introduction
MinIO claims to be the fastest object storage server out there. On standard hardware, object storage can have read/write speeds of up to 183 GB/s and 171 GB/s. Object storage can be used as the primary storage layer for various complex workloads such as Spark, Presto, TensorFlow, H2O.ai, and as a replacement for Hadoop HDFS. That is, building high-performance infrastructure for machine learning, analytics, and application data workloads.
Technology selection (why choose minio)
What this section wants to discuss is why I choose minio, or in a larger direction, why I use object storage. According to the information I found and my personal understanding, I will make a preliminary introduction below.
Object Storage vs File Storage
There is a very detailed analysis of this question in Zhihu. Many big guys have written their own understandings. I will pick some expressions here: What is the essential difference between block storage, file storage, and object storage?
- Object storage (key-value database): The interface is simple. An object can be regarded as a file, which can only be written and read in full. Usually, large files are the main ones, and sufficient IO bandwidth is required.
- Block storage (hard disk): Its IO characteristics are consistent with traditional hard disks. A hard disk should be able to meet general needs, that is, it can handle large file reading and writing, and can also handle small file reading and writing. But the hard disk is characterized by large capacity and obvious hot spots. Therefore, block storage can mainly deal with hot issues. In addition, block storage requires the lowest latency.
- File storage (file system): The system design of the interface supporting file storage is consistent with the characteristics and difficulties of traditional local file systems such as Ext4. It has richer interfaces than block storage, and needs to consider the support of directories, file attributes, etc. , implementing a file store that supports parallelization should be the most difficult. But systems like HDFS and GFS, which define their own standards, can define the interface according to the implementation, which will be easier.
According to my understanding, the essential difference between file storage and object storage is that the distributed file storage file is organized as a directory tree, that is, the tree format in Linux, and the object storage adopts a flat organization method; the essential difference between the three is to use The "users" of data are different: the users of block storage are software systems that can read and write block devices, such as traditional file systems and databases; the users of file storage are natural persons; the users of object storage are other computer software.
For block storage, although the delay is very low, the data is protected by means such as Raid and LVM, and the parallel writing method can achieve a delay of 10ms, but the cost is high, which is not conducive to the connection between hosts of different operating systems. Issues such as data sharing are also at risk. For file storage, the cost is low, files can be shared between different hosts, and FTP and NFS services are used, which can be distributed, but there are bottlenecks, and the problem of low efficiency when the number of files increases cannot be overcome.
The reason for the emergence of object storage is to overcome the shortcomings of block storage and file storage, and to promote their respective advantages. In short, block storage is fast to read and write, which is not conducive to sharing, and file storage is slow to read and write, which is conducive to sharing. Can you get a fast read and write, which is beneficial to sharing. Hence the object storage.
Object storage can be understood as decomposing a file into objects for storage. Simply put, a piece of metadata will be attached to the storage file. When querying, find the metadata and locate the file. To use an inaccurate but helpful analogy, object storage is equivalent to adding a descriptive label to the blocks of block storage, which enhances the queryability of files and facilitates management. Object storage can be said to combine the advantages of file storage and block storage, and is the development direction of storage. It is the optimal file storage method for programs and systems.
Distributed storage comparison
Two blogs are mainly quoted here, because it is impossible for me to try every open source software, and I made a choice after comparing them at the beginning.
Inventorying Distributed File Storage Systems
Ceph VS MinIO Comparison of Distributed Storage Systems
Distributed storage comparison:
| File system | Developers | Development language | open source protocol | Ease of use | Applicable scene | characteristic | shortcoming |
|---|---|---|---|---|---|---|---|
| GFS | Not open source | ||||||
| HDFS | Apache | Java | Apache | Simple installation and professional documentation | Store very large files | Batch read and write of large data, high throughput; write once, read many times, read and write sequentially | It is difficult to meet the low-latency data access at the millisecond level; it does not support concurrent writing of the same file by multiple users; it is not suitable for a large number of small files |
| Ceph | Sage Weil, UC Santa Cruz | C++ | LGPL | Simple installation and professional documentation | Large, medium and small files in a single cluster | Distributed, no single point of dependency, written in C, better performance | Based on immature btrfs, it is not mature and stable enough, and is not recommended for use in production environments |
| TFS | Ali Baba | C++ | GPL V2 | The installation is complicated and there are few official documents | Small files across clusters | Tailored for small files, the random IO performance is relatively high; it implements soft RAID, which enhances the system’s concurrent processing capability and data fault-tolerant recovery capability; supports active-standby hot swap to improve system availability; Provide read/standby function | Not suitable for storage of large files; does not support POSIX, low versatility; does not support custom directory structure and file permission control; download through API, there is a single point of performance bottleneck; few official documents, high learning costs |
| Lustre | SUN | C | GPL | Complicated and heavily dependent on the kernel, the kernel needs to be recompiled | read and write large files | Enterprise-level product, very large, deeply dependent on the kernel and ext3 | |
| MooseFS | Core Sp. z o.o. | C | GPL V3 | Simple installation, many official documents, and a web interface for management and monitoring | Read and write a large number of small files | Relatively lightweight, written in perl, more people use it in China | There is a single point of dependence on the master server, and the performance is relatively poor |
| MogileFS | Danga Interactive | Perl | GPL | Mainly used in the web field to process massive small pictures | key-value meta file system; much more efficient than mooseFS | FUSE is not supported | |
| FastDFS | Domestic developer Yu Qing | C | GPL V3 | Simple installation and relatively active community | Small and medium files in a single cluster | The system does not need to support POSIX, which reduces the complexity of the system and has higher processing efficiency; realizes soft RAID, which enhances the system's concurrent processing capability and data fault-tolerant recovery capability; supports master-slave files and custom extensions; master-slave Tracker service, Enhance system availability | It does not support resumable uploading, which is not suitable for large file storage; it does not support POSIX, and its versatility is low; there is a large delay in the synchronization of files across public networks, and corresponding fault tolerance strategies need to be applied; the synchronization mechanism does not support file correctness Verification; download through API, there is a single point of performance bottleneck |
| GlusterFS | Z RESEARCH | C | GPL V3 | Simple installation and professional documentation | Suitable for large files, there is still a lot of room for optimization of small file performance | No metadata server, stacking architecture (basic functional modules can be stacked to achieve powerful functions), with linear horizontal expansion capability; larger than mooseFS | Since there is no metadata server, it increases the load of the client and occupies a considerable amount of CPU and memory; however, when traversing the file directory, the implementation is more complicated and inefficient, and all storage nodes need to be searched. It is not recommended to use a deeper path |
| GridFS | MongoDB | C++ | easy installation | Usually used to handle large files (over 16M) | Partial files can be accessed without loading the entire file into memory, maintaining high performance; files and metadata are automatically synchronized |
Ceph VS MinIO for Distributed Storage System Comparison:
| Ceph | MiniO | |
| advantage | · Mature · Stepson of Red Hat, Ceph founder has joined Red Hat · Powerful function · Support thousands of nodes · Support dynamic increase of nodes and automatically balance data distribution. · Strong configurability, can be tuned for different scenarios | · Low learning cost, simple installation, operation and maintenance, and out-of-the-box use · At present, the MinIO forum is very popular, and you can answer any questions. · There are java clients and js clients. Data protection: Distributed MinIO uses erasure codes to prevent multiple nodes Downtime and bit decay bit rot. Distributed MinIO requires at least 4 hard disks, and the erasure coding function is automatically introduced using distributed MinIO. Consistency: MinIO in distributed and stand-alone mode, all read and write operations strictly follow the read-after-write consistency model. · Support federated mode expansion cluster |
| shortcoming | · High learning cost and complicated installation, operation and maintenance. · There are so-called Ceph Chinese communities in China, private institutions, inactive, documents are lagging behind, and there is no sign of updating. | · It does not support dynamic increase of nodes. The design concept of the founder of MinIO is that it is too complicated to dynamically increase nodes, and other solutions will be adopted to support expansion in the future. |
| Development language | · C | · Go |
| data redundancy | Copy, erasure coding | · Reed-Solomon code |
| consistency | · Strong consistency | · Strong consistency |
| Dynamic expansion | · HASH | · Dynamic node addition is not supported |
| central node | · Object storage centerless | CephFS has a central point of metadata service |
| storage method | block, file, object | · Object storage |
| Activity | · High, the Chinese community is not very active | · High, no Chinese community |
| maturity | · high | · middle |
| File system | · EXT4, XFS | · EXT4, XFS |
| client | C 、 python, S3 | java,s3 |
| http | · 兼容S3,分段上传,断点下载 | · 兼容S3,分段上传,断点下载 |
| 学习成本 | · 高 | · 中 |
| 开源协议 | · LGPL version 2.1 | · Apache v2.0 |
| 管理工具 | · Ceph-admin,Ceph-mgr,zabbix插件 | · web管理工具 命令行工具 mc |
个人理解
第一张表中,针对中小文件作为主要区分分布式存储的特征,以及还有具有web界面与便于安装这两者具有简化操作的功能能判断是否足够友好,相对而言我觉得简单易用的是MooseFS,MogileFS,FastDFS,GlusterFS;除了fastdfs,其它三款我好像了解也不是很多,但单说fastdfs,可能作为单节点来说,确实很不错,操作用其它语言api来讲也还行,反正根据我之前搭建的过程来讲,没有编译C++的东西复杂,但多节点听说就很复杂了,而且我看B站上的视频讲得也很长,顿时就有了种不想看的感觉,emmm。
第二张表中,可以很明显的看到,ceph各方面都比minio优秀,但是它的缺点尤其明显,太过于复杂和难于管理,我也有针对ceph看过相关资料,ceph是一款面向团队的产品,它的高度自动化带来遍历的同时,系统的运行状态不完全在管理员控制之下,系统中会有若干自动触发而不是管理员触发的操作,这需要运维团队针对这些可能出现的情况进行预案以及适应。但我仅仅一个人,别说运行起这个东西,就算真运行起来了,我感觉也会自己把自己坑死,emmm。。
所以minio毫不意外的成为了我的选择,即最开头引言的最后一句话,“为机器学习、分析和应用程序数据工作负载构建高性能基础架构”。因为我本身工作涉及视频图像算法,上面这句话是在GitHub中作为minio的第一段介绍中强调,我感觉如果对业务足够敏感,对于身兼PPT技术的大佬来讲,这一句话瞬间能醍醐灌顶。为啥?这star量,加上开头这句话,这不就是PPT素材嘛,甚至都不用考虑能不能用。别给我扯什么分布式,高可用,云原生,老夫敲代码就是一把梭(滑稽),最主要呢,还是得老板开心,老板开心我就很开心,虽然疫情挺严重,还是得过个好年的,emmm。。。
minio部署与测试
minio的单节点部署
关于部署这一块,作为用go语言所写的底层,minio展现出了非常强大的跨系统以及兼容性,我之前是用了两台非docker下部署了集群,还不错,操作很简单。但因为写本篇的时候是在家,刚好试试在之前买的腾讯云部署。
docker pull minio/minio
mkdir -p /data/minio/config
mkdir -p /data/minio/data
docker run -p 9000:9000 -p 9090:9090 --net=host --name minio -d --restart=always -e "MINIO_ACCESS_KEY=minioadmin" -e "MINIO_SECRET_KEY=xxx" -v /data/minio/data:/data -v /data/minio/config:/root/.minio minio/minio server /data --console-address ":9090" -address ":9000"
minio的本地部署与docker部署都很简单,上面secret_key是密码,填写完运行即启动了minio,不过上面命令需要注意的是docker安装完后会有三种网络模式,-p使用的是bridge模式,而–net=host使用的是host模式,并且host模式优先级强于前者,所以上面-p指定的端口是无效的,因为网络默认绑定宿主机了。我也是去看了下别人运行的命令,不过有些确实没啥必要。
没报错启动后,我们就能输入localhost:9090进入登录界面,登录成功后如下图:
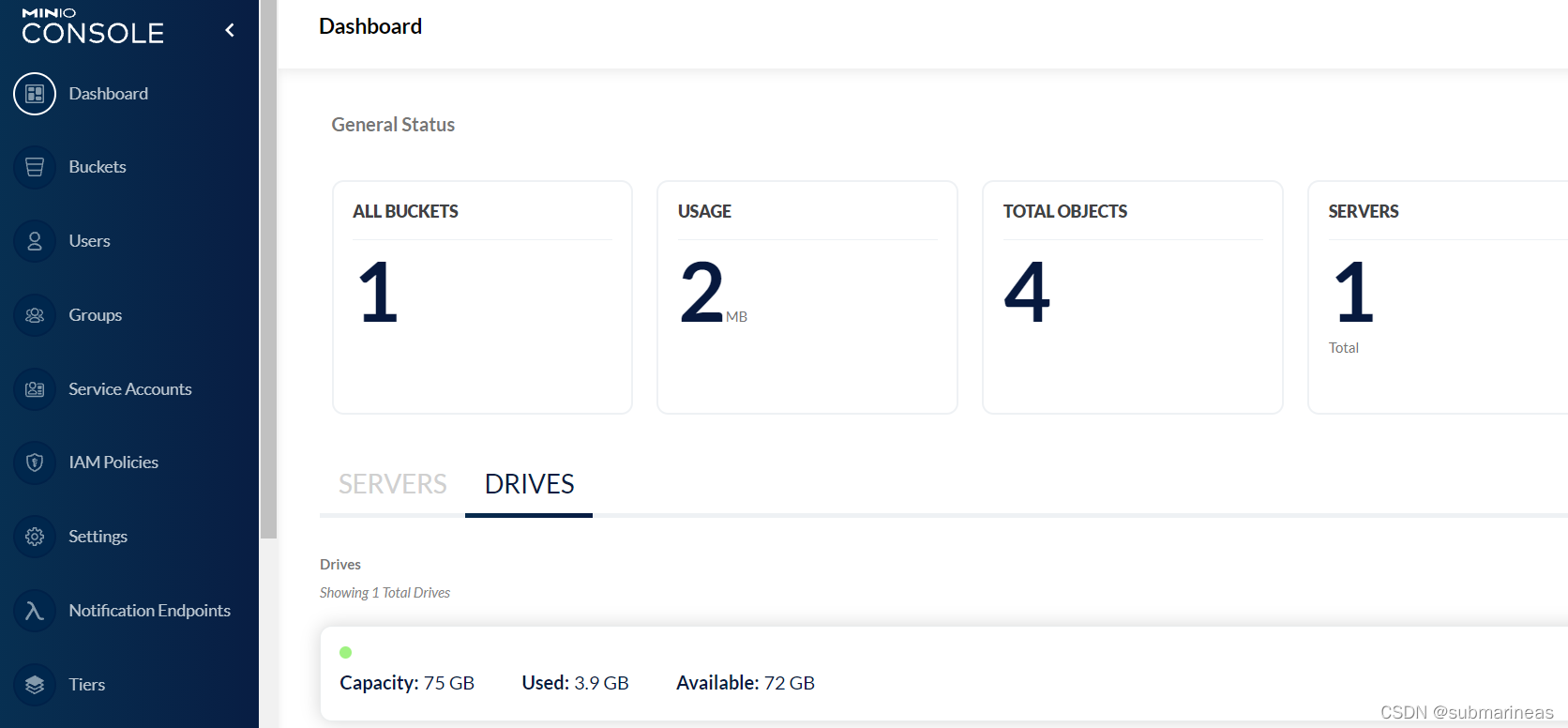
我这里因为刚部署上去,加了一个bucket,并丢了几张图上去,bucket应该不用多说,对象存储s3存储单元都叫这个。minio的操作界面非常友好了,基本小白都能懂,然后我原先还没发现,它能显示的格式是真的多,连webp这种小众格式还有PDF都能看:

|
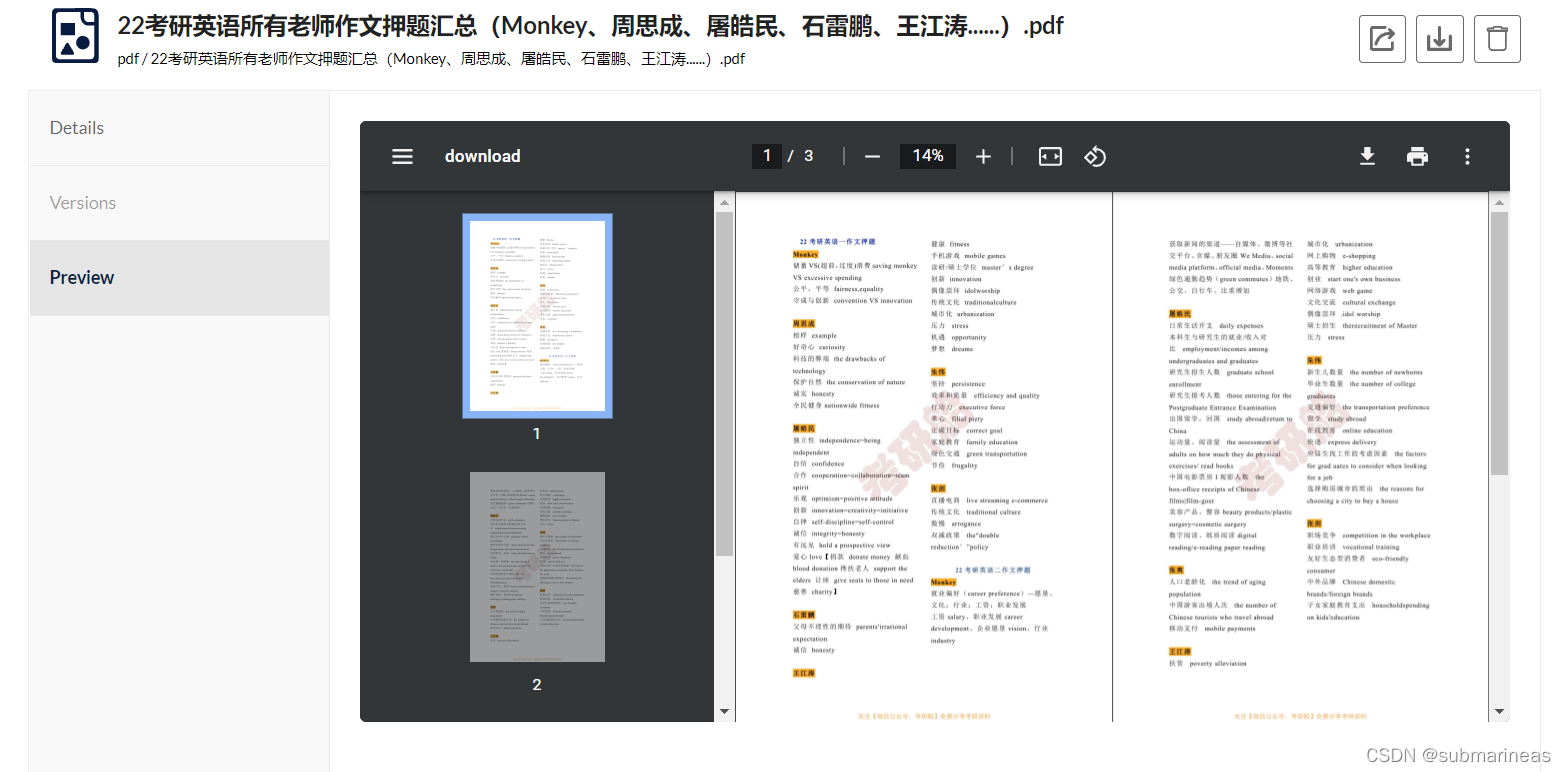
|
PDF还内置双页打开,如果不是窗口太小,都能拿来划水了。。同样,之前用公司搭的上传了部分视频,如果玩过音视频的可能知道,视频编码格式有非常多种,web端最能接受的是avc1,而其它格式在网页端很难直接播放,但minio就我测试来看,似乎很强。这里就不再演示了,更多的可以去官网直接看它对此做的改进。
minio上传与下载
minio上传测试:
import logging
from minio import Minio
from minio.error import S3Error
logging.basicConfig(
level=logging.INFO,
filename='test.log',
filemode='a',
format='%(asctime)s %(name)s %(levelname)s--%(message)s'
)
# 确定要上传的文件
file_name = "self_introduction.m4a"
file_path = "/home/video/{}".format(file_name)
def upload_file():
# 创建一个客户端
minioClient = Minio(
'IP:Port',
access_key='xxxx',
secret_key='xxxx',
secure=False
)
# 判断桶是否存在
check_bucket = minioClient.bucket_exists("pdf")
if not check_bucket:
minioClient.make_bucket("pdf")
try:
# logging.info("start upload file")
print("start upload file")
minioClient.fput_object(bucket_name="pdf", object_name="data/{}".format(file_name),
file_path=file_path)
# logging.info("file {0} is successfully uploaded".format(file_name))
print("file {0} is successfully uploaded".format(file_name))
except FileNotFoundError as err:
logging.error('upload_failed: '+ str(err))
except S3Error as err:
logging.error("upload_failed:", err)
if __name__ == '__main__':
upload_file()

网页上可以看到为:
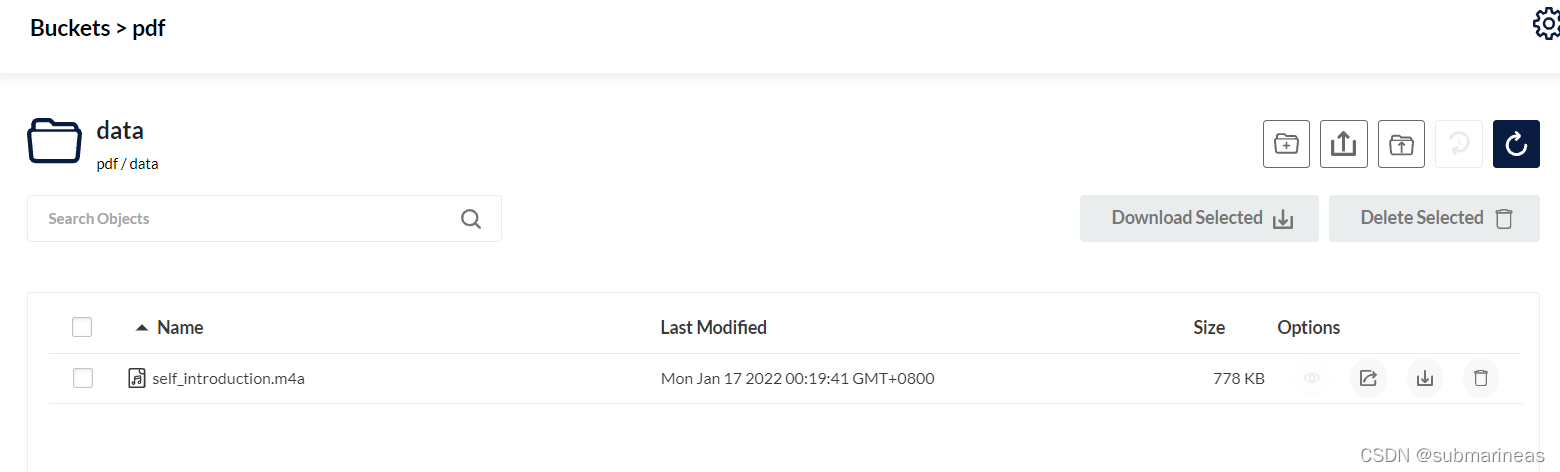
minio下载测试:
import logging
from minio import Minio
from minio.error import S3Error
logging.basicConfig(
level=logging.INFO,
filename='test.log',
filemode='a',
format='%(asctime)s %(name)s %(levelname)s--%(message)s'
)
# 要下载文件
file_name = "self_introduction.m4a"
file_path = "G:\\360Downloads\\img\\{}".format(file_name)
def download_file():
# 创建一个客户端
minioClient = Minio(
'IP:Port',
access_key='xxxx',
secret_key='xxxx',
secure=False
)
try:
minioClient.fget_object(
bucket_name="pdf",
object_name="data/{}".format(file_name),
file_path=file_path
)
logging.info("file '{0}' is successfully download".format(file_name))
except S3Error as err:
logging.error("download_failed:", err)
if __name__ == '__main__':
download_file()
这里就不再举例,关于批量上传 or 下载,可以加个for循环,以及去官网查看更多的api,GitHub地址为:
https://github.com/minio/minio-py
当然官网也有api的介绍,这里推荐的官网也英文版本的,虽然它有中文,不过毕竟不是官方在维护,有所滞后,所以能看懂英文还是推荐英文。
minio纠删码技术
这里算是分布式的高可用应用场景,这里我了解不深,根据官网的说法来讲,docker是按如下方式启动:
docker run -p 9000:9000 --name minio \
-v /mnt/data1:/data1 \
-v /mnt/data2:/data2 \
-v /mnt/data3:/data3 \
-v /mnt/data4:/data4 \
-v /mnt/data5:/data5 \
-v /mnt/data6:/data6 \
-v /mnt/data7:/data7 \
-v /mnt/data8:/data8 \
minio/minio server /data1 /data2 /data3 /data4 /data5 /data6 /data7 /data8
然后就能随意插拔小于等于一半阵列数量的硬盘,它会采用Reed-Solomon code将对象拆分成N/2数据和N/2 奇偶校验块,来保证数据安全。关于里面是啥逻辑我不知道,但就我试验情况,我两台使用此方式启动,其中一台reboot,另一台开始错误日志起飞,可能这算是一种预警,然后恢复数据倒没观察,因为本身玩也没多久,还算一个预案,只能说还行。未完待续,后续如果有测试出其它问题会进行补充。