MySQL has proactively introduced the master-slave replication (replication) feature in its version 3.23, about 20 years ago. It is this move that makes MySQL catch up with the development trend of the Internet 1.0 era. The use of replication features can easily achieve the expansion of the database architecture and read-write separation functions to increase the capacity of the architecture.
I think from this perspective, replication is the most important feature of MySQL is not an exaggeration.
Anyone familiar with MySQL knows that MySQL's replication technology is one of its core technologies and the basis for the flexible use of MySQL. Starting from version 3.23, MySQL introduced the asynchronous replication function, and then continued to evolve, introducing semi-synchronous replication, lossless semi-synchronous replication, and the latest group replication function. The basic principle is almost the same-the use of binary log file propagation and data playback between database servers to achieve data synchronization between multiple database servers. A qualified MySQL practitioner must master the basic knowledge of replication technology, be familiar with various solutions of replication technology, and use them flexibly to meet various needs in the production system.

MySQL can become "the most popular open source database", and its replication technology has played a huge role. Sharing Nothing architecture, horizontal expansion, high availability, disaster tolerance, data integration and aggregation, the architecture and application scenarios represented by this series of terms are all related to replication technology. Multiple application scenarios mean that the technology related to replication is flexible and complex: asynchronous replication, enhanced semi-synchronous replication, statement-level replication, row-level replication, site-by-site replication, GTID replication, multi-source replication, cascaded replication, multi-threaded replication, Dual-master architecture, one-master multiple-slave architecture, delayed replication, separation of reads and writes, etc. Different business scenarios, using different replication architectures, how to correctly construct the MySQL replication topology, how to effectively monitor and correctly maintain these are the problems that architects and DBAs have to solve.
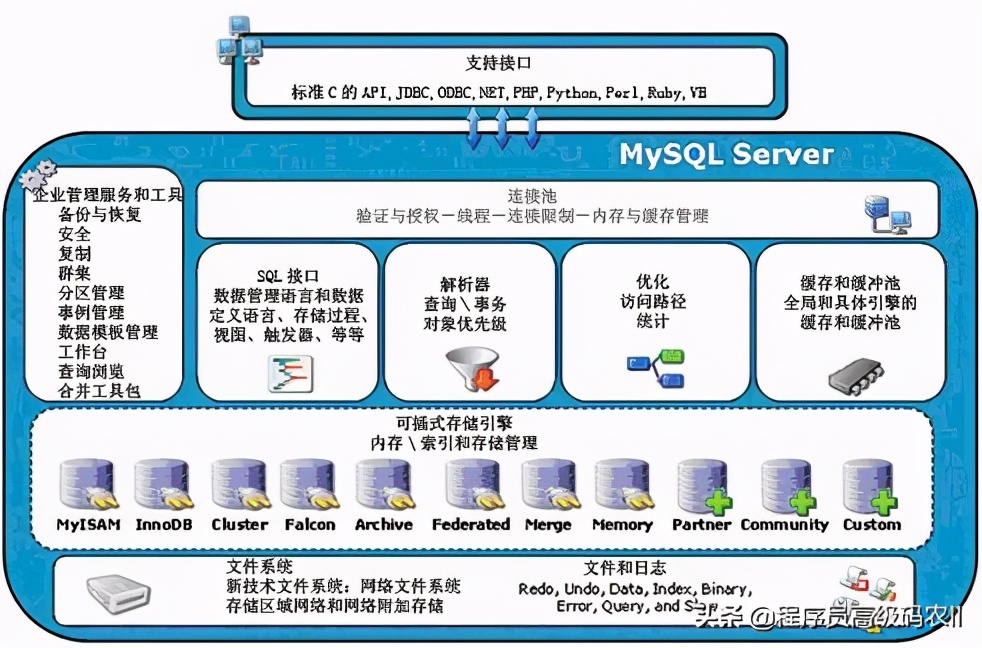
As the country strengthens its requirements for the security and control of database technology, the use of open source MySQL databases has become a trend. Open source represents code security and database controllability. Various industries continue to promote the deployment of MySQL, and MySQL practitioners have also spread from the Internet industry to traditional industries. The use of replication technology can achieve MySQL's high availability and high scalability, which is a necessary technology to ensure MySQL data security and database expansion. Security and control are essential to traditional industries, so I strongly recommend MySQL practitioners, especially DBAs in traditional industries, to read this article.
table of Contents

main content
The full text is divided into 3 chapters: basic chapter, plan chapter and reference chapter, with a total of 38 chapters.
In accordance with the logical sequence of "Basic Principles"→"Production Practice"→"More References", the article is equipped with a large number of schematic diagrams of the principles and schemes, and strives to use easy-to-understand language, intuitive diagrams, and complete knowledge to cover all aspects. MySQL replication technology is explained thoroughly.
Among them, the basic chapter focuses on the principle of master-slave replication and the evolution of replication technology, the solution chapter focuses on the application of master-slave replication technology in the production environment, and the reference chapter focuses on the basic composition of binary logs and common object replication in master-slave replication. Security, etc.
This article is suitable for beginners, intermediate and advanced MySQL DBAs, database architects and related developers to read.
Basics
Chapter 1 Overview of replication ; in simple terms, "replication" is to transfer data changes from a MySQL Server (here, the master role, that is, the main database) to one or more other through its logical binary log (binlog) In a MySQL Server (here refers to the slave role, that is, from the library), other MySQL Servers complete data synchronization by applying (playing back) these logical binary logs. The logical relationship between these MySQL Servers is called "replication topology" (or "replication architecture").
By default, replication is asynchronous, that is, after the master library transmits the binary log to the slave library, it does not care whether the slave library successfully receives it. Whether the slave library receives these binary logs does not affect any read/write access of the main library; and the replication thread of the slave library can also be suspended or stopped at will without affecting the read/write access of the main library. Generally, the asynchronous mode can give full play to the highest performance of the database, but the data security is not well guaranteed. If the data security requirements are high, you can consider using semi-synchronous replication.
In addition, by default, the copied data is for the entire instance (excluding some system tables). You can choose whether you need to copy the data of the entire instance according to your own needs, whether to copy only certain libraries or only certain tables. Wait. Next, we will briefly introduce some applicable scenarios of replication topology in MySQL, as well as concepts related to replication.

Chapter 2 The basic principles of replication; Chapter 1 briefly introduces the basic concepts related to MySQL replication (technology), and this chapter will introduce the basic principles in detail. Since the birth of MySQL's replication technology, as the requirements of various application scenarios for data security and replication performance continue to increase, it is also constantly iterating and optimizing. To deeply understand MySQL's replication technology, it is necessary to start with its basic principles, which will be introduced below.
Chapter 3 is a detailed explanation of the replication format; through the previous two chapters, we understand the usage scenarios of the replication technology and its basic principles and implementation, knowing that replication is achieved through the circulation of binary log records between the master and slave libraries. Chapter 1 gives a brief introduction to the record format of the binary log. This chapter will elaborate on the copy format.
Chapter 4 Traditional Replication and GTID Replication; MySQL versions prior to 5.6 only support traditional replication, that is, "replication based on the binary log file (binlog file) and location (binlog pos)". In this replication mode, operations such as initial configuration and change of replication topology, and high-availability switching of replication need to find the correct binary log file and location, otherwise it will not be able to replicate correctly. However, the operation steps involved in the process of finding the location information are more cumbersome, so in MySQL 5.6 and later versions, GTID-based replication (for convenience of presentation, this text is also referred to as GTID replication) mode appears. It uses the feature of GTID automatic positioning, no longer needs the location information of the binary log, and eliminates the cumbersome steps required to find this information, which greatly simplifies the initial configuration and changes of the replication topology, and the high availability switching of replication, etc. operating. This chapter will give a basic introduction to these two replication modes.
Chapter 5 Semi-Synchronous Replication; In addition to the built-in asynchronous replication, MySQL 5.7 also supports the implementation of semi-synchronous replication interfaces through plug-ins. Compared with the semi-synchronous replication in MySQL 5.5 and MySQL 5.6, we usually refer to the semi-synchronous replication in MySQL 5.7 as "enhanced semi-synchronous replication", also known as "lossless replication" (MySQL 5.5 and MySQL 5.6 also support semi-synchronous replication. Copy, but "lossless copy" is not guaranteed. For details, see section 5.4 "Notes on Semi-Synchronous Copy"). This chapter will introduce in detail the semi-synchronous replication in MySQL 5.7.

Chapter 6 Multithreaded Replication; MySQL versions prior to 5.6 do not support parallel replay of the binary log of the master library from the slave library, so once the write pressure of the master library is slightly greater, the slave library is prone to delays. Of course, the latest MySQL version has been able to support multi-threaded replication well. In order to understand how replication evolves step by step into multi-threaded replication, this chapter will start with single-threaded replication. Before you start learning the contents of this chapter, you may need to review the basic principles of replication, see Chapter 2 "Basic Principles of Replication" for details.

Chapter 7 Multi-source replication: After some business data is scattered to multiple database instances, database backup and recovery are more cumbersome. Is there any simple solution to this problem? MySQL 5.7.6 introduces the concept of replication channels, so that the same slave library can receive data from multiple master libraries at the same time, and a replication channel logically corresponds to a master library. This chapter will briefly introduce how to use channels, channel-related concepts in replication topology, and the impact of related system settings on single-source (single replication channel) replication.

Chapter 8 Slave library relay log and status log; the binary log read from the main library by the library I/O thread needs to be temporarily stored in the disk file of the slave library. This disk file is the relay log. The I/O thread is not responsible for parsing and replaying the binary log, but the SQL thread is responsible. When the copy thread is running normally, we are not very sensitive to the working position of the copy thread (here refers to the position where the I/O thread reads the binary log of the main library and the position where the SQL thread replays), but when the database process of the slave Or when the host crashes, after restarting from the library, you need to know the correct position of the last copy thread, that is to say, the working position of the copy thread needs to be persisted, otherwise once it is lost, you will not be able to know the last copy. Where is it? The status log is used to persist the working position of the replication thread (the status log includes relay loginfo and master info. The specific purpose is detailed below). This chapter will introduce the relay log and status log in detail.

Chapter 9 checks the replication information through the PERFORMANCE_SCHEMA library; usually, we habitually use the SHOW SLAVE STATUS statement when viewing status information related to replication. Maybe you will say, "I will also use the table in the PERFORMANCE_SCHEMA library to view some error messages when copying", but you know the similarities and differences between the information output by the SHOW SLAVE STATUS statement and the copy information record table in the PERFORMANCE_ SCHEMA library ? This chapter will introduce the similarities and differences between the two in detail.

Chapter 10 checks the replication information by other means ; Chapter 8 details how to check the replication information through the mysql.slave_master_info and mysql.slave_relay_log_info tables, and Chapter 9 details how to check the replication information through the replication record table under the PERFORMANCE_SCHEMA library , This chapter will supplement the small details related to copying that are not mentioned in the previous chapters. For example, use the SHOW PROCESSLIST statement to view the status information of the I/O thread and SQL thread, and use the user_variables_by_thread table in the PERFORMANCE_SCHEMA library to view the custom variable information registered by the I/O thread to the main library.

Chapter 11: How MySQL Replication Delay Seconds_Behind_Master is calculated; in a master-slave replication topology, monitoring replication delay is an indispensable work. If the application scenario is not sensitive to the replication delay, it is sufficient to monitor the replication delay by collecting the value of the Seconds_Behind_Master field in the output information of the SHOW SLAVESTATUS statement most of the time. I believe people with MySQL experience are not unfamiliar with this method. We all know that the value of Seconds_Behind_Master is not so reliable in some scenarios, and we know more or less some methods to calculate this value. But are these calculation methods really correct? Next, this chapter will discuss this and confirm the correct calculation method.

Chapter 12 How to ensure the safe recovery of the slave library after an accidental suspension; in order to ensure that the copy thread can correctly restore to the state before the suspension (sometimes called crash-safe) after the accidental suspension of the slave library, some systems in the slave library are required Set appropriate values for variables and copy options. This chapter will introduce in detail how to set these system variables and copy options and their corresponding different effects.
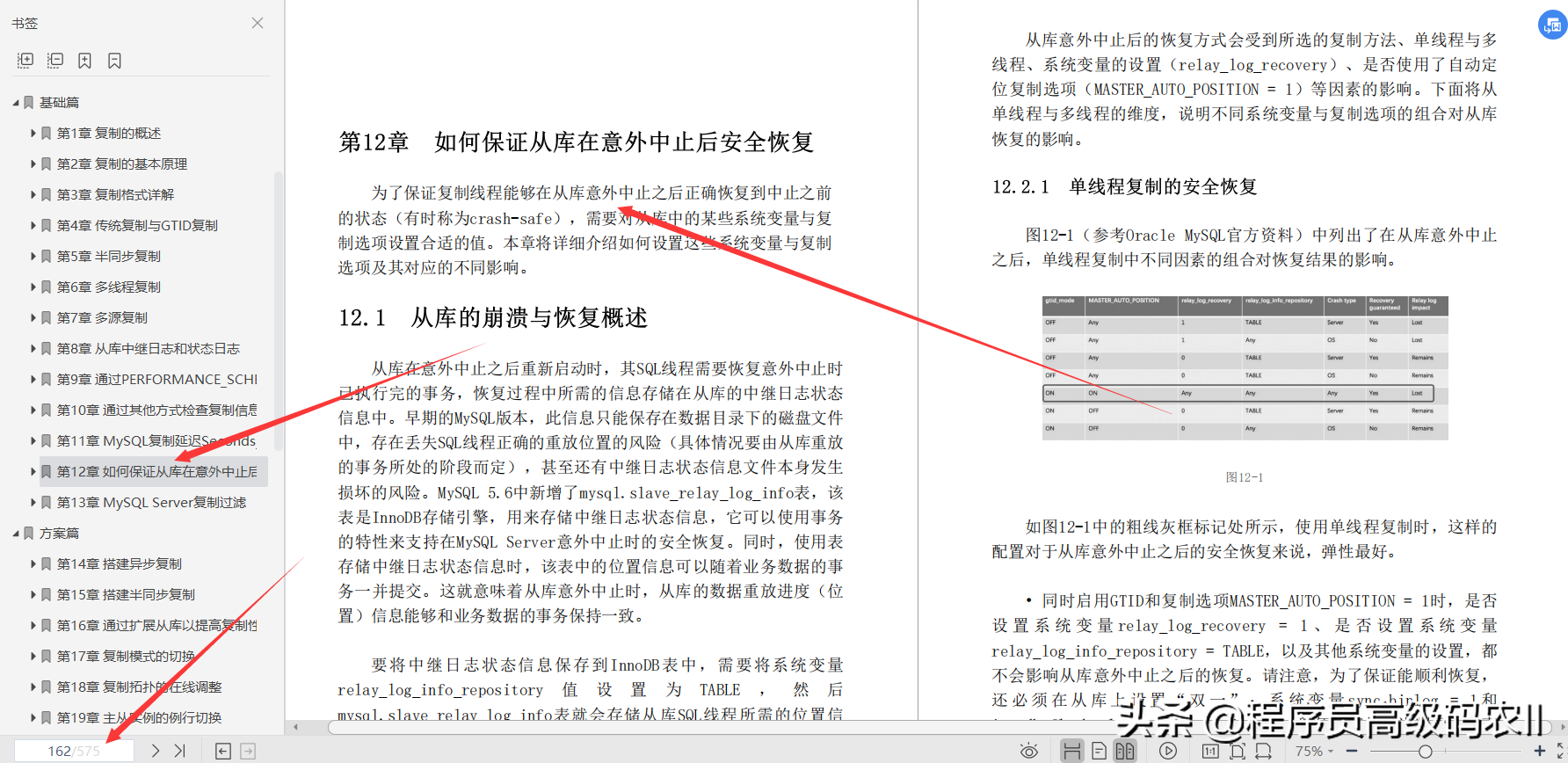
Chapter 13 MySQL Server Replication Filtering; Although the MySQL Server replication filtering function is generally not recommended in a standard production environment (because if used improperly, it may cause a variety of inconsistent master-slave database data problems), but in In some cases, in order to distinguish business data or ensure data security (for example, all write operations to business data are uniformly written to the main library, but the reading of business data needs to be divided according to business modules, because different business systems There is a need for data security isolation), the replication filtering function of MySQL Server may be a simple and fast implementation solution. With sufficient understanding and careful planning to avoid its shortcomings, it can also be listed as one of the options that can solve such needs. This chapter will briefly review the implementation logic of the MySQL Server replication filtering function.
Program articles
Chapter 14 Setting Up Asynchronous Replication; Asynchronous replication is relative to synchronous replication and semi-synchronous replication. For the difference between the three, please refer to Chapter 1 "Overview of Replication" and Chapter 5 "Semi-Synchronous Replication". Compared with the other two types of replication, asynchronous replication is the fastest, and the performance of the master database is not affected by the performance of the slave database. It is also the earliest replication technology in MySQL. Before MySQL 5.6, whether it was synchronous, semi-synchronous, or asynchronous replication, it was traditional replication (based on binary log files and location), and it was troublesome to maintain the replication topology. MySQL 5.6 and later versions support GTID replication mode, making the maintenance of the replication topology very convenient and fast. This chapter will introduce in detail the process of setting up asynchronous replication under the two replication modes of traditional replication and GTID replication. For the principles of traditional replication and GTID replication, please refer to Chapter 4.
Chapter 15 Setting up semi-synchronous replication; this chapter will introduce the semi-synchronous replication solution with the most cost-effective, simplest implementation, and the easiest to install and deploy.
Chapter 16 Improve the replication performance by extending the slave library; in most OLTP or OLAP business systems, the operation of the database usually reads more and writes less (except for special scenarios. For example, data collection, data recovery, etc., write more and read less Scenario). Therefore, with the growth of the business, the database instances in the original replication topology are gradually unable to support read access traffic (assuming that the master database in the replication topology provides write services and all slave libraries provide read services). There is an urgent need to improve the database Read access capability. Then, we need a convenient, fast, and light-weight read access capability expansion solution. This chapter takes horizontal expansion as an example to introduce the implementation process of the entire program.
Chapter 17 Replication Mode Switching; MySQL 5.5 and earlier versions do not support GTID mechanism, so they use traditional replication (ie, replication based on binary log files and locations). The GTID mechanism is introduced in MySQL 5.6. This mechanism has many advantages (for details, please refer to Chapter 4, Chapter 12 and other chapters, as well as the replication mode switching process that will be demonstrated below, which will not be introduced here). It is for the MySQL administrator Maintenance work has brought great convenience, so most users will choose to switch to GTID replication mode (that is, GTID-based replication, hereinafter collectively referred to as "GTID replication"). Except for some special application scenarios, it is rarely necessary to switch from GTID replication to traditional replication.
In Chapter 1, we referred to traditional replication and GTID replication as "data synchronization methods", but generally we prefer to refer to them as "replication modes". This chapter will give a detailed introduction to some concepts in these two replication modes and their mutual switching process.
Chapter 18 Online Adjustment of Replication Topology; If MySQL database access is not large, you can use a master-slave replication topology. The master database provides write services and the slave database provides read services. The semi-synchronous replication of MySQL 5.7 is used. High-availability software can realize high-availability and zero loss of data. In scenarios with a large amount of read access, it may be necessary to extend the replication topology to one-master and multiple-slave, or even dual-master and multiple-slave, to alleviate the read access pressure of a single slave library (for the expansion of the slave library, please refer to Chapter 16 "By extension From the library to improve copy performance"). But expanding the replication topology also means increasing management difficulty. For example, after the main library fails or is switched online to the new main library, the slave library connected to the original main library needs to be adjusted to connect to the new main library; or in order to improve the replication performance, an intermediate library may be added and the replication topology adjusted For cascading replication, online adjustment of the replication topology is involved at this time. This chapter will introduce in detail the online adjustment steps of the replication topology.
Chapter 19 Routine switch of master-slave instance ; routine switch of master-slave instance, here refers to the active transfer of write access requests of the master database to other database instances according to business changes or operation and maintenance management needs, this switch Not triggered by a fault. So, in what scenarios do you need to perform routine switching?

Chapter 20 Database Failover; Database Failover, here refers to the process of transferring the main library's read/write business to other database instances to continue to provide external read/write services triggered by the failure of the main database. For example, when it is detected that the main library host is down, the main library database process does not exist, the main library database cannot be logged in, or the main library database cannot perform query or update operations, in order to minimize the impact of the main library failure on the business, it needs to be as soon as possible Transfer the read/write access entry to the database instance in a normal state.
In actual scenarios, there are many reasons why the main library cannot provide read/write services. For a database management system, the more factors considered, the more complex it will be, and the worse the reliability will be. Therefore, it is usually recommended to divide the problem into scenarios where the cause of the fault can be determined and those where the cause of the fault cannot be determined, and then solve them in different ways. If confused, it may often lead to misoperation and transfer.
For scenarios where the cause of the failure can be determined and business access can be restored through automatic failover, the database management system can be used to automatically perform failover.
Chapter 21 Setting up multi-source replication; MySQL multi-source replication (also called "multi-master replication") refers to the slave library in the replication topology that simultaneously receives binary logs from multiple source servers (master libraries) for replay . Multi-source replication can be used to back up the data of multiple servers to a single server (from the library), and in the scenario of sub-database sub-tables, to merge data from multiple servers' shard tables. When the slave library applies binary logs from multiple master libraries, it will not perform any conflict detection or conflict resolution. If necessary, the application program will solve these problems. In a multi-source replication topology, the slave library establishes a separate replication channel (separate I/O thread, coordinator thread, and worker thread) for each master library, and replays their own binary logs, independent of each other.
For the principles and usage scenarios of multi-source replication, please refer to Chapter 7 "Multi-source replication" for details. This chapter will introduce in detail the setup steps of multi-source replication.

Chapter 22 MySQL version upgrade; MySQL version does not need to be upgraded frequently, but if you want to use a new feature of the new version, or in order to fix a bug in the old version, you have to upgrade the version. In a production environment, to avoid a single point of failure, multiple MySQL instances are usually used to build a replication topology. In order to make the impact of the upgrade operation on the business as small as possible, you can first upgrade the read-only instance (slave library) in the replication topology, and then perform a master-slave role switch (it will cause a brief interruption of the application), and finally treat the master library as a slave The library can be upgraded again.
This chapter only explains some precautions for upgrading the MySQL version in the replication topology. For the steps to upgrade the MySQL version in the replication topology, please refer to Section 19.2 "Online Switching".
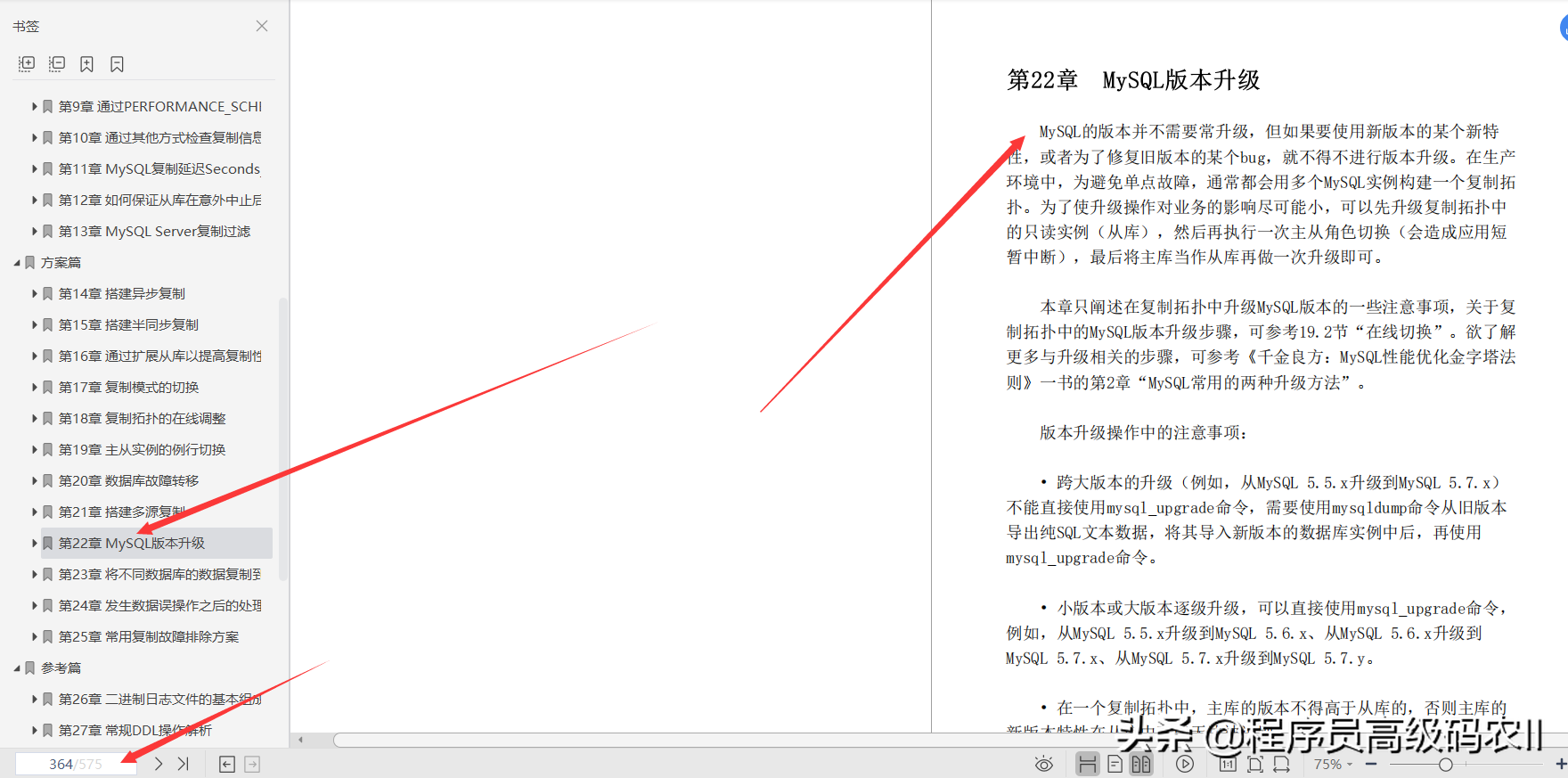
Chapter 23: Copying data from different databases to different instances; copying data from different databases to different instances (MySQL Server), in terms of implementation, specifically refers to pulling the full binary log of the main library from the library to the local After relaying the logs, when the slave SQL thread replays these binary logs, it selects which libraries and tables need to be applied and which libraries and tables need to be ignored according to the replication filtering rules configured by itself.
Of course, replication filtering is also supported on the main library side. Although the configuration of replication filtering on the main library side can reduce the amount of binary log transmission, the main library side only supports library-level filtering rules, and it is easy to cause inconsistent data between the master and the slave libraries. It is generally not recommended to configure replication filtering rules on the main library side. Reliable replication filtering is implemented on the secondary library side, because this is more reasonable. Each slave library can flexibly configure the replication filtering rules according to its own needs.
Regarding the principle and process of replication filtering, this chapter will not elaborate too much. You can refer to Chapter 13 "MySQL Server Replication Filtering". This chapter will take the configuration of copy filtering rules on the slave library side as an example to introduce its operation steps in detail.
Chapter 24 Handling plan after data misoperation occurs; In today's era of information explosion, data and information are the cornerstones of a technology-based company's survival. However, in the process of daily maintenance of the server storing data and information, it is inevitable for technicians to make mistakes (for example, mistaken modification, mistaken deletion, mistaken writing, etc.). However, we can minimize the loss caused by misoperation. After the misoperation occurs, some methods can be used to recover the misoperation data as much as possible. This chapter will explain in detail several common simple and effective methods of recovering accidentally deleted data in MySQL.
Chapter 25 Common Replication Troubleshooting Solutions; As MySQL database administrators, we will encounter MySQL replication-related problems more or less in our daily work. Some problems may be solved soon, and some problems are somewhat confusing , It may take a long time to investigate to find the specific cause. For the latter, we will encounter them again in our future work. When you meet again, do you feel like you've known each other but can't remember the specific details?
In order to avoid this embarrassment, it is recommended that after handling the fault, immediately summarize the fault phenomenon, its recurrence and troubleshooting process, solutions and avoidance methods in the form of a document, and keep it.
In addition, although the faults are diverse, their handling ideas and procedures are common. This chapter focuses on dealing with MySQL replication-related failures, and introduces in detail a general solution for troubleshooting replication failures (note that this chapter only explains the ideas and processes, and does not introduce details).
Reference
Chapter 26 The basic composition of binary log files; on the platform that uses MySQL database, many key application scenarios are implemented based on binary logs, such as master-slave replication (this is also the subject of this book, and a lot of space is introduced in the previous The principle and use case of replication), point-in-time backup and recovery, rollback of misoperation data, data supply (parse binary log files, and transfer the obtained text data to another platform, such as data warehouse, Kafka, etc.) Wait, but few people have learned about the binary log in detail. This chapter will give a detailed introduction to the contents of the binary log file from the perspective of binary log event types.
Chapter 27 Analysis of conventional DDL operations;

Chapter 28: Why are the events of the same transaction in the binary log out of order; for this problem, I believe that many people just know the principle, and have not done a specific case analysis. This chapter will take a common UPDATE statement to update data as a case, and analyze the process in detail.
Chapter 29 Copy the AUTO_INCREMENT field; when designing the MySQL table structure, it is generally recommended to use the AUTO_INCREMENT field as the primary key of the table instead of using the UUID as the primary key. The reason is that using the former as the primary key can ensure that the data rows are written in order. If the random write method is adopted, InnoDB will generate a large number of random I/O operations when writing data, and will frequently perform data page splitting operations.
The primary key of the AUTO_INCREMENT field has advantages in insertion performance and in inhibiting the generation of fragmented space. But its value is generated by MySQL Server, so in the replication topology, how does MySQL ensure the consistency of the AUTO_INCREMENT field data between the master and slave libraries? This chapter discusses how to ensure that the AUTO_INCREMENT field is copied correctly in MySQL.
Chapter 30 Copy CREATE...IF NOT EXISTS statement; MySQL has CREATE...IF NOT EXISTS statement, which is very convenient for the program to create a library or table: if the library or table does not exist, create it; otherwise, do not create it. Regardless of whether there is a library in the main library, when the CREATE DATABASE IF NOT EXISTS statement is used to create the library, the statement can be correctly copied to the slave library. Similarly, regardless of whether a table exists in the main library, CREATE TABLE IF NOT EXISTS statements (except CREATE TABLE IFNOT EXISTS ... SELECT) can be copied to the slave library correctly. In this chapter, we will take a look at how the CREATE DATABASE IF NOT EXISTS and CREATE TABLE IF NOT EXISTS statements are correctly copied to the slave library.

Chapter 31 Copying CREATE TABLE...SELECT Statements; Chapter 30 explains how CREATE...IF NOT EXISTS statements (except CREATE TABLEIF NOT EXISTS...SELECT) are copied correctly. In this chapter, let’s look at the first How the CREATE TABLE IF NOT EXISTS ... SELECT and CREATE TABLE ... SELECT statements not covered in Chapter 30 are copied correctly.

Chapter 32 uses different table definitions in master-slave replication; under normal circumstances, we use MySQL master-slave replication to ensure the consistency of master-slave database data, but sometimes we may encounter some requirements. For example, for security reasons, certain fields need to be filtered when the upstream database is synchronized to the downstream database, or the intermediate database needs to adjust the field type, then if the table (structure) definition is not synchronized in MySQL, it is artificially separated in the main database Unlike creating different table definitions from the database, MySQL is only responsible for data synchronization during replication. Is this feasible? This chapter will introduce the use of different table definitions for replication in master-slave replication.
Chapter 33 Calling Functions in Replication; In daily work, DBAs will inevitably encounter scenarios where stored procedures, triggers, custom functions, etc. are used. Therefore, in this chapter, we will talk about how to ensure storage in MySQL replication. The correctness of procedures, triggers, custom functions, etc.
Chapter 34 Copy LIMIT clauses; DBAs generally advise developers not to use large transactions when using MySQL. For example, when cleaning millions of rows of data on a certain table, it is not recommended to use a DELETE statement to clean up all the data directly. Instead, it is recommended to use the LIMIT clause to clean up small batches and multiple times. The LIMIT clause limits the number of rows returned in the result set that meets the conditions, but it is impossible to specify which rows are. In MySQL replication, how to ensure the consistency of replication for clauses such as LIMIT clauses with uncertainties? In this chapter, we will take a look at how the LIMIT clause is copied correctly.
Chapter 35 Duplicate the LOAD DATA statement; LOAD DATA statement can easily import the data in the file into MySQL, and it is a way that developers are used to importing data. In this chapter, we will take a look at how to ensure that the LOAD DATA statement is correctly copied from the master database to the slave database in the MySQL master-slave replication architecture.
Chapter 36 The impact of the system variable max_allowed_packet on replication; anyone familiar with MySQL knows that MySQL has many system variables that can be set to control its behavior or performance. For example, the system variable max_allowed_packet can control the transmission after the client is connected to the server The maximum size of the data packet. In this chapter, we will talk about the impact of the system variable max_allowed_packet on replication, and then introduce some other similar system variables.
Chapter 37 Replicating Temporary Tables; Compared with ordinary tables, I believe that many readers should be both unfamiliar and familiar with temporary tables. This article is about MySQL replication, so this chapter will talk about how temporary tables are replicated in MySQL. , And what to do if you encounter a temporary table during replication.

Chapter 38 Transactions in replication do not cause problems; in MySQL replication, we are all worried about the data consistency of the master and slave databases. In some cases, the inconsistency of master-slave database data is caused by inconsistent transactions between the master-slave database. In this chapter, we will talk about the types, causes, and results of transaction inconsistencies in MySQL replication.

This [MySQL replication technology and production practice] document has a total of 575 pages. If you need a full version, you can forward this article and follow the editor, scan the code below to get it! ! !
