The detailed data generated by the business system is usually processed and calculated according to a certain logic into the required results to support the business activities of the enterprise. There are generally many such data processing tasks, which need to be calculated in batches. In the banking and insurance industries, it is often called batch processing. Other industries such as petroleum and electric power often have batch processing requirements.
Most business statistics require a certain day as the cut-off point, and in order not to affect the operation of the production system, the batch running task is generally carried out at night. Only at this time can the new detailed data generated by the production system that day be exported and sent to a special The database or data warehouse completes the running batch calculation. The next morning, the batch run results can be provided to business personnel.
Different from online query, running batch calculation is an offline task that is automatically executed at regular intervals, and there is no situation where multiple people access a task at the same time, so there is no concurrency problem, and there is no need to return results in real time. However, the run batch must be completed within the specified window time. For example, the batch running window of a bank is from 8:00 pm to 7:00 am the next day. If the batch running task has not been completed by 7:00 am, it will cause serious consequences that the business personnel cannot work normally.
The amount of data involved in batch running tasks is very large, and all historical data is likely to be used. Moreover, the calculation logic is complex and there are many steps. Therefore, the batch running time is often measured in hours. It is common for a task to run for two or three hours. Hours are not surprising. With the development of business, the amount of data is still increasing. The burden of running the batch database grows rapidly, and it will not be able to run all night, which will seriously affect the user's business, which is unacceptable.
problem analysis
To solve the problem of running batches for too long, the problems in the existing system architecture must be carefully analyzed.
The typical architecture of the batch running system is roughly as follows:
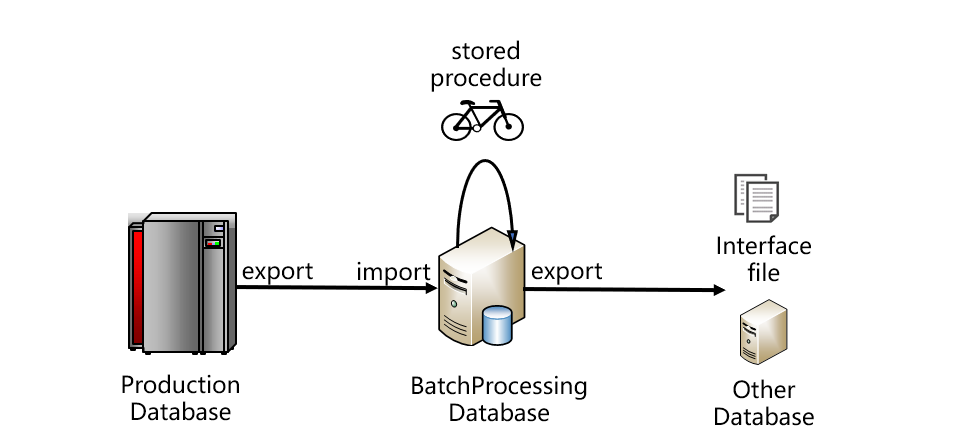
From the figure, the data should be taken out from the production database and stored in the running batch database. The running batch database is usually relational, and the stored procedure code is written to complete the running batch calculation. The results of running batches are generally not used directly, but are exported from the batch running database, provided to other systems in the form of interface files, or imported into other system databases. This is a typical architecture. The production database in the figure may also be a central data warehouse or Hadoop. Under normal circumstances, the production library and the batch running library will not be the same database, and they often transfer data through files, which is also conducive to reducing coupling. After the batch calculation is completed, the results are used by multiple application systems, and are generally transmitted in the form of files.
The first reason for the slow batch running is that the relational database used to complete the batch running task is too slow to enter and exit the warehouse. Due to the closed storage and computing capabilities of relational databases, excessive constraint checking and security processing are required for data entry and exit. When the amount of data is large, the efficiency of writing and reading is very low, and the time-consuming is very long. Therefore, the process of importing file data into the batch database, and the process of running batch calculation results and then exporting files will be very slow.
The second reason for running batches is slow is the poor performance of stored procedures. Because the syntax system of SQL is too old, there are many restrictions, and many efficient algorithms cannot be implemented, so the calculation performance of SQL statements in stored procedures is not ideal. Moreover, when the business logic is relatively complex, it is difficult to implement it with one SQL, and it is often divided into multiple steps, which can only be completed with a dozen or even dozens of SQL statements. The intermediate result of each SQL must be stored in a temporary table for use by the SQL in the subsequent steps. When the amount of data in the temporary table is large, it must be landed, which will cause a large amount of data to be written out. The performance of writing out of the database is much worse than that of reading in, which will seriously slow down the entire stored procedure.
For more complex calculations, it is even difficult to implement directly with SQL statements. It is necessary to traverse the data with a database cursor and perform loop calculations. However, the computing performance of database cursor traversal is much worse than that of SQL statements, and generally does not directly support multi-threaded parallel computing. It is difficult to utilize the computing power of multiple CPU cores, which will make computing performance even worse.
So, can we consider using a distributed database to replace the traditional relational database, and increase the number of nodes to improve the speed of running batch tasks?
The answer is still not feasible. The main reason is that the logic of running batch calculations is quite complicated. Even if the stored procedures of traditional databases are used, it is often necessary to write thousands or even tens of thousands of lines of code. The storage procedures of distributed databases have relatively weak computing power, so it is difficult to achieve such complexity. run batch calculation.
Moreover, when complex computing tasks have to be divided into multiple steps, distributed databases also face the problem of intermediate results. Since the data may be on different nodes, the intermediate results are implemented in the previous steps, and when the subsequent steps are read, it will cause a large number of read and write operations across the network, and the performance is very uncontrollable.
At this time, the distributed database cannot rely on data redundancy to improve the query speed. This is because multiple copies of redundant data can be prepared in advance before querying. However, the intermediate results of running batches are temporarily generated. If redundant, multiple copies will be generated temporarily, and the overall performance will only become slower.
Therefore, the actual batch running business is usually still carried out by using a large single database. When the calculation intensity is too high, an all-in-one machine like ExaData will be used (ExaData is a multi-database, but it has been specially optimized by Oracle, which can be regarded as a super-large single database. body database). Although it is very slow, I can't find a better choice for the time being. Only such large databases have enough computing power, so I can only use it to complete batch running tasks.
SPL is used to run batches
The open source professional computing engine SPL provides computing power that does not depend on the database, and directly uses the file system for computing, which can solve the problem that the relational database is too slow to store and store. Moreover, SPL implements a better algorithm, and its performance is much higher than that of stored procedures, which can significantly improve the computing efficiency of a single computer, and is very suitable for running batch computing.
The new architecture of the batch running system implemented by SPL is as follows:

In the new architecture, SPL solves two major bottlenecks that cause slow batch runs.
First of all, let's look at the inbound and outbound issues of data. SPL can be calculated directly based on the files exported from the production library, without having to import the data into the relational database. After the batch-running calculation is completed, SPL can directly store the final result in a general format such as a text file, and transmit it to other application systems, avoiding the out-of-warehouse operation of the original batch-running database. In this way, SPL saves the slow in-warehousing and out-warehousing process of relational databases.
Let's look at the calculation process again. SPL provides better algorithms (many are the industry's first), and the computing performance far exceeds that of stored procedures and SQL statements. These high-performance algorithms include:

These high-performance algorithms can be applied to common JOIN calculations, traversal, grouping and summarization in batch running tasks, which can effectively improve the calculation speed. For example, running a batch task often traverses the entire history table. In some cases, a history table needs to be traversed many times to complete the calculation of various business logics. The amount of data in the history table is generally large, and each traversal consumes a lot of time. At this time, we can apply the traversal multiplexing mechanism of SPL , and only traverse the large table once, and can complete various calculations at the same time, which can save a lot of time.
SPL's multi-way cursor can read and calculate data in parallel, even if it is a very complex batch-running logic, it can also use multiple CPU cores to realize multi-threaded parallel operations. The database cursor is difficult to parallelize, so that the calculation speed of SPL can often reach several times of the stored procedure.
The delayed cursor mechanism of SPL can define multiple calculation steps on a cursor, and then let the data flow complete these steps in sequence to realize chain calculation , which can effectively reduce the number of intermediate results landing. In cases where data must be landed, SPL can also store intermediate results in a built-in high-performance data format for use in the next step. SPL high-performance storage is based on files. It adopts technologies such as ordered compression storage, free columnar storage, multiplication segmentation, and its own compression encoding , which reduces the hard disk occupation, and the read and write speed is much better than that of the database.
Apply effects
SPL breaks the two bottlenecks existing in relational batch database in terms of technical architecture, and has achieved very good results in practical applications.
The batch running task of L bank adopts the traditional architecture, uses the relational database as the batch running database, and uses the stored procedure programming to realize the batch running logic. Among them, the loan agreement storage process needs to be executed for 2 hours, and it is the pre-sequence task of many other batch running tasks. It takes so long to have a serious impact on the entire batch running task.
After using SPL, high-performance algorithms and storage mechanisms such as high -performance column storage, file cursors, multi-thread parallelism, small result memory grouping, and cursor multiplexing are used to shorten the original 2-hour calculation time to 10 minutes, and the performance is improved by 12 times. .
Also, the SPL code is more concise. The original stored procedure has more than 3,300 lines. After it is changed to SPL, there are only 500 lattice statements, and the amount of code is reduced by more than 6 times , which greatly improves the development efficiency.
In the auto insurance business of P Insurance Company, it is necessary to use the historical policies of previous years to associate new policies, which is called the historical policy association task in the running batch. Originally, the relational database was also used to complete the batch running. The stored procedure calculates the 10-day new policy associated with the historical policy, and the running time is 47 minutes; 30 days, it takes 112 minutes, which is close to 2 hours; if the date span is larger, the running time will be longer. Unbearable, basically becomes an impossible task.
After using SPL, high-performance file storage, file cursors, orderly merge and segment retrieval, memory association , and traversal multiplexing technologies are applied, and it takes only 13 minutes to calculate a 10-day new policy; 30-day new policy only takes 17 minutes , the speed increased by nearly 7 times . Also, the execution time of the new algorithm is not very large with the number of policy days, and does not increase proportionally like the stored procedure.
Judging from the total amount of code, the original stored procedure has 2000 lines of code, and there are more than 1800 lines after removing the comments, while the total code of SPL is less than 500, less than 1/3 of the original .
The detailed data of the loans issued by Bank T through the Internet channel needs to be executed every day, and all historical data before the specified date needs to be collected and summarized. The batch running task is implemented using the SQL statement of the relational database. The total running time is 7.8 hours, which takes up too much batch running time and even affects other batch running tasks, so it must be optimized.
After using SPL, high-performance file, file cursor, ordered grouping, ordered association, delayed cursor, dichotomy and other technologies have been applied. It took 7.8 hours to run batch tasks, but only 180 seconds for a single thread and 137 for two threads. seconds, the speed increased by 204 times .