I am often asked
There is a xx requirement, should I use Kafka or RabbitMQ?
This problem is very common, and many people do not have a good grasp of the choice between the two.
So I decided to write an article to talk about it in detail: What is the difference between Kafka and RabbitMQ?
At the same time, this question is often asked in interviews.
Below I will compare and analyze the advantages and disadvantages of Kafka and RabbitMQ through 6 scenarios.
The sequence of messages
There is such a requirement: when the order status changes, the message of the order status change is sent to all systems that care about the order change.
The order will have the status of successfully created, pending payment, paid, and shipped, and the status is one-way flow.
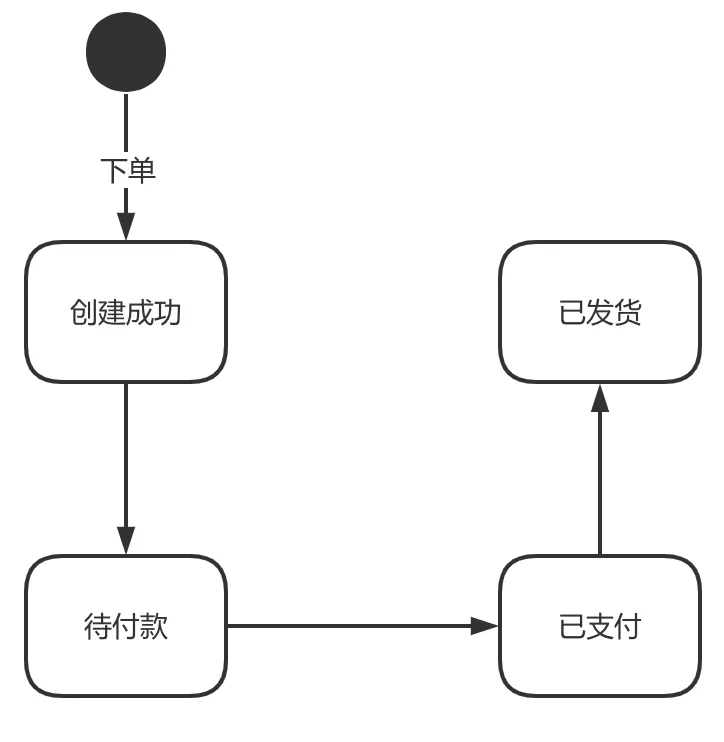
Well, now we send the order status change message to all systems that care about the order status. The way to achieve this is to use a message queue.
In this business, what do we want most?
-
Sequence of messages: For the same order, the changes of status are strictly sequenced.
-
Throughput: For a business like an order, we naturally want the more orders the better. The more orders, the greater the throughput.
In this case, let's first see how RabbitMQ does it.
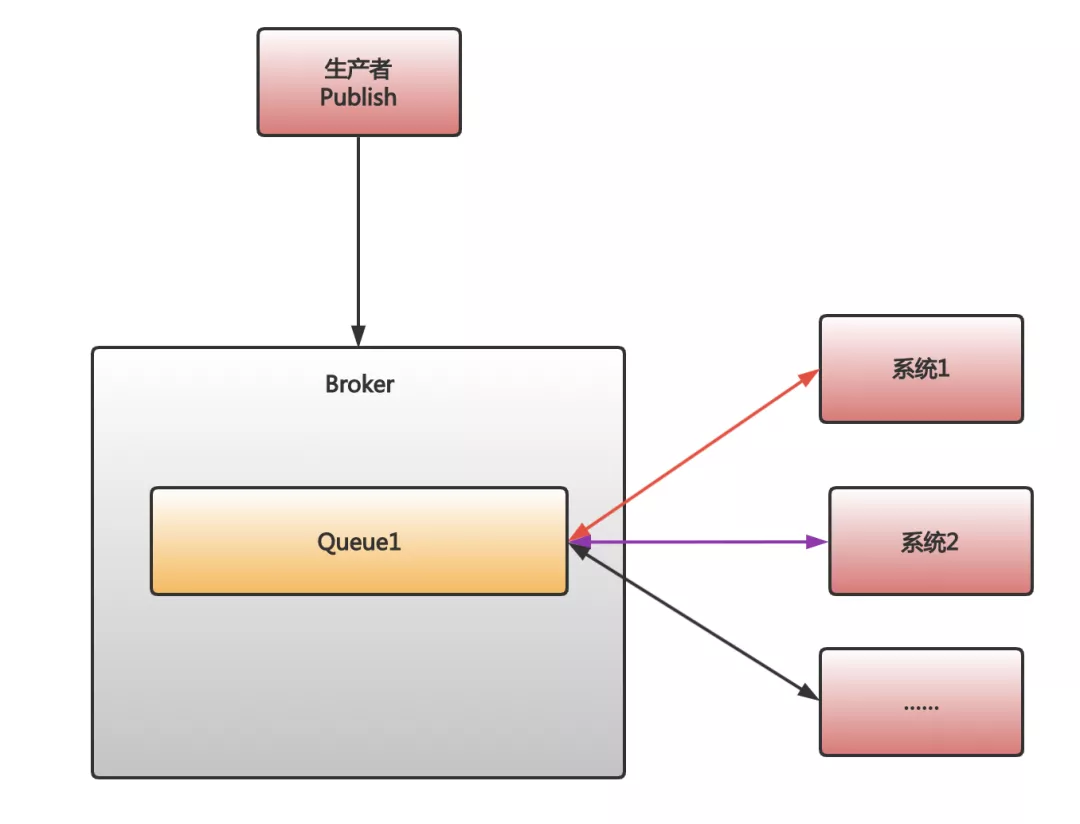
First of all, for the case of sending messages and broadcasting to multiple consumers, RabbitMQ will establish a corresponding queue for each consumer. That is, if there are 10 consumers, RabbitMQ will create 10 corresponding queues. Then, when a message is sent, RabbitMQ will copy 10 copies of the message into the 10 queues.
When RabbitMQ puts the message into the corresponding queue, the next question we face is how many threads should we start inside the system to get the message from the message queue.
If it is only a single thread to get the message, then there is nothing to say. But in the case of multi-threading, there may be problems...
RabbitMQ has such a feature. It declares in the official document that it does not guarantee that multiple threads consume messages from the same queue, and the order must be guaranteed. The reason for the lack of guarantee is that when a thread consumes a message and reports an error, RabbitMQ will re-queue the message that failed to consume, and out-of-order conditions may occur at this time.
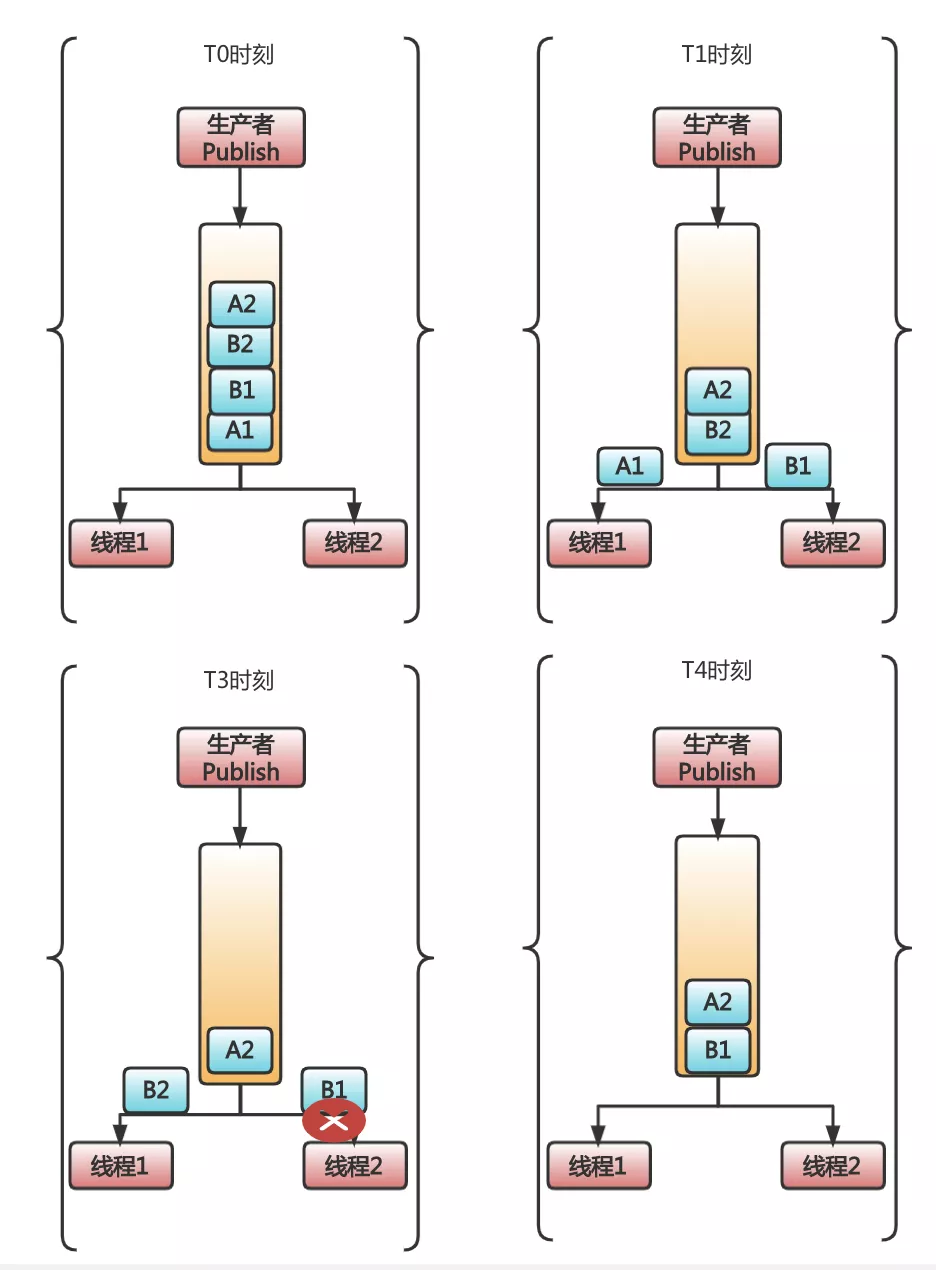
At time T0, there are four messages A1, B1, B2, and A2 in the queue. Among them, A1 and A2 represent the two states of order A: pending payment and paid. The same is true for B1 and B2, which are pending and paid for order B.
At time T1, message A1 is received by thread 1, and message B1 is received by thread 2. At this point, everything was normal.
At the time of T3, B1 consumes an error, and at the same time, due to the fast processing speed of thread 1, B2 is obtained from the message queue. At this point, problems started to appear.
At time T4, due to the RabbitMQ thread consumption error, the message can be re-queued, and B1 will be re-queued to the head of the queue. Therefore, if it is unfortunate that thread 1 obtains B1, there will be an out-of-order situation. The state of B2 is obviously the subsequent state of B1, but it is processed in advance.
So, you can see that there are three problems with RabbitMQ in this scenario:
- In order to implement the publish-subscribe function, the message replication used will reduce performance and consume more resources
- Multiple consumers cannot strictly guarantee message order
- A large number of orders are concentrated in one queue and throughput is limited
So what about Kafka? Kafka is much better than RabbitMQ on these three issues.
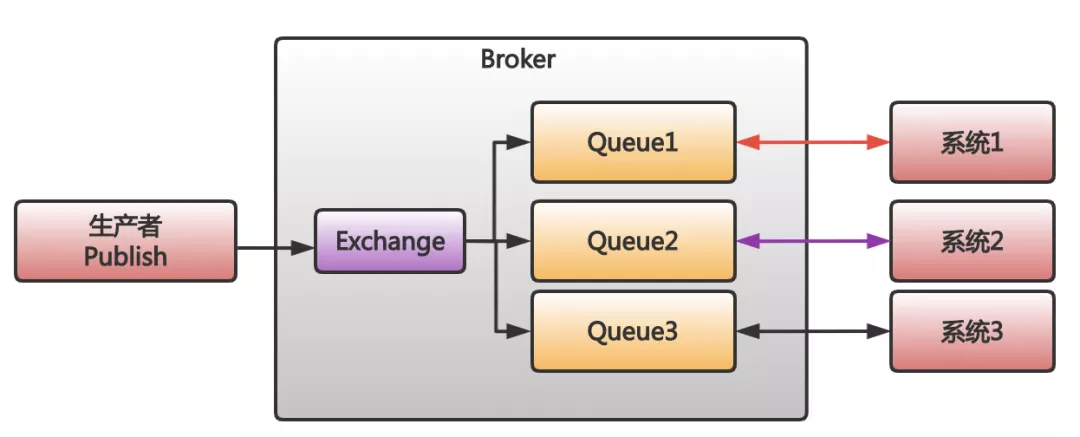
First of all, Kafka's publish and subscribe does not copy messages, because Kafka's publish and subscribe means that consumers can directly obtain the messages saved in the log file by Kafka. No matter how many consumers, they just need to actively find the location of the message in the file.
Secondly, Kafka will not re-queue the message after the consumer makes an error.
Finally, Kafka can partition orders and store different orders in multiple partitions, so that the throughput can be better.
Therefore, Kafka is more suitable for this requirement.
Second, the matching of the message
I once worked on a marketing system. A very significant feature of this system is that it is very complex and flexible to match rules.
For example, it is necessary to match different methods of promotion according to the promotion content. For another example, it is necessary to match different channels for distribution according to different activities.
In short, countless matching rules are a very important feature of this system.
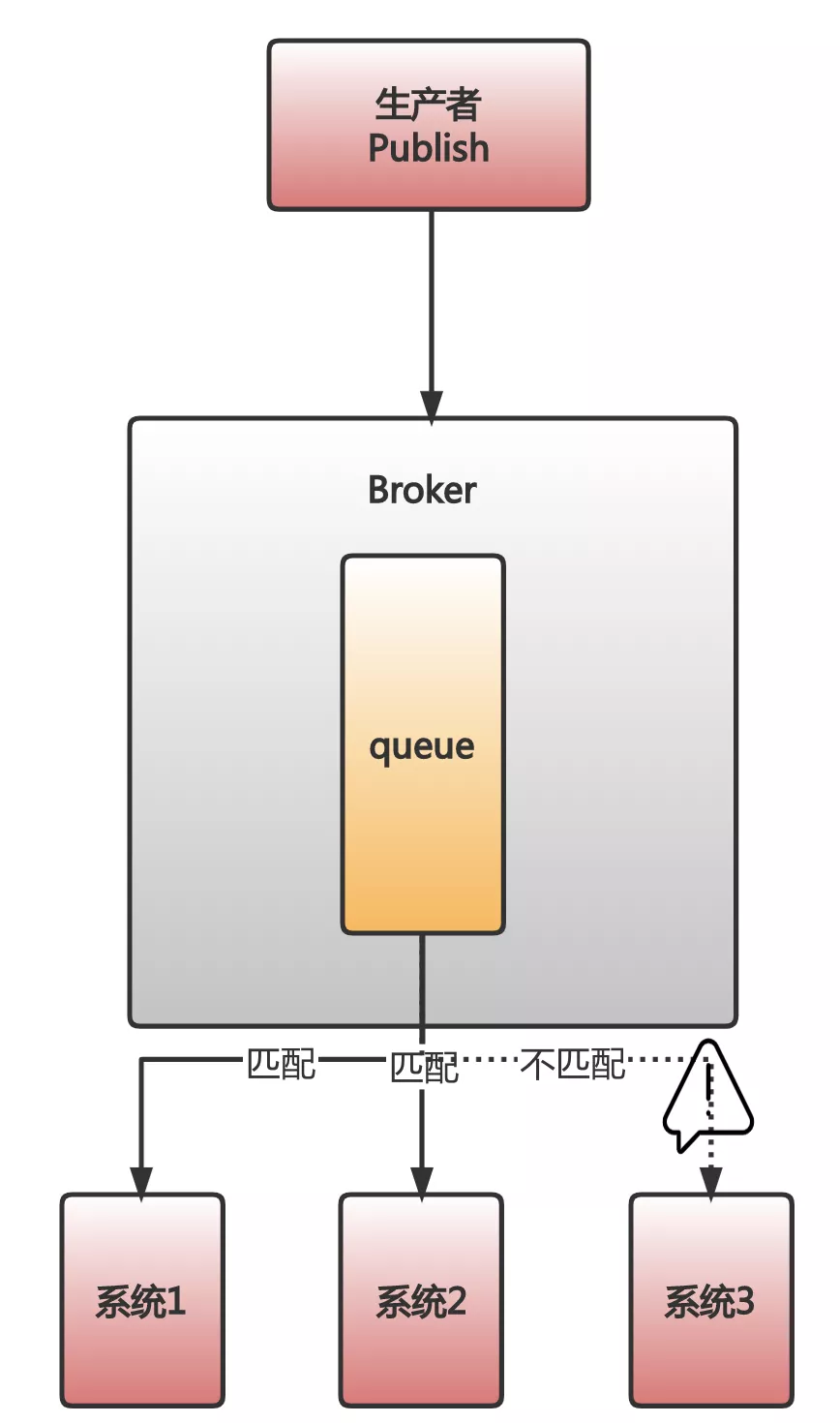
First of all, look at RabbitMQ, you will find that RabbitMQ allows adding routing_key or custom message headers to messages, and then through some special Exchange, it is very simple to achieve message matching and distribution. Development costs almost nothing.
And what about Kafka? If you want to implement message matching, the development cost is much higher.
First of all, it is impossible to automatically match and distribute to the appropriate consumers through simple configuration.
Second, the consumer must first fetch all messages whether they are needed or not. Then, according to business needs, you can achieve various precise and fuzzy matching by yourself. Maybe because of excessive complexity, a rule engine is also introduced.
RabbitMQ regained one point in this scenario.
3. Timeout of the message
In the e-commerce business, there is a requirement: after placing an order, if the user does not pay within 15 minutes, the order will be automatically cancelled.
You may be wondering, how can this kind of message queue be used?
Let me briefly explain that in a single-service system, it can be done by starting a scheduled task.
However, in SOA or microservice architecture, this is not enough. Because many services are concerned about whether to pay or not, if each service implements a set of logic for scheduled tasks by itself, it is repetitive and difficult to maintain.
In this case, we tend to do a layer of abstraction: encapsulate the task to be performed into a message. When the time is up, it is directly thrown into the message queue. After the subscribers of the message get the message, they can execute it directly.
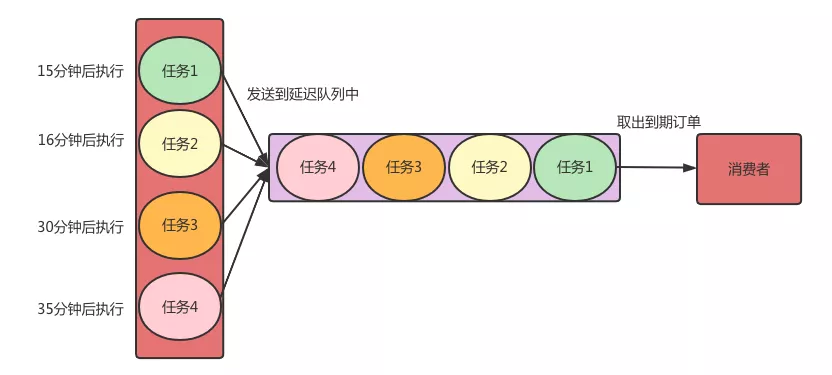
Those who want to delay the processing of messages for a certain period of time are called delay queues.
For the business of order cancellation, when creating an order, we will throw a message containing the execution task information to the delay queue at the same time. After specifying 15 minutes, each consumer who subscribes to this queue can receive this message. . Then, the system where each consumer is located can perform the related task of scanning the order.
How to choose RabbitMQ and Kafka message queue?
Let's take a look at RabbitMQ first.
The message of RabbitMQ comes with a watch, and there is a TTL field in the message, which can set the storage time of the message in RabbitMQ. If it times out, it will be moved to a place called a dead letter queue.
Therefore, the easiest way to implement a delay queue RabbitMQ is to set the TTL, and then a consumer listens to the dead letter queue. When the message times out, the consumer listening to the dead letter queue receives the message.
However, there is a big problem with this: Suppose we put an A message with an expiration time of 10 seconds into the queue, and then put a B message with an expiration time of 5 seconds. So the question is, will the B message enter the dead letter queue before the A message?
the answer is negative. The B message will preferentially obey the first-in, first-out rule of the queue. After the A message expires, it will enter the dead letter queue with it and be consumed by the consumer.
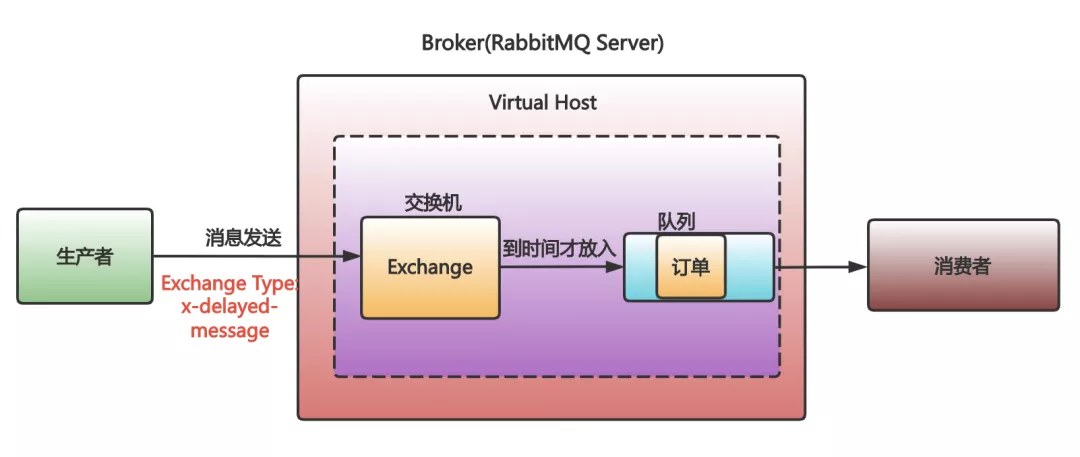
After version 3.5.8 of RabbitMQ, the officially recommended rabbitmq delayed message exchange plugin can solve this problem.
- With this plugin, when we send a message, we send the message to a special Exchange.
- At the same time, specify the time to delay in the message header.
- Exchange that receives the message does not put the message in the queue immediately, but only after the message delay time has elapsed.
Take a look at Kafka's:
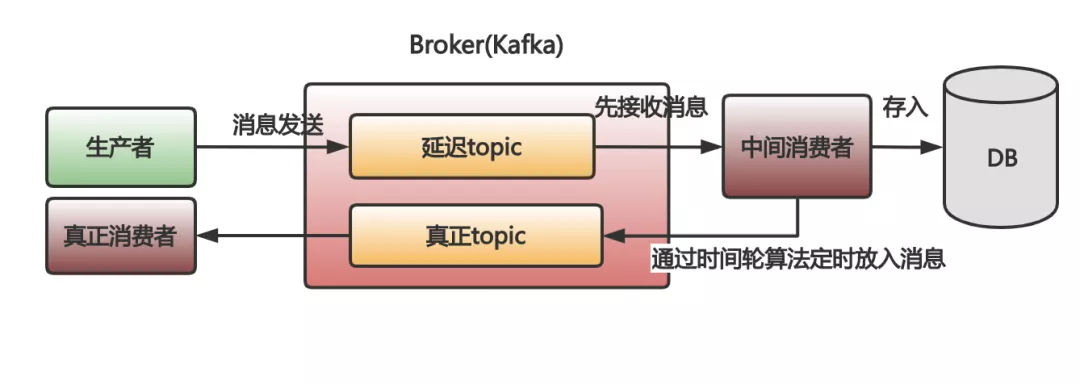
Kafka is very troublesome to implement delayed queues.
- You first need to put the message into a temporary topic first.
- Then you have to develop a transit consumer yourself. Let the intermediate consumer first fetch the message from this temporary topic.
- Take it out, this news can't be processed immediately, because there is no time. I can't save it in my own memory, I'm afraid it will crash and the message will be gone. Therefore, it is necessary to store the messages that have not reached the time in the database.
- The messages stored in the database need to be put into Kafka after the time is up, so that the real consumers can execute the real business logic.
- ……
Thinking about it is already a big head, and this is about to become a scheduling platform. To be more advanced, you need to use the time wheel algorithm to be better and more accurate.
This time, the news about wearing a watch on RabbitMQ is the best choice.
Fourth, the maintenance of news
In microservices, the event sourcing pattern is often used. If you want to use a message queue to implement, generally, events are treated as messages and sent to the message queue in turn.
One of the most classic scenarios of event sourcing is event replay. Simply put, it is to take out the events that occurred in the system for a certain period of time and then process them in turn. Moreover, according to different business scenarios, these events may not be replayed once, but more likely to be repeated N times.
Suppose, we now need a batch of online event replays to troubleshoot some problems.
RabbitMQ really doesn't work at this time, because the message is deleted after being taken out. Want to be re-consumed again? I am sorry.
As for Kafka, messages are persisted in a dedicated log file. It will not be deleted just because it is consumed.
Therefore, please choose Kafka for Kafka, which never leaves the message, as opposed to RabbitMQ, which is used and thrown away.
5. Error handling of messages
In many cases, Kafka is generally the best choice when doing business related to recording data. However, sometimes I prefer to use RabbitMQ when the recording data throughput is not large.
The reason is that Kafka has a design principle that I really dislike:
When a message in a single partition fails to consume, it can only stop instead of skipping the failed message and continue consuming subsequent messages. That is, message holes are not allowed.
As long as the message fails, whether it is the corruption of Kafka's own message format or the abnormal processing of the consumer, it is not allowed to skip the failed message and continue to consume it later.
Therefore, Kafka is selected in the scenario where data statistics do not require very accurate . Once the message consumption problem occurs, the project will be unavailable. This really adds to the trouble.
As for RabbitMQ, when there is a problem with the message or the consumption is wrong, it can re-enter the queue or move the message to the dead letter queue, and continue to consume the later, which will save a lot of worry.
Bad news is like the bad guy in the crowd, and Kafka is too brutal to deal with this bad guy, and it has to catch the bad guy out. Relatively speaking, RabbitMQ is much gentler. The masses are the masses, and the bad guys are bad guys. They should be dealt with separately.
6. Message throughput
Kafka's throughput is hundreds of thousands of messages per second, while RabbitMQ's throughput is tens of thousands of messages per second.
In fact, within a company, there are really few projects that must use Kafka's large throughput. For most projects, the throughput of tens of thousands of messages per second like RabbitMQ is quite enough.
Introducing Kafka in some projects with less throughput, I think it is better to introduce RabbitMQ.
why?
Because Kafka has greatly increased its own complexity for better throughput. And these complexities are troublesome for the project, mainly reflected in two aspects:
1. Complex configuration and maintenance
The parameter configuration of Kafka is very complicated compared to RabbitMQ. For example: disk management related parameters, cluster management related parameters, ZooKeeper interaction related parameters, topic level related parameters, etc., all require some thinking and tuning.
In addition, Kafka's own cluster and ZooKeeper, which participates in managing the cluster, bring more maintenance costs. To use Kafka well, you need to consider the JVM, message persistence, the interaction of the cluster itself, and the reliability and efficiency of ZooKeeper itself and between it and Kafka.
2. Use it well, use the right threshold
There is also a high threshold for Kafka's Producer and Consumer to use them well.
For example, Producer message reliability guarantee, idempotency, transaction messages, etc., all require a deep understanding of KafkaProducer.
And not to mention Consumer, just a log offset management makes a lot of people lose a lot of hair.
Relatively speaking, RabbitMQ is much simpler. You may not need to configure anything, just start it up and you can use it stably and reliably. Even if it is configured, there are only a few parameter settings.
Therefore, when you introduce message queues into your project, you really have to think about it carefully, and don't introduce it without thinking because everyone advocates that Kafka is good.
Summarize
It can be seen that if we want to select the message queue, there are two things that must be done:
-
List the most important characteristics of your business
-
Dive into the details of message queues to compare
After we are very familiar with the characteristics of these middleware, we can even decompose the business into different sub-businesses, and then introduce different message queues according to the characteristics of different sub-businesses, that is, message queues are mixed. In this way, we may maximize our benefits and minimize our costs.
Having said so much, in fact, there are still many comparisons between Kafka and RabbitMQ that have not been said, such as the difference between the two clusters, the comparison of how much resources they occupy, and so on. There will be a chance to mention it later.
In short, I hope that after reading this article, you can have a more detailed understanding of the difference between Kafka and RabbitMQ.
Finally, share a more complete comparison picture on the Internet: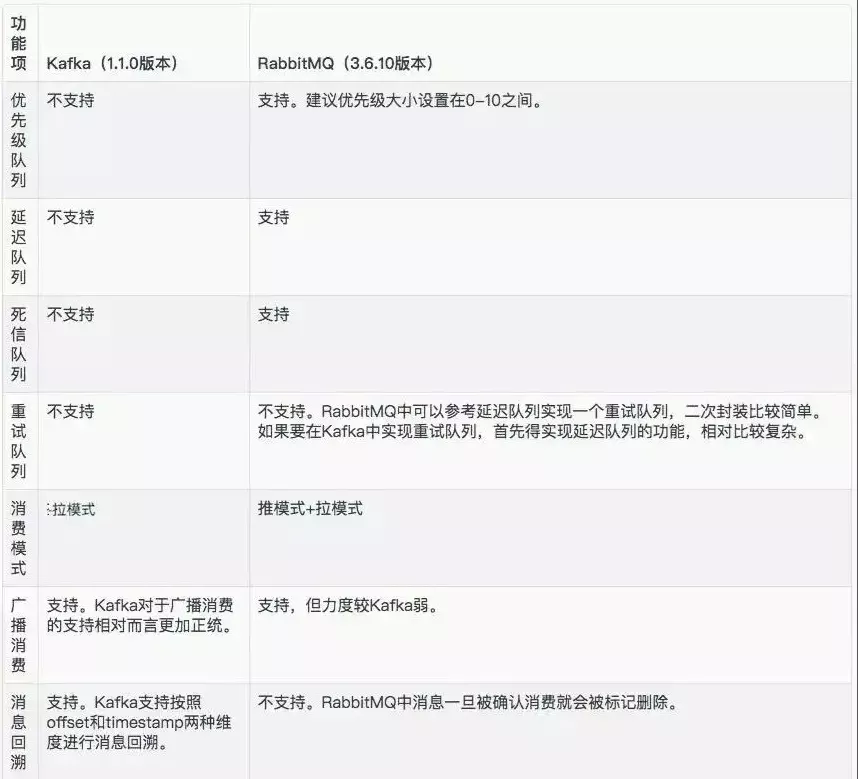

Hello, I'm Shimonai.
The technical director of a listed company, managing a technical team of more than 100 people.
I went from a non-computer graduate to a programmer, working hard and growing all the way.
I will write my own growth story into articles, boring technical articles into stories.
Welcome to pay attention to my official account. After following, you can receive high concurrency and algorithm learning materials.