background
In the previous article, I translated the first three chapters of the official cuda10.0 document, this time I will translate the fourth chapter-hardware implementation
The NVIDIA GPU architecture is compiled by a variable array composed of multi-threaded streaming multiprocessors (SM). When a cuda program on a host CPU calls a core grid, the thread blocks in the grid will be enumerated. And is distributed to multi-processors with appropriate execution capabilities. Threads in a thread block execute concurrently on one processor, and multiple thread blocks can also execute concurrently on one processor. When the thread block ends, the new block is started on the freed processor. Multiprocessors are designed to execute hundreds of threads concurrently. In order to manage so many threads, it uses a separate architecture called SIMT (Single Instruction Multithreading). Instructions are scheduled by using instruction-level parallelism within threads and thread-level parallelism through hardware multithreading. Unlike CPU cores that are scheduled in order, there is no branch prediction and speculative execution in GPU multiprocessors. In addition, the NVIDIA GPU architecture uses little-endian notation. Next, we explain the architectural features and streaming multiprocessors common to all devices.
SIMT architecture
Multiprocessors create, manage, schedule, and execute threads in the form of pseudo-threads, which are a set of 32 parallel threads. The independent threads that make up the pseudo thread start at the same address in the program, but they have their own instruction address counters and register states, so they can branch freely and execute independently. Pseudo-threads originating from waves belong to the first parallel thread technology. Semi-pseudo-threads are the first or second part of the pseudo-threads, and the quarter-pseudo-threads are part of the pseudo-threads.
When the multiprocessor has one or more thread blocks to be executed, it partitions the thread blocks into pseudo threads, and each pseudo thread is scheduled for execution by the pseudo thread scheduler. The method of dividing a thread block into pseudo-threads is always the same: each pseudo-thread contains a continuously increasing thread id, and the first pseudo-thread will contain a thread with a thread id of 0. The thread level section in Chapter 2 describes the relationship between thread id and thread index in the block (thread index and block index can be used to calculate thread id)
A pseudo thread executes an instruction at the same time, so when all 32 threads in the thread block have no objection to their own execution logic, the efficiency is full. If some of the pseudo-threads find another way because of the conditional branch that the data depends on, the pseudo-thread will also execute each conditional branch, but the threads that are not on this branch will not be executed. Branch dispersion only occurs in pseudo-threads, and different pseudo-threads will execute in parallel regardless of whether they are executing the same code path.
The SIMT architecture is similar to the SIMD (Single Instruction Multiple Data) vector architecture, in which one instruction controls multiple elements to be processed. The key difference between the two architectures is that the SIMD vector architecture exposes the SIMD width to the software, while the SIMT instruction specifies the execution and branch behavior in a single thread. In contrast to the SIMD vector machine, SIMT allows programmers to write thread-level parallel code for independent and variable threads, as well as data parallel code for cooperating threads. In order to consider correctness, programmers can basically ignore the behavior of SIMT, but beware that the code rarely requires thread dispersion in pseudo-threads. Paying attention to this can improve the performance of the program. In practice, this is similar to the role of cache lines in traditional code: when correctness is considered, the size of the cache line can be safely ignored, but if excellent performance is required, then the size of the cache line must be considered in the code structure . On the other hand, the vector architecture requires software to merge loads into vectors, and then manually manage branching.
Before the Volta architecture, the pseudo thread used the program counter shared by 32 threads and the active mask of the specified active thread. As a result, threads in different regions or different execution states in the same pseudo thread could not send signals or exchange data with each other, requiring lock control The algorithm for fine-grained data sharing is prone to deadlock, which depends on which pseudo thread the competing thread comes from.
Starting from the Volta architecture, independent thread scheduling allows complete concurrency between threads, regardless of whether they come from the same pseudo thread. At this time, the GPU holds the running state of each thread, including the program counter and call stack, so it can be parallelized at the thread granularity, which not only makes better use of execution resources, but also allows threads to wait for data produced by other threads. The scheduling optimizer decides how to group active threads from the same pseudo thread into a SIMT unit, which not only retains the high throughput of SIMT scheduling in the past NVIDIA GPU, but also improves flexibility: threads can be smaller than pseudo threads Disperse and re-converge under the particle size.
If developers have to make pseudo-thread synchronization assumptions in the previous hardware architecture, independent thread scheduling may result in a different set of threads participating in the execution of code than expected. Specifically, any pseudo-thread synchronization code (such as synchronization release, pseudo-thread merge, etc.) should be reviewed to ensure compatibility in Volta and higher architectures.
Note: The
thread that participates in the execution of the current instruction in a pseudo thread is called the active thread, and the thread that does not participate in the execution is the inactive thread. There are many factors for thread inactivity, including ending earlier than other threads in the pseudo-thread, being on a different code path from the branch being executed by the pseudo-thread, or being the last in the thread block whose number of threads is not divisible by the capacity of the pseudo-thread One thread.
If a non-atomic operation performed by multiple threads in a pseudo thread writes to the same address in global or shared memory, the serial write at that address depends on the computing power of the device and which thread executes The last time it was written is uncertain.
If an atomic operation performed by multiple threads in a pseudo-thread reads, writes, and modifies an address in global memory, each read, write or modify will occur, and it will be executed serially, but the order in which they occur is unknown .
Hardware multithreading
The pseudo-thread execution environment (program counter, register, etc., each pseudo-thread has) processed by the multiprocessor is on-chip maintained during the entire life cycle of the pseudo-thread. Therefore, there is no overhead to switch from one execution context to another. When each instruction is initiated, the pseudo-thread scheduler will select the pseudo-thread whose thread is ready to execute the next instruction (see the record of active threads in the previous section) To allocate instructions.
Specifically, each multiprocessor has a set of 32-bit registers partitioned between pseudo-threads, and parallel data cache or shared memory partitioned between thread blocks
For a kernel function to be executed, the number of thread blocks and pseudo-threads that can coexist and process simultaneously on a multiprocessor depends on the number of registers and shared memory available on the processor and the number of registers required by the kernel function And the number of shared memory. Further, the number of threads in the thread and pseudo-blocks per multiprocessor coexisting have a maximum limit, which limits available multi-processor registers and shared memory is the function of the device computing capability, to the following table:
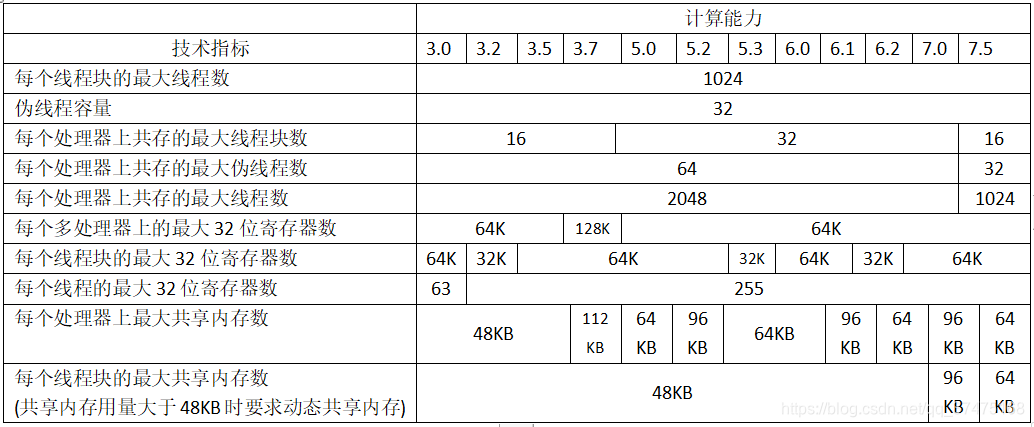
If If each multiprocessor does not have enough registers or shared memory to process at least one thread block, the kernel function will fail to start.
The number of pseudo threads in a thread block = ceil(T / Wsize, 1), where T is the number of threads in each thread block, Wsize is the pseudo thread capacity (32), and ceil(x, y) will round x to The nearest integer multiple of y, and then return x.
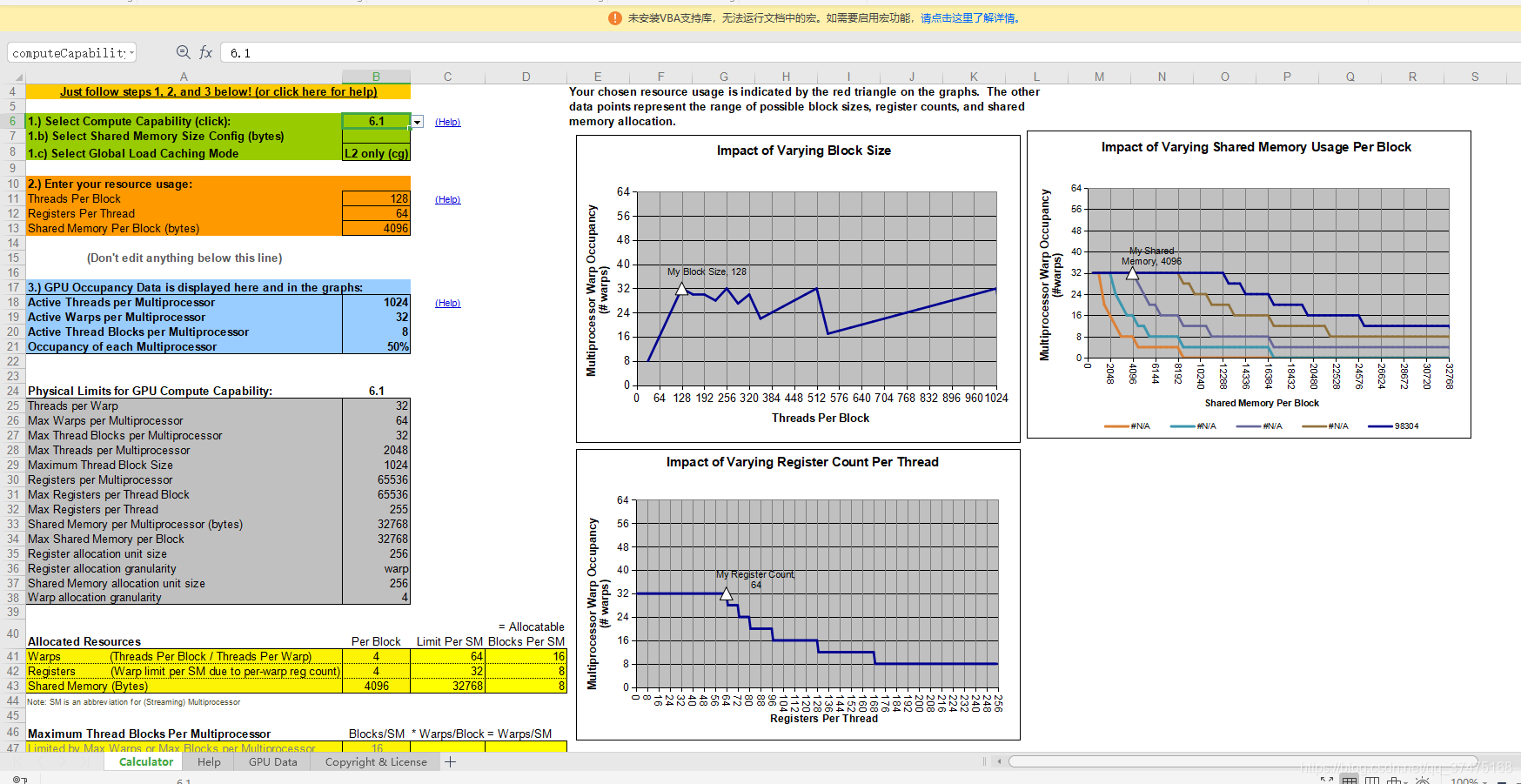
The total number of registers in a thread block and the number of shared memory allocated to this thread block can refer to the CUDA Occupancy Calculator
in the cuda toolkit. It is located in the tools directory of the cuda installation directory. The

content after opening is shown

in the following figure. Under the Calculator tab, select yourself The computing power of the device, you can see some detailed information
Conclusion
The fourth chapter is finished, and the fifth chapter-performance guide will be translated next week.