Preface
Before I was busy with my graduation thesis, it happened that ALBERT had just come out, and I was thinking about talking about this article, but I was really lazy and it was not easy to graduate. Recently, everything has come to an end, and I have entered the state of graduation from the Buddhist department, doing my best, knowing the fate of heaven.
This article describes the modules according to the order of the paper itself, discusses some details, and finally puts forward some opinions on the effect of the model.
One thing to note is: ALBERT reduces the amount of model parameters and thus reduces the training time of the model (reduced communication overhead), but the predictive reasoning time of the model does not decrease. This point needs to be kept in mind and used throughout the text.
The purpose of ALBERT
As mentioned at the beginning of the paper, in the field of pre-training language models, increasing the model can often achieve good results, but is this improvement endless? A detailed experiment was conducted in [2], which answered this question to a considerable extent. First bury a pit here, and then fill it in a few days.
The pre-training language model is already very large, and most laboratories and companies are not eligible to participate in this game. For large models, a very shallow idea is: how to compress the large models? The essence of ALBERT is the product of compression of the BERT model.
If you have a good understanding of model compression, you must know that there are many methods for model compression, including pruning, parameter sharing, low-rank decomposition, network structure design, knowledge distillation, etc. (this is another pit, bury it first). ALBERT also failed to escape this framework. It is actually a fairly engineering idea. Its two major compression tricks are also easy to think of. Let's talk about it in detail below.
Three major innovations
1. Factorized embedding parameterization
The Trick is essentially a low-rank decomposition operation, which achieves the effect of reducing the parameters by reducing the dimensionality of the Embedding part. In the original BERT, taking Base as an example, the dimensions of the Embedding layer and the hidden layer are both 768, but we know that for the distributed representation of words, such a high dimension is often not needed, such as in the Word2Vec era. Use 50 or 300 dimensions more often. Then a very simple idea is to reduce the amount of parameters by decomposing the Embedding part, which is expressed by the formula as follows:

V: vocabulary size; H: hidden layer dimension; E: word vector dimension
Let's take BERT-Base as an example. The Hidden size in Base is 768 and the vocabulary size is 3w. At this time, the parameter amount is: 768 * 3w = 23040000. If the dimension of Embedding is changed to 128, then the parameter quantity of the Embedding layer at this time is: 128 * 3w + 128 * 768 = 3938304. The difference between the two is 19101696, which is approximately 19M. We see that in fact, the Embedding parameter has changed from the original 23M to the current 4M. It seems that the change is particularly large. However, when we look at the overall situation, the parameter of BERT-Base is 110M, and reducing 19M can not produce any revolutionary The change. Therefore, it can be said that the factorization of the Embedding layer is not actually the main means to reduce the amount of parameters.
Note that I have deliberately ignored the part of the parameter of Position Embedding, mainly considering that 512 is a bit insignificant compared to 3W.
In 4.4, the choice of word vector dimensions is discussed in detail:
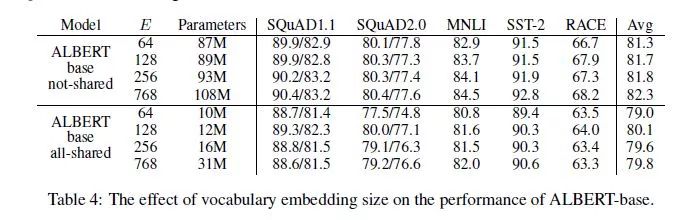
From the above figure, we can see that the benefits of increasing the dimension of the word vector are very small after 128, which also echoes the above point.
2. Cross-layer parameter sharing
该Trick本质上就是对参数共享机制在Transformer内的探讨。在Transfor中有两大主要的组件:FFN与多头注意力机制。ALBERT主要是对这两大组件的共享机制进行探讨。
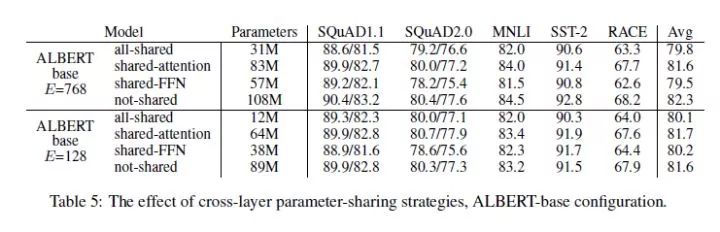
论文里采用了四种方式: all-shared,shared-attention,shared-FFN以及 not-shared。我们首选关注一下参数量,not-shared与all-shared的参数量相差极为明显,因此可以得出共享机制才是参数量大幅减少的根本原因。然后,我们看到,只共享Attention参数能够获得参数量与性能的权衡。最后,很明显的就是,随着层数的加深,基于共享机制的 ALBERT 参数量与BERT参数量相比下降的更加明显。
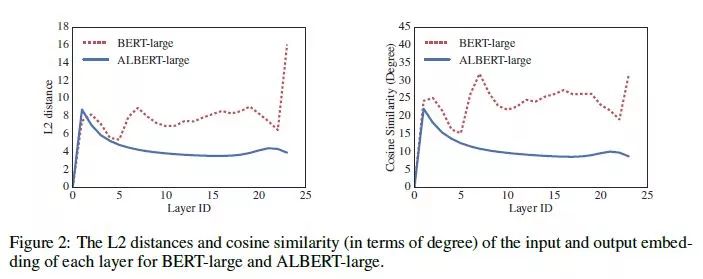
此外,文章还说道,通过共享机制,能够帮助模型稳定网络的参数。这点是通过L2距离与 cosine similarity 得出的,俺也不太懂,感兴趣的可以找其他文章看看:
3. SOP 替代 NSP
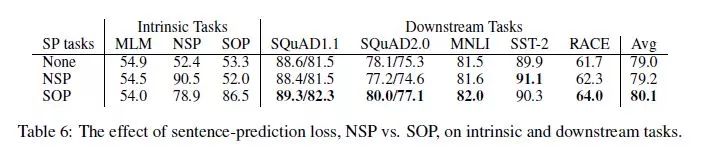
SOP 全称为 Sentence Order Prediction,其用来取代 NSP 在 BERT 中的作用,毕竟一些实验表示NSP非但没有作用,反而会对模型带来一些损害。SOP的方式与NSP相似,其也是判断第二句话是不是第一句话的下一句,但对于负例来说,SOP并不从不相关的句子中生成,而是将原来连续的两句话翻转形成负例。
很明显的就可以看出,SOP的设计明显比NSP更加巧妙,毕竟NSP任务的确比较简单,不相关句子的学习不要太容易了。论文也比较了二者:
BERT vs ALBERT
1. 从参数量级上看
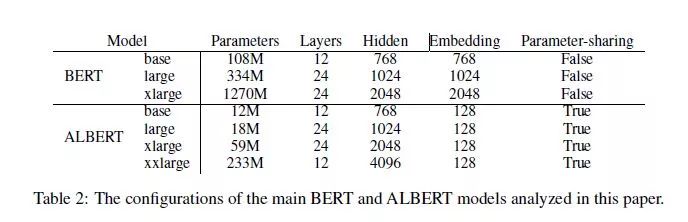
首先,参数量级上的对比如上表所示,十分明显。这里需要提到的是ALBERT-xxlarge,它只有12层,但是隐层维度高达4096,这是考虑到深层网络的计算量问题,其本质上是一个浅而宽的网络。
2. 从模型表现上看
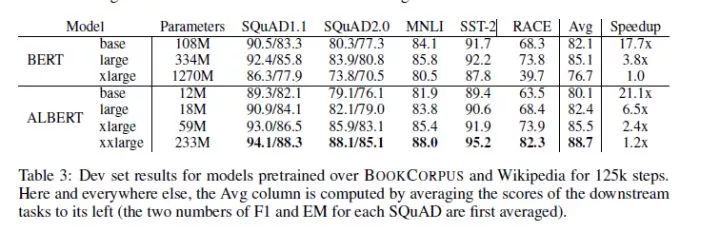
首先,我们看到 ALBERT-xxlarge的表现完全超过了BERT-large的表现,但是BERT-large的速度是要比ALBERT-xxlarge快3倍左右的。
其次,BERT-xlarge的表现反而变差,这点在[2]中有详细探讨,先略过不表。
Tricks
其实,最近很多预训练语言模型文章中都相当程度上提到了调参以及数据处理等Trick的重要性,可惜我等没有资源去训,本来想在结尾将本文的Trick都提一下,但由于无法形成对比,因此作罢。等过段时间将各大预训练语言模型中的Trick‘汇总一下再说吧。
最后
其实,从模型创新的角度来看,ALBERT其实并没有什么很大的创新,如果是一个轻量级的任务,相信这种模型压缩的方式早就做烂了。可惜的是,计算资源限制了绝大多数的实验室和公司,只能看头部公司笑傲风云。
此外,这篇文章本质上就是一个工程性质的文章,我觉得其中的一些Trick都十分的有借鉴意义,等我有时间再搞搞吧。
觉得写的还行的,点赞呀,老铁
Reference
如何看待瘦身成功版BERT——ALBERT?
[1] ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
[2] T5 - Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
本文由作者授权AINLP原创发布于公众号平台,点击'阅读原文'直达原文链接,欢迎投稿,AI、NLP均可。
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。
