DolphinDB is a high-performance distributed time-series database software that supports multi-user and multi-task concurrent operations. Efficient memory management for big data is one of the reasons for its excellent performance. The memory management involved in this tutorial includes the following:
- Variable memory management : Provide and reclaim the memory required by the programming environment for users.
- Cache management of distributed tables : Multiple sessions share partition table data to improve memory usage.
- Streaming data cache : Streaming data sending nodes provide persistence and sending queue cache, and subscribing nodes provide receiving data queue cache.
- DFS database write cache : Data written to DFS is first written to WAL and cache, and throughput is improved by batch writing.
1. Memory Management Mechanism
DolphinDB applies for memory blocks from the operating system and manages it by itself. When the requested memory block is idle, the system will periodically check and release it. At present, the memory allocation of vector, table and all strings has been incorporated into DolphinDB's memory management system.
Set the maximum memory usage of the node through the parameter maxMemSize : This parameter specifies the maximum usable memory of the node. If the setting is too small, it will severely limit the performance of the cluster. If the setting is too large, such as exceeding the physical memory, it may trigger the operating system to forcibly shut down the process. If the machine memory is 16GB and only one node is deployed, it is recommended to set this parameter to about 12GB.
Apply for a memory block from the operating system in 512MB units : When the user queries for operations or program changes to the required memory, DolphinDB will apply for memory from the operating system in 512MB units. If the operating system cannot provide a large block of continuous memory, it will try 256MB, 128MB and other smaller memory blocks.
The system makes full use of available memory to cache database data : When the total memory usage of a node is less than maxMemSize, DolphinDB will cache as much data in the database partition as possible to improve the speed of users accessing the data block next time. When the memory is insufficient, the system will automatically remove part of the cache.
Scanning every 30 seconds, the free memory block is returned to the operating system : when the user releases the variables in the memory, or uses the function clearAllCache to release the cache, if the memory block is completely free, it will be returned to the operating system as a whole. Part of the memory is in use, for example, if 10MB of the 512MB memory block is still in use, it will not be returned to the operating system.
2. Variable memory management
2.1 Create variables
On the DolphinDB node, first create a user user1, and then log in. Create a vector, containing 100 million INT type elements, about 400MB.
Example 1. Create a vector variable
login("admin","123456") //Create user needs to log in admin
createUser("user1","123456")
login("user1","123456")
v = 1..100000000
sum(mem().blockSize -mem().freeSize) //Output memory usage results
The result is: 402,865,056, the memory occupies about 400MB, which is in line with expectations.
Create a table with 10 million rows, 5 columns, 4 bytes per column, about 200MB.
Example 2. Create table variable
n = 10000000 t = table(n:n,["tag1","tag2","tag3","tag4","tag5"],[INT,INT,INT,INT,INT]) (mem().blockSize - mem().freeSize).sum()
结果为:612,530,448,约600MB,符合预期。
2.2 释放变量
可通过undef函数,释放变量的内存。
示例3. 使用undef函数或者赋值为NULL释放变量
undef(`v)
或者
v = NULL
除了手动释放变量,当session关闭时,比如关闭GUI和其他API连接,都会触发对该session的所有内存进行回收。当通过web notebook连接时,10分钟内无操作,系统会关闭session,自动回收内存。
3. 分布式表的缓存管理
DolphinDB对分布式表是以分区为单位管理的。分布式表的缓存是全局共享的,不同的session或读事务在大部分情况下,会看到同一份数据copy(版本可能会有所不同),这样极大的节省了内存的使用。
历史数据库都是以分布式表的形式存在数据库中,用户平时查询操作也往往直接与分布式表交互。分布式表的内存管理有如下特点:
- 内存以分区列为单位进行管理。
- 数据只加载到所在的节点,不会在节点间转移。
- 多个用户访问相同分区时,使用同一份缓存。
- 内存使用不超过maxMemSize情况下,尽量多缓存数据。
- 缓存数据达到maxMemSize时,系统自动回收。
以下多个示例是基于以下集群:部署于2个节点,采用单副本模式。按天分30个区,每个分区1000万行,11列(1列DATE类型,1列INT类型,9列LONG类型),所以每个分区的每列(LONG类型)数据量为1000万行 * 8字节/列 = 80M,每个分区共1000万行 * 80字节/行 = 800M,整个表共3亿行,大小为24GB。
函数clearAllCache()可清空已经缓存的数据,下面的每次测试前,先用该函数清空节点上的所有缓存。
3.1 内存以分区列为单位进行管理
DolphinDB采用列式存储,当用户对分布式表的数据进行查询时,加载数据的原则是,只把用户所要求的分区和列加载到内存中。
示例4. 计算分区2019.01.01最大的tag1的值。该分区储存在node1上,可以在controller上通过函数getClusterChunksStatus()查看分区分布情况,而且由上面可知,每列约80MB。在node1上执行如下代码,并查看内存占用。
select max(tag1) from loadTable(dbName,tableName) where day = 2019.01.01 sum(mem().blockSize - mem().freeSize)
输出结果为84,267,136。我们只查询1个分区的一列数据,所以把该列数据全部加载到内存,其他的列不加载。
示例5. 在node1 上查询 2019.01.01的前100条数据,并观察内存占用。
select top 100 * from loadTable(dbName,tableName) where day = 2019.01.01 sum(mem().blockSize - mem().freeSize)
输出结果为839,255,392。虽然我们只取100条数据,但是DolphinDB加载数据的最小单位是分区列,所以需要加载每个列的全部数据,也就是整个分区的全部数据,约800MB。
注意: 合理分区以避免"out of memory":DolphinDB是以分区为单位管理内存,因此内存的使用量跟分区关系密切。假如用户分区不均匀,导致某个分区数据量超大,甚至机器的全部内存都不足以容纳整个分区,那么当涉及到该分区的查询计算时,系统会抛出"out of memory"的异常。一般原则,如果用户设置maxMemSize=8,则每个分区常用的查询列之和为100-200MB为宜。如果表有10列常用查询字段,每列8字段,则每个分区约100-200万行。
3.2 数据只加载到所在的节点
在数据量大的情况下,节点间转移数据是非常耗时的操作。DolphinDB的数据是分布式存储的,当执行计算任务时,把任务发送到数据所在的节点,而不是把数据转移到计算所在的节点,这样大大降低数据在节点间的转移,提升计算效率。
示例6. 在node1上计算两个分区中tag1的最大值。其中分区2019.01.02数组存储在node1上,分区2019.01.03数据存储在node2上。
select max(tag1) from loadTable(dbName,tableName) where day in [2019.01.02,2019.01.03] sum(mem().blockSize - mem().freeSize)
输出结果为84,284,096。在node2上用查看内存占用结果为84,250,624。每个节点存储的数据都为80M左右,也就是node1上存储了分区2019.01.02的数据,node2上存储了2019.01.03的数据。
示例7. 在node1上查询分区2019.01.02和2019.01.03的所有数据,我们预期node1加载2019.01.02数据,node2加载2019.01.03的数据,都是800M左右,执行如下代码并观察内存。
select top 100 * from loadTable(dbName,tableName) where day in [2019.01.02,2019.01.03] sum(mem().blockSize - mem().freeSize)
node1上输出结果为839,279,968。node2上输出结果为839,246,496。结果符合预期。
注意: 谨慎使用没有过滤条件的"select *",因为这会将所有数据载入内存。在列数很多的时候尤其要注意该点,建议仅加载需要的列。若使用没有过滤条件的"select top 10 *",会将第一个分区的所有数据载入内存。
3.3 多个用户访问相同分区时,使用同一份缓存
DolphinDB支持海量数据的并发查询。为了高效利用内存,对相同分区的数据,内存中只保留同一份副本。
示例8. 打开两个GUI,分别连接node1和node2,查询分区2019.01.01的数据,该分区的数据存储在node1上。
select * from loadTable(dbName,tableName) where date = 2019.01.01 sum(mem().blockSize - mem().freeSize)
上面的代码不管执行几次,node1上内存显示一直是839,101,024,而node2上无内存占用。因为分区数据只存储在node1上,所以node1会加载所有数据,而node2不占用任何内存。
3.4 节点内存占用情况与缓存数据的关系
3.4.1 节点内存使用不超过maxMemSize情况下,尽量多缓存数据
通常情况下,最近访问的数据往往更容易再次被访问,因此DolphinDB在内存允许的情况下(内存占用不超过用户设置的maxMemSize),尽量多缓存数据,来提升后续数据的访问效率。
示例9. 数据节点设置的maxMemSize=8。连续加载9个分区,每个分区约800M,总内存占用约7.2GB,观察内存的变化趋势。
days = chunksOfEightDays();
for(d in days){
select * from loadTable(dbName,tableName) where = day
sum(mem().blockSize - mem().freeSize)
}
内存随着加载分区数的增加变化规律如下图所示:
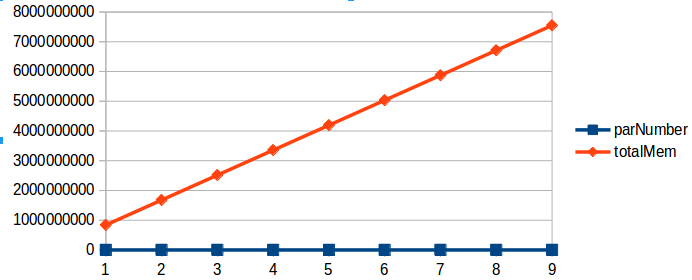
当遍历每个分区数据时,在内存使用量不超过maxMemSize的情况下,分区数据会全部缓存到内存中,以在用户下次访问时,直接从内存中提供数据,而不需要再次从磁盘加载。
3.4.2 节点内存使用达到maxMemSize时,系统自动回收
如果DolphinDB server使用的内存,没有超过用户设置的maxMemSize,则不会回收内存。当总的内存使用达到maxMemSize时,DolphinDB 会采用LRU的内存回收策略, 来腾出足够的内存给用户。
示例10. 上面用例只加载了8天的数据,此时我们继续共遍历15天数据,查看缓存达到maxMemSize时,内存的占用情况。如下图所示:
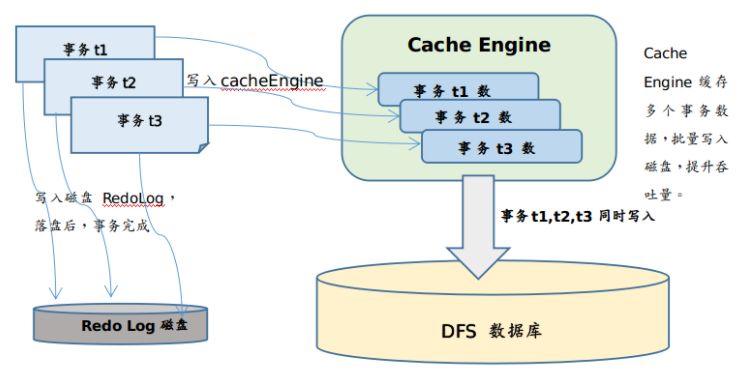
如上图所示,当缓存的数据超过maxMemSize时,系统自动回收内存,总的内存使用量仍然小于用户设置的最大内存量8GB。
示例11. 当缓存数据接近用户设置的maxMemSize时,继续申请Session变量的内存空间,查看系统内存占用。此时先查看系统的内存使用:
sum(mem().blockSize - mem().freeSize)
输出结果为7,550,138,448。内存占用超过7GB,而用户设置的最大内存使用量为8GB,此时我们继续申请4GB空间。
v = 1..1000000000 sum(mem().blockSize - mem().freeSize)
输出结果为8,196,073,856。约为8GB,也就是如果用户定义变量,也会触发缓存数据的内存回收,以保证有足够的内存提供给用户使用。
4. 流数据消息缓存队列
当数据进入流数据系统时,首先写入流表,然后写入持久化队列和发送队列(假设用户设置为异步持久化),持久化队列异步写入磁盘,将发送队列发送到订阅端。
当订阅端收到数据后,先放入接受队列,然后用户定义的handler从接收队列中取数据并处理。如果handler处理缓慢,会导致接收队列有数据堆积,占用内存。如下图所示:
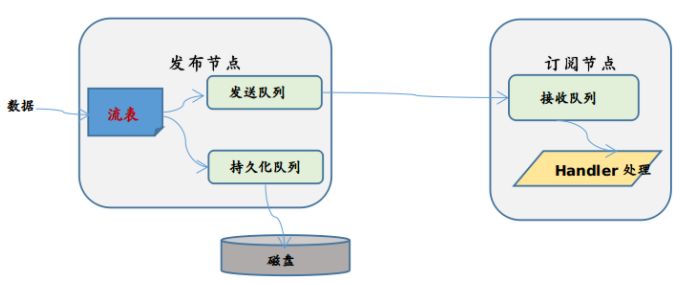
流数据内存相关的配置选项:
- maxPersistenceQueueDepth: 流表持久化队列的最大消息数。对于异步持久化的发布流表,先将数据放到持久化队列中,再异步持久化到磁盘上。该选项默认设置为1000万。在磁盘写入成为瓶颈时,队列会堆积数据。
- maxPubQueueDepthPerSite: 最大消息发布队列深度。针对某个订阅节点,发布节点建立一个消息发布队列,该队列中的消息发送到订阅端。默认值为1000万,当网络出现拥塞时,该发送队列会堆积数据。
- maxSubQueueDepth: 订阅节点上最大的每个订阅线程最大的可接收消息的队列深度。订阅的消息,会先放入订阅消息队列。默认设置为1000万,当handler处理速度较慢,不能及时处理订阅到的消息时,该队列会有数据堆积。
- 流表的capacity:在函数enableTablePersistence()中第四个参数指定,该值表示流表中保存在内存中的最大行数,达到该值时,从内存中删除一半数据。当流数据节点中,流表比较多时,要整体合理设置该值,防止内存不足。
运行过程,可以通过函数getStreamingStat()来查看流表的大小以及各个队列的深度。
5. 为写入DFS数据库提供缓存
DolphinDB为了提高读写的吞吐量和降低读写的延迟,采用先写入WAL和缓存的通用做法,等累积到一定数量时,批量写入。这样减少和磁盘文件的交互次数,提升写入性能,可提升写入速度30%以上。因此,也需要一定的内存空间来临时缓存这些数据,如下图所示:
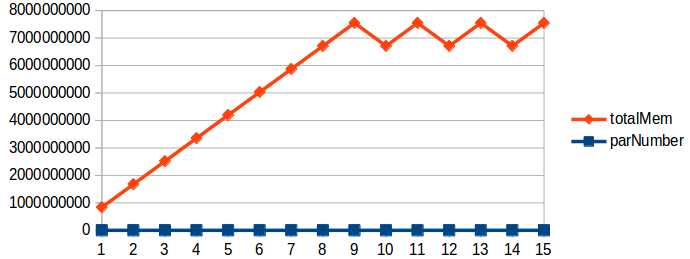
当事务t1,t2,t3都完成时,将三个事务的数据一次性写入到DFS的数据库磁盘上。Cache Engine空间一般推荐为maxMemSize的1/8~1/4,可根据最大内存和写入数据量适当调整。CacheEngine的大小可以通过配置参数chunkCacheEngineMemSize来配置。
- chunkCacheEngineMemSize:指定cache engine的容量。cache engine开启后,写入数据时,系统会先把数据写入缓存,当缓存中的数据量达到chunkCacheEngineMemSize的30%时,才会写入磁盘。
6. 高效使用内存
在企业的生产环境中,DolphinDB往往作为流数据中心以及历史数据仓库,为业务人员提供数据查询和计算。当用户较多时,不当的使用容易造成Server端内存耗尽,抛出"out of memory" 异常。可遵循以下建议,尽量避免内存的不合理使用。
- 合理均匀分区:DolphinDB是以分区为单位加载数据,因此,分区大小对内存影响巨大。合理均匀的分区,不管对内存使用还是对性能而言,都有积极的作用。因此,在创建数据库的时候,根据数据规模,合理规划分区大小。每个分区的常用字段数据量约100MB左右为宜。
- 及时释放数据量较大的变量:若用户创建数据量较大的变量,例如v = 1..10000000,或者将含有大量数据的查询结果赋值给一个变量t = select * from t where date = 2010.01.01,v和t将会在用户的session占用大量的内存。如果不及时释放,当其他用户申请内存时,就有可能因为内存不足而抛出异常。
- 只查询需要的列:避免使用select *,如果用select *会把该分区所有列加载到内存。实际中,往往只需要几列。因此为避免内存浪费,尽量明确写出所有查询的列,而不是用*代替。
- 数据查询尽可能使用分区过滤条件:DolphinDB按照分区进行数据检索,如果不加分区过滤条件,则会全部扫描所有数据,数据量大时,内存很快被耗尽。有多个过滤条件的话,要优先写分区的过滤条件。
- 尽快释放不再需要的变量或者session:根据以上分析可知,用户的私有变量在创建的session里面保存。session关闭的时候,会回收这些内存。因此,尽早使用undef函数或者关闭session来释放内存。
- 合理配置流数据的缓存区:一般情况下流数据的容量(capacity)会直接影响发布节点的内存占用。比如,capacity设置1000万条,那么流数据表在超过1000万条时,会回收约一半的内存占用,也就是内存中会保留500万条左右。因此,应根据发布节点的最大内存,合理设计流表的capacity。尤其是在多张发布表的情况,更需要谨慎设计。
7. 内存监控及常见问题
7.1 内存监控
7.1.1 controller上监控集群中节点内存占用
在controller上提供函数getClusterPerf()函数,显示集群中各个节点的内存占用情况。包括:
MemAlloc:节点上分配的总内存,近似于向操作系统申请的内存总和。
MemUsed:节点已经使用的内存。该内存包括变量、分布式表缓存以及各种缓存队列等。
MemLimit:节点可使用的最大内存限制,即用户配置的maxMemSize。
7.1.2 mem()函数监控某个节点内存占用
mem()函数可以显示整个节点的内存分配和占用情况。该函数输出4列,其中列blockSize表示分配的内存块大小,freeSize表示剩余的内存块大小,通过sum(mem().blockSize - mem().freeSize) 得到节点所使用的总的内存大小。
7.1.3 监控节点上不同session的内存占用
可通过函数getSessionMemoryStat()查看节点上每个session占用的内存量,该内存只包含session内定义的变量。当节点上内存占用太高时,可以通过该函数排查哪个用户使用了大量的内存。
7.1.4 查看某个对象占用的内存大小
通过函数memSize来查看某个对象占用内存的具体大小,单位为字节。比如:
v=1..1000000 memSize(v)
输出:4000000。
7.2 常见问题
7.2.1 监控显示节点内存占用太高
通过上面的分析可知,DolphinDB会在内存允许的情况下,会尽可能多的缓存数据。因此,如果只显示节点内存占用太高,接近maxMemSize,而没有其他内存相关的错误,那么这种情况是正常的。 如果出现"out of memory"等类似的错误,首先可以通过函数getSessionMemoryStat()查看各个session占用的内存大小,其次通过函数clearAllCache()来手动释放节点的缓存数据。
7.2.2 MemAlloc显示值跟操作系统实际显示值有差异
DolphinDB是C++程序,本身需要一些基础的数据结构和内存开销,MemAlloc显示内存不包括这些内存,如果两者显示相差不大,几百MB以内,都属于正常现象。
7.2.3 查询时,报告"out of memory"
该异常往往是由于query所需的内存大于系统可提供的内存导致的。可能由以下原因导致:
- 查询没有加分区过滤条件或者条件太宽,导致单个query涉及的数据量太大。
- 分区不均匀。可能某个分区过大,该分区的数据超过节点配置的最大内存。
- 某个session持有大的变量,导致节点可用的内存很小。
7.2.4 查询时,DolphinDB进程退出,没有coredump产生
这种情况往往是由于给节点分配的内存超过系统物理内存的限制,操作系统把DolphinDB强制退出。Linux上可以通过操作系统的日志查看原因。
7.2.5 执行clearAllCache()函数后,MemUsed没有明显降低
可以通过getSessionMemoryStst()查看各个session占用的内存大小。可能是由于某个session持有占用大量内存的变量不释放,导致该部分内存一直不能回收。