsDisabled && a != b)
throw new AssertionError();
System.out.println("\u516C\u4F17\u53F7\uFF1AHollis");
if(!$assertionsDisabled && a == b)
{
throw new AssertionError("Hollis");
} else
{
System.out.println("\u535A\u5BA2\uFF1Awww.hollischuang.com");
return;
}
}
static final boolean $assertionsDisabled = !com/hollis/suguar/AssertTest.desiredAssertionStatus();
}Obviously, the decompiled code is much more complicated than our own code. Therefore, we save a lot of code by using the syntactic sugar of assert.
In fact, the underlying implementation of the assertion is the if language. If the assertion result is true, nothing will be done, and the program will continue to execute. If the assertion result is false, the program will throw an AssertError to interrupt the execution of the program.
-enableassertions will set the value of the $assertionsDisabled field.
3.9 Numeric literals
In Java 7, numeric literals, whether they are integers or floating-point numbers, allow any number of underscores to be inserted between numbers. These underscores will not affect the literal value, the purpose is to facilitate reading.
for example:
public class Test {
public static void main(String... args) {
int i = 10_000;
System.out.println(i);
}
}After decompilation:
public class Test
{
public static void main(String[] args)
{
int i = 10000;
System.out.println(i);
}
}After decompilation, _ is deleted. That is to say, the compiler does not recognize the _ in the numeric literal, and needs to remove it at the compilation stage.
3.10 for-each
The enhanced for loop (for-each) is believed to be familiar to everyone. It is often used in daily development. It will write a lot less code than the for loop. So how is this syntactic sugar implemented?
public static void main(String... args) {
String[] strs = {"Hollis", "公众号:Hollis", "博客:www.hollischuang.com"};
for (String s : strs) {
System.out.println(s);
}
List<String> strList = ImmutableList.of("Hollis", "公众号:Hollis", "博客:www.hollischuang.com");
for (String s : strList) {
System.out.println(s);
}
}The decompiled code is as follows:
public static transient void main(String args[])
{
String strs[] = {
"Hollis", "\u516C\u4F17\u53F7\uFF1AHollis", "\u535A\u5BA2\uFF1Awww.hollischuang.com"
};
String args1[] = strs;
int i = args1.length;
for(int j = 0; j < i; j++)
{
String s = args1[j];
System.out.println(s);
}
List strList = ImmutableList.of("Hollis", "\u516C\u4F17\u53F7\uFF1AHollis", "\u535A\u5BA2\uFF1Awww.hollischuang.com");
String s;
for(Iterator iterator = strList.iterator(); iterator.hasNext(); System.out.println(s))
s = (String)iterator.next();
}The code is very simple, and the principle of for-each is actually to use ordinary for loops and iterators.
3.11 try-with-resource
In Java, for resources that are very expensive such as file operations, IO streams, and database connections, they must be closed by the close method in time after use, otherwise the resources will always be open, which may cause problems such as memory leaks.
The common way to close a resource is to release it in the finally block, that is, to call the close method. For example, we often write code like this:
public static void main(String[] args) {
BufferedReader br = null;
try {
String line;
br = new BufferedReader(new FileReader("d:\\hollischuang.xml"));
while ((line = br.readLine()) != null) {
System.out.println(line);
}
} catch (IOException e) {
// handle exception
} finally {
try {
if (br != null) {
br.close();
}
} catch (IOException ex) {
// handle exception
}
}
}Starting from Java 7, jdk provides a better way to close resources. Use the try-with-resources statement to rewrite the above code. The effect is as follows:
public static void main(String... args) {
try (BufferedReader br = new BufferedReader(new FileReader("d:\\ hollischuang.xml"))) {
String line;
while ((line = br.readLine()) != null) {
System.out.println(line);
}
} catch (IOException e) {
// handle exception
}
}Look, this is a great boon. Although I usually use IOUtils to close the stream before, I don’t use the method of writing a lot of code in finally, but this new syntactic sugar seems to be much more elegant.
Decompile the above code to see the principle behind it:
public static transient void main(String args[])
{
BufferedReader br;
Throwable throwable;
br = new BufferedReader(new FileReader("d:\\ hollischuang.xml"));
throwable = null;
String line;
try
{
while((line = br.readLine()) != null)
System.out.println(line);
}
catch(Throwable throwable2)
{
throwable = throwable2;
throw throwable2;
}
if(br != null)
if(throwable != null)
try
{
br.close();
}
catch(Throwable throwable1)
{
throwable.addSuppressed(throwable1);
}
else
br.close();
break MISSING_BLOCK_LABEL_113;
Exception exception;
exception;
if(br != null)
if(throwable != null)
try
{
br.close();
}
catch(Throwable throwable3)
{
throwable.addSuppressed(throwable3);
}
else
br.close();
throw exception;
IOException ioexception;
ioexception;
}
}In fact, the principle behind it is also very simple. The compiler has done for us the operations of closing resources that we did not do.
Therefore, it is confirmed again that the function of syntactic sugar is to facilitate the use of programmers, but in the end it must be converted into a language that the compiler understands.
3.12 Lambda expressions
Regarding lambda expressions, some people may have doubts, because some people on the Internet say that it is not syntactic sugar. Actually, I want to correct this statement.
Labmda expressions are not syntactic sugar for anonymous inner classes, but they are syntactic sugar too. The implementation method actually relies on several lambda-related APIs provided by the bottom layer of the JVM.
Let's look at a simple lambda expression first. Iterate over a list:
public static void main(String... args) {
List<String> strList = ImmutableList.of("Hollis", "公众号:Hollis", "博客:www.hollischuang.com");
strList.forEach( s -> { System.out.println(s); } );
}Why do you say that it is not the syntactic sugar of the inner class? We said earlier that the inner class will have two class files after compilation, but the class containing the lambda expression will only have one file after compilation.
The decompiled code is as follows:
public static /* varargs */ void main(String ... args) {
ImmutableList strList = ImmutableList.of((Object)"Hollis", (Object)"\u516c\u4f17\u53f7\uff1aHollis", (Object)"\u535a\u5ba2\uff1awww.hollischuang.com");
strList.forEach((Consumer<String>)LambdaMetafactory.metafactory(null, null, null, (Ljava/lang/Object;)V, lambda$main$0(java.lang.String ), (Ljava/lang/String;)V)());
}
private static /* synthetic */ void lambda$main$0(String s) {
System.out.println(s);
}It can be seen that in the forEach method, the java.lang.invoke.LambdaMetafactory#metafactory method is actually called, and the fourth parameter implMethod of the method specifies the method implementation. It can be seen that a lambda$main$0 method is actually called here for output.
Let's look at a slightly more complicated one, filter the List first, and then output:
public static void main(String... args) {
List<String> strList = ImmutableList.of("Hollis", "公众号:Hollis", "博客:www.hollischuang.com");
List HollisList = strList.stream().filter(string -> string.contains("Hollis")).collect(Collectors.toList());
HollisList.forEach( s -> { System.out.println(s); } );
}The decompiled code is as follows:
public static /* varargs */ void main(String ... args) {
ImmutableList strList = ImmutableList.of((Object)"Hollis", (Object)"\u516c\u4f17\u53f7\uff1aHollis", (Object)"\u535a\u5ba2\uff1awww.hollischuang.com");
List<Object> HollisList = strList.stream().filter((Predicate<String>)LambdaMetafactory.metafactory(null, null, null, (Ljava/lang/Object;)Z, lambda$main$0(java.lang.String ), (Ljava/lang/String;)Z)()).collect(Collectors.toList());
HollisList.forEach((Consumer<Object>)LambdaMetafactory.metafactory(null, null, null, (Ljava/lang/Object;)V, lambda$main$1(java.lang.Object ), (Ljava/lang/Object;)V)());
}
private static /* synthetic */ void lambda$main$1(Object s) {
System.out.println(s);
}
private static /* synthetic */ boolean lambda$main$0(String string) {
return string.contains("Hollis");
}The two lambda expressions call the lambda$main$1 and lambda$main$0 methods respectively.
Therefore, the implementation of lambda expressions actually relies on some underlying APIs. During the compilation phase, the compiler desugars lambda expressions and converts them into ways of calling internal APIs.
4 pits that may be encountered
4.1 Generics - when generics encounter overloading
public class GenericTypes {
public static void method(List<String> list) {
System.out.println("invoke method(List<String> list)");
}
public static void method(List<Integer> list) {
System.out.println("invoke method(List<Integer> list)");
}
} The above code has two overloaded functions because their parameter types are different, one is List and the other is List. However, this code cannot be compiled. As we said earlier, the parameters List and List are erased after compilation and become the same native type List. The erase action causes the feature signatures of these two methods to become exactly the same.
4.2 Generics - when generics encounter catch
Generic type parameters cannot be used in catch statements for Java exception handling. Because exception handling is performed by the JVM at runtime. Since the type information is erased, the JVM cannot distinguish between the two exception types MyException<String> and MyException<Integer>
4.3 Generics - when static variables are included in generics
public class StaticTest{
public static void main(String[] args){
GT<Integer> gti = new GT<Integer>();
gti.var=1;
GT<String> gts = new GT<String>();
gts.var=2;
System.out.println(gti.var);
}
}
class GT<T>{
public static int var=0;
public void nothing(T x){}
}The output of the above code is: 2! Due to type erasure, all generic class instances are associated with the same bytecode, and all static variables of the generic class are shared.
4.4 Autoboxing and unboxing - object equality comparison
public static void main(String[] args) {
Integer a = 1000;
Integer b = 1000;
Integer c = 100;
Integer d = 100;
System.out.println("a == b is " + (a == b));
System.out.println(("c == d is " + (c == d)));
}Output result:
a == b is false
c == d is trueIn Java 5, a new feature was introduced on operations on Integer to save memory and improve performance. Integer objects enable caching and reuse by using the same object reference.
Works with integer values in the range -128 to +127.
Applies only to autoboxing. Creating an object using a constructor does not apply.
4.5 Enhanced for loop
for (Student stu : students) {
if (stu.getId() == 2)
students.remove(stu);
}A ConcurrentModificationException will be thrown.
Iterator works in an independent thread and owns a mutex lock. After the Iterator is created, it will create a single-link index table pointing to the original object. When the number of original objects changes, the content of the index table will not change synchronously, so when the index pointer moves backwards, it will not be found to iterate. object, so according to the fail-fast principle, Iterator will throw java.util.ConcurrentModificationException immediately.
So the Iterator does not allow the iterated object to be changed while it is working. But you can use the method remove() of Iterator itself to delete the object, and the Iterator.remove() method will maintain the consistency of the index while deleting the current iteration object.
5 summary
The previous section introduced 12 commonly used syntactic sugars in Java. Due to space issues, there are other common syntactic sugars such as string concatenation based on StringBuilder. The var keyword in Java 10 declares local variables using intelligent type inference and will not be mentioned here.
The so-called syntactic sugar is just a kind of syntax provided to developers for easy development. But this syntax is known only to developers. To be executed, it needs to be desugared, that is, converted into a syntax recognized by the JVM.
When we desugar the grammar, you will find that the convenient grammars we use every day are actually composed of other simpler grammars.
With these grammatical sugars, we can greatly improve efficiency in daily development, but at the same time avoid excessive use. It is best to understand the principle before using it to avoid falling into the pit.