[Part1 - Theory Chapter]
Just think about a question, if we want to capture the comment data of a Weibo big V Weibo, how should we achieve it? The easiest way is to find the Weibo comment data interface, and then change the parameters to get the latest data and save it. First, look for the interface for grabbing comments from the Weibo api, as shown in the following figure.
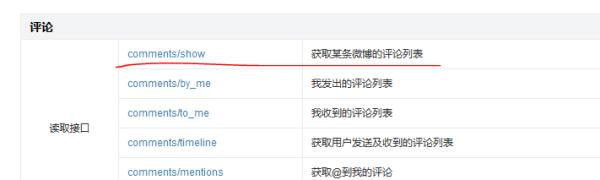
But unfortunately, the frequency of this interface is limited, and it was banned after being caught a few times. Before it started to take off, it was cold.
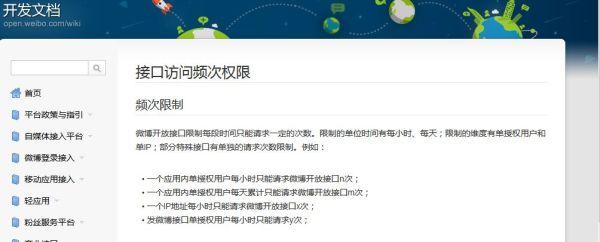
Next, the editor selects Weibo's mobile website, first log in, then find the Weibo we want to capture comments, open the browser's built-in traffic analysis tool, pull down the comments, and find the comment data interface, as shown in the following figure .
Then click the "Parameters" tab, you can see that the parameters are as shown in the following figure:
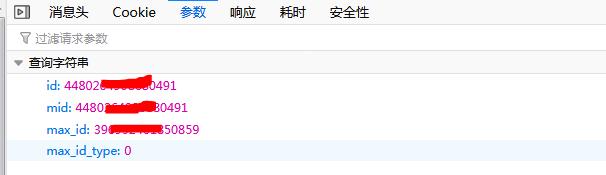
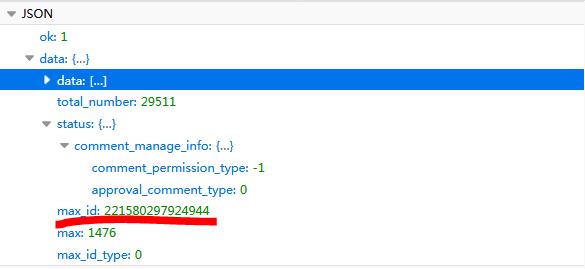
It can be seen that there are a total of 4 parameters, of which the first and second parameters are the id of the microblog, just like a person's ID number, which is equivalent to the "ID number" of the microblog, and max_id is the transformation The parameter of the page number must be changed every time, and the value of the next max_id parameter is in the returned data of this request.
【Part2 - Actual Combat】
With the above foundation, let's start to code and implement it in Python.

1. First distinguish the url, the first time does not need max_id, the second time you need to use the max_id returned for the first time.

2. You need to bring cookie data when requesting. The validity period of Weibo cookies is relatively long, which is enough to capture a Weibo comment data. The cookie data can be found from browser analysis tools.
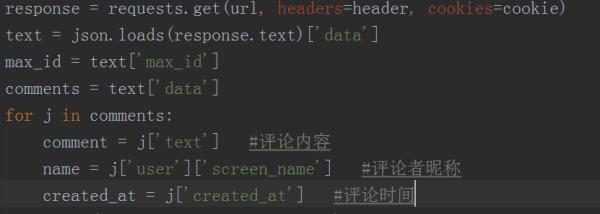
3. Then convert the returned data into json format, and extract data such as comment content, commenter's nickname and comment time, and the output result is shown in the following figure.

4. In order to save the comment content, we need to remove the expression in the comment and use regular expressions to process it, as shown in the following figure.

5. Then save the content to a txt file and use a simple open function to implement it, as shown in the following figure.

6. The key point is that you can only return up to 16 pages of data (20 per page) through this interface. There is also a report on the Internet that you can return 50 pages, but the interface is different and the number of data returned is also different, so I added a for Loop, one step in place, traversal is still very powerful, as shown in the following figure.

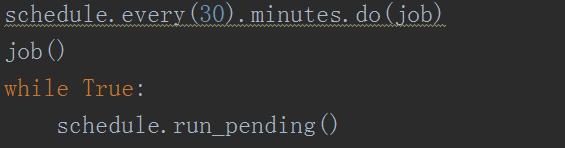
7. Here the function is named job. In order to always take out the latest data, we can use schedule to add a timing function to the program, and grab it every 10 minutes or half an hour, as shown in the following figure.
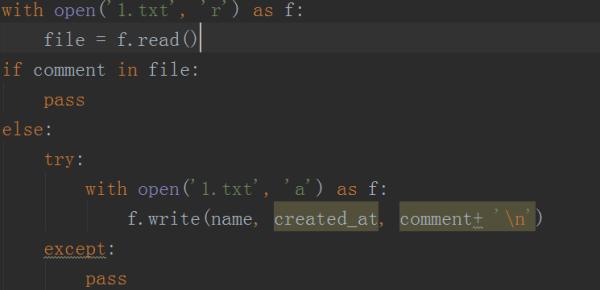
8. Perform deduplication processing on the obtained data, as shown in the following figure. If the comment is already there, just pass it, if not, just keep adding it.
This work is basically completed.
[Part3 - Summary]
Although this method does not capture all the data, it is also a more effective method under the constraints of this kind of Weibo.
If you really meet a good colleague, you are lucky, come on, learn quickly.
python share penguin circle: 1055012877
It includes artificial intelligence software such as python and crawlers, as well as programming methods for crawlers, network security, and fully automatic office.
Create a comprehensive analysis from zero foundation to project development to get started with actual combat!
Click to join