In our impression, the mysql data table is nothing more than storing data row by row. Similar to an excel.
Traversing this line of data directly, the performance is O(n), which is relatively slow. In order to speed up the query, B+ tree is used as the index, which optimizes the query performance to O(lg(n)) .
But here comes the problem. There are many data structures with lg(n) level of query data performance. For example, the jump table used in redis' zset is also lg(n) , and the implementation is quite simple.
So why doesn't the mysql index use the skip table?
Let's talk about this topic today.
The structure of the B+ tree
In a previous article , the structure of the B+ tree has been mentioned . The article is not long, if you haven't read it, it is recommended to read it first.
Of course, don't look at it.
Here, in order to mix up the word count, I briefly summarize the structure of the B+ tree.
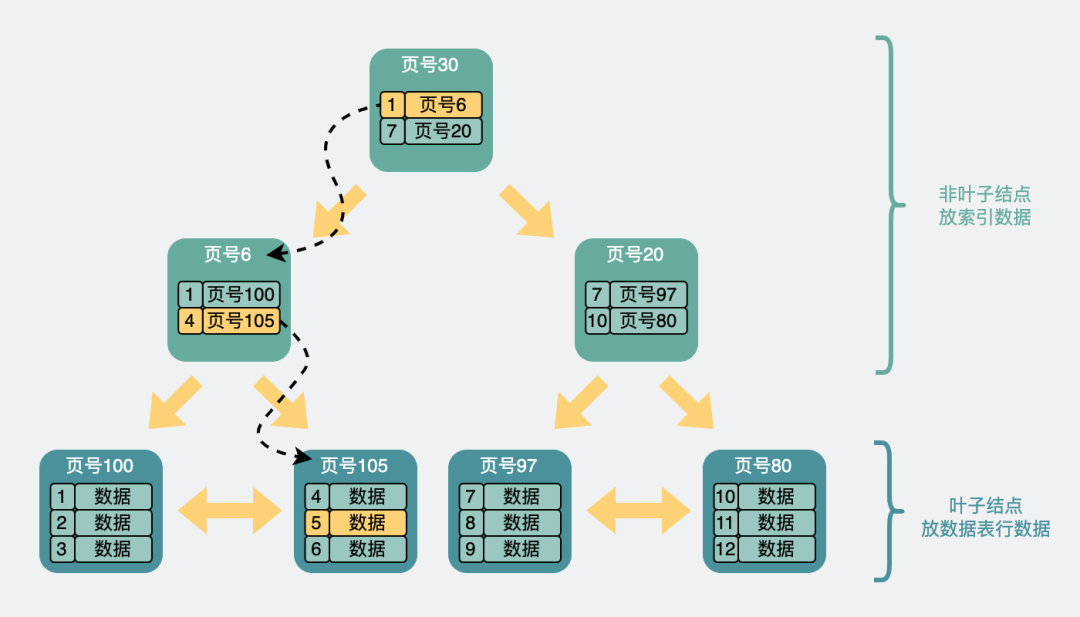
B+ tree query process
As shown in the figure above, the general B+ tree is a multi-level structure composed of multiple pages. For each page 16Kb, for the primary key index, the leaf node at the last level releases data, and the non-leaf node puts the index information (primary key id and page numbers) to speed up queries.
Let's say we want to find row data 5. It will start with the records on the top page. The record contains the primary key id and page number (page address) . Focus on the yellow arrow, the smallest id to the left is 1, and the smallest id to the right is 7. If the data with id=5 exists, it must be on the left arrow. So follow the page address of the record to the 6号data page, and then judge that id=5>4, so it must be in the data page on the right, so load the 105号data page.
There 105号数据页, although there are multiple rows of data, they are not traversed one by one . There is also a page directory information in the data page. It can speed up the query of row data through binary search , so the data row with id=5 is found and the query is completed. .
As can be seen from the above, the B+ tree uses the space-for-time method (constructs a batch of non-leaf nodes to store index information), and optimizes the query time complexity from O(n) to O(lg(n)) .
The structure of the skip table
After reading the B+ tree, let's take a look at how the jump table comes from.
In the same way, it is still to store row by row data.
We can chain them together with a linked list .

Single list
If you want to query one of the nodes in the linked list, the time complexity is O(n), who can withstand this, so he proposes some linked list nodes, and then builds a new linked list.
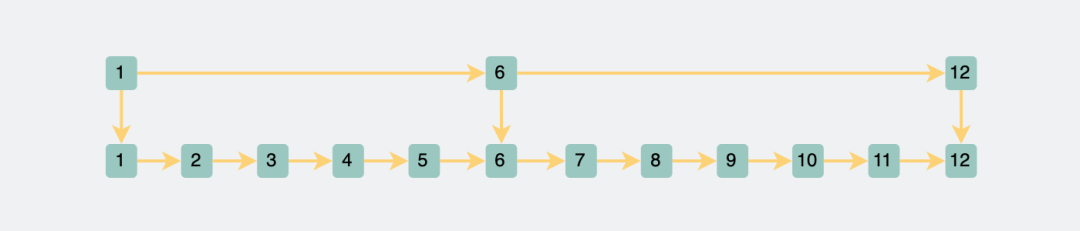
Two-tier skip table
In this way, when I want to query a piece of data, I first check the upper-level linked list, so it is easy to know which range the data falls in, and then jump to the next level to query. **This reduces the search scope by more than half at once.
For example, to query the data with id=10, we first traverse the upper layer, and judge 1, 6, 12 in turn, and soon we can judge that 10 is between 6 and 12, and then jump to the next step, we can traverse 6, 7, After 8,9,10, determine the position of id=10. Directly changing the query range from the original 1 to 10 to the current 1, 6, 7, 8, 9, and 10 is considered a cut in half.
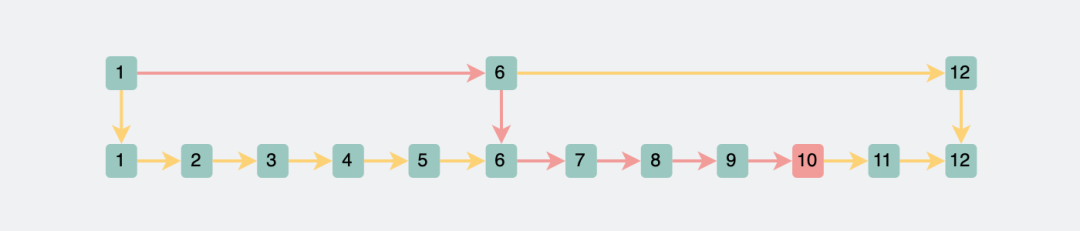
Two-level jump table to find data with id 10
Since the two-layer linked list directly cuts the query scope in half, wouldn't it be wonderful if I add a few more layers ?
So the skip table has become multi-layered.
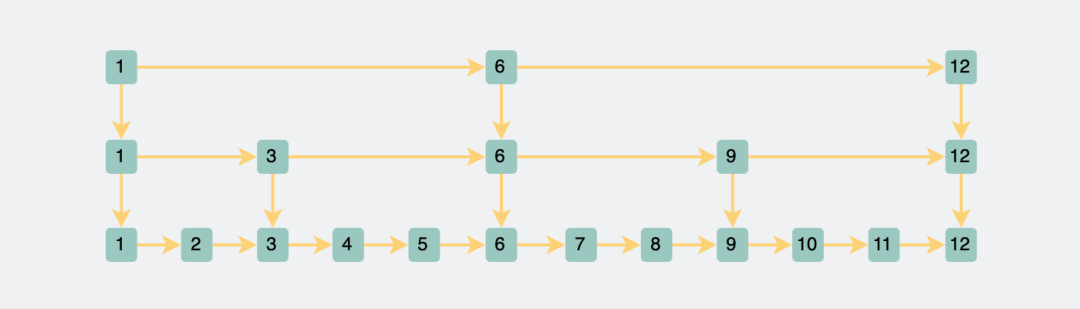
three-level skip table
If you still query the data with id=10, you only need to query 1, 6, 9, and 10 to find it, which is faster than the two layers.
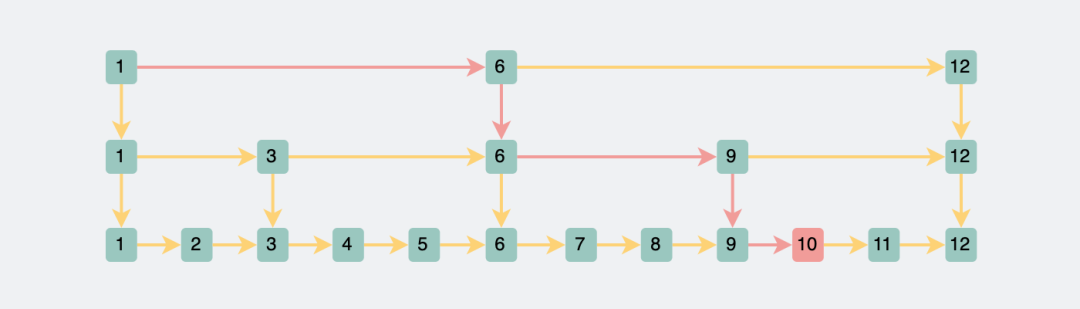
Three-level jump table query data with id 10
It can be seen that skipping the table also improves query performance by sacrificing space for time . The time complexity is lg(n) .
The difference between B+ tree and skip list
As can be seen from the above, the bottom layer of the B+ tree and the jump table contains all the data , and they are all sequential, suitable for range queries . The layers above are built to improve search performance. The two are so similar. But there are still some differences between the two when adding and deleting data . Let's talk about adding new data as an example.
What happens to the new data in the B+ tree
A B+ tree is essentially a multi-fork balanced binary tree. The key lies in the word " balance ". For the multi-fork tree structure, its meaning is that the height levels of the subtrees are as consistent as possible (generally one level difference at most), so that when searching, no matter which subtree it is to Branches, the number of searches is not much different.
When new data is continuously inserted into the database table, in order to maintain the balance of the B+ tree, the B+ tree will continue to split and adjust the data pages.
We know that the B+ tree is divided into leaf nodes and non-leaf nodes .
When inserting a piece of data, the maximum capacity of the leaf node and its upper index node (non-leaf node) is 16k, and they may be full.
To simplify the problem, we assume that a data page can only hold three rows of data or indexes.
Adding a piece of data can be divided into three situations according to whether the data page will be full.
- Neither leaf node nor index node is full . This is the easiest case, just insert it directly into the leaf node.
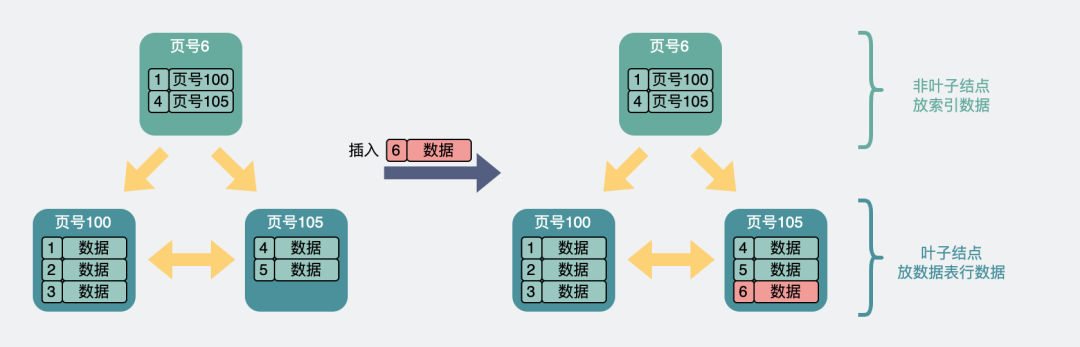
Both leaf and non-leaf are not full
- Leaf nodes are full, but index nodes are not . At this time, the leaf nodes need to be split, and the index nodes need to add new index information.
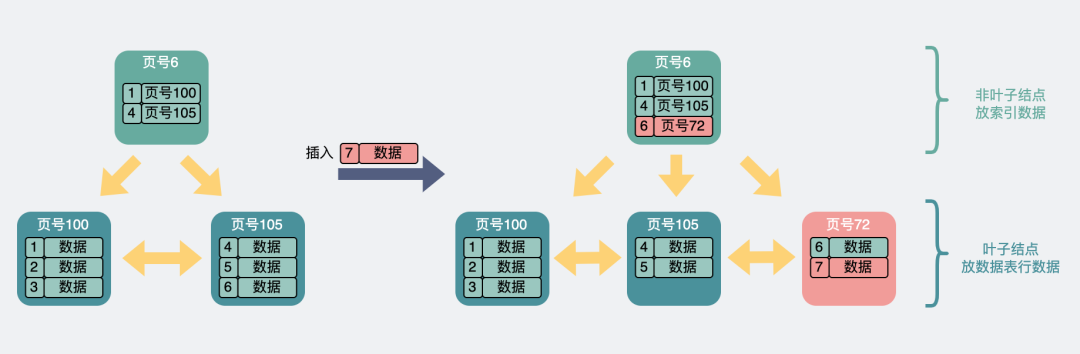
The leaves are full but not the leaves are not full.drawio
- Leaf nodes are full, and index nodes are also full . The leaves and index nodes should be split, and a layer of index should be added .
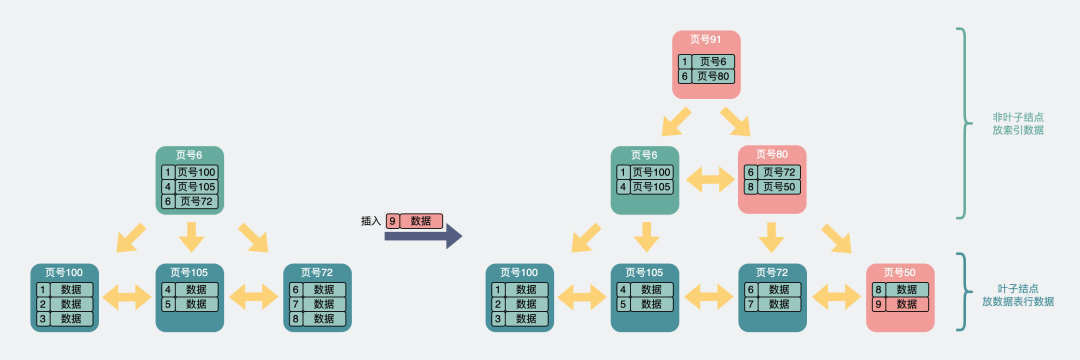
full of leaves and non-leaves
As can be seen from the above, only when the leaves and index nodes are full , the B+ tree will consider adding a new layer of nodes.
From the previous article , we know that to fill the three-layer B+ tree, it takes about 2kw of data.
Jump table new data
The skip list also has many layers. When adding a new data, the bottommost linked list needs to insert data.
At this point, do you need to add data to the upper layers for indexing?
This is purely a random function .
In theory, in order to achieve the effect of two divisions , the number of nodes in each layer needs to be one-half of the number of nodes in the next layer.
That is to say, there is now a new data inserted, and 50%some probability needs to be 第二层added to the index, and 25%some probability needs to be 第三层added to the index, and so on until 最顶层.
For example, if the data id=6 is inserted in the skip table, and the random function returns the third level (with a 25% probability), then it is necessary to insert data from the bottom to the third level of the skip table.
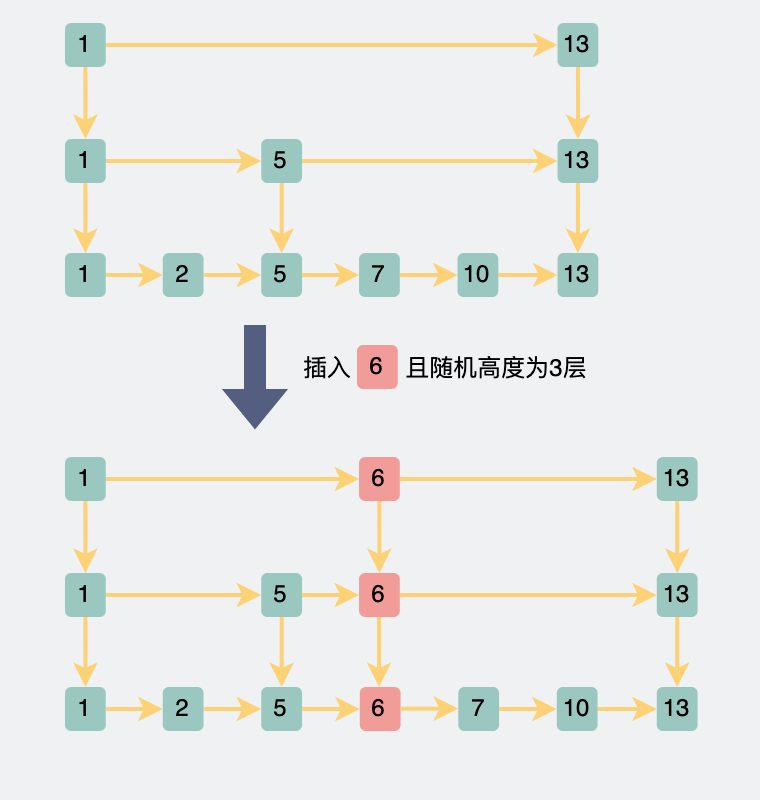
Jump table insert data
If this random function is designed as above, when the data sample is large enough , the distribution of the data will meet our ideal "dichotomy".
Unlike the B+ tree above, whether the skip table adds new layers or not depends purely on random functions, and does not care about the front and rear nodes at all.
Well, the basic science is over, we can get to the point.
Why does Mysql index use B+ tree instead of skip table?
The B+ tree is a multi-fork tree structure, and each node is a 16k data page, which can store more index information, so the fan-out is very high . About three layers of data can be stored 2kw(just know the conclusion, if you want to know the reason, you can read the previous article ). That is to say, to query data once, if these data pages are all in the disk, then you need to query the disk IO at most three times .
The skip table is a linked list structure, one piece of data and one node. If the bottom layer needs to store 2kwdata, and each query must be able to achieve the effect of binary search2kw , it is about 2的24次方left and right. Therefore, the height of the skip table is about 24 layers . In the worst case, these 24 layers of data will be scattered in different data pages, that is, a data query will experience 24 disk IOs .
Therefore, for the same amount of data, the height of the B+ tree is less than that of the skip table. If it is placed on the mysql database, the number of disk IOs is less, so the B+ tree query is faster .
For write operations , the B+ tree needs to split and merge the index data pages, and the skip table is inserted independently, and the number of layers is determined according to the random function. There is no overhead of rotation and balance maintenance, so the write performance of the skip table will be better than that of the B+ tree.
In fact, the storage engine of mysql can be replaced. It used to be myisam, and it was only later . They all use B+ treesinnodb for the underlying indexes . That is to say, you can build a storage engine whose index is a skip table and install it in mysql. In fact, a new storage engine was built, and a skip table was used in it . Straight to the conclusion, its write performance is indeed better than innodb, but its read performance is indeed much worse than innodb. If you are interested, you can see their performance comparison data in the references at the end of the article.facebookrocksDB
Why does redis use a skip table instead of a B+ tree or binary tree?
Redis supports a variety of data structures, and there is an ordered set , also called ZSET . The internal implementation is the skip table . So why use a jump table instead of a structure such as a B+ tree?
This is asked in almost every interview.
Although I am already familiar with it, I have to pretend that I didn't think about it before every time, and I only know the answer after thinking about it on the spot.
Really, it's a test of acting skills.
As we all know, redis is a pure in-memory database.
Reading and writing data is all about operating memory, which has nothing to do with disk, so there is no disk IO , so layer height is no longer a disadvantage of skipping tables.
And it was mentioned earlier that the B+ tree has a series of merge and split operations. If it is replaced by a red-black tree or other AVL tree, it is also a variety of rotations, and the purpose is to maintain the balance of the tree .
When inserting data into the skip table, you only need to randomize it to know whether you want to add an index, and you don't need to consider the feelings of the front and rear nodes, and the overhead of rotation balance is reduced .
Therefore, redis chose the jump table instead of the B+ tree.
Summarize
-
The B+ tree is a multi-fork balanced search tree with high fan-out. It only needs about 3 layers to store data of about 2kw. In the same case, the jump table needs about 24 layers. Assuming that the layer height corresponds to disk IO , then the read performance of the B+ tree It is better than skipping the table, so mysql chose B+ tree as the index.
-
The read and write operations of redis are all performed in memory, and no disk IO is involved. At the same time, the implementation of the jump table is simple. Compared with the B+ tree and AVL tree, the overhead of rotating the tree structure is less. Therefore, redis uses the jump table to implement ZSET instead of the tree. structure.
-
The storage engine RocksDB uses a skip table internally. Compared with innodb using a B+ tree, although the write performance is better, the read performance is actually worse. In the scenario of reading more and writing less, the B+ tree is still YYDS.
References
"MYSQL Kernel: INNODB Storage Engine Volume 1"
《RocksDB and Innodb engine performance PK is unpredictable? 》
https://cloud.tencent.com/developer/article/1813695
At last
Recently, I was watching "Dragon and Snake Romance", the plot is very general, but I just watched the latest episode in one breath, and it was very good.
why?
Click on it and you will understand me when you see the heroine.

Let me put it this way, a beautiful and hot sister, and a world-class martial arts master, wearing a cheongsam, stepping on high heels, and doing all kinds of movements that make Newton's coffin board almost unable to hold down, just to hold hands Teach you the basics of martial arts.
At this point, does the plot still matter?
I have to say, when I saw my sister dressed like this and used a wooden stick to lift a 400-pound mercury ball.

I'm sure the director doesn't understand physics at all.
but!
The director understands men very well!
This has to make me ponder, what exactly is good content?
Is there a big sister who wears a black silk high-heeled miniskirt now and teaches you such basic things as variable declaration and definition, will you also watch it?
I don't know if you will.
I will anyway.

Recently, the reading volume of original updates has steadily declined, and after thinking about it, I tossed and turned at night.
I have an immature request.

It's been a long time since I left Guangdong, and no one called me Pretty Boy for a long time.
Can you call me a pretty boy in the comment area ?
Can such a kind and simple wish of mine be fulfilled?
If you really can't speak out, can you help me click the like and watch in the lower right corner ?
Stop talking, let's choke in the ocean of knowledge together
Pay attention to the public number: [Xiaobai debug]
Promise me, after paying attention, learn techniques well, don't just collect my emojis. .
32 original content
No public
Not satisfied with talking shit in the message area?
Add me, we have set up a group of paddling and bragging. In the group, you can chat about interesting topics with colleagues or interviewers you may encounter next time you change jobs. Just super! open! Heart!