Open source computer vision project for image captioning
Have you ever hoped for some technology that can add captions to your social media images, because neither you nor your friends can come up with cool captions? Deep learning for image subtitles can help you.
Image captioning is the process of generating text descriptions for images. It is a combined task of computer vision and natural language processing (NLP).

Computer vision methods help to understand and extract features from input images. In addition, NLP converts images into text descriptions in the correct word order.
Here are some useful data sets to help you use image subtitles:
1.COCO Caption
COCO is a large-scale object detection, segmentation and captioning data set. It consists of 3.3 million images (labeled> 200K), with 1.5 million object instances and 80 object categories, and each image has 5 titles.
2.Flicker 8k dataset
It is an image caption corpus consisting of 158,915 crowdsourced captions, describing 31,783 images. This is an extension of the Flickr 8k data set. The new images and titles focus on people who are engaged in daily activities and events.
Open source computer vision project for human pose estimation
Human pose estimation is an interesting application of computer vision. You must have heard of Posenet, which is an open source model for human pose estimation. In short, pose estimation is a computer vision technology that can infer the poses of people or objects in images/videos.
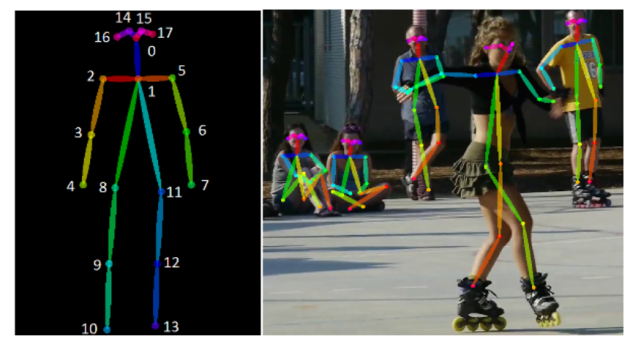
Before discussing the working principle of pose estimation, let us first understand the "human pose skeleton". It is a set of coordinates that define a person's posture. A pair of coordinates are limbs. In addition, pose estimation is performed by identifying, locating and tracking the key points of the human pose skeleton in the image or video.
If you want to develop a pose estimation model, here are some data sets:
1.MPII
The MPII Human Pose dataset is the latest benchmark for evaluating articulated human pose estimation. The data set contains approximately 25K images containing more than 40,000 people with annotated human joints. Overall, the data set covers 410 human activities, and each image has an activity label.
2.HUMANEVA
The HumanEva-I dataset contains 7 calibration video sequences synchronized with 3D human poses. The database contains 4 objects that perform 6 common actions (for example, walking, jogging, gestures, etc.). These actions are divided into training, validation, and test sets.
I found that Google’s DeepPose is a very interesting research paper that uses deep learning models for pose estimation. In addition, you can access multiple research papers on pose estimation to better understand it.
An open source computer vision project for emotion recognition through facial expressions
Facial expressions play a vital role in the process of nonverbal communication and recognition of people. They are very important for recognizing people's emotions. Therefore, information about facial expressions is usually used in automatic systems for emotion recognition.
Emotion recognition is a challenging task because emotions may vary depending on the environment, appearance, culture, and facial reactions, resulting in unclear data.
Facial expression recognition system is a multi-stage process, including facial image processing, feature extraction and classification.
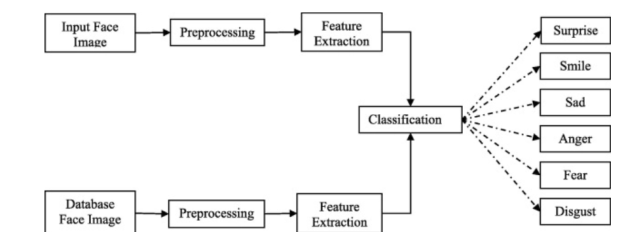
The following is a data set that you can practice:
Real-world Affective Faces Database
Real-world Affective Faces Database (RAF-DB) is a large-scale facial expression database, containing about 30K diverse facial images. It consists of 29672 real-world images and the 7-dimensional expression distribution vector of each image.
Open source computer vision project for semantic segmentation
When we talk about complete scene understanding in computer vision technology, semantic segmentation appears. The task is to classify all pixels in the image into related categories of objects.

Open source computer vision project-semantic segmentation
The following is a list of open source datasets that practice this topic:
1.CamVid
This database is one of the first semantically segmented data sets to be published. This is usually used in (real-time) semantic segmentation research. The data set contains:
367 pairs of training
101 verification pairs
233 test pairs
2.Cityscapes
This dataset is a processed subsample of the original urban landscape. The data set has a still image of the original video, and the semantic segmentation label is displayed in the image next to the original image. This is one of the best datasets for semantic segmentation tasks. It has 2975 training image files and 500 verification image files, each image is 256×512 pixels.
Open source computer vision project for road lane detection of autonomous vehicles
A self-driving car is a vehicle that can sense the environment and operate without human participation. They create and maintain maps of the surrounding environment based on various sensors installed in different parts of the vehicle.

These vehicles have radar sensors that monitor the location of nearby vehicles. Cameras detect traffic lights, read road signs, track other vehicles, and lidar (light detection and ranging) sensors reflect light pulses from around the car to measure distances, detect road edges and identify lane markings.

Lane detection is an important part of these vehicles. In road transportation, the lane is a part of the traffic lane and is designated for one-way vehicles to control and guide the driver and reduce traffic conflicts. Here are some data sets that can be used for experiments:
1.TUsimple
This data set is part of the Tusimple Lane Detection Challenge. It contains 3626 video clips, each of which is 1 second. Each of these video clips contains 20 frames, with an annotated last frame. It contains training and testing data sets, which contain 3626 video clips, 3626 annotated frames in the training data set and 2782 video clips for testing.

In fact, more and more projects based on AI artificial intelligence computer vision have begun to be applied in actual scenarios. For example, the EasyCVR video intelligent analysis platform that supports face recognition and license plate recognition, based on AI intelligent recognition and multi-target tracking technologies, comprehensively processes and analyzes video images from road surveillance cameras, and can perceive a lot of key information.
With the help of deep learning technology, the analysis and judgment of traffic violations can be realized, human faces and vehicles can be recognized, and changes in road traffic flow can be monitored and analyzed in real time, illegal license plate photos, driver fatigue status, etc., AI can be used in traffic scheduling, traffic planning, traffic Play an important role in behavior management and traffic safety prevention scenarios.