
Author|Liang Depeng
The tools in the field of AI mapping have been unsatisfactory until last August when Stable Diffusion was open sourced and became an indisputable epoch-making model in the field of AI image generation.
In order to improve its reasoning efficiency, OneFlow accelerated the Stable Diffusion model to the era of "one-second map generation" for the first time , which greatly improved the speed of Vincent graphs, which aroused great repercussions in the AIGC field and received official support from Stability.ai. So far, OneFlow is still refreshing the SOTA record.
However, since most teams currently develop based on the translation API + English Stable Diffusion model, it is difficult for the English version model to give the correct matching picture content when using the unique Chinese narrative and expression, which is a problem for some domestic users. It's not very convenient.
In order to solve this problem, the domestic IDEA Institute Cognitive Computing and Natural Language Research Center (IDEA CCNL) also open sourced the first Chinese version of "Taiyi Stable Diffusion", based on 20 million screened Chinese image-text pairs for training . Last month, Taiyi Stable Diffusion had nearly 150,000 downloads on HuggingFace, making it the most downloaded Chinese Stable Diffusion.
Recently, the OneFlow team has adapted the OneFlow backend for Taiyi Stable Diffusion, which has greatly improved the inference performance and can also produce maps in one second. Many developers are curious about what optimization "secrets" OneFlow uses, which will be briefly explained later.
Welcome Star, run the OneFlow version of Taiyi Stable Diffusion:
https://github.com/Oneflow-Inc/diffusers/wiki/How-to-Run-OneFlow-Stable-Diffusion#without-docker
1Compared with PyTorch
, OneFlow more than doubles the reasoning speed of "Taiyi Stable Diffusion"
The following charts show the use of PyTorch and OneFlow on Taiyi Stable on different types of GPU hardware of A100 (PCIe 40GB / SXM 80GB), V100 (SXM2 32GB), RTX 2080, RTX 3080 Ti, RTX 3090, and T4 respectively The performance of Diffusion inference.


It can be seen that for the A100 graphics card, whether it is a PCIe 40GB configuration or an SXM 80GB configuration, the performance of OneFlow can be more than doubled compared with PyTorch, and the inference speed has reached more than 50it/s. The time required to generate a picture is in within 1 second.
Other hardware data:
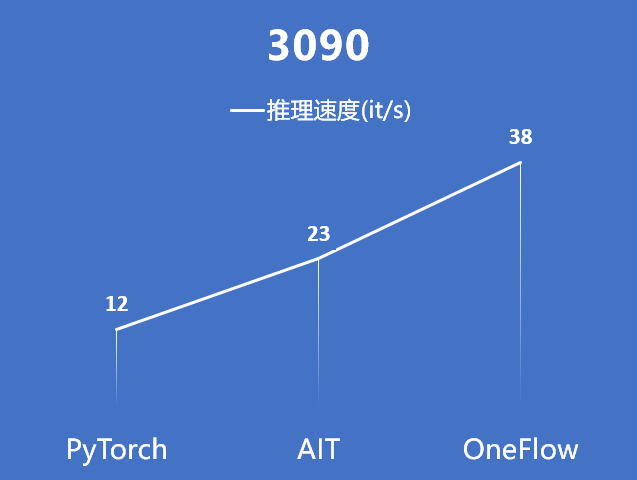
Note: AIT data on 3090 is provided by IDEA Research Institute




In summary, in the comparison of various hardware, compared with PyTorch, OneFlow can more than double the reasoning performance of Taiyi Stable Diffusion.
2
Generate image display
surging river, continuous, beautiful, illustration

Great Wall, morning, hazy, beautiful, illustration

Dreaming back to Jiangnan, an ancient Chinese town, beautiful, illustration

Future city in China, sci-fi illustration

ancient buildings, snowy

Snail noodles

Note: The above pictures are all generated based on the OneFlow version of Taiyi Stable Diffusion
3
Seamlessly compatible with PyTorch ecosystem
Want to experience the OneFlow version of Taiyi Stable Diffusion? Only two lines of code need to be modified:

The reason why models can be migrated so easily is because OneFlow Stable Diffusion has two outstanding features:
-
OneFlowStableDiffusionPipeline.from_pretrained can directly use PyTorch weights.
-
The API of OneFlow itself is aligned with PyTorch, so after importing oneflow as torch, expressions such as torch.autocast and torch.float16 do not need to be modified at all.
The above features make OneFlow compatible with the PyTorch ecosystem, which not only played a role in the migration of OneFlow to Taiyi Stable Diffusion, but also greatly accelerated the migration of many other models by OneFlow users. For example, in flowvision, which is benchmarked against torchvision, many models only need It can be obtained by adding import oneflow as torch to the torchvision model file.
In addition, OneFlow also provides a global "mock torch" function. Running eval $(oneflow-mock-torch) on the command line can make the import torch in all Python scripts run next automatically point to oneflow.
4
Dynamic and static integrated programming experience
The prototype development stage of deep learning algorithms requires rapid modification and debugging, and dynamic graph execution (Eager mode, define by run) is optimal. But in the deployment phase, the model has been fixed, and computational efficiency becomes more important. Static graph execution (lazy mode, define and run) can be statically optimized by the compiler to achieve better performance. Therefore, the inference phase mainly uses the static graph mode.
Recently, PyTorch was upgraded to 2.0 and introduced the compile() API, which can change a model or a module from dynamic graph execution to static graph execution. There is a similar mechanism in OneFlow, but the interface name is nn.Graph(), which can convert the incoming Module into a static graph execution mode.
Not only that, OneFlow's nn.Graph mode implements layer optimization of a series of calculation graphs based on MLIR , such as memory layout and operator fusion.
This not only enables the deep learning model represented by the calculation graph to achieve the highest performance on various hardware, but more importantly, makes the calculation graph imported by the deep learning framework more convenient to migrate between different hardware, which helps to overcome domestic hardware. The problem of weak software ecology. In the future, we will publish more content to reveal the design and implementation of the OneFlow deep learning compiler.
Welcome Star, run the OneFlow version of Taiyi Stable Diffusion:
https://github.com/Oneflow-Inc/diffusers/wiki/How-to-Run-OneFlow-Stable-Diffusion#without-docker
OneFlow Address: https://github.com/Oneflow-Inc/oneflow/
everyone else is watching
-
One small step for ChatGPT, one giant step for NLP paradigm shift
-
Ten Prospects for AI in 2023: GPT-4 leads the transformation of large models
-
Li Bai: Your model weight is very good, but unfortunately I confiscated it
-
Sam Altman, head of OpenAI: the next stage of AI development
-
Faster than fast, open source Stable Diffusion refreshes the drawing speed
-
OneEmbedding: Training a TB-level recommendation model with a single card is not a dream