在第一篇关于hadoop集群的文章中主要是讲了关于集群的一些基础原理知识,以及准备了三台独立的虚拟机。
在正式进行集群部署时,我们还需要做一点点的准备,那就是ssh的安装,那为什么要在集群部署中安装ssh呢? 请留意后面做出的解释
scp(完全拷贝)
试想一下这样一个场景:当你在hadoop100虚拟机上有一个scp_test文件夹,这时候你要拷贝到其他两台虚拟机上,第一种方法就是直接拷贝,用u盘复制出来,这种办法显然不是我们程序员该做的;第二种办法就是利用scp命令行进行拷贝。
基于语法
scp -r scp_test leon@hadoop99:work/

参数说明:
-r :递归拷贝,在拷贝文件夹时候必须添加
scp_test :需要拷贝的目标文件夹,这是我事先建立好的测试文件夹
leon:是我的一个用户名,这是最开始第一章中我们建立好的,它的权限和root一样;
hadoop99:目标主机名,这里本来是要写目标主机的ip,为什么可以写主机名?其实是做了一些设置后,它其实也是表示目标虚拟机的ip地址;
work:这就是要拷贝到的目的地文件夹;
主机名设置
在之前的scp命令中,为什么可以使用hadoop99表示主机,其实是经过了一个简单的设置,具体设置如下:
第一步:设置每个主机的主机名
sudo vim /etc/hostname

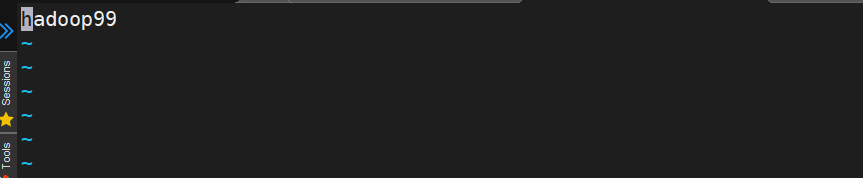
打开后在里面写上我们的主机名为hadoop99就可以了,这时hadoop99主机名就表示这台虚拟机的ip地址,以后用谁都可以找到这台虚拟机了。
但是这只是指定了主机名,只有自己才知道自己的名字,那其他的主机如何知道我这台主机的主机名呢?那就需要做一个公示?也就是第二步。
第二步:主机名公示
sudo vim /etc/hosts

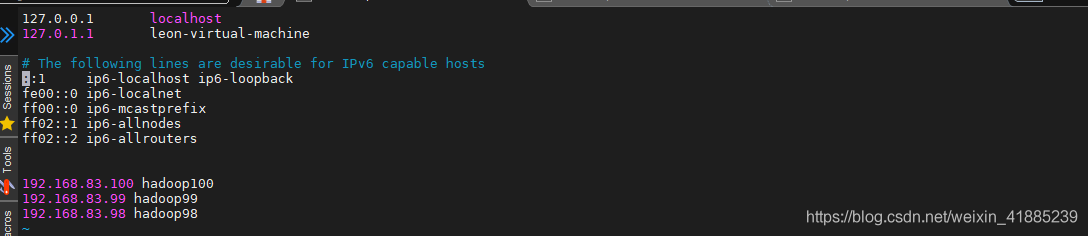
只有在这里公示主机名,三台机子才可以互相知道对方的主机名。
rsync(部分拷贝)
为什么要将rsync呢,肯定是因为之前的scp同步有缺陷,scp的缺陷在于:每次拷贝都会完全拷贝,倘若我们只修改了一个小文件,但是用scp同步时,就需要同步整个文件,耗时耗力,这时候rsync出现,rsync会自动识别出修改过的文件,在整个文件的同步时,只同步修改过的那些文件,针对性强。快速且不耗费资源。
基本语法
rsync -av works leon@hadoop98:works
参数说明:
-av :递归拷贝,在拷贝文件夹时候必须添加
works :需要拷贝的源文件夹,这是我事先建立好的测试文件夹,如果只是拷贝具体文件夹下的某个文件,比如1.txt,只需要works/1.txt就行。
leon:用户名,自己设置
hadoop98:要拷贝到的目标文件名,注意前面的@是不能丢的。
works:和前面的一样,是目标文件。
ssh免密设置
ssh免密设置的必要性
首先我们在学习的时候,一定是需要他才学,那这里为什么要进行ssh的免密设置呢,还是先回顾一下,上一步的将的rsync。
1、rsync解决了一个什么问题呢?他实现了部份拷贝,只同步修改过的内容,而不是像scp一样全部拷贝,但是它有什么问题呢?
2、如果要用rsync将hadoop100下的一整个works文件拷贝到hadoop98下,这个时候,我们必须到hadoop98下先mkdir建立相应的文件夹,才能使用rsync。
3、这时候如果不想切换主机,就需要用ssh远程登陆,我们只需要在hadoop100下远程登录hadoop98,然后建立相应的works文件夹。但是这时候又有什么问题呢?
4、问题就在于,每次ssh远程登录时候,都需要输入密码,这样就会很烦?那这时候就需要进行ssh免密设置。
ssh免密原理
这里不做很深入的理解,我仅以个人的理解做个简单的记录,ssh首先是分为公钥和私钥,如果我们要实现免密登录,只需要将自己的公钥提供给其他主机就行了。
注意,你有多少台服务器,每一台服务器都要知道其他的服务器的公钥,才可以实现免密登录。
第一步:进入到.ssh目录,这个目录在home目录下,有可能你跳转到home目录下是看不到.ssh目录,但是没关系,你只需要直接跳转就行。

第二步:生成公钥和私钥
ssh-keygen -t rsa
第三步:将公钥拷贝到其他主机上
这里沿用上一个章节中讲到的hadoop100,hadoop99,hadoop98。
从hadoop100中,将公钥拷贝到其他两个主机
ssh-copy-id hadoop98
ssh-copy-id hadoop99
注意:其他的两台服务器上,也需要用同样的办法,拷贝公钥到另外两台服务器。
基本上就实现了ssh的免密登录了。
xsync同步分发脚本
既然ssh免密登录我们都设置好了,那我们就可以通过同一个脚本直接完成到所有服务器的同步拷贝
#! /bin/bash
#1.判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2.遍历集群所有机器
for host in hadoop100 hadoop99 hadoop98
do
echo ======================== $host =============================
#3.遍历所有目录,挨个发送
for file in $@
do
#4.判断文件是否存在
if [ -e $file ]
then
#.获取目录
pdir=$(cd -P $(dirname $file); pwd)
#6.获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
对以上脚本不做过多解释,只是在学shell脚本时,一定要注意空格的使用,不要像c语言或者其他语言一样,总喜欢加空格作为对其,显得代码整洁。shell脚本可不一样,每个空格都是比较严格的。
下一篇则会将,具体hadoop集群的部署。