Recently at work, I need to export the data from the public Data Warehouse, put it into the cloud storage resources belonging to our team's own account, and then query such resources in our application. The data needs to be exported because querying data directly from the Data Warehouse is a slow and asynchronous process, and our application data query needs to be real-time. Now to solve this problem, there are some AWS services that we can choose from, basically divided into two categories:
The first category is Storage & Content Delivery:
- CloudFront: CloudFront is used to distribute content to users in different regions. It has several "edges" around the world as the entrance to access data from adjacent networks. Just like the CDN equipment established by the big website. This is obviously not what I need.
- Glacier: Glacier is ideal for storing infrequent, compressed and backed up massive file data, and it is the cheapest of the centralized file storage services. Such as storage logs, filing data, etc. Of course, it sacrifices performance and consistency of data transfer. Apparently it doesn't fit my scenario either.
- S3: S3 (Simple Storage Service) is suitable for storing raw data and large objects (a single upper limit of 5Tb), and the cost is lower than that of database services. If I finally decide to use a filesystem to store my data, it's a good choice. In addition, whether it is Glacier or S3, the hierarchical concept is the largest and is at the regional level (called vault in Glacier, bucket in S3, and each such unit is located in a certain region, such as Asin Pacific), so if Multiple nodes around the world need to access the same data, and additional data needs to be distributed to various regions.
- Storage Gateway: Storage Gateway is used for internal deployment in an integrated IT environment. It supports optimization based on gateway caching or optimization of gateway storage, facilitating rapid access to data from local and adjacent networks. It can be used for file sharing, mirroring or backup in different geographical locations within the company, and it is not suitable for my scenario here.
Selecting file storage cannot provide functions such as conditional query of the database. At present, it is not required in my scenario. I only need to obtain data sets according to different regions and data unique keys. Otherwise, I need to consider database services:
- DynamoDB: DynamoDB is a NoSQL database service hanging on the cloud. Each table needs to specify a hash primary key or a hash and range primary key. At the same time, the minimum unit of its data read and storage is 4KB. That is to say, the performance of accessing 0.5KB and 4KB data is almost the same. From the data volume, if I choose the database service, it is the best solution for my problem.
- SimpleDB: Similar to DynamoDB, it is a non-relational database, the structure can be changed at will, and the data is automatically indexed, so the query is very fast. Its data capacity is much smaller, and a typical use is to use SimpleDB to store S3 file addresses, like "pointers". However, its capacity limit needs to be considered. Each domain has only an upper limit of 10G, and multiple domains can be established, but then you need to apply yourself to route and select domains. Regarding consistency, it is the same as DynamoDB, you can choose between eventual consistency and strong consistency, of course, strong consistency costs more money and reduces throughput.
- ElastiCache: Moving Memcached or Redis to the cloud is obviously not what I need.
- RDS: RDS (Relational Database Service) is equivalent to moving the relational database to the cloud. The difference between it and DynamoDB or SimpleDB is mainly the difference between RDB and NoSQL DB.
- RedShift: RedShift is a data warehouse service that uses columnar storage technology and parallel distributed queries between nodes to optimize data access on P.
Here you can also find the differences between these database services on AWS, and use a table to cover them up:
| If You Need | Consider Using | |
| A relational database service with minimal administration | Amazon RDS, a fully managed service that offers a choice of MySQL, Oracle or SQL Server database engines, scale compute & storage, Multi-AZ availability and more. | |
| A fast, highly scalable NoSQL database service | Amazon DynamoDB, a fully managed service that offers extremely fast performance, seamless scalability and reliability, low cost and more. | |
| A NoSQL database service for smaller datasets | Amazon SimpleDB, a fully managed service that provides a schemaless database, reliability and more. | |
| A relational database you can manage on your own | Your choice of relational AMIs on Amazon EC2 and EBS that provide scale compute & storage, complete control over instances, and more. |
再有另一个技术选型的例子,在web容器中选择Tomcat还是Jetty。Jetty结构简单,容易定制其组件,也就是说,小和简单(这也是当初Google选择它作为app引擎的最重要原因), 是它最大的优势。Jetty在同时处理大量连接并且需要长时间保持这些连接的时候,性能上更有优势,因为它是基于NIO,而不是Tomcat的BIO来处 理请求的;但是我们也能找到很多性能测试的数据,在对于连接生命周期非常短而且非常频繁的请求,Tomcat的性能要优于Jetty。
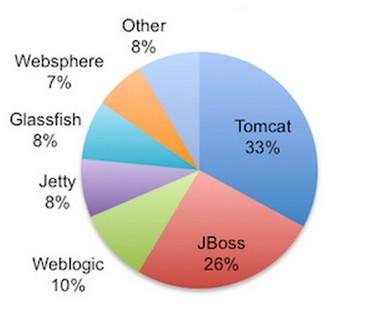
以下摘选自《Jetty VS Tomcat Performance Comparison》的二者比较:
Jetty Features and Powered:
- Full-featured and standards-based.
- Embeddable and Asynchronous.
- Open source and commercially usable.
- Dual licensed under Apache and Eclipse.
- Flexible and extensible, Enterprise scalable.
- Strong Tools, Application, Devices and Cloud computing supported.
- Low maintenance cost.
- Small and Efficient.
Tomcat Features and Powered:
- Famous open source under Apache.
- Easier to embed Tomcat in your applications, e.g. in JBoss.
- Implements the Servlet 3.0, JSP 2.2 and JSP-EL 2.2 support.
- Strong and widely commercially usable and use.
- Easy integrated with other application such as Spring.
- Flexible and extensible, Enterprise scalable.
- Faster JSP parsing.
- Stable.
在选择实现技术的时候经常会遇到这样或那样的选择题,上面的两个例子,都是相对理性地分析和比较的例子。我们考虑的内容往往包括功能、性能、社区支持、扩展性和定制性、已知问题和约束等等。
但是,具有讽刺意味的是,仔细想想,实际上我们选择某一项技术的最重要的原因,却远远不是那些“理智的分析”,而是下面这些:
- “因为大家都在用它啊”,比如项目用Java或者C++作为主要语言来实现,我想很多人和我一样,经常并没有经过太多思考,这似乎是一个思维惯性。
- “因为我没有用过这项技术,我感兴趣,我想学一下”,其实这也无可厚非,我以前也经历过一个项目组,大部分人(包括主管在内),都排斥使用新技 术,原因是担心风险。我原则上认同风险一说,但是适度范围内给程序员选择技术的自由从长远看是有好处的,尤其是技术也是需要进步的。把所有问题都让“工程 商人”来解决,只会让目光过于浅近。
- “因为我只知道它啊”,这种情况更多。你为什么选择C3P0连接池?因为那时候我不知道还有哪些别的数据库连接池……
工程师总会在技术选型的时候寻找某种平衡,纸面上未必会写这三条理由,但是心里面,有意识无意识地,一定会给向着这三条理由倾斜。
现在让我们退一步,倘若我们都非常理性地评估了类似技术的优缺点,但是在真正使用技术实现的时候,却发现,实际上这几条类似的技术都可以实现,选哪 个关系并不大。因为数据规模、问题大小,都不足以到了非得区分类似技术优劣的地步。举例来说,持久层使用MyBatis还是Hibernate,优秀的程 序员可以说出二者各自的好处是什么,也许对于大型项目至关重要;但是也有程序员会吐槽,其实用哪个都可以啊,好处坏处的差异并没有那么明显,因为我的项目 那么小,需要的数据库读写如此简单……
有人说,小项目可以帮助拓宽技术视野,但是只做小项目无法深入了解技术本身,因为你无从比较并理解类似技术的优劣。这也是“玩具代码”在学新东西的时候有成就感,也很适合技术分享的胶片之用,却无法带来工程师持续成长的原因。
你觉得是不是这样呢?
【stz总结:把握广度很深度的平衡。大项目做一个,深入理解某项技术+小项目多多扩展视野】